Dataflow vs spark streaming

This document compares Spark Streaming and Google DataFlow for processing streaming data from Google Pub/Sub and writing to BigQuery. Some key differences are: - DataFlow provides richer streaming concepts like event-time processing, watermarks, and session windows while Spark Streaming only supports fixed and sliding windows based on processing time. - Fault tolerance is completely handled by DataFlow and Spark Streaming requires developers to implement checkpointing and recovery. - Code reuse is limited between batch and streaming with Spark Streaming but the DataFlow SDK can call the same APIs. - DataFlow integrates better with Google Cloud services and has richer monitoring while Spark Streaming requires more integration work for deployment and operations. - Local testing is easier


Dataflow vs spark streaming
- 1. Spark Streaming Google DataFlow Pub/sub Source Use SparkŌĆÖs custom receiver interface In receiver mode, data is ackŌĆÖed back to pubsub once committed to Spark write ahead log. In direct mode, the calling application needs to ack once message persisted Google libraries provide pubsub integration by default (accessible through scio) Separate checkpointing thread that acks/n-acks messages to pubsub - no application control over it OTOH: application code need not bother about pubsub acks BigQuery Sink Use TableData.insertall api Data needs to be converted back to json (no support for avro, or direct handling of case classes) Need to add a lot more error handling in the BQ integration Scio provides handy annotations which enables us to directly pass case class objects to write API (it abstracts out all the dirty reflection stuff) Google BigQueryIO methods in dataflow SDK infer streaming / non-streaming modes and call the appropriate APIs Dependen cies Spark streaming SDK Google dataflow SDK, Spotify SCIO (which needs a special compiler plugin for macro/annotations)
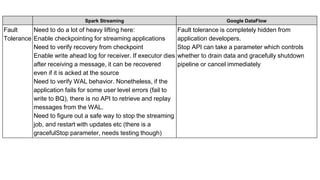
- 2. Spark Streaming Google DataFlow Fault Tolerance Need to do a lot of heavy lifting here: Enable checkpointing for streaming applications Need to verify recovery from checkpoint Enable write ahead log for receiver. If executor dies after receiving a message, it can be recovered even if it is acked at the source Need to verify WAL behavior. Nonetheless, if the application fails for some user level errors (fail to write to BQ), there is no API to retrieve and replay messages from the WAL. Need to figure out a safe way to stop the streaming job, and restart with updates etc (there is a gracefulStop parameter, needs testing though) Fault tolerance is completely hidden from application developers. Stop API can take a parameter which controls whether to drain data and gracefully shutdown pipeline or cancel immediately
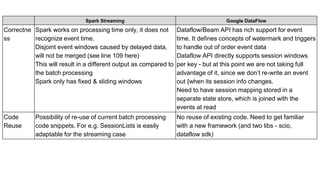
- 3. Spark Streaming Google DataFlow Correctne ss Spark works on processing time only, it does not recognize event time. Disjoint event windows caused by delayed data, will not be merged (see line 109 here) This will result in a different output as compared to the batch processing Spark only has fixed & sliding windows Dataflow/Beam API has rich support for event time. It defines concepts of watermark and triggers to handle out of order event data Dataflow API directly supports session windows per key - but at this point we are not taking full advantage of it, since we donŌĆÖt re-write an event out {when its session info changes. Need to have session mapping stored in a separate state store, which is joined with the events at read Code Reuse Possibility of re-use of current batch processing code snippets. For e.g. SessionLists is easily adaptable for the streaming case No reuse of existing code. Need to get familiar with a new framework (and two libs - scio, dataflow sdk)
- 4. Spark Streaming Google DataFlow Deploy and Operations Runs on Dataproc - spark history server issue needs to be sorted out Need to integrate with InfluxDB monitoring Airflow integration needs to be thought through - this is not a scheduled job, itŌĆÖs a daemon which needs to be managed on a cluster Runs on dataflow. Logs are forwarded to stack driver Rich monitoring information displayed both on the dataflow UI, and available on stackdriver The orchestrator is still in question here, similar to spark streaming Local testing and unit tests Easy to test locally (with local master) DirectPipelineRunner which is used for local mode, does not work with pubsub. To test locally the input method needs to be changed from pubsub to reading from a file Cost Dataproc: $394 / mo (@3 nodes - 12vCPU) Pubsub: - same - BQ Streaming: - same - Dataflow: $764 / mo (@3 Workers 12 vCPU, 45GB, 1.25TB) Pubsub: $342 / mo (@1000 events/sec, 3 ops/event) BQ Streaming: $126 / mo (@1000 row/s, each row 1KB) Stackdriver for pubsub: Pricing not clear yet. Seems free :)