






























顿叠性能の基础 DB性能高速化入門 ?基礎から列指向、GPU活用まで? 宮原 徹
- 3. 自己紹介 ? 本名:宮原 徹 ? 1972年1月 神奈川県生まれ ? 1994年3月 中央大学法学部法律学科卒業 ? 1994年4月 日本オラクル株式会社入社 – PCサーバ向けRDBMS製品マーケティングに従事 – Linux版Oracle8の日本市場向け出荷に貢献 ? 2000年3月 株式会社デジタルデザイン 東京支社長および株 式会社アクアリウムコンピューター 代表取締役社長に就任 – 2000年6月 (株)デジタルデザイン、ナスダック?ジャパン上場(4764) ? 2001年1月 株式会社びぎねっと 設立 ? 2006年12月 日本仮想化技術株式会社 設立 ? 2008年10月 IPA「日本OSS貢献者賞」受賞 ? 2009年10月 日中韓OSSアワード 「特別貢献賞」受賞 3
- 4. 日本仮想化技術株式会社 概要 ? 社名:日本仮想化技術株式会社 – 英語名:VirtualTech Japan Inc. – 略称:日本仮想化技術/VTJ ? 設立:2006年12月 ? 資本金:3,000万円 ? 売上高:1億8100万円(2022年7月期) ? 本社:東京都渋谷区渋谷1-8-1 ? 取締役:宮原 徹(代表取締役社長兼CEO) ? 伊藤 宏通(取締役CTO) ? スタッフ:11名(うち8名が仮想化技術専門エンジニアです) ? URL:http://VirtualTech.jp/ ? 仮想化技術に関する研究および開発 – 仮想化技術に関する各種調査 – 仮想化技術を導入したシステムの構築?運用サポート – 5G活用のためのインフラ?サービス研究開発 – DevOps支援サービスの提供 – GPUを活用した超高速データ分析基盤「爆速DB」の提供 ベンダーニュートラルな 独立系仮想化技術の エキスパート集団 4
- 6. DBの性能の基本 6
- 7. DBの検索性能を決定する要素 ? データの読み込み ? 検索処理 ? 集計その他の演算処理 ? 本資料はビッグデータ処理などを想定した検 索処理のみを取り上げています ? DBMS(DataBase Management System)という ブラックボックスをSQLなどで操作する観点で 解説しており、DBMSの実装によって詳細が 異なる場合があります
- 8. データの読み込み ? データはストレージからメモリに読み込んで処理 ? ストレージの読み込み速度とは – ストレージ自体の速度 – 接続経路の速度 ? ストレージ自体の速度 – IOPSや読み書き速度(○MB/秒)などで表される – HDDならプラッターサイズや回転速度が影響 – SSDならシリコンやコントローラー速度が影響 ? 接続経路の速度 – SATAやSAS、NVMe(PCI Expressバス直結) – SATA(6Gbps)<SAS(12Gbps)<NVMe(64Gbps) ※ ? NVMeはPCIe 4.0のx4レーンを想定 ※理論値であり、プロトコルオーバーヘッドなどで実速度は低下します データ メインメモリ CPU
- 9. 接続種類 帯域 主な用途 SATA 6Gbps 一般的なPC SAS 12Gbps サーバー 専用ストレージ NVMe 64Gbps (PCI-Express 4.0) 最近のPC ストレージの接続経路と速度
- 10. 検索処理 ? メモリに読み込んだデータをCPUで処理 ? WHERE句による条件一致処理 – IN演算子やLIKE演算子などの処理を含む – インデックスが使われない場合には全件検索 – 副問い合わせによる条件値の抽出 ? JOIN句による表結合処理 ? SELECT選択リストによるデータの抽出 データ メインメモリ CPU
- 11. 集計その他の演算処理 ? 検索処理されたデータに対する追加処理 – CPUとメモリを使って処理 ? ソート処理 ? GROUP BY句による集約 ? 集約関数による各種集計処理 – COUNT関数など 演算処理を行った結果をアプリに返す
- 12. DBの性能を向上させるには 12
- 13. データベース性能向上の方法 ? ストレージの読み込みを速くする ? ハードウェアの改善など ? データの所在を明らかにする ? インデックスの利用 ? パーティショニング ? 検索処理や演算処理を速くする ? CPUやメモリ、ストレージを増やす ? 単体性能を向上させるスケールアップ ? 処理を分散させるスケールアウト
- 14. データの読み込みを速くする ? より高速なストレージデバイスを使用する – HDDよりSSD – SATA<SAS<NVMe – FibreChannelやiSCSIで接続経路を広帯域化 ? デバイスを複数用意する – RAID 0(ストライピング)化 ? 必要なデータだけ読み込むことで読み込み量を減らす – インデックスの活用 – カラム(列)指向データベース ? 最初からメモリ(バッファ)に読み込んでおく – インメモリデータベース
- 15. データの所在を明らかにする ? データの在処が分からなければ全件検索するしかない – 読み込みに時間がかかる – メモリが大量に必要となる ? インデックスを利用してデータの所在を明らかにする ? インデックスも万能ではない – データ件数が少ない – カーディナリティが低い(「0か1か」など取る値の種類が少 ない) ? パーティショニングでデータを分割する ? カラム(列)志向データベースの利用 – 抽出したい列が決まっている場合
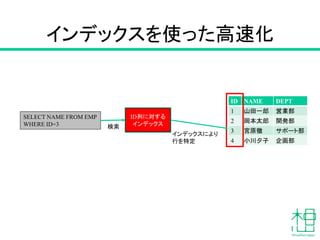
- 16. ID NAME DEPT 1 山田一郎 営業部 2 岡本太郎 開発部 3 宮原徹 サポート部 4 小川夕子 企画部 SELECT NAME FROM EMP WHERE ID=3 ID列に対する インデックス 検索 インデックスにより 行を特定 インデックスを使った高速化
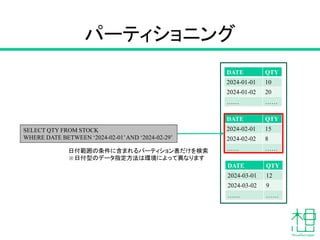
- 17. DATE QTY 2024-01-01 10 2024-01-02 20 …… …… DATE QTY 2024-02-01 15 2024-02-02 8 …… …… DATE QTY 2024-03-01 12 2024-03-02 9 …… …… SELECT QTY FROM STOCK WHERE DATE BETWEEN ‘2024-02-01’AND ‘2024-02-29’ 日付範囲の条件に含まれるパーティション表だけを検索 ※日付型のデータ指定方法は環境によって異なります パーティショニング
- 18. 検索処理や演算処理を速くする 1台を高速化するスケールアップ ? CPUコアのクロック数を高速化する – プロセスルールの微細化の限界と発熱の制限 ? CPUコア数を増やす – ダイサイズによる実装可能コア数の制限 – マルチプロセスやマルチスレッドで活用 複数台で高速化するスケールアウト ? 台数を増やしてクラスター化する – 複数台利用によるコストの増加 – 管理やトラブル解決の煩雑さ
- 21. 中間まとめ:DB検索が遅くなる要因 ? ストレージの速度が遅い ? データの量が多い ? CPUが遅い(クロック数?コア数) ? メモリが少ない ? インデックスが適切に使われていない ? 処理が複雑(副問い合わせや集計処理)
- 23. PG-Stromの高速化手法 ? PG-StromはPostgreSQLを拡張?高速化 – GPUによる超並列処理 – GPUDirect Storageによるデータ高速読込 – Apache Arrowによるデータ読込の最適化 ? 通常は遅くなる処理を高速化 – インデックスが効かないフルスキャン検索 – ビッグデータの集計処理 – 位置情報データの検索処理
- 24. GPUによる超並列処理 ? CPUとGPUのコア数に大きな違い – 現在のサーバー用CPUがプロセッサあたり最 大48コアから96コア – 現在のエンタープライズ用GPUが約5000コア ? データの検索処理や集計処理を並列化 – より多くのコアで超並列処理 – 単純な処理ほど並列化に向いている ? 計算機は条件分岐などの複雑な処理が苦手
- 25. GPUDirect Storageによる高速読込 ? NVMe接続されたストレージからGPUのメモリ に対して直接データを読み込む技術 – メインメモリ経由でGPUメモリに読み込むより高速 ? PCIe 4.0 x4接続のSSDを4台接続して 256Gbpsの帯域幅を確保 – バイト換算で32GB/秒 ※理論値 ? NVMe-oF(NVMe over Fabrics)により、外部 ストレージから高速なEthernet経由で直接読 み込みも可能 – 100GbEでバイト換算で約12GB/秒 ※理論値 ※理論値は概算値であり、プロトコルオーバーヘッドなどで実速度は低下します
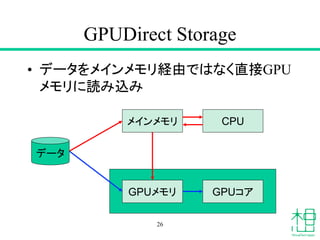
- 26. GPUDirect Storage ? データをメインメモリ経由ではなく直接GPU メモリに読み込み 26 データ GPUメモリ GPUコア メインメモリ CPU
- 27. Apache Arrowによる読込の最適化 ? Apache Arrow形式はカラム(列)指向のデー タフォーマット – インメモリデータベースに向いている ? あらかじめ集計などを行う列を抽出してデー タファイル化 – 読込量を減らして高速処理 ? 更新はできないので検索処理のみに使用 – OLTP系DBならテーブルからArrow形式に変換 ? Fluentdの出力をArrow形式で保存 – IoTなどのシステム
- 28. GPUキャッシュ ? GPUメモリ上にデータをキャッシュ – ストレージからの読込不要に – GPUメモリに乗りきるデータサイズに有効 ? Tesla A100で80GBのGPUメモリ ? メインメモリでOLTP処理されているテーブ ルデータを差分同期可能
- 29. PostGIS関数のGPU対応 ? 地理空間情報を扱うPostGIS関数をGPU対応 – 対応している関数は一部の関数のみ ? PostGISでは点や線分、区画(ポリゴン)などを ジオメトリ型として扱う – 例:緯度経度からジオメトリ型(点)に変換できる ? 関数の例 – st_contains():ジオメトリa(ポリゴン等)にジオメトリ b(点など)が包含されるかを判定 – st_distance():ジオメトリ間の距離を返す ? GiSTインデックス利用で更に高速化可能
- 30. 現在の開発状況 ? 新版バージョンVer5系が正式リリース – 内部アーキテクチャの改善 – DPU(NICなどのプロセッサ)対応 30 https://github.com/heterodb/pg-strom
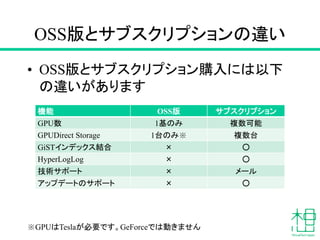
- 31. OSS版とサブスクリプションの違い ? OSS版とサブスクリプション購入には以下 の違いがあります 機能 OSS版 サブスクリプション GPU数 1基のみ 複数可能 GPUDirect Storage 1台のみ※ 複数台 GiSTインデックス結合 × ○ HyperLogLog × ○ 技術サポート × メール アップデートのサポート × ○ ※GPUはTeslaが必要です。GeForceでは動きません
- 32. OSS版PG-Strom導入 ? OSS版PG-StromはCUDA対応GPUがあれ ば動作可能 – GPUDirect StorageはTeslaが必要 ? 対応LinuxディストリビューションはCUDA がサポートされているもの – インストールのしやすさからRHEL系推奨 ? インストールガイドを提供
- 33. 爆速DB ? 「爆速DB」はPG-Stromをベースに導入から運 用までをワンストップでサポートするデータ分 析基盤ソリューションです ? 推奨ハードウェア構成をベースにしたハード ウェアアプライアンスを提供しています – サブスクリプションのみ購入も可能 ? 仮想マシンやコンテナでの動作もサポートし ます ? GPUが扱える各種クラウドサービスにも対応 します – mdx、さくらの高火力サーバーなど
- 34. 活用ユースケース ? 大容量ログの解析に – Webサービス等のアクセスログ – 通信ログ – IoTのセンサー等のログ ? 位置情報分析 – 移動体通信デバイスの位置情報分析
- 36. ありがとうございました 36