Deconstructing Popularity Bias in Recommender Systems_ Origins, Impacts, and Mitigation
0 likes89 views

Presentation of the talk given by Amit Jaspal on popularity bias in Trust & Responsibility in Recommendation Systems Workshop WSDM 2025












![References
[1] Abdollahpouri, H., Mansoury, M.: Multi-sided exposure bias in recommendation. In: Proceedings of the International Workshop on Industrial
Recommendation Systems in conjunction with ACM KDD 2020 (2020)
[2]Banerjee, A., Patro, G.K., Dietz, L.W., Chakraborty, A.: Analyzing ÔÇÿnear meÔÇÖ services: potential for exposure bias in location-based retrieval.
In: 2020 IEEE International Conference on Big Data, pp. 3642ÔÇô3651(2020)
[3]Boratto, L., Fenu, G., Marras, M.: Connecting user and item perspectives in popularity debiasing for collaborative recommendation. Inf.
Process. Manag. 58(1), 102387 (2021)
[4]Channamsetty, S., Ekstrand, M.D.: Recommender response to diversity and popularity bias in user profiles.In: Proceedings of the 13th
International FLAIRS Conference, pp. 657ÔÇô660 (2017)
[5] Chen, J., Dong, H., Wang, X., Feng, F., Wang, M., He, X.: Bias and debias in recommender system: a survey and future directions. ACM
Trans. Inf. Syst. 31, 1ÔÇô39 (2020)
[6] Deldjoo, Y., Bellogin, A., Di Noia, T.: Explaining recommender systems fairness and accuracy through the lens of data characteristics. Inf.
Process. Manag. 58(5), 102662 (2021)
[7] Yalcin, E., Bilge, A.: Investigating and counteracting popularity bias in group recommendations. Inf. Pro-cess. Manag. 58(5), 102608 (2021)
[8] Yang, Y., Huang, C., Xia, L., Huang, C., Luo, D., Lin, K.: Debiased contrastive learning for sequential recommendation. In: Proceedings of
the ACM Web Conference 2023, WWW ÔÇÖ23, pp. 1063ÔÇô1073 (2023b)
[9] Zanon, A.L., da Rocha, L.C.D., Manzato, M.G.: Balancing the trade-off between accuracy and diversity in recommender systems with
personalized explanations based on linked open data. Knowl. Based Syst. 252, 109333 (2022)](https://image.slidesharecdn.com/deconstructingpopularitybiasinrecommendersystemsoriginsimpactsandmitigation1-250328182220-f568fddc/85/Deconstructing-Popularity-Bias-in-Recommender-Systems_-Origins-Impacts-and-Mitigation-14-320.jpg)
Deconstructing Popularity Bias in Recommender Systems_ Origins, Impacts, and Mitigation
- 1. Deconstructing Popularity Bias in Recommender Systems: Origins, Impacts, and Mitigation Amit Jaspal Trust & Responsibility in Recommendation Systems, WSDM 2025
- 2. AmitÔÇÖs Introduction ÔùÅ Thank you for the opportunity to speak ! ÔùÅ Engineering Manager and Research Scientist at Meta leading ecommerce recommendations team ÔùÅ Building recommender and information systems in Industry for the last 14 years Ôùï Ecommerce recommendations at Meta Ôùï Video recommendations at Meta Ôùï Ads recommendations at Meta Ôùï Newsfeed recommendations at Linkedin Ôùï Apace SOLR at Cloudera Ôùï Hurricane search engine in D.E.Shaw ÔùÅ Research fellow at NCSA and TDIL Labs Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 3. What is Popularity Bias? ÔùÅ Popularity bias refers to the tendency of a recommender system to over-recommend popular items at the expense of less popular ones. In other words, already-popular items get disproportionate exposure, while long-tail items are under-represented. ÔùÅ Not a unique problem to recommender systems, but dynamic nature of recommender system makes it worse. ÔùÅ Examples of Popularity Bias in other domains Ôùï Academic Research/Citations Ôùï Financial Markets/Stock Trading Ôùï Book Publishing/Best Seller Lists Ôùï Hiring and Job Portals Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
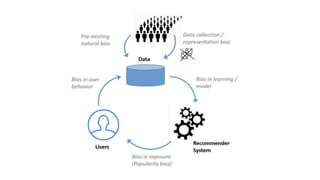
- 4. Sources of Popularity Bias in Recommender Systems ÔùÅ Inherent Audience Size Imbalance (Data Bias): Ôùï Some items are naturally more appealing to a broader audience. Ôùï Item popularity often follows a long-tail distribution inherently. Ôùï Even bias-free algorithms will see more interactions with these items. ÔùÅ Model Bias (Algorithmic Bias): Ôùï Machine learning models learn patterns from training data, including existing popularity biases. Ôùï Collaborative filtering and similar methods tend to amplify popularity signals. Ôùï Models may over-generalize from popular item interactions, leading to biased predictions. ÔùÅ Closed Feedback Loop (Systemic Bias): Ôùï Dynamic recommendation systems operate in a closed loop. Ôùï Recommendations influence user interactions, which become training data for future models. Ôùï This creates a feedback loop that can accumulate and exacerbate popularity bias over time. Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 6. Why Does Popularity Bias Matter? ÔùÅ For Users: Ôùï Reduced novelty and serendipity - Recommendations become predictable and less engaging. Ôùï Limited personalization - May not discover items truly aligned with individual preferences, especially niche interests. Ôùï Decreased user satisfaction and trust in the system over time. ÔùÅ For Item Providers (Especially Long-Tail): Ôùï Reduced visibility and sales opportunities for less popular items. Ôùï Unfair competition - Popular items dominate, regardless of quality or relevance to specific users e.g click baits Ôùï Item side cold start problem. ÔùÅ System-Level: Ôùï Reinforcement loops - Bias can worsen over time due to feedback cycles. Ôùï System behaves suboptimally catering only to popular items on one side and users who are ok with engagement w/ only popular items. Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 7. Measuring Popularity Bias ÔùÅ Gini Coefficient Ôùï Statistical measure of inequality within a distribution, computed using Lorenz Curve Ôùï Lorenz Curve is a graphical representation of inequality, showing the cumulative distribution of a resource (e.g., wealth, recommendation exposure) across a population. Ôùï Gini Index can be computed as the area between the Lorenz Curve and the Line of Equality ÔùÅ Recall breakdown by item set bucket e.g recall@k for head items, recall@k for tail items Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 8. Mitigation Strategies ÔùÅ Key Mitigation Goals: Ôùï Promote long-tail item visibility. Ôùï Improve fairness and diversity. Ôùï Maintain or improve recommendation accuracy (or minimize accuracy loss). ÔùÅ Categorization by Processing Stage: Ôùï Pre-processing: Modify training data before model training. Ôùï In-processing (Modeling): Integrate debiasing directly into the model training process. Ôùï Post-processing: Adjust recommendation lists after model prediction. Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 9. Mitigation Strategies - Pre & Post-processing ÔùÅ Pre-processing Ôùï Data Sampling: Down-sample popular item interactions or up-sample long-tail item interactions. Ôùï Item Exclusion: Remove highly popular items from the training data or candidate pool (use with caution). Ôùï Balanced Dataset Creation: Aim for a more uniform distribution of item interactions in training data. Ôùï Data Augmentation: Enrich data with side information to provide more context beyond popularity. ÔùÅ Post-processing Ôùï Re-scaling (Score Adjustment): Adjust predicted scores based on item popularity. Ôùï Re-ranking: Re-order the initial ranked list to promote less popular items. Ôùï Rank Aggregation / Slotting: Combine rankings from biased and debiased models. Ôùï Post-filtering: Remove top-k popular items from the final recommendation list. Ôùï False Positive Correction (FPC): Correct scores probabilistically based on past unclicked recommendations Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 10. Mitigation Strategies - In-processing (Model-Level) ÔùÅ Causal Inference Methods: Ôùï Counterfactual reasoning - Estimate recommendations without popularity influence. Ôùï Model ranking as cause-and-effect relationship to disentangle popularity and user preference ÔùÅ Reducing Memorization Ôùï Remove ID features or add large dropouts Ôùï Metadata based feature to improve generalization ÔùÅ Re-weighting Approaches: Ôùï Adjust item weights during training to balance popular and unpopular items. Ôùï Inverse Propensity Scoring (IPS) - Weight items inversely proportional to their popularity. ÔùÅ Regularization-based Approaches: Ôùï Add regularization terms to the loss function to penalize popularity bias. Ôùï Encourage models to learn from less popular items. Ôùï Examples: Popularity-aware regularization, information neutrality regularization. . Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 11. Evaluation and Datasets ÔùÅ Offline Evaluation (Dominant Approach): Ôùï Static Split: Train/test split on historical data (snapshot view). Ôùï Dynamic/Longitudinal Split: Simulate dynamic system evolution over time. Ôùï Metrics: Combine accuracy metrics (NDCG, Recall) with bias-related metrics (Gini, Coverage). ÔùÅ Online Evaluation (User Studies, A/B Tests): Ôùï A/B tests: Deploy debiasing methods in real-world systems and measure user behavior (clicks, engagement). Ôùï User studies: Gather user perceptions, subjective feedback on debiased recommendations. Ôùï More resource-intensive but crucial for real-world validation. ÔùÅ Datasets Ôùï MovieLens, LastFM, BookCrossing etc. - Widely used Ôùï All exhibit skewed popularity distributions but vary in size, density, and bias levels. Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 12. Challenges in Addressing Popularity Bias ÔùÅ Accuracy vs. fairness trade-off Ôùï Reducing popularity can come at a cost of user experience (especially short term) Ôùï Careful tuning of parameters to manage tradeoff is critical ÔùÅ Defining fairness goals Ôùï what a fair distribution of recommendations remains unclear ? ÔùÅ Measurement Ôùï Pre-test vs post launch inconsistency in metrics because of feedback loop based training data ÔùÅ Lack of multi-stakeholder evaluation of recommender systems in A/B tests. ÔùÅ Lack of measurement of long term metrics e.g retention vs short term metrics e.g clicks and watch time Trust & Responsibility in Recommendation Systems Workshop WSDM 2025
- 14. References [1] Abdollahpouri, H., Mansoury, M.: Multi-sided exposure bias in recommendation. In: Proceedings of the International Workshop on Industrial Recommendation Systems in conjunction with ACM KDD 2020 (2020) [2]Banerjee, A., Patro, G.K., Dietz, L.W., Chakraborty, A.: Analyzing ÔÇÿnear meÔÇÖ services: potential for exposure bias in location-based retrieval. In: 2020 IEEE International Conference on Big Data, pp. 3642ÔÇô3651(2020) [3]Boratto, L., Fenu, G., Marras, M.: Connecting user and item perspectives in popularity debiasing for collaborative recommendation. Inf. Process. Manag. 58(1), 102387 (2021) [4]Channamsetty, S., Ekstrand, M.D.: Recommender response to diversity and popularity bias in user profiles.In: Proceedings of the 13th International FLAIRS Conference, pp. 657ÔÇô660 (2017) [5] Chen, J., Dong, H., Wang, X., Feng, F., Wang, M., He, X.: Bias and debias in recommender system: a survey and future directions. ACM Trans. Inf. Syst. 31, 1ÔÇô39 (2020) [6] Deldjoo, Y., Bellogin, A., Di Noia, T.: Explaining recommender systems fairness and accuracy through the lens of data characteristics. Inf. Process. Manag. 58(5), 102662 (2021) [7] Yalcin, E., Bilge, A.: Investigating and counteracting popularity bias in group recommendations. Inf. Pro-cess. Manag. 58(5), 102608 (2021) [8] Yang, Y., Huang, C., Xia, L., Huang, C., Luo, D., Lin, K.: Debiased contrastive learning for sequential recommendation. In: Proceedings of the ACM Web Conference 2023, WWW ÔÇÖ23, pp. 1063ÔÇô1073 (2023b) [9] Zanon, A.L., da Rocha, L.C.D., Manzato, M.G.: Balancing the trade-off between accuracy and diversity in recommender systems with personalized explanations based on linked open data. Knowl. Based Syst. 252, 109333 (2022)