DataProcessingInBuffettCode-20190213
2 likes1,368 views

バフェットコード(丑迟迟辫蝉://飞飞飞.产耻蹿蹿别迟迟-肠辞诲别.肠辞尘/)における、データ処理の考え方を齿叠搁尝を例に话しました。











DataProcessingInBuffettCode-20190213
- 2. 0. 今日話すこと 1. 自己紹介的な 2. バフェットコードについて ○ バフェットコードって何? ○ バフェットコードが生まれたわけ 3. バフェットコードの日次データ処理 4. XBRLデータ構造とparserの話 ○ XBRLとは ○ XBRLのデータ構造 ○ データ処理におけるparserの考え方 5. まとめ
- 3. 1. 自己紹介的な なまえ:しゅう (@shoe116) お仕事:広告系エンジニア→データ分析基盤屋さん 推し事:ももくろ→でんぱ組→BiSH→CY8ER、オサカナ 関連語:Hadoop, Kafka, Storm, Tez, Beam, Cloud Dataflow 開発言語:Java or Scala, Python, Go バフェットコードはデータ処理を中心にwebアプリ以外を担当
- 4. 2.1 バフェットコードって何? オープンデータを用いた、効率的な企業分析を行うためのwebサイト 使い方は、https://www.buffett-code.com/ にアクセスするだけ 主な機能は以下の3つ 1. 財務?株価データの参照 2. スクリーニング 3. 企業比較 最近、ようやく有料機能出した
- 5. 機能①. 企業別財務数値?株価指標の参照 ● 国内の上場企業データベースを可視化して提供 ○ 検索窓に企業名or銘柄コードを入力 ○ 業種から銘柄を探すことも可能 ○ 例:任天堂の企業詳細ページ ● 企業ごとに以下のデータを提供 ○ 基本的な財務数値と株価指標 ○ 株価推移とヒストリカルマルチプル ○ 大株主情報 ○ 四半期毎の業績と業績予想 ○ 開示資料へのリンク集
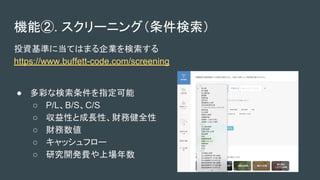
- 6. 機能②. スクリーニング(条件検索) 投資基準に当てはまる企業を検索する https://www.buffett-code.com/screening ● 多彩な検索条件を指定可能 ○ P/L、B/S、C/S ○ 収益性と成長性、財務健全性 ○ 財務数値 ○ キャッシュフロー ○ 研究開発費や上場年数
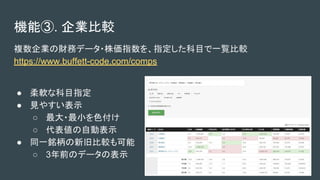
- 7. 機能③. 企業比較 複数企業の財務データ?株価指数を、指定した科目で一覧比較 https://www.buffett-code.com/comps ● 柔軟な科目指定 ● 見やすい表示 ○ 最大?最小を色付け ○ 代表値の自動表示 ● 同一銘柄の新旧比較も可能 ○ 3年前のデータの表示
- 9. 3. バフェットコードの日次データ加工処理 1. OPENデータ(XBRL file)を取得、保存 ○ EDINETから、該当日発行分の有価証券報告書(有報)を取得 ○ TDNETから、該当日発行分の決算短信を取得 ○ Edgarから、該当日発行分の10-K, 10-Qを取得 ○ それぞれをオブジェクトストレージに保存 2. 取得したXBRL fileをparseし、RDBに格納 3. 格納されたデータと、当日の株価を元に財務数値を計算、RDBに格納 4. RDB上のスクリーニング、比較用のデータセットを更新
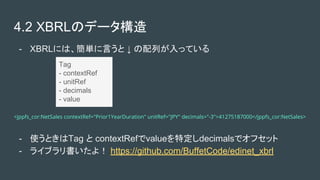
- 10. 4.1 XBRLとは ● eXtensible Business Reporting Language ● Edinet, Tdnet, Edgar 等から結構いい感じにDLできるXML ○ Edinet http://disclosure.edinet-fsa.go.jp ○ Tdnet https://www.jpx.co.jp/equities/listing/tdnet/index.html ○ Edgar https://www.sec.gov/edgar.shtml ● XMLのタグごとに、データが入っている $ grep ‘jppfs_cor:NetSales’ test.xbrl <jppfs_cor:NetSales contextRef="Prior1YearDuration" unitRef="JPY" decimals="-3">41275187000</jppfs_cor:NetSales> <jppfs_cor:NetSales contextRef="CurrentYearDuration" unitRef="JPY" decimals="-3">45089432000</jppfs_cor:NetSales>
- 11. 4.2 XBRLのデータ構造 Tag - contextRef - unitRef - decimals - value - XBRLには、簡単に言うと ↓ の配列が入っている - 使うときはTag と contextRefでvalueを特定しdecimalsでオフセット - ライブラリ書いたよ! https://github.com/BuffetCode/edinet_xbrl <jppfs_cor:NetSales contextRef="Prior1YearDuration" unitRef="JPY" decimals="-3">41275187000</jppfs_cor:NetSales>
- 12. 4.3 データ処理におけるparserの考え方 ● 死ぬほど当たり前だけど、parse := Inv format ● 感覚的にはserializerとdeserializerを実装するときと似ている ○ 論理的なデータ構造は変えず、物理的なAlignmentだけ変換する ● 論理的なデータ構造から設計するべき 1. 論理的な財務データを考える (FinancialsObject) 2. def XBRL.formatter(financials: FinancialsObject) : XBRLFile を想像する 3. def XBRL.parser(xbrl: XBRLFile): FinancialsObject が決まる ● 論理的な中間表現を介して変換のペアを書くときれいに作れる ○ XBRL => JSONならXBRL parserとJSON Formatter ○ XBRL => TableRowなら、XBRL parserとTableRow Formatter
- 13. 4.4 「XBRLのparseは難しい」という人へ ● 難しいのparseじゃなくてformat ○ nestしているので、RDBのrowとかCSVにするのは難しい ○ XBRLってつまりXMLなので、難しいはずない ● Parserにparse以外のロジックを書いているコードはよく見る ○ 必要な情報だけ抽出する、内部の変数を上書きするetc ○ 戻り値をformatterに食わせて元に戻らないのはparserじゃない ● XX2YYConverterは↓って実装すると読みやすいしテストしやすい def convert(input: XX): YY obj = XXParser.parse(input) YYFormatter.format(obj)
- 14. 5. Appendix
- 15. Buffett-Codeの現状 1. Buffett-Codeと周辺サービス ○ メインのWebアプリケーション https://www.buffett-code.com/ ○ フォロワー26.5K超のTwitter https://twitter.com/buffett_code ○ 企業分析に役立つBlog https://blog.buffett-code.com/ ○ CampFire https://camp-fire.jp/projects/view/114594 2. Buffett-Codeの技術発信 ○ OSSの公開 https://github.com/buffetcode ○ Python Packageの公開 https://pypi.org/project/edinet-xbrl/ ○ Buffett-Codeの内部技術の紹介 ■ https://qiita.com/shoe116/items/dd362ad880f2b6baa96f ■ https://qiita.com/shoe116/items/a7b688d05b699cf403a1
- 16. ● Buffett-Code ○ WebApp https://www.buffett-code.com/ ○ Usage https://blog.buffett-code.com/entry/18/02/01 ○ Twitter https://twitter.com/buffett_code ○ Blog https://blog.buffett-code.com/ ○ GitHub https://github.com/buffetcode ○ Dev Docs https://qiita.com/shoe116/items/dd362ad880f2b6baa96f ● Data Sources ○ Edinet, http://disclosure.edinet-fsa.go.jp ○ Tdnet, https://www.jpx.co.jp/equities/listing/tdnet/index.html ○ Edgar, https://www.sec.gov/edgar/searchedgar/companysearch.html ● XBRL Info ○ XBRL.org https://www.xbrl.org/ ○ 有報キャッチャー https://ufocatch.com/