



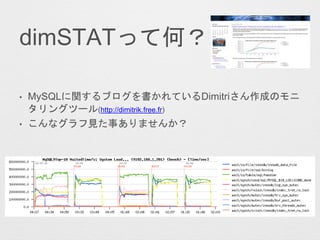


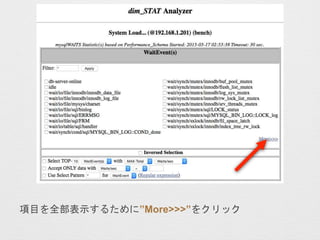
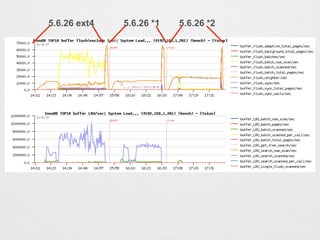
![? ÉĻĪ»10¼ž¤Ī¤ß±ķŹ¾¤¹¤ė¤æ¤į Select TOP-[10]¤Ė„Į„§„Ć„Æ
? ½g¤źŽz¤ß¤æ¤¤„Ń„æ©`„ó¤Č¤·¤Ę wait/synch/* ¤ņČėĮ¦¤·
Use Select Pattern ¤Ė„Į„§„Ć„Æ](https://image.slidesharecdn.com/myna-201508dimstat-ppt-150830031103-lva1-app6892/85/dimSTAT-13-320.jpg)


























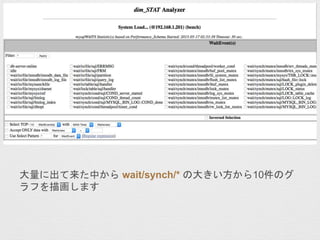
![fio + perf + Flame Graphs
? gŠŠ„³„Ž„ó„É
? perf record -a -g -F100000 /usr/bin/fio --name=ӨtestӮ
--readwrite=randwrite --blocksize=4k --size=32m
--filename=/var/lib/mysql/fio/fiotest --direct=1 --numjobs=16
--group_reporting
? 1¤Ä¤Ī„Õ„”„¤„ė¤Ė¤·¤Ę16„ׄķ„»„¹¤Ē¤½¤ģ¤¾¤ģ32MB¤Īų¤Žz¤ß
¤ņO_DIRECT¤ĒŠŠ¤¤¤Ž¤¹
? Flame Graphs¤Ī×÷³É
? perf script > perf_data.txt
? stackcollapse-perf.pl perf_data.txt | flamegraph.pl --title ”°[„愤
„Č„ėĆū]”± > [„Õ„”„¤„ėĆū].svg
? ²Īæ¼: perf + Flame Graphs ¤Ē Linux „«©`„Ķ„ėÄŚ¤Ī„Ü„Č„ė„Ķ„Ć„Æ¤ņĢŲ¶Ø¤¹¤ė
(http://d.hatena.ne.jp/yohei-a/20150706/1436208007)](https://image.slidesharecdn.com/myna-201508dimstat-ppt-150830031103-lva1-app6892/85/dimSTAT-58-320.jpg)








»å¾±³¾³§°Õ“”°Õ¤«¤é¼ū¤ė„Ł„ó„Į„Ž©`„Æ
- 2. ×Ō¼ŗ½B½é ? ¤¤¤Č¤¦ ¤Ņ¤ķ¤ę¤ ? „µ©`„Šß\ÓĆ/±£ŹŲ¤¬ŹĖŹĀ ? „Ķ„Ć„Č„ļ©`„Ƥ«¤éOS”¢„ß„É„ė„¦„§„¢¤Ž¤Ē„¢„ׄź„±©`„·„ē„ó ŅŌĶā¤ĻŗĪ¤Ē¤āĆęµ¹¤ņŅ¤Ž¤¹(³Ģ¶Č¤Ī²ī¤Ļ¤¢¤ź¤Ž¤¹) ? MySQLŗƤ”¢¾ĘŗƤ
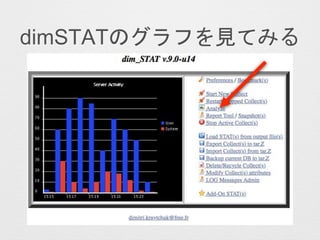
- 4. ¤Ŗī} ? dimSTAT¤Ć¤ĘŗĪ£æ ? dimSTAT¤Īŗ g¤ŹŹ¹¤¤·½ ? »å¾±³¾³§°Õ“”°Õ¤Ī„°„é„Õ¤ņ¼ū¤Ę¤ß¤ė ? »å¾±³¾³§°Õ“”°Õ¤«¤é¼ū¤ė„Ł„ó„Į„Ž©`„Æ
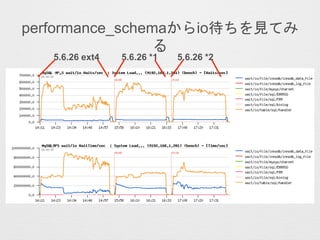
- 6. ? MySQL¤Īperformance_schema¤Ėév¤¹¤ė„°„é„Õ¤āÉś³ÉæÉÄÜ (wait¤Ė½j¤ąĪļ) ²Īæ¼1: http://dev.mysql.com/doc/refman/5.6/ja/wait-summary-tables.html ²Īæ¼2: http://dev.mysql.com/doc/refman/5.6/ja/performance-schema-instrument- naming.html ? events_waits_summary_global_by_event_name„Ę©`„Ö„ė¤«¤é Ēéó¤ņČ”µĆ ? COUNT_STAR¤ČSUM_TIMER_WAIT ? ¤½¤ĪĖū„ā„Ė„æ„ź„ó„°„Ä©`„ė(Cacti, munin¤Č¤«)¤ĒĖŹ¤Ē §¼Æ³öĄ“ ¤ėĪļ¤Ļ¤Ą¤¤¤æ¤¤ §¼ÆæÉÄÜ ? „¤„ó„¹„Č©`„ė·½·Ø¤Ė¤Ä¤¤¤Ę¤Ļ¤Ļ¤Ę„Ą¤ĖŅŌĒ°ų¤¤¤æ¤Ī¤ĒŹ¹¤Ć¤Ę¤ß¤æ ¤¤·½¤Ļ²Ī漤Ė¤·¤ĘĻĀ¤µ¤¤ (http://d.hatena.ne.jp/hiroi10/20150523/1432345143)
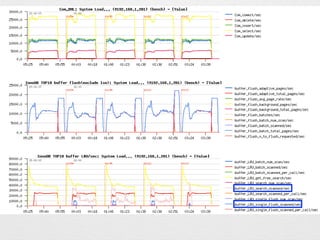
- 13. ? ÉĻĪ»10¼ž¤Ī¤ß±ķŹ¾¤¹¤ė¤æ¤į Select TOP-[10]¤Ė„Į„§„Ć„Æ ? ½g¤źŽz¤ß¤æ¤¤„Ń„æ©`„ó¤Č¤·¤Ę wait/synch/* ¤ņČėĮ¦¤· Use Select Pattern ¤Ė„Į„§„Ć„Æ
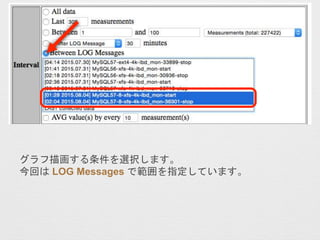
- 14. „°„é„ÕĆ軤¹¤ėĢõ¼ž¤ņßxk¤·¤Ž¤¹”£ ½ń»Ų¤Ļ LOG Messages ¤Ē·¶ģ¤ņÖø¶Ø¤·¤Ę¤¤¤Ž¤¹”£
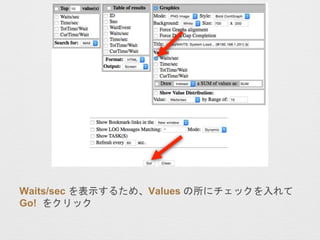
- 15. Waits/sec ¤ņ±ķŹ¾¤¹¤ė¤æ¤į”¢Values ¤ĪĖł¤Ė„Į„§„Ć„Æ¤ņČė¤ģ¤Ę Go! ¤ņ„Æ„ź„Ć„Æ
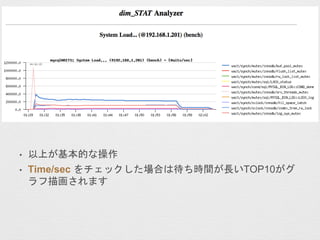
- 16. ? ŅŌÉĻ¤¬»ł±¾µÄ¤Ź²Ł×÷ ? Time/sec ¤ņ„Į„§„Ć„Æ¤·¤æöŗĻ¤Ļ“ż¤Įrég¤¬éL¤¤TOP10¤¬„° „é„ÕĆ軤µ¤ģ¤Ž¤¹
- 17. dimSTAT¤Īŗ g¤ŹŹ¹¤¤·½ 1. „¤„ó„¹„Č©`„ė 2. Č”µĆ¤·¤æ¤¤„µ©`„Š¤ĪµĒåh 3. Č”µĆé_Ź¼ 4. „Ł„ó„Į„Ž©`„Æ¤Č¤«gŠŠ 5. Ķ£Ö¹ 6. „°„é„Õ¤ņŅ¤ė(Č”µĆÖŠ¤āæÉ)
- 18. dimSTATĄūÓĆr¤ĪŌO¶Ø ? my.cnf¤ĖŅŌĻĀŌO¶Ø¤ņŠŠ¤¦ŹĀ¤¬ĶĘX¤Č¤Ź¤ź¤Ž¤¹ ? performance_schema = ON (5.6, 5.7¤Ź¤é„Ē„Õ„©„ė„ȤĒON) ? performance_schema_instrument=”®%sync%=on' ? innodb_monitor_enable = 'all'
- 19. „Ē„ā
- 21. „Ł„ó„Į„Ž©`„Æh¾³ ? HP DL360p G8v2 („Ł„ó„Į„Ž©`„Æ„µ©`„Š) ? CPU Intel Xeon E5-2643 v2 @ 3.50GHz x 2(1CPU = 6Core) ? MEM 8GB x 8 = 64GB ? ioDrive2 785GB ? Driver version: 3.2.6 build 1212, Firmware v7.1.15, rev 110356 Public ? NIC Intel I350 ? OS CentOS 6.6(2.6.32-504.12.2.el6.x86_64)
- 22. ? HP DL360 G7(„Ł„ó„Į„Ž©`„ƄƄ鄤„¢„ó„Č) ? CPU Intel Xeon L5640 @ 2.27GHz (2CPU = 6Core x 2) ? MEM 4GB x 12 = 48GB ? NIC Broadcom NetXtreme II BCM5709 ? OS CentOS 5.9 (2.6.18-348.16.1.el5)
- 23. ? MySQL „Š©`„ø„ē„ó(RPM°ęŹ¹ÓĆ) ? 5.7.8 RC ¼°¤Ó 5.6.26 ? „Ł„ó„Į„Ž©`„Æ„Ä©`„ė ? LinkBench ? „Ē©`„æĮæ 218GB FBWorkload.properties¤Ēmaxid1 = 200000001 ? „Õ„”„¤„ė„·„¹„Ę„ą ? xfs, ext4 „Ž„¦„ó„Č„Ŗ„ׄ·„ē„ó: defaults,nobarrier,discard
- 24. ÓyÄŚČŻ 1. »ł±¾MySQL¤ĻĶ¬¤øŌO¶Ø Ī“ŌO¶Ø¤Ė¤č¤ė„Ē„Õ„©„ė„ȤĻĻó„Š©`„ø„ē„óŹ 2. MySQL 5.7, 5.6¤½¤ģ¤¾¤ģ¤Ēxfs, ext4¤Ē„Ł„ó„Į„Ž©`„ƤņgŹ© 3. LinkBench¤ĪĢõ¼ž¤Ļ„ź„Æ„Ø„¹„ČŹż¤Ī¤ßÖø¶Ø ? ./bin/linkbench -c config/MyConfig.properties -D requests=600000 -r ? „ź„Æ„Ø„¹„ČŹż¤Ī„Ē„Õ„©„ė„ȤĻ1000000 ? „¹„ģ„Ć„ÉŹż¤Ī„Ē„Õ„©„ė„ȤĻ100
- 25. „Ż„¤„ó„ȤȤŹ¤ė„Ń„é„į©`„æ ? innodb_io_capacity = 18000 ? innodb_io_capacity_max = 23000 ? innodb_log_file_size = 1G ? innodb_log_files_in_group =16 (default 2) ? innodb_buffer_pool_instances = 23 (default 8) ? innodb_buffer_pool_size = 46G ? innodb_lru_scan_depth = 6000 (default 1024) ? innodb_page_size = 4k (default 16k) ? innodb_adaptive_flushing = 1 (default 1)
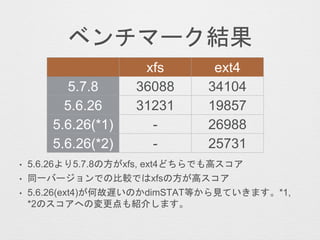
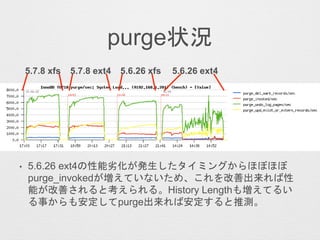
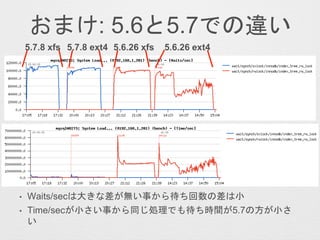
- 26. „Ł„ó„Į„Ž©`„ƽY¹ū ? 5.6.26¤č¤ź5.7.8¤Ī·½¤¬xfs, ext4¤É¤Į¤é¤Ē¤āøß„¹„³„¢ ? Ķ¬Ņ»„Š©`„ø„ē„ó¤Ē¤Ī±ČŻ^¤Ē¤Ļxfs¤Ī·½¤¬øß„¹„³„¢ ? 5.6.26(ext4)¤¬ŗĪ¹ŹßW¤¤¤Ī¤«dimSTATµČ¤«¤éŅ¤Ę¤¤¤¤Ž¤¹”£*1, *2¤Ī„¹„³„¢¤Ų¤Īäøüµć¤ā½B½é¤·¤Ž¤¹”£ xfs ext4 5.7.8 5.6.26 5.6.26(*1) 5.6.26(*2)
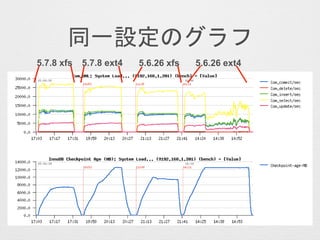
- 27. Ķ¬Ņ»ŌO¶Ø¤Ī„°„é„Õ 5.7.8 xfs 5.7.8 ext4 5.6.26 ext45.6.26 xfs
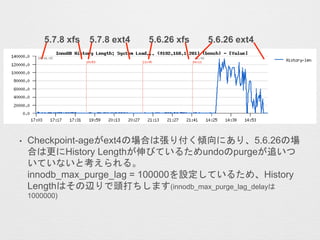
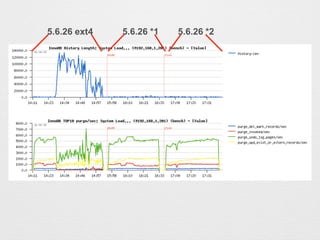
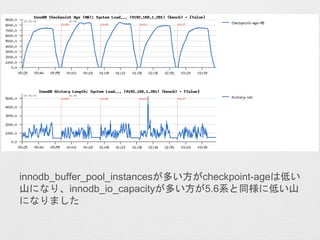
- 28. ? Checkpoint-age¤¬ext4¤ĪöŗĻ¤Ļ¤źø¶¤ÆAĻņ¤Ė¤¢¤ź”¢5.6.26¤Īö ŗĻ¤Ļøü¤ĖHistory Length¤¬Éģ¤Ó¤Ę¤¤¤ė¤æ¤įundo¤Īpurge¤¬×·¤¤¤Ä ¤¤¤Ę¤¤¤Ź¤¤¤Č漤ؤé¤ģ¤ė”£ innodb_max_purge_lag = 100000¤ņŌO¶Ø¤·¤Ę¤¤¤ė¤æ¤į”¢History Length¤Ļ¤½¤ĪŽx¤ź¤Ēī^“ņ¤Į¤·¤Ž¤¹(innodb_max_purge_lag_delay¤Ļ 1000000) 5.7.8 xfs 5.7.8 ext4 5.6.26 ext45.6.26 xfs
- 29. ? 5.6.26 ext4¤ĪŠŌÄÜĮӻƤ¬°kÉś¤·¤æ„愤„ß„ó„°¤«¤é¤Ū¤Ü¤Ū¤Ü purge_invoked¤¬¤Ø¤Ę¤¤¤Ź¤¤¤æ¤į”¢¤³¤ģ¤ņøÄÉĘ³öĄ“¤ģ¤ŠŠŌ Äܤ¬øÄÉʤµ¤ģ¤ė¤Č漤ؤé¤ģ¤ė”£History Length¤ā¤Ø¤Ę¤ė¤¤ ¤ėŹĀ¤«¤é¤ā°²¶Ø¤·¤Ępurge³öĄ“¤ģ¤Š°²¶Ø¤¹¤ė¤ČĶĘy”£ 5.7.8 xfs 5.7.8 ext4 5.6.26 ext45.6.26 xfs purgeדr
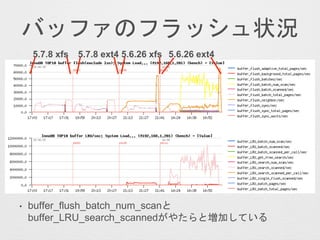
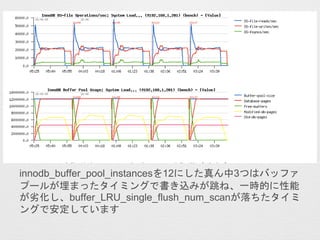
- 30. „Š„Ć„Õ„”¤Ī„Õ„é„Ć„·„åדr ? buffer_flush_batch_num_scan¤Č buffer_LRU_search_scanned¤¬¤ä¤æ¤é¤Č¼Ó¤·¤Ę¤¤¤ė 5.7.8 xfs 5.7.8 ext4 5.6.26 ext45.6.26 xfs
- 31. ? ./storage/innobase/srv/srv0mon.cc ¤«¤é„³„į„ó„Či» ? purge_del_mark_records ? Number of delete-marked rows purged ? purge_invoked ? Number of times purge was invoked ? purge_undo_log_pages ? Number of undo log pages handled by the purge ? purge_upd_exist_or_extern_records ? Number of purges on updates of existing records and updates on delete marked record with externally stored field ? buffer_flush_batch_num_scan ? Number of times buffer flush list flush is called ? buffer_LRU_search_scanned ? Total pages scanned as part of LRU search
- 32. 2„Ń„æ©`„ó¤Īź 1. innodb_io_capacity, innodb_io_capacity_max¤ņO¶Ė¤Ė¤ä¤·¤Ę¤ß¤ė ? innodb_io_capacity = 55000 ? innodb_io_capacity_max = 60000 ? ²Īæ¼: 14.13.8. InnoDB „Ž„¹„æ©`„¹„ģ„ƄɤĪ I/O „ģ©`„ȤĪ³É (http://dev.mysql.com/doc/refman/5.6/ja/innodb-performance-thread_io_rate.html) 2. innodb_log_file_in_group¤ņp¤é¤·”¢redo„ķ„°¤Ī¾tĮæ¤ņŠ”¤µ¤Æ¤¹¤ėŹĀ ¤Ē°²¶Ø¤·¤ĘSharp Checkpoint¤¬°kÉś¤¹¤ė¤č¤¦¤Ė¤¹¤ė (°kÉś¤¹¤ėio¤ņĘ½¾łµÄ¤Ė¤·¤Ę¤·¤Ž¤¦) ? innodb_log_file_in_group = 3(ŗĻÓ¤Ē3GB) ? ²Īæ¼: ¤³¤ģ¤Ą¤±¤ß¤ģ¤Š“óÕÉ·ņ Cacti ¤Ė¤č¤ėMySQL„Ń„Õ„©©`„Ž„ó„¹±OŅ¤Ī„Ä „Ü (http://www.slideshare.net/nobuhatano/osc2015-my-sqlr3)
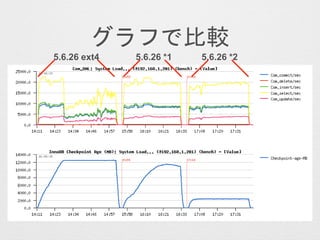
- 33. „°„é„Õ¤Ē±ČŻ^ 5.6.26 ext4 5.6.26 *25.6.26 *1
- 34. 5.6.26 ext4 5.6.26 *25.6.26 *1
- 35. 5.6.26 ext4 5.6.26 *25.6.26 *1
- 36. ? innodb_io_capacity¤¬55000¤ĪöŗĻ”¢checkpoint-age¤Ļ¤źø¶ ¤«¤ŗ”¢ŠŌÄܤĻ°²¶Ø”£innodb_log_file_in_group¤ņäøü¤·¤æöŗĻ ¤Ļcheckpoint-age¤Ļ¤źø¶¤Æ¤¬ŠŌÄܤĻ°²¶Ø”£ ? I„±©`„¹¤Ė¤Ŗ¤¤¤Ę°²¶Ø¤·¤Ępurge¤¬ŠŠ¤ļ¤ė¤æ¤įHistory Length ¤ĻÉģ¤Ó¤Ź¤¤ ? I„±©`„¹¹²¤Ė°²¶Ø¤Ļ¤·¤Ę¤¤¤ė¤¬”¢innodb_io_capacity¤ņ¤ä ¤·¤æ·½¤¬øߊŌÄÜ ? purge_invoked¤Ļ¤É¤Į¤é¤Ī„Ń„æ©`„ó¤ā¤Ø¤Ę¤¤¤ė¤¬”¢ innodb_log_file_in_group¤ņp¤é¤·¤æ·½¤¬øߤ¤Ī»ÖƤĒ°²¶Ø ? 5.6Ļµ¤Ēbuffer_flush_batch_num_scan¤¬¤Ø¤æ¤é¤æ¤Ö¤óŲ¤±
- 37. 5.6.26 ext4 5.6.26 *25.6.26 *1 performance_schema¤«¤éio“ż¤Į¤ņŅ¤Ę¤ß¤ė
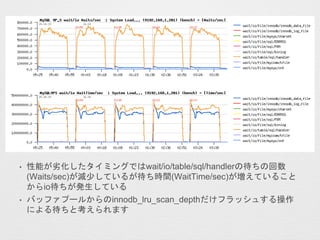
- 38. ? ./storage/perfschema/pfs_instr.h¤č¤ź /** @def WAIT_STACK_LOGICAL_SIZE Maximum number of nested waits. Some waits, such as: - "wait/io/table/sql/handler" - "wait/lock/table/sql/handler" are implemented by calling code in a storage engine, that can cause nested waits (file io, mutex, ...) Because of partitioned tables, a table io event (on the whole table) can contain a nested table io event (on a partition). Because of additional debug instrumentation, waiting on what looks like a "mutex" (safe_mutex, innodb sync0sync, ...) can cause nested waits to be recorded. For example, a wait on innodb mutexes can lead to: - wait/sync/mutex/innobase/some_mutex - wait/sync/mutex/innobase/sync0sync - wait/sync/mutex/innobase/os0sync The max depth of the event stack must be sufficient for these low level details to be visible. */ ? WaitedTime/sec¤Ė¤Ŗ¤¤¤Ęwait/io/table/sql/handler¤¬ŠŌÄÜĮÓ»Æ r¤«¤é¼Ó¤·¤Ę¤¤¤ė¤³¤Č¤«¤é„Ę©`„Ö„ė¤Ī²Ł×÷(INSERT¤ä UPDATE)¤Ėrég¤¬¤«¤«¤ė¤č¤¦¤Ė¤Ź¤Ć¤Ę¤¤¤ė¤Č漤ؤé¤ģ¤Ž¤¹
- 39. 5.6Ļµ+ext4¤Īŗ g¤Ź¤Ž¤Č¤į ? øßĖŁ¤Ź„Õ„é„Ć„·„儹„Č„ģ©`„ø”¢5.6ĻµĒŅ¤Äext4¤ņ„Ē©`„æīIÓņ¤Č ¤·¤ĘŹ¹ÓƤ·¤Ę¤¤¤ėh¾³¤ĒøüŠĀIĄķ¤¬·Ē³£¤Ė¶ą¤¤r¤ĖŠŌÄܤ¬²» °²¶Ø¤Ė¤Ź¤ėöŗĻ¤Ļinnodb_io_capacity¤ņŅÖ±¤·¤æ·½¤¬Į¼¤¤æÉ ÄÜŠŌ¤¬¤¢¤ė ? ½ń»Ų¤ĻLinkBench¤Ī„ļ©`„Æ„ķ©`„ɤĖ¤Ŗ¤¤¤ĘÉĻŹÖ¤ÆÓ¤¤¤Ę¤Æ ¤ģ¤æ¤Ą¤±¤Ź¤Ī¤Ē”¢æÉÄÜŠŌ¤Ē¤·¤«¤¢¤ź¤Ž¤»¤ó ? redo„ķ„°¤Ī„µ„¤„ŗäøü¤ĻMySQL¤ĪŌŁĘšÓ¤¬±ŲŅŖ¤Ė¤Ź¤ė¤æ¤į ”¢„Ŗ„ó„鄤„óäøü¤¬æÉÄܤŹinnodb_io_capacity¤Ī·½¤¬„«„ø„å „¢„ė¤Ėäøü¤·¤Ęæ¹ū¤¬“_ÕJæÉÄܤŹµć¤¬„į„ź„ƄȤĒ¤¹
- 41. ¤Ŗ¤Ž¤±: 5.6¤Č5.7¤Ē¤Īß`¤¤ ? Waits/sec¤Ļ“󤤏²ī¤¬o¤¤ŹĀ¤«¤é“ż¤Į»ŲŹż¤Ī²ī¤ĻŠ” ? Time/sec¤¬Š”¤µ¤¤ŹĀ¤«¤éĶ¬¤øIĄķ¤Ē¤ā“ż¤Įrég¤¬5.7¤Ī·½¤¬Š”¤µ ¤¤ 5.7.8 xfs 5.7.8 ext4 5.6.26 ext45.6.26 xfs
- 42. sxlock is ŗĪ£æ ? https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_rw_lock ¤č ¤ź ? An sx-lock provides write access to a common resource while permitting inconsistent reads by other threads. sx- locks were introduced in MySQL 5.7 to optimize concurrency and improve scalability for read-write workloads.
- 43. ÓąÕ1 ? MySQL 5.6Ļµ¤Īinnodb_io_capacity¤ĪÖĘÓł¤Ļ¤«¤Ź¤źßmµ±¤Ź¤Ī¤Ē×¢ Ņā¤¬±ŲŅŖ”£ĘÕĶؤĻinnodb_io_capacity¤ņO¶Ė¤Ė“ó¤¤Æ¤·¤Ź¤¤·½¤¬ Į¼¤¤¤Ē¤¹ ? „Ł„ó„Į„Ž©`„ƽKĮĖįį¤Ė5.7Ļµ¤ĻŅ»¶Ø¤ĪwriteĮæ¤Ź¤Ī¤Ė5.6Ļµ¤Ļo²čæą ²čwrite¤·¤Ę¤¤¤ė¤³¤Č¤«¤é¤½¤ĪŹĀ¤¬Į¼¤Æ¤ļ¤«¤ź¤Ž¤¹ 5.7.8 xfs 5.7.8 ext4 5.6.26 ext45.6.26 xfs
- 44. „Ł„ó„Į½KĮĖÖ±įį¤Īsar -b ? 5.6 ? 02:16:49 AM 69062.50 0.00 69062.50 0.00 1084890.91 ? 02:16:50 AM 67874.16 0.00 67874.16 0.00 1067200.00 ? 02:16:51 AM 69042.05 0.00 69042.05 0.00 1085245.45 ? 5.7 ? 03:06:25 AM 18944.33 0.00 18944.33 0.00 298795.88 ? 03:06:26 AM 18871.43 0.00 18871.43 0.00 296669.39 ? 03:06:27 AM 19266.67 0.00 19266.67 0.00 302866.67
- 46. Ļó„Ń„é„į©`„æ ? innodb_buffer_pool_instances ? innodb_lru_scan_depth ? innodb_io_capacity ? innodb_io_capacity_max ? innodb_page_cleaners
- 47. ? ¾A¤¤¤Ę„°„é„Õ¤ņŅ¤Ę¤¤¤¤Ž¤¹¤¬”¢1¤Ī„±©`„¹¤¬„¹„³„¢¤Č¤·¤Ę ¤ĻµĶ¤¤¤Ē¤¹¤¬×ī¤āŠŌÄܤ¬°²¶Ø¤·¤Ę¤¤¤ė¤č¤¦¤ĖŅ¤Ø¤Ž¤¹”£ ? 2,3,4¤Ļ¤ä¤äŠŌÄܤ¬¤Ö¤ģ¤ėŹĀ¤¬¤¢¤ė ? 5¤Ļøī¤Č°²¶ØŻĪ¶¤Ą¤±¤Éinnodb_buffer_pool¤¬Āń¤Ž¤Ć¤æ„愤„ß „ó„°¤Ē¤ĪĮӻƤ¬¤ä¤ä“󤤤 1 2 3 4 5 innodb_buffer_pool_instances 12 innodb_lru_scan_depth 1500 innodb_io_capacity 22000 innodb_io_capacity_max 25000 innodb_page_cleaners 8 Linkbench„¹„³„¢
- 48. ? innodb_buffer_pool_instances ? InnoDB¤Ī„Š„Ć„Õ„”„ש`„ė¤ņÖø¶Ø¤·¤æŹż¤Ē·Öøī¤·”¢„Š„Ć„Õ „”¤ĪøŗĻ¤ņĻ÷p¤·¤Ž¤¹”£ ? innodb_lru_scan_depth ? „Ž„Ė„å„¢„ė¤č¤ź: page_cleaner„¹„ģ„Ƅɤ¬„Õ„é„Ć„·„夹¤ė„Ą©`„Ę„£©`„Ś©`„ø¤ņ ŹĖ÷¤¹¤ėėH¤Ė”¢¤É¤Ī¤Æ¤é¤¤¤ĪÉī¤µ¤Ž¤Ē„Š„Ć„Õ„”©`„ש`„ė LRU „ź„¹„Ȥņ„¹„„ć „ó¤¹¤ė¤Ī¤«¤¬Öø¶Ø¤µ¤ģ¤Ž¤¹”£¤³¤ģ¤Ļ”¢1 Ćė¤“¤Č¤Ė 1 »ŲgŠŠ¤µ¤ģ¤ė„Š„Ć„Æ„°„鄦 „ó„ɲŁ×÷¤Ē¤¹”£ ? Ó¤¤Č¤·¤Ę¤Ļø÷„Š„Ć„Õ„”„ש`„ė„¤„󄹄æ„󄹤ĪFree Buffer ¤¬Öø¶Ø¤·¤Ę¤¤¤ė¤ņĻĀ»Ų¤Ć¤Ę¤¤¤æ¤éÖø¶Ø¤·¤æ¤Ž¤ĒæÕ¤īI Óņ¤ņ“_±£¤·¤č¤¦¤Č¤·¤Ž¤¹ ? ¤č¤Ć¤Ę×ī“ó¤Ē Free Buffer = innodb_buffer_pool_instances x innodb_lru_scan_depth ¤Ž¤Ē„Š„Ć„Õ„”¤ņé_·Å¤·¤č¤¦¤Č¤·¤Ž¤¹”£
- 49. ? innodb_lru_scan_depth¤Ļ¤ä¤·¤æ·½¤¬°²¶Ø¤¹¤ėŹĀ¤¬¤¢¤ė¤¬”¢ Free Buffer¤¬¤Ø¤ė”¢¤Ä¤Ž¤źŹ¹ÓĆæÉÄܤŹ„Š„Ć„Õ„”„ש`„ė¤¬p ¤ė¤Ī¤Ē¤ä¤·¤¹¤®¤ė¤Čio¤¬¤Ø”¢½Y¹ū¤Č¤·¤ĘŠŌÄܤ¬ĻĀ¤¬¤ėö ŗĻ¤ā¤¢¤ź¤Ž¤¹”£ ? Öø¶Ø¤·¤æ¤¬“󤤹¤®¤ė¤Č¤½¤Ī¤Ž¤ĒFree Buffer¤ņ“_±£¤·¤č ¤¦¤Č¤¹¤ė¤Ī¤Ē¤½¤Ī“ż¤Įrég¤Ė¤č¤źĮӻƤ¹¤ėöŗĻ¤ā¤¢¤ź¤Ž¤¹
- 54. ¤Ž¤Č¤į
- 55. ? dimSTAT¤ņŹ¹ÓƤ¹¤ė¤Čperformance_schema¤ä innodb_monitor¤«¤éŠŌÄܤĖév¤ļ¤ėķÄæ¤ā„°„é„ջƤ¹¤ėŹĀ¤¬æÉ ÄÜ ? ŠŌÄÜy¶Ø¤Īégøō¤¬æÕ¤¤¤Ę¤āég¤Īrég¤ĻŹ”ĀŌ¤·¤æ„°„é„Õ¤¬×÷³É ¤µ¤ģ¤ė¤æ¤į±ČŻ^¤¬¤·¤ä¤¹¤Æ¤Ź¤ź¤Ž¤¹ ? Č”µĆ¤µ¤ģ¤ėķÄ椬“óĮæ¤Ī¤æ¤įŅ椦¤Ī¤¬“óä¤Ē¤¹¤¬ Bookmark¤ĪCÄܤņĄūÓƤ·¤ĘÓč¤įÓĆŅā¤·¤Ę¤Ŗ¤±¤Š„Ł„ó„Įįį¤Ė ŻS¤Ė¤ņ²ĪÕÕæÉÄܤȤŹ¤ź¤Ž¤¹ ? ±ČŻ^¤·¤æÄŚČŻ¤ĻSnapshot¤Ė¤·¤Ę¤Ŗ¤Æ¤Čįį¤«¤é¤Ī²ĪÕÕ¤¬S¤Ē¤¹ ? Č”µĆ¤µ¤ģ¤ėķÄ椬¶ą¤¤¤æ¤į”¢„Ń„é„į©`„æäøü¤Ī¤Ó¤ņÕ{¤Ł¤ė ¤Ī¤ĖĻņ¤¤¤Ę¤¤¤Ž¤¹
- 56. ¤Ŗ¤ļ¤ź
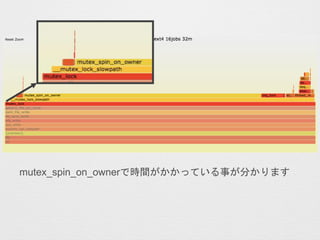
- 58. fio + perf + Flame Graphs ? gŠŠ„³„Ž„ó„É ? perf record -a -g -F100000 /usr/bin/fio --name=”®test”Æ --readwrite=randwrite --blocksize=4k --size=32m --filename=/var/lib/mysql/fio/fiotest --direct=1 --numjobs=16 --group_reporting ? 1¤Ä¤Ī„Õ„”„¤„ė¤Ė¤·¤Ę16„ׄķ„»„¹¤Ē¤½¤ģ¤¾¤ģ32MB¤Īų¤Žz¤ß ¤ņO_DIRECT¤ĒŠŠ¤¤¤Ž¤¹ ? Flame Graphs¤Ī×÷³É ? perf script > perf_data.txt ? stackcollapse-perf.pl perf_data.txt | flamegraph.pl --title ”°[„愤 „Č„ėĆū]”± > [„Õ„”„¤„ėĆū].svg ? ²Īæ¼: perf + Flame Graphs ¤Ē Linux „«©`„Ķ„ėÄŚ¤Ī„Ü„Č„ė„Ķ„Ć„Æ¤ņĢŲ¶Ø¤¹¤ė (http://d.hatena.ne.jp/yohei-a/20150706/1436208007)
- 62. ³ę“Ś²õ¤Ī³”ŗĻ
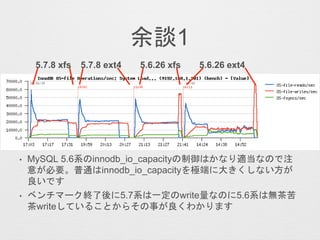
- 65. fio¤Ī„¹„³„¢(iops) ext4 xfs ? ¤Į¤Ź¤ß¤ĖŅŌĻĀ¤Ī¤ĖdirectoryÖø¶Ø¤Ē¤½¤ģ¤¾¤ģ¤Ī„¹„ģ„Ƅɤ¬® ¤Ź¤ė„Õ„”„¤„ė¤Ėwrite¤ņŠŠ¤Ć¤æöŗĻ¤Ļext4, xfs¤ĪI·½¤Č¤āŹ®·Ö ¤Źiops¤¬³ö¤Ž¤¹ ? /usr/bin/fio --name='test' --readwrite=randwrite --blocksize=4k --size=100m --directory=/var/lib/mysql/fiotest --direct=1 --numjobs=32 --loops=3 --group_reporting
- 67. ¤Ŗ¤Ž¤±¤Ī¤Ŗ¤ļ¤ź