


























¶Łµž„Į„å©`„Ė„ó„°³¬ČėĆÅ
- 2. ×Ō¼ŗ½B½é ? ±¾Ćū£ŗmŌ Ų ? 1972Äź1ŌĀ ÉńÄĪ“رhÉś¤Ž¤ģ ? 1994Äź3ŌĀ ÖŠŃė“óѧ·Øѧ²æ·ØĀÉѧæĘ×äI ? 1994Äź4ŌĀ ČÕ±¾„Ŗ„é„Æ„ėÖźŹ½»įÉēČėÉē ØC PC„µ©`„ŠĻņ¤±RDBMSŃuĘ·„Ž©`„±„Ę„£„ó„°¤Ė¾ŹĀ ØC Linux°ęOracle8¤ĪČÕ±¾ŹŠöĻņ¤±³öŗɤĖŲĻ× ? 2000Äź3ŌĀ ÖźŹ½»įÉē„Ē„ø„æ„ė„Ē„¶„¤„ó |¾©Ö§ÉēéL¤Ŗ¤č¤ÓÖź Ź½»įÉē„¢„Æ„¢„ź„¦„ą„³„ó„Ō„å©`„æ©` “ś±ķČ”¾ŅŪÉēéL¤Ė¾ĶČĪ ØC 2000Äź6ŌĀ £ØÖź£©„Ē„ø„æ„ė„Ē„¶„¤„󔢄Ź„¹„Ą„Ć„Æ?„ø„ć„Ń„óÉĻö£Ø4764£© ? 2001Äź1ŌĀ ÖźŹ½»įÉē¤Ó¤®¤Ķ¤Ć¤Č ŌOĮ¢ ? 2006Äź12ŌĀ ČÕ±¾¢Ļė»Æ¼¼ŠgÖźŹ½»įÉē ŌOĮ¢ ? 2008Äź10ŌĀ IPA”øČÕ±¾OSSŲĻ×Õߣp”¹ŹÜŁp ? 2009Äź10ŌĀ ČÕÖŠķnOSS„¢„ļ©`„É ”øĢŲeŲĻףp”¹ŹÜŁp 2
- 3. ČÕ±¾¢Ļė»Æ¼¼ŠgÖźŹ½»įÉē øÅŅŖ ? ÉēĆū£ŗČÕ±¾¢Ļė»Æ¼¼ŠgÖźŹ½»įÉē ØC Ó¢ÕZĆū£ŗVirtualTech Japan Inc. ØC ĀŌ³Ę£ŗČÕ±¾¢Ļė»Æ¼¼Šg£ÆVTJ ? ŌOĮ¢£ŗ2006Äź12ŌĀ ? ŁY±¾½š£ŗ3,000ĶņŅ ? ÓÉĻøߣŗ1|8100ĶņŅ£Ø2022Äź7ŌĀĘŚ£© ? ±¾Éē£ŗ|¾©¶¼i¹ČĒųi¹Č1-8-1 ? Č”¾ŅŪ£ŗmŌ Ų£Ø“ś±ķČ”¾ŅŪÉēéL¼ęCEO£© ? ŅĮĢŁ ŗźĶØ£ØČ”¾ŅŪCTO£© ? „¹„æ„Ć„Õ£ŗ11Ćū£Ø¤¦¤Į8Ćū¤¬¢Ļė»Æ¼¼ŠgéT„Ø„ó„ø„Ė„¢¤Ē¤¹£© ? URL£ŗhttp://VirtualTech.jp/ ? ¢Ļė»Æ¼¼Šg¤Ėév¤¹¤ėŃŠ¾æ¤Ŗ¤č¤Óé_°k ØC ¢Ļė»Æ¼¼Šg¤Ėév¤¹¤ėø÷·NÕ{Ė ØC ¢Ļė»Æ¼¼Šg¤ņ§Čė¤·¤æ„·„¹„Ę„ą¤ĪŗB?ß\ÓĆ„µ„Ż©`„Č ØC 5G»īÓƤĪ¤æ¤į¤Ī„¤„ó„Õ„é?„µ©`„Ó„¹ŃŠ¾æé_°k ØC DevOpsÖ§Ō®„µ©`„Ó„¹¤ĪĢį¹© ØC GPU¤ņ»īÓƤ·¤æ³¬øßĖŁ„Ē©`„æ·ÖĪö»ł±P”ø±¬ĖŁDB”¹¤ĪĢį¹© „Ł„ó„Ą©`„Ė„å©`„Č„é„ė¤Ź ¶ĄĮ¢Ļµ¢Ļė»Æ¼¼Šg¤Ī „Ø„„¹„Ń©`„Č¼Æā 3
- 4. DB¤ĪŹĖ÷ŠŌÄܤņQ¶Ø¤¹¤ėŅŖĖŲ ? „Ē©`„æ¤ĪÕi¤ßŽz¤ß ? ŹĖ÷IĄķ ? ¼ÆÓ¤½¤ĪĖū¤ĪŃŻĖćIĄķ ? ±¾ŁYĮĻ¤Ļ„Ó„Ć„°„Ē©`„æIĄķ¤Ź¤É¤ņĻė¶Ø¤·¤æŹ Ė÷IĄķ¤Ī¤ß¤ņČ”¤źÉĻ¤²¤Ę¤¤¤Ž¤¹ ? DBMS£ØDataBase Management System£©¤Č¤¤¤¦ „Ö„é„Ć„Æ„Ü„Ć„Æ„¹¤ņSQL¤Ź¤É¤Ē²Ł×÷¤¹¤ėÓQµć¤Ē ½āÕh¤·¤Ę¤Ŗ¤ź”¢DBMS¤Īg×°¤Ė¤č¤Ć¤ĘŌ¼¤¬ ®¤Ź¤ėöŗĻ¤¬¤¢¤ź¤Ž¤¹
- 5. „Ē©`„æ¤ĪÕi¤ßŽz¤ß ? „Ē©`„æ¤Ļ„¹„Č„ģ©`„ø¤«¤é„į„ā„ź¤ĖÕi¤ßŽz¤ó¤ĒIĄķ ? „¹„Č„ģ©`„ø¤ĪÕi¤ßŽz¤ßĖŁ¶Č¤Č¤Ļ ØC „¹„Č„ģ©`„ø×ŌĢå¤ĪĖŁ¶Č ØC ½Ó¾A½UĀ·¤ĪĖŁ¶Č ? „¹„Č„ģ©`„ø×ŌĢå¤ĪĖŁ¶Č ØC IOPS¤äÕi¤ßų¤ĖŁ¶Č£Ø”šMB/Ćė£©¤Ź¤É¤Ē±ķ¤µ¤ģ¤ė ØC HDD¤Ź¤é„ׄé„Ć„æ©`„µ„¤„ŗ¤ä»ŲÜĖŁ¶Č¤¬Ó°ķ ØC SSD¤Ź¤é„·„ź„³„ó¤ä„³„ó„Č„ķ©`„é©`ĖŁ¶Č¤¬Ó°ķ ? ½Ó¾A½UĀ·¤ĪĖŁ¶Č ØC SATA¤äSAS”¢NVMe£ØPCI Express„Š„¹Ö±½Y£© ØC SATA(6Gbps)£¼SAS(12Gbps)£¼NVMe(64Gbps) ”ł ? NVMe¤ĻPCIe 4.0¤Īx4„ģ©`„ó¤ņĻė¶Ø ”łĄķÕ¤Ē¤¢¤ź”¢„ׄķ„Č„³„ė„Ŗ©`„Š©`„Ų„ƄɤŹ¤É¤ĒgĖŁ¶Č¤ĻµĶĻĀ¤·¤Ž¤¹ „Ē©`„æ „į„¤„ó„į„ā„ź CPU
- 6. ŹĖ÷IĄķ ? „į„ā„ź¤ĖÕi¤ßŽz¤ó¤Ą„Ē©`„æ¤ņCPU¤ĒIĄķ ? WHERE¾ä¤Ė¤č¤ėĢõ¼žŅ»ÖĀIĄķ ØC INŃŻĖć×Ó¤äLIKEŃŻĖć×Ó¤Ź¤É¤ĪIĄķ¤ņŗ¬¤ą ØC „¤„ó„Ē„Ć„Æ„¹¤¬Ź¹¤ļ¤ģ¤Ź¤¤öŗĻ¤Ė¤ĻČ«¼žŹĖ÷ ØC ø±¤¤ŗĻ¤ļ¤»¤Ė¤č¤ėĢõ¼ž¤Ī³é³ö ? JOIN¾ä¤Ė¤č¤ė±ķ½YŗĻIĄķ ? SELECTßxk„ź„¹„ȤĖ¤č¤ė„Ē©`„æ¤Ī³é³ö „Ē©`„æ „į„¤„ó„į„ā„ź CPU
- 7. ¼ÆÓ¤½¤ĪĖū¤ĪŃŻĖćIĄķ ? ŹĖ÷IĄķ¤µ¤ģ¤æ„Ē©`„æ¤Ė¤¹¤ė×·¼ÓIĄķ ØC CPU¤Č„į„ā„ź¤ņŹ¹¤Ć¤ĘIĄķ ? „½©`„ČIĄķ ? GROUP BY¾ä¤Ė¤č¤ė¼Æ¼s ? ¼Æ¼sévŹż¤Ė¤č¤ėø÷·N¼ÆÓIĄķ ØC COUNTévŹż¤Ź¤É ŃŻĖćIĄķ¤ņŠŠ¤Ć¤æ½Y¹ū¤ņ„¢„ׄź¤Ė·µ¤¹
- 9. „Ē©`„æ„Ł©`„¹ŠŌÄÜĻņÉĻ¤Ī·½·Ø ? „¹„Č„ģ©`„ø¤ĪÕi¤ßŽz¤ß¤ņĖŁ¤Æ¤¹¤ė ? „Ļ©`„É„¦„§„¢¤ĪøÄÉʤŹ¤É ? „Ē©`„æ¤ĪĖłŌŚ¤ņĆ÷¤é¤«¤Ė¤¹¤ė ? „¤„ó„Ē„Ć„Æ„¹¤ĪĄūÓĆ ? „Ń©`„Ę„£„·„ē„Ė„ó„° ? ŹĖ÷IĄķ¤äŃŻĖćIĄķ¤ņĖŁ¤Æ¤¹¤ė ? CPU¤ä„į„ā„ź”¢„¹„Č„ģ©`„ø¤ņ¤ä¤¹ ? gĢåŠŌÄܤņĻņÉĻ¤µ¤»¤ė„¹„±©`„ė„¢„Ć„× ? IĄķ¤ņ·ÖÉ¢¤µ¤»¤ė„¹„±©`„ė„¢„¦„Č
- 10. „Ē©`„æ¤ĪÕi¤ßŽz¤ß¤ņĖŁ¤Æ¤¹¤ė ? ¤č¤źøßĖŁ¤Ź„¹„Č„ģ©`„ø„Ē„Š„¤„¹¤ņŹ¹ÓƤ¹¤ė ØC HDD¤č¤źSSD ØC SATA£¼SAS£¼NVMe ØC FibreChannel¤äiSCSI¤Ē½Ó¾A½UĀ·¤ņŚ”Óņ»Æ ? „Ē„Š„¤„¹¤ņŃ}ŹżÓĆŅā¤¹¤ė ØC RAID 0£Ø„¹„Ȅ鄤„Ō„ó„°£©»Æ ? ±ŲŅŖ¤Ź„Ē©`„æ¤Ą¤±Õi¤ßŽz¤ą¤³¤Č¤ĒÕi¤ßŽz¤ßĮæ¤ņp¤é¤¹ ØC „¤„ó„Ē„Ć„Æ„¹¤Ī»īÓĆ ØC „«„é„ą£ØĮŠ£©ÖøĻņ„Ē©`„æ„Ł©`„¹ ? ×ī³õ¤«¤é„į„ā„ź£Ø„Š„Ć„Õ„”£©¤ĖÕi¤ßŽz¤ó¤Ē¤Ŗ¤Æ ØC „¤„ó„į„ā„ź„Ē©`„æ„Ł©`„¹
- 11. „Ē©`„æ¤ĪĖłŌŚ¤ņĆ÷¤é¤«¤Ė¤¹¤ė ? „Ē©`„æ¤ĪŌŚI¤¬·Ö¤«¤é¤Ź¤±¤ģ¤ŠČ«¼žŹĖ÷¤¹¤ė¤·¤«¤Ź¤¤ ØC Õi¤ßŽz¤ß¤Ėrég¤¬¤«¤«¤ė ØC „į„ā„ź¤¬“óĮæ¤Ė±ŲŅŖ¤Č¤Ź¤ė ? „¤„ó„Ē„Ć„Æ„¹¤ņĄūÓƤ·¤Ę„Ē©`„æ¤ĪĖłŌŚ¤ņĆ÷¤é¤«¤Ė¤¹¤ė ? „¤„ó„Ē„Ć„Æ„¹¤āĶņÄܤĒ¤Ļ¤Ź¤¤ ØC „Ē©`„漞Źż¤¬ÉŁ¤Ź¤¤ ØC „«©`„Ē„£„Ź„ź„Ę„£¤¬µĶ¤¤£Ø”ø0¤«1¤«”¹¤Ź¤ÉČ”¤ė¤Ī·Nī¤¬ÉŁ ¤Ź¤¤£© ? „Ń©`„Ę„£„·„ē„Ė„ó„°¤Ē„Ē©`„æ¤ņ·Öøī¤¹¤ė ? „«„é„ą£ØĮŠ£©Ö¾Ļņ„Ē©`„æ„Ł©`„¹¤ĪĄūÓĆ ØC ³é³ö¤·¤æ¤¤ĮŠ¤¬Q¤Ž¤Ć¤Ę¤¤¤ėöŗĻ
- 12. ŹĖ÷IĄķ¤äŃŻĖćIĄķ¤ņĖŁ¤Æ¤¹¤ė 1ĢؤņøßĖŁ»Æ¤¹¤ė„¹„±©`„ė„¢„Ć„× ? CPU„³„¢¤Ī„Æ„ķ„Ć„ÆŹż¤ņøßĖŁ»Æ¤¹¤ė ØC „ׄķ„»„¹„ė©`„ė¤ĪĪ¢¼»Æ¤ĪĻŽ½ē¤Č°kį¤ĪÖĘĻŽ ? CPU„³„¢Źż¤ņ¤ä¤¹ ØC „Ą„¤„µ„¤„ŗ¤Ė¤č¤ėg×°æÉÄÜ„³„¢Źż¤ĪÖĘĻŽ ØC „Ž„ė„Į„ׄķ„»„¹¤ä„Ž„ė„Į„¹„ģ„ƄɤĒ»īÓĆ Ń}ŹżĢؤĒøßĖŁ»Æ¤¹¤ė„¹„±©`„ė„¢„¦„Č ? ĢØŹż¤ņ¤ä¤·¤Ę„Ƅ鄹„æ©`»Æ¤¹¤ė ØC Ń}ŹżĢØĄūÓƤĖ¤č¤ė„³„¹„ȤĪ¼Ó ØC ¹ÜĄķ¤ä„Č„é„Ö„ė½āQ¤Ī©ėj¤µ
- 13. ÖŠég¤Ž¤Č¤į£ŗDBŹĖ÷¤¬ßW¤Æ¤Ź¤ėŅŖŅņ ? „¹„Č„ģ©`„ø¤ĪĖŁ¶Č¤¬ßW¤¤ ? „Ē©`„æ¤ĪĮ椬¶ą¤¤ ? CPU¤¬ßW¤¤£Ø„Æ„ķ„Ć„ÆŹż?„³„¢Źż£© ? „į„ā„ź¤¬ÉŁ¤Ź¤¤ ? „¤„ó„Ē„Ć„Æ„¹¤¬ßmĒŠ¤ĖŹ¹¤ļ¤ģ¤Ę¤¤¤Ź¤¤ ? IĄķ¤¬Ń}ėj£Øø±¤¤ŗĻ¤ļ¤»¤ä¼ÆÓIĄķ£©
- 15. PG-Strom¤ĪøßĖŁ»ÆŹÖ·Ø ? PG-Strom¤ĻPostgreSQL¤ņ?øßĖŁ»Æ ØC GPU¤Ė¤č¤ė³¬KĮŠIĄķ ØC GPUDirect Storage¤Ė¤č¤ė„Ē©`„æøßĖŁÕiŽz ØC Apache Arrow¤Ė¤č¤ė„Ē©`„æÕiŽz¤Ī×īßm»Æ ? Ķس£¤ĻßW¤Æ¤Ź¤ėIĄķ¤ņøßĖŁ»Æ ØC „¤„ó„Ē„Ć„Æ„¹¤¬æ¤«¤Ź¤¤„Õ„ė„¹„„ć„óŹĖ÷ ØC „Ó„Ć„°„Ē©`„æ¤Ī¼ÆÓIĄķ ØC Ī»ÖĆĒéó„Ē©`„æ¤ĪŹĖ÷IĄķ
- 16. GPU¤Ė¤č¤ė³¬KĮŠIĄķ ? CPU¤ČGPU¤Ī„³„¢Źż¤Ė“󤤏ß`¤¤ ØC ¬FŌŚ¤Ī„µ©`„Š©`ÓĆCPU¤¬„ׄķ„»„Ć„µ¤¢¤æ¤ź×ī “ó48„³„¢¤«¤é96„³„¢ ØC ¬FŌŚ¤Ī„Ø„ó„æ©`„ׄ鄤„ŗÓĆGPU¤¬¼s5000„³„¢ ? „Ē©`„æ¤ĪŹĖ÷IĄķ¤ä¼ÆÓIĄķ¤ņKĮŠ»Æ ØC ¤č¤ź¶ą¤Æ¤Ī„³„¢¤Ē³¬KĮŠIĄķ ØC g¼¤ŹIĄķ¤Ū¤ÉKĮŠ»Æ¤ĖĻņ¤¤¤Ę¤¤¤ė ? ÓĖćC¤ĻĢõ¼ž·ÖįŖ¤Ź¤É¤ĪŃ}ėj¤ŹIĄķ¤¬æąŹÖ
- 17. GPUDirect Storage¤Ė¤č¤ėøßĖŁÕiŽz ? NVMe½Ó¾A¤µ¤ģ¤æ„¹„Č„ģ©`„ø¤«¤éGPU¤Ī„į„ā„ź ¤Ė¤·¤ĘÖ±½Ó„Ē©`„æ¤ņÕi¤ßŽz¤ą¼¼Šg ØC „į„¤„ó„į„ā„ź½UÓɤĒGPU„į„ā„ź¤ĖÕi¤ßŽz¤ą¤č¤źøßĖŁ ? PCIe 4.0 x4½Ó¾A¤ĪSSD¤ņ4ĢؽӾA¤·¤Ę 256Gbps¤Ī”Óņ·ł¤ņ“_±£ ØC „Š„¤„ČQĖć¤Ē32GB/Ćė ”łĄķÕ ? NVMe-oF£ØNVMe over Fabrics£©¤Ė¤č¤ź”¢Ķā²æ „¹„Č„ģ©`„ø¤«¤éøßĖŁ¤ŹEthernet½UÓɤĒÖ±½ÓÕi ¤ßŽz¤ß¤āæÉÄÜ ØC 100GbE¤Ē¤¢¤ģ¤Š„Š„¤„ČQĖć¤Ē¼s12GB/Ćė ”łĄķÕ ”łĄķÕ¤ĻøÅĖć¤Ē¤¢¤ź”¢„ׄķ„Č„³„ė„Ŗ©`„Š©`„Ų„ƄɤŹ¤É¤ĒgĖŁ¶Č¤ĻµĶĻĀ¤·¤Ž¤¹
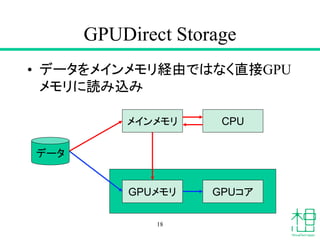
- 18. GPUDirect Storage ? „Ē©`„æ¤ņ„į„¤„ó„į„ā„ź½UÓɤĒ¤Ļ¤Ź¤ÆÖ±½ÓGPU „į„ā„ź¤ĖÕi¤ßŽz¤ß 18 „Ē©`„æ GPU„į„ā„ź GPU„³„¢ „į„¤„ó„į„ā„ź CPU
- 19. Apache Arrow¤Ė¤č¤ėÕiŽz¤Ī×īßm»Æ ? Apache ArrowŠĪŹ½¤Ļ„«„é„ą£ØĮŠ£©ÖøĻņ¤Ī„Ē©` „æ„Õ„©©`„Ž„Ć„Č ØC „¤„ó„į„ā„ź„Ē©`„æ„Ł©`„¹¤ĖĻņ¤¤¤Ę¤¤¤ė ? ¤¢¤é¤«¤ø¤į¼ÆÓ¤Ź¤É¤ņŠŠ¤¦ĮŠ¤ņ³é³ö¤·¤Ę„Ē©` „æ„Õ„”„¤„ė»Æ ØC ÕiŽzĮæ¤ņp¤é¤·¤ĘøßĖŁIĄķ ? øüŠĀ¤Ļ¤Ē¤¤Ź¤¤¤Ī¤ĒŹĖ÷IĄķ¤Ī¤ß¤ĖŹ¹ÓĆ ØC OLTPĻµDB¤Ź¤é„Ę©`„Ö„ė¤«¤éArrowŠĪŹ½¤ĖäQ ? Fluentd¤Ī³öĮ¦¤ņArrowŠĪŹ½¤Ē±£“ę ØC IoT¤Ź¤É¤Ī„·„¹„Ę„ą
- 20. GPU„„ć„Ć„·„å ? GPU„į„ā„źÉĻ¤Ė„Ē©`„æ¤ņ„„ć„Ć„·„å ØC „¹„Č„ģ©`„ø¤«¤é¤ĪÕiŽz²»ŅŖ¤Ė ØC GPU„į„ā„ź¤Ė\¤ź¤¤ė„Ē©`„愵„¤„ŗ¤ĖÓŠæ ? Tesla A100¤Ē80GB¤ĪGPU„į„ā„ź ? „į„¤„ó„į„ā„ź¤ĒOLTPIĄķ¤µ¤ģ¤Ę¤¤¤ė„Ę©`„Ö „ė„Ē©`„æ¤ņ²ī·ÖĶ¬ĘŚæÉÄÜ
- 21. PostGISévŹż¤ĪGPUź ? µŲĄķæÕégĒéó¤ņQ¤¦PostGISévŹż¤ņGPUź ØC ź¤·¤Ę¤¤¤ėévŹż¤ĻŅ»²æ¤ĪévŹż¤Ī¤ß ? PostGIS¤Ē¤Ļµć¤ä¾·Ö”¢Ēų»£Ø„Ż„ź„“„󣩤Ź¤É¤ņ „ø„Ŗ„į„Č„źŠĶ¤Č¤·¤ĘQ¤¦ ØC Ąż£ŗ¾¶Č½U¶Č¤«¤é„ø„Ŗ„į„Č„źŠĶ£Øµć£©¤ĖäQ¤Ē¤¤ė ? évŹż¤ĪĄż ØC st_contains()£ŗ„ø„Ŗ„į„Č„źa£Ø„Ż„ź„“„óµČ£©¤Ė„ø„Ŗ„į„Č„ź b£Øµć¤Ź¤É£©¤¬°üŗ¬¤µ¤ģ¤ė¤«¤ņÅŠ¶Ø ØC st_distance()£ŗ„ø„Ŗ„į„Č„źég¤Ī¾ąėx¤ņ·µ¤¹ ? GiST„¤„ó„Ē„Ć„Æ„¹ĄūÓƤĒøü¤ĖøßĖŁ»ÆæÉÄÜ
- 22. ¬FŌŚ¤Īé_°kדr ? ¬FŠŠ„Š©`„ø„ē„ó¤ĻVer3Ļµ ØC é_°k×ŌĢå¤Ļ½KĮĖ ? “ĪĘŚ„Š©`„ø„ē„óVer5Ļµ¤¬¦Į°ę„ź„ź©`„¹ ØC ÄŚ²æ„¢©`„„Ę„Æ„Į„ć¤ĪøÄÉĘ ØC DPU£ØNIC¤Ź¤É¤Ī„ׄķ„»„Ć„µ£©ź 22 https://github.com/heterodb/pg-strom
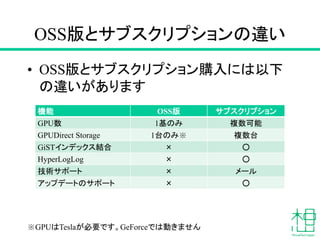
- 23. OSS°ę¤Č„µ„Ö„¹„Æ„ź„ׄ·„ē„ó¤Īß`¤¤ ? OSS°ę¤Č„µ„Ö„¹„Æ„ź„ׄ·„ē„óŁČė¤Ė¤ĻŅŌĻĀ ¤Īß`¤¤¤¬¤¢¤ź¤Ž¤¹ CÄÜ OSS°ę „µ„Ö„¹„Æ„ź„ׄ·„ē„ó GPUŹż 1»ł¤Ī¤ß Ń}ŹżæÉÄÜ GPUDirect Storage 1ĢؤĪ¤ß”ł Ń}ŹżĢØ GiST„¤„ó„Ē„Ć„Æ„¹½YŗĻ ”Į ”š HyperLogLog ”Į ”š ¼¼Šg„µ„Ż©`„Č ”Į „į©`„ė „¢„ƄׄĒ©`„ȤĪ„µ„Ż©`„Č ”Į ”š ”łGPU¤ĻTesla¤¬±ŲŅŖ¤Ē¤¹”£GeForce¤Ē¤ĻÓ¤¤Ž¤»¤ó
- 24. OSS°ęPG-Strom§Čė ? OSS°ęPG-Strom¤ĻCUDAźGPU¤¬¤¢¤ģ ¤ŠÓ×÷æÉÄÜ ØC GPUDirect Storage¤ĻTesla¤¬±ŲŅŖ ? źLinux„Ē„£„¹„Č„ź„Ó„å©`„·„ē„ó¤ĻCUDA ¤¬„µ„Ż©`„Ȥµ¤ģ¤Ę¤¤¤ė¤ā¤Ī ØC „¤„ó„¹„Č©`„ė¤Ī¤·¤ä¤¹¤µ¤«¤éRHELĻµĶĘX ? „¤„ó„¹„Č©`„ė„¬„¤„ɤĪĢį¹© ØC „Š©`„ø„ē„ó3Ļµ¤ĻĢį¹©ŹäÖŠ ØC „Š©`„ø„ē„ó5Ļµ¤ņ¬FŌŚé_°kÖŠ
- 25. »īÓĆ„ę©`„¹„±©`„¹ ? “óČŻĮæ„ķ„°¤Ī½āĪö¤Ė ØC Web„µ©`„Ó„¹µČ¤Ī„¢„Æ„»„¹„ķ„° ØC ĶØŠÅ„ķ„° ØC IoT¤Ī„»„󄵩`µČ¤Ī„ķ„° ? Ī»ÖĆĒéó·ÖĪö ØC ŅĘÓĢåĶØŠÅ„Ē„Š„¤„¹¤ĪĪ»ÖĆĒéó·ÖĪö
- 26. ±¬ĖŁDB ? ”ø±¬ĖŁDB”¹¤ĻPG-Strom¤ņ„Ł©`„¹¤Ė§Čė¤«¤éß\ ÓƤŽ¤Ē¤ņ„ļ„ó„¹„Č„Ć„×¤Ē„µ„Ż©`„Ȥ¹¤ė„Ē©`„æ·Ö Īö»ł±P„½„ź„å©`„·„ē„ó¤Ē¤¹ ? ĶĘX„Ļ©`„É„¦„§„¢³É¤ņ„Ł©`„¹¤Ė¤·¤æ„Ļ©`„É „¦„§„¢„¢„ׄ鄤„¢„󄹤ņĢį¹©¤·¤Ę¤¤¤Ž¤¹ ØC „µ„Ö„¹„Æ„ź„ׄ·„ē„ó¤Ī¤ßŁČė¤āæÉÄÜ ? ¢Ļė„Ž„·„ó¤ä„³„ó„Ę„Ź¤Ē¤ĪÓ×÷¤ā„µ„Ż©`„Ȥ· ¤Ž¤¹ ? GPU¤¬Q¤Ø¤ėø÷·N„Ƅ鄦„É„µ©`„Ó„¹¤Ė¤āź ¤·¤Ž¤¹ ØC mdx”¢¤µ¤Æ¤é¤Īøß»šĮ¦„µ©`„Š©`¤Ź¤É