Datanote
âĒ
0 likesâĒ405 views

Datanote is a desktop application that extracts and visualizes relationships between entities from documents and other sources using graph visualization. It identifies named entities and displays their connections to analyze recurring patterns and relationships between micro to macro levels. The prototype uses its own datasets and local extraction models, with plans to support external data sources and models. Future roadmaps include smarter extraction, complex graph queries, third-party models, search, and monetization options.

































Datanote
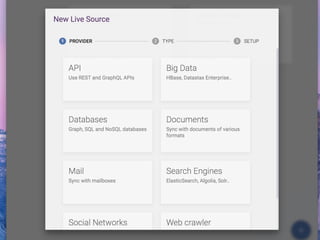
- 2. Datanote is a desktop app to extract and visualize relationships between entities cited in .pdf, .doc etc.. documents but also other sources such as databases or web pages.
- 4. "Iâm a product manager. I like gardening, cinema and sky diving."
- 5. "Iâm a product manager. I like gardening, cinema and sky diving."
- 6. "Iâm a product manager. I like gardening, cinema and sky diving."
- 7. "Iâm a product manager. I like gardening, cinema and sky diving."
- 8. "Iâm a product manager. I like gardening, cinema and sky diving."
- 9. "Cutaneous administration of unicornamycin might transform the subject into a unicorn."
- 10. "Cutaneous administration of unicornamycin might transform the subject into a unicorn."
- 12. Named entities being unique, they are a versatile metric to establish the nature of documents but also the recurring patterns of these entities themselves.
- 14. Fed with the right input our visual cortex can become a powerful analysis system. Graph visualization helps us perceive relationships between entities from the micro to the macro level. To exploit this effect we project entities onto a 2D plane using co-citation scores as a distance metric.
- 15. But different kinds of questions may impose different ways to interact with and explore the knowledge graph. For this reason multiple interfaces are being developed in Datanote.
- 16. Warning: working prototype, UI subject to change.
- 19. Concept.
- 20. What are the use cases?
- 21. Your Industry What A are linked with B? What if you built your own extraction model using your company data? Human Resources What entities are associated with a candidate ? Or a school, a company, a skill? Market Intelligence What terms are mentioned with my brand? my competitor? And in their job offers? Fraud detection Who is mentioned in some PDF reports? What are the links between accounts or phone numbers?
- 22. Behind the hood
- 23. Datanote is a stand-alone application written in Electron. In the prototype text extraction is performed locally using Node modules and data is stored in an embedded OrientDB database.
- 24. Datanote is designed with i18n support in mind: not only for display but also for entity identification. This approach makes it possible to process mixed-language sources such as web pages and social media. This design also allows humans to improve the model by adding new words.
- 25. For now Datanote uses its own datasets some which are open-source at github.com/datagica Support for external data sources and models will probably be asked.. and so is planned.
- 26. Using pre-defined lists of words works for certain cases but what about unknown data? For complex entities Datanote uses pattern matching models to recognise human names, phones and IBAN numbers, addresses, emails, spoken languages..
- 27. Feature roadmap
- 28. Smarter extraction models? Our own machine-learned models? Complex knowledge graph interrogation in Gremlin or natural language? Allow people to use their own "better" models? Third party API cloud models?
- 29. Support other DBs for data storage? Full featured search system? Chatbot API? Slack integration? A model or datasource plugin marketplace? With a commission system for us? Jupyter extension for datascientists? Web platform to publish read-only notebooks? What should be done ïŽrst?
- 30. On a more personal note: project status
- 31. Datanote is a side project with no funding and thus is progressing rather slowly, stopping at times. As I do not wish to see it disappear I am in the process of open-sourcing it bit by bit. But maybe it could be monetized? What would be the market and the business model then? That is still an open question.
- 32. Thank you!
- 33. Questions?