
















![VAEź┘®`ź╣ż╬Į╠Ĥż╩żĘDisentanglementż╬’Lļģā╣
Ī░VAEĪ▒ż╚Ī▒”┬-VAEĪ▒ż╬ŽÓ▀`ĄŃ
? KLź└źżźą®`źĖź¦ź¾ź╣(KLD)
ż╦ųžż▀éS╩²”┬ż“ūĘ╝ė
Ė„Ū▒į┌ēõ╩²ż¼żĮżņżŠżņš²ęÄĘų▓╝ż╦
┬õż┴żļżĶż”ÅŖż»ųŲ╝sż“ż½ż▒żļ
ż│ż╚żŪĖ„Ū▒į┌ēõ╩²ż¼Č└┴óż╦ż╩żļ
”┬-VAE(1/4)
18[2] Yosua Bengio et al. hogehoge
[5] Yosua Bengio et al. hogehoge
VAE-based/┤_┬╩šō](https://image.slidesharecdn.com/magurodisentanglementverdistribution-191005033805/85/Disentanglement-Survey-Can-You-Explain-How-Much-Are-Generative-models-Disentangled-18-320.jpg)






![╩ĮĘųĮŌæķ╣·Ģr┤·ż╬─╗ķ_ż▒ĪóTotal Correlation(TC)
Ī░”┬-VAEĪ▒ż╬å¢Ņ}ĄŃ
? KLDĒŚż╦ųžż▀ż“Æņż▒żļż╚į┘śŗ│╔š`▓Ņż¼▌XęĢżĄżņżļ
Ī·╗ŁŽ±ż¼ż▄żõż▒żõż╣ż»ż╩żļ
į┘śŗ│╔š`▓Ņż╦ė░Ēæż“ėļż©ż╩żżżĶż”ż╦żĘżĶż”ŻĪ
FactorVAE(1/5)
25[6] Yosua Bengio et al. hogehoge
InfoGANżŽė¢ŠÜż¼░▓Č©ż╗ż║īgė├Ą─żŪżŽż╩żż
VAE-based/┤_┬╩šōĪóŪķł¾└Ēšō](https://image.slidesharecdn.com/magurodisentanglementverdistribution-191005033805/85/Disentanglement-Survey-Can-You-Explain-How-Much-Are-Generative-models-Disentangled-25-320.jpg)


































![ū╦ä▌Ūķł¾ż╚╚╦╬’╠žÅšż“ĘųļxżĘżŲż╬ū╦ä▌▄׹┤
62
ÅĻė├蹊┐FD-GAN(2/2)
╝╚┤µ╩ųĘ©[18, 19]ż╦īØżĘżŲ
FD-GANżŽš²żĘż»▄׹┤żŪżŁżŲżżżļ
żĘż½żĘĪóż▐ż└ż▐ż└ņÄżŽšnŅ}żóżĻż½](https://image.slidesharecdn.com/magurodisentanglementverdistribution-191005033805/85/Disentanglement-Survey-Can-You-Explain-How-Much-Are-Generative-models-Disentangled-62-320.jpg)

















![[DL▌åši╗ß]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=560&fit=bounds)





![[DL▌åši╗ß]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=560&fit=bounds)









![[DL▌åši╗ß]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=560&fit=bounds)
![SSII2021 [OS2-02] ╔Ņīėč¦┴Ģż╦ż¬ż▒żļźŪ®`ź┐ÆłÅłż╬įŁ└Ēż╚ūŅą┬äėŽ“](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=560&fit=bounds)
![[DL▌åši╗ß]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=560&fit=bounds)
![[DL▌åši╗ß]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)



![[DL▌åši╗ß]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=560&fit=bounds)
![[DL▌åši╗ß]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=560&fit=bounds)



More Related Content
What's hot (20)
Disentanglement Survey:Can You Explain How Much Are Generative models Disentangled?
- 1. Disentanglement Survey Hideki Tsunashima(@maguroIsland) 1Kogakuin University, AIST Can You Explain How Much Are Generative models Disentangled?
- 2. ūį╝║ĮBĮķ 2 ŠVŹu ąŃśõ(@maguroIsland) -╦∙╩¶ ╣żč¦į║┤¾č¦ ą▐╩┐šn│╠2─Ļ-ĻÉ蹊┐╩ę «bŠtčą(AIST) Research Assistant -蹊┐źŲ®`ź▐ ╔·│╔źŌźŪźļż╬ėŗ╦Ń┴┐Ž„£pĪó╗ŁŽ±╔·│╔ -╚ż╬Č ĮŅź╚źņĪóźóźßźšź╚ĪóšiĢ°Īó궜Sź▓®`źÓ
- 3. Ī∙ūóęŌĪ∙ 3 ? 2019─Ļ10į┬¼Fį┌ż╬Ūķł¾ż¼į¬ż╬źĄ®`ź┘źż┘Y┴ŽżŪż╣ ? ╩²╩ĮżŽ║å┬į╗»ż╬ż┐żßĪóę╗▓┐źĒź╣ą╬╩ĮżŪėø╩÷ż“żĘż▐ ż╣ż╬żŪĪóį¬ż╬╩²╩Įż“┤_šJżĘż┐żż╚╦żŽźĻźšźĪźņź¾ź╣ ż“▓╬ššżĘżŲż»ż└żĄżż ? øg╔Įż╬šō╬─ż╬ĮBĮķżŪżŽż╩ż»Disentanglementż╬ ŽĄūVż“Ė®Ņ½Ą─ż╦ęŖżļźĄ®`ź┘źżż╚ż╩ż├żŲżżż▐ż╣ (ūŅßßż╬ŽĄĮyż┤ż╚ż╦šō╬─źĻź╣ź╚ż“▌dż╗ż▐ż╣) ? ź╣źķźżź╔żŽ╦Įż╬twitterż╦▌dż╗żŲżżżļż╬żŪĪóżĮż│ ż½żķ’wż¾żŪż┤┤_šJż»ż└żĄżżĪ· @maguroIsland
- 5. ╗ŁŽ±╔·│╔źŌźŪźļŠ▐╚╦ VAE(ż¬żĄżķżż) 5 VAE-based/┤_┬╩šō ? ╗ŁŽ±ż“łR┐sżĄżņż┐▒Ē¼Fzż╦ ź©ź¾ź│®`ź╔ ? zż¼╩┬Ū░Ęų▓╝(e.g. š²ęÄĘų▓╝) ż╦ÅŠż”żĶż”ż╦ż╣żļ
- 6. ╗ŁŽ±╔·│╔źŌźŪźļŠ▐╚╦ VAE(ż¬żĄżķżż) 6 VAE-based/┤_┬╩šō ? ╗ŁŽ±xż“łR┐sżĄżņż┐▒Ē¼Fzż╦ ź©ź¾ź│®`ź╔ ? zż¼╩┬Ū░Ęų▓╝(e.g. š²ęÄĘų▓╝) ż╦ÅŠż”żĶż”ż╦ż╣żļ ? zż½żķxż“Å═į¬ Ū▒į┌ēõ╩²zż“š²ęÄĘų▓╝ż½żķźĄź¾źū źĻź¾ź░ż╣żļż│ż╚żŪ╔½Ī®ż╩╗ŁŽ±ż“ ╔·│╔┐╔─▄
- 7. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ 7 ? DisentanglementŻĮżŌż─żņż╬ĮŌż▒ ? EntanglementŻĮżŌż─żņ źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚żĄżņż┐▒Ē¼Fż╚żŽę╗ż─ż╬ Ū▒į┌źµź╦ź├ź╚żŽę╗ż─ż╬╔·│╔ę“ūėż╦īØżĘżŲ├¶ĖążŪżóżĻĪó żĮż╬╦¹ż╬ę“ūėż╦ė░Ēæż“╝░ż▄żĄż╩żż▒Ē¼Fż╚Č©┴xżĄżņżļĪŻ Yosua Bengio ? źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬Č©┴x
- 9. Contents 9 Disentanglementż╬ŽĄūVĪó│▀Č╚ĪóÅĻė├ i. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬ŽĄūV ii. ╩ĮĘųĮŌæķ╣·Ģr┤· iii. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬įuü²│▀Č╚ iv. Go Beyond Disentanglement v. źßź┐źĄ®`ź┘źż
- 11. ╔·│╔źŌźŪźļż╬Į╠Ĥż╩żĘDisentanglementż╬’Lļģā╣ Ī░InfoGANĪ▒ż╚Ī▒vanillaż╬GANĪ▒ż╬ŽÓ▀`ĄŃ ? Generator(G)ż╬╚ļ┴”ż╦Ū▒į┌ź│®`ź╔c(ź┘ź»ź╚źļą╬╩Į)ż“ūĘ╝ė ? Discriminator(D)żŽreal/fake┼ąČ©ż└ż▒żŪż╩ż» Ū▒į┌ź│®`ź╔cż╬═Ųšōż“ąąż” ? Gż╬╚ļ┴”cż╚Dż╬═ŲšōĮY╣¹ż¼ę╗ų┬ż╣żļżĶż”ė¢ŠÜ Ī·ŽÓ╗źŪķł¾┴┐ż╬ūŅ┤¾╗» InfoGAN(1/6) 11 GAN-based/Ūķł¾└Ēšō
- 18. VAEź┘®`ź╣ż╬Į╠Ĥż╩żĘDisentanglementż╬’Lļģā╣ Ī░VAEĪ▒ż╚Ī▒”┬-VAEĪ▒ż╬ŽÓ▀`ĄŃ ? KLź└źżźą®`źĖź¦ź¾ź╣(KLD) ż╦ųžż▀éS╩²”┬ż“ūĘ╝ė Ė„Ū▒į┌ēõ╩²ż¼żĮżņżŠżņš²ęÄĘų▓╝ż╦ ┬õż┴żļżĶż”ÅŖż»ųŲ╝sż“ż½ż▒żļ ż│ż╚żŪĖ„Ū▒į┌ēõ╩²ż¼Č└┴óż╦ż╩żļ ”┬-VAE(1/4) 18[2] Yosua Bengio et al. hogehoge [5] Yosua Bengio et al. hogehoge VAE-based/┤_┬╩šō
- 19. VAEź┘®`ź╣ż╬Į╠Ĥż╩żĘDisentanglementż╬’Lļģā╣ ? = ? ?”š(?|?) ????”╚ (?|?) ? ? ?? ?”š ? ? ||?(?) ”┬-VAE(2/4) 19 ēõĘųŽ┬Įń(Lower Bound) VAEż╦ż¬żżżŲūŅ┤¾╗»ż╣ż┘żŁ ─┐Ą─ķv╩² źčźķźß®`ź┐”╚ż╬NN(Decoder)żŪį┘śŗ│╔ ż╣żļĘų▓╝ż“źčźķźß®`ź┐”Ąż╬NN (Encoder) żŪŲ┌┤²éÄż“╚Īż├ż┐ĒŚ ꬿ╣żļż╦żõżļż│ż╚żŽŲ┌┤²éÄż╬ūŅ┤¾╗» (=ź©ź¾ź│®`ź╔żĘż┐zż“╩╣ż├żŲxż“═ĻĶĄż╦į┘śŗ │╔ż╣żļ)ż╩ż╬żŪĪóį┘śŗ│╔š`▓Ņż╬ūŅąĪ╗»ż╬ĒŚ VAE-based/┤_┬╩šō
- 20. VAEź┘®`ź╣ż╬Į╠Ĥż╩żĘDisentanglementż╬’Lļģā╣ ? = ? ?”š(?|?) ????”╚ (?|?) ? ? ?? ?”š ? ? ||?(?) ”┬-VAE(2/4) 20 źčźķźß®`ź┐”Ąż╬NN(Encoer)żŪxż½żķ ═ŲČ©żĘż┐ź©ź¾ź│®`ź╔żĘż┐zż╬Ęų▓╝ż╚ ╩┬Ū░ż╦▀xż¾żŪż¬żżż┐Ęų▓╝ż╚ż╬KLDż“ ╚ĪżļĒŚ ꬿ╣żļż╦╩┬Ū░Ęų▓╝ż╦═ŲČ©żĘż┐Ęų▓╝ż“ Į³ż┼ż▒ż┐żżż╬żŪĪóKLDż╬ūŅąĪ╗»ż╬ĒŚ VAE-based/┤_┬╩šō
- 21. VAEź┘®`ź╣ż╬Į╠Ĥż╩żĘDisentanglementż╬’Lļģā╣ ? = ? ?”š(?|?) ????”╚ (?|?) ? ? ?? ?”š ? ? ||?(?) ”┬-VAE(2/4) 21 ?? ?? ?”š ? ? ||?(?) KLDĒŚż╦ųžż▀éS╩²”┬(”┬>1)ż“ ╝ėż©żļż│ż╚żŪĖ„Ū▒į┌ēõ╩²ż¼ żĶżĻÅŖż»╩┬Ū░Ęų▓╝ż╦ÅŠż”żĶż” ż╦ųŲ╝sż“╝ėż©żļ VAE-based/┤_┬╩šō
- 22. VAEź┘®`ź╣ż╬Į╠Ĥż╩żĘDisentanglementż╬’Lļģā╣ ”┬-VAE(3/4) 22 ? VAE EnganlementżĘżŲ żĘż▐ż├żŲżżżļ ? InfoGAN ēõ╗»ż¼Ę”żĘżż ? ”┬-VAE ēõ╗»żŌžNż½żŪ EntanglementżŌ żóż▐żĻż╩żż (ż╣ż┤żżż▄żõż▒żŲ żżżļżĶż”ż╩...) VAE-based/┤_┬╩šō
- 24. Contents 24 Disentanglementż╬ŽĄūVĪó│▀Č╚ĪóÅĻė├ i. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬ŽĄūV ii. ╩ĮĘųĮŌæķ╣·Ģr┤· iii. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬įuü²│▀Č╚ iv. Go Beyond Disentanglement v. źßź┐źĄ®`ź┘źż
- 25. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╬─╗ķ_ż▒ĪóTotal Correlation(TC) Ī░”┬-VAEĪ▒ż╬å¢Ņ}ĄŃ ? KLDĒŚż╦ųžż▀ż“Æņż▒żļż╚į┘śŗ│╔š`▓Ņż¼▌XęĢżĄżņżļ Ī·╗ŁŽ±ż¼ż▄żõż▒żõż╣ż»ż╩żļ į┘śŗ│╔š`▓Ņż╦ė░Ēæż“ėļż©ż╩żżżĶż”ż╦żĘżĶż”ŻĪ FactorVAE(1/5) 25[6] Yosua Bengio et al. hogehoge InfoGANżŽė¢ŠÜż¼░▓Č©ż╗ż║īgė├Ą─żŪżŽż╩żż VAE-based/┤_┬╩šōĪóŪķł¾└Ēšō
- 26. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╬─╗ķ_ż▒ĪóTotal Correlation(TC) ”┬-VAEż╬į┘śŗ│╔š`▓Ņż¼ēł╝ėż╣żļįŁę“ż╚żŽŻ┐ ?”┬???? = 1 ? ”ę ?=1 ? ? ??????? +”┬(?? ?; ? +? ?? ? ? , ? ? ) FactorVAE(2/5) 26 VAE-based/┤_┬╩šōĪóŪķł¾└Ēšō KLDĒŚ(Ęų▓╝ż╬▓╗ę╗ų┬Č╚) ż│ż│żŪżŽzģg╠Õż╬Ęų▓╝ż╚╩┬Ū░ Ęų▓╝ż╬▓╗ę╗ų┬Č╚ ż│ż╬ĒŚż╬ūŅąĪ╗»żŪĖ„Ū▒į┌ēõ╩² żŽČ└┴óż╚ż╩żļ ?”┬???? = 1 ? ”ę ?=1 ? ? ??????? + ”┬? ?? (N:minibatch) KLDż╬źŪ®`ź┐Ęų▓╝żŪż╬Ų┌┤²éÄż“ĘųĮŌ 1 ? ”ę ?=1 ? ? = ? ?(?) ? MIĒŚ(Mutual InformationŻ║ŽÓ╗źŪķł¾┴┐) 2Ęų▓╝ķgż╬ę└┤µķvéSż“▒ĒżĘżŲżżżļ ż│ż│żŪżŽ╚ļ┴”xż╚Ū▒į┌ēõ╩²zż╬ę└┤µķvéS ż│ż╬ĒŚż╬ūŅ┤¾╗»żŪxż╚zż╬īØÅĻķvéSż¼½@Ą├żĄżņżļ ╝╚┤µż╬ōp╩¦ķv╩²żŽ? ?(?) ? ?? ż“ūŅąĪ╗»żĘżĶż”ż╚żĘżŲ ż┐ż╬żŪĪóŽÓ╗źŪķł¾┴┐żŌūŅąĪ╗»żĘżŲżĘż▐ż├żŲżżż┐ŻĪ Ī·xż½żķzżžż╬Ūķł¾ōp╩¦ŻĮį┘śŗ│╔š`▓Ņż╬ēł╝ė
- 27. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╬─╗ķ_ż▒ĪóTotal Correlation(TC) ”┬-VAEż╬į┘śŗ│╔š`▓Ņż¼ēł╝ėż╣żļįŁę“ż╚żŽŻ┐ FactorVAE(2/5) 27 VAE-based/┤_┬╩šōĪóŪķł¾└Ēšō ?”┬???? = 1 ? ”ę ?=1 ? ? ??????? + ”┬? ?? (N:minibatch) KLDż╬źŪ®`ź┐Ęų▓╝żŪż╬Ų┌┤²éÄż“ĘųĮŌ 1 ? ”ę ?=1 ? ? = ? ?(?) ? żĘż½żĘĪóĪóĪó ŽÓ╗źŪķł¾┴┐żŽų▒Įėėŗ╦Ńż╣żļż│ż╚ż¼▓╗┐╔─▄ż╩ż┐żßĪóż│ż╬╩ĮżŽĮŌż▒ż╩żż żŪżŽĪóę╗╠Õż╔ż”ż╣żņżąĪóĪóĪó ?”┬???? = 1 ? ”ę ?=1 ? ? ??????? +”┬(?? ?; ? +? ?? ? ? , ? ? )
- 28. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╬─╗ķ_ż▒ĪóTotal Correlation(TC) ”┬-VAEż╬į┘śŗ│╔š`▓Ņż¼ēł╝ėż╣żļįŁę“ż╚żŽŻ┐ ? ???????? = 1 ? ”ę ?=1 ? ? ??????? + ? ?? +”├? ?? FactorVAE(2/5) 28 VAE-based/┤_┬╩šōĪóŪķł¾└Ēšō ?”┬???? = 1 ? ”ę ?=1 ? ? ??????? + ”┬? ?? (N:minibatch) KLDż╬źŪ®`ź┐Ęų▓╝żŪż╬Ų┌┤²éÄż“ĘųĮŌ 1 ? ”ę ?=1 ? ? = ? ?(?) ? TCż╬ųŲ╝sĒŚ(2Ęų▓╝ķgż╬Č└┴óąį) ŽÓ╗źŪķł¾┴┐ż¼żóż▐żĻąĪżĄż»żĘż╩żżżĶż”ż╦żĘĪóżĮżņż╚żŽ äeż╦Ū▒į┌ēõ╩²═¼╩┐ż¼Č└┴óż╦ż╩żļųŲ╝sĒŚż“ūĘ╝ė ż│ż╬ĒŚż“ūŅąĪ╗»ż╣żļż│ż╚żŪŪ▒į┌ēõ╩²ż¼Č└┴óż╦ż╩żļŻĪ Ī·Disentanglementż╬ż▀ż¼┤┘żĄżņżļŻĪ ?”┬???? = 1 ? ”ę ?=1 ? ? ??????? +”┬(?? ?; ? +? ?? ? ? , ? ? )
- 36. Contents 36 Disentanglementż╬ŽĄūVĪó│▀Č╚ĪóÅĻė├ i. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬ŽĄūV ii. ╩ĮĘųĮŌæķ╣·Ģr┤· iii. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬įuü²│▀Č╚ iv. Go Beyond Disentanglement v. źßź┐źĄ®`ź┘źż
- 37. Disentanglementż╬įuü²│▀Č╚ż╬ĄŪł÷ŻĪ Disentanglement Metric Scoreż╦ż─żżżŲ ? ”┬-VAEż╦żŲ╠ß░ĖżĄżņż┐│§ż╬Disentanglementż╬įuü²│▀Č╚ ? ĘųĮŌżĄżņżļę“ūė(e.g. ╗ž▄×Īó╠½żĄ)ż¼żóżķż½żĖżßż’ż½ż├żŲżżżļ ż╚żŁż╬ż▀╩╣ė├┐╔─▄ ? ź═ź├ź╚ź’®`ź»(VAEż╩ż╔)ż½żķ╔·│╔żĘż┐╗ŁŽ±ż¼ż╔ż╬ę“ūėż“▒Ż│ų żĘżŲżżżļż╬ż½ż“ŠĆą╬ĘųŅÉŲ„żŪź»źķź╣ĘųŅÉż╣żļ╩ųĘ© Ī·š²żĘżżę“ūėż╦ĘųŅÉżĄżņżņżąOKŻĪ Disentanglement Metric Score 37 Metric
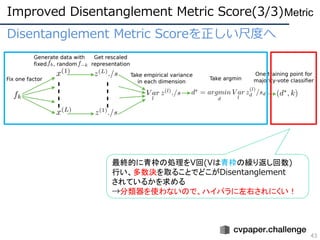
- 38. Disentanglement Metric Scoreż“š²żĘżż│▀Č╚żž Disentanglement Metric Scoreż╦żŽå¢Ņ}ż¼ĪóĪóĪó ? iteration╩²Īóųžż▀│§Ų┌╗»ż╩ż╔ż╬źŽźżźčźķż╦ŠĆą╬ĘųŅÉŲ„ż¼├¶Ėą ? ŠĆą╬ĘųŅÉŲ„ż╦═©żĘżŲżĘż▐ż”ż╚ų▒ĖąĄ─żŪżŽż╩żż (šh├„ąįż╬ėQĄŃżŪżŌĘųŅÉŲ„ż╦═©ż╣ż╬żŽČ“Įķ) ? KéĆųąK-1éĆż╬ę“ūėż╬DisentanglementżŪź╣ź│źó100%ż¼│÷żļ Ī·ų┬├³Ą─ż╩źąź░ Improved Disentanglement Metric Score(1/3) 38 Metric
- 39. Disentanglement Metric Scoreż“š²żĘżż│▀Č╚żž Disentanglement Metric Scoreż“Ė─┴╝żĘż┐įuü²│▀Č╚ż╦ż─żżżŲ ? FactorVAEżŪ╠ß░ĖżĄżņż┐įuü²│▀Č╚ ? ĘųĮŌżĄżņżļę“ūė(e.g. ╗ž▄×Īó╠½żĄ)ż¼żóżķż½żĖżßż’ż½ż├żŲżżżļ ż╚żŁż╬ż▀╩╣ė├┐╔─▄ ? ź»źķź╣ĘųŅÉżŪżŽż╩ż»ČÓ╩²øQżŪę“ūėż“øQČ©ż╣żļż│ż╚żŪźŽźżźčźķ ż╦├¶ĖążŪż╩ż»ż╩ż├ż┐ ? Š╔╩ųĘ©ż╦▒╚ż┘żŲź╚®`ź┐źļż╬╦┘Č╚żŽ210▒ČĪ½1800▒ČŻĪŻĪĪ∙ (Š╔╩ųĘ©:30ĘųĪó▒Š╩ųĘ©:╩²├ļ) 39 Metric Ī∙ Š╔╩ųĘ©żŽź»źķź╣ĘųŅÉŲ„ż╬ė¢ŠÜż¼▒žę¬ż╩ż╬żŪ▀Wżż Improved Disentanglement Metric Score(2/3)
- 40. Disentanglement Metric Scoreż“š²żĘżż│▀Č╚żž 40 Metric 1ż─ż╬ę“ūėż“╣╠Č©żĘż┐LéĆż╬╗ŁŽ±ż“╔·│╔żĘĪó ė¢ŠÜ£gż▀EncoderżŪŪ▒į┌ēõ╩²zż“½@Ą├żĘż▐ż╣ Improved Disentanglement Metric Score(3/3)
- 41. Disentanglement Metric Scoreż“š²żĘżż│▀Č╚żž 41 Metric Ū▒į┌ēõ╩²zż╬Ęų╔óż“Ū¾żßżļ ę“ūėż¼═Ļ╚½ż╦DisentanglementżĄżņżŲżżżļ ł÷║ŽżŽżĮż╬ę“ūėż╬Ęų╔óżŽ0ż╚ż╩żļ Improved Disentanglement Metric Score(3/3)
- 42. Disentanglement Metric Scoreż“š²żĘżż│▀Č╚żž 42 Metric Ęų╔óż¼ūŅżŌąĪżĄżżę“ūėż╬Ū▒į┌ēõ╩²zż╬┤╬į¬ż“Ū¾żßżļ Improved Disentanglement Metric Score(3/3)
- 43. Disentanglement Metric Scoreż“š²żĘżż│▀Č╚żž Improved Disentanglement Metric Score(3/3) 43 Metric ūŅĮKĄ─ż╦ŪÓ¢śż╬äI└Ēż“V╗ž(VżŽŪÓ¢śż╬└RżĻĘĄżĘ╗ž╩²) ąążżĪóČÓ╩²øQż“╚Īżļż│ż╚żŪż╔ż│ż¼Disentanglement żĄżņżŲżżżļż½ż“Ū¾żßżļ Ī·ĘųŅÉŲ„ż“╩╣ż’ż╩żżż╬żŪĪ󟎟żźčźķż╦ū¾ė꿥żņż╦ż»żżŻĪ
- 44. ┬ę┴óż╣żļDisentanglement Metric ? SAP (Separated Attribute Predictability) ŠĆą╬╗žÄóż“ąąż”ż│ż╚żŪźŽźżźčźķż╦ę└┤µżĘż╩żżMetricż╬╠ß░Ė (Factor VAE MetricęįŪ░ż╦ĄŪł÷) ? Modularity Modularityż╚Explicitnessż“įuü² ModularityŻ║1ż─ż╬ę“ūėż╦ĘųĮŌżĄżņżŲżżżļż½ ExplicitnessŻ║źĒźĖź╣źŲźŻź├ź»╗žÄóżŪ╚▌ęūż╦╗žÄóżŪżŁżļż½ Ī·╚▌ęūż╦╗žÄó┐╔─▄ż╩żķšh├„ąįżŌĖ▀żżż╚żżż”ĮŌßŗ żĮż╬╦¹ż╬Disentanglement Metric 44 Metric
- 45. ┬ę┴óż╣żļDisentanglement Metric ? DCI Disentanglement (šō╬─ųążŪżŽ├¹│Ųż╩żĘ) DisentanglementĪóCompletenessĪóInformativenessż“įuü² Lasso╗žÄóż▐ż┐żŽźķź¾ź└źÓźšź®źņź╣ź╚ĘųŅÉŲ„ż“ė├żżżļ DisentanglementŻ║ę“ūėĘųŅÉż╦ż¬żżżŲėąęµż╩Ū▒į┌ēõ╩² CompletenessŻ║ĘųŅÉżĄżņż┐ę“ūėż╬ź©ź¾ź╚źĒźį®`ż╬▓Ņ Ī·ż╔żņż└ż▒ę“ūėĘųĮŌż¼żĘż├ż½żĻąąż’żņżŲżżżļż½ InformativenessŻ║ĘųŅÉŲ„ż╬ėĶ£yš`▓Ņ Ī·š²żĘż»DisentanglementżŪżŁżŲżżżļż½ ? MIG (Mutual Information Gap) ŽÓ╗źŪķł¾┴┐ż╬ūŅżŌĖ▀żżę“ūėż╚┤╬ĄŃż╬ę“ūėż╬▓ŅĪ∙ ¼Fį┌ūŅą┬ż╬Disentanglementż╬Metric Ī∙ ŽÓ╗źŪķł¾┴┐żŽĖ▀żżż█ż╔Disentanglementż¼│÷└┤żŲżżżļ żĮż╬╦¹ż╬Disentanglement Metric 45 Metric
- 47. 47 ŻĪŻ┐
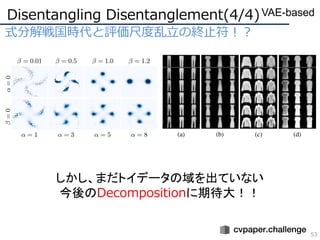
- 48. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╚įuü²│▀Č╚┬ę┴óż╬ĮKų╣Ę¹ŻĪŻ┐ Disentangling Disentanglement(1/4) 48 VAE-based Disentanglementż╬ą┬│▀Č╚ ą┬─┐Ą─ķv╩²ż╬╠ß░Ė State of the ArtŻĪŻĪ ¤oŽ▐źļ®`źūĪóĪóĪó Disentanglementż╬ą┬å¢Ņ}įOČ©
- 49. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╚įuü²│▀Č╚┬ę┴óż╬ĮKų╣Ę¹ŻĪŻ┐ Disentanglementż╬ę╗░Ń╗»żžĪó▒Š└┤żõżĻż┐żżż│ż╚ż╚żŽŻ┐ Disentangling Disentanglement(2/4) 49 VAE-based č}ļjż╩źŪ®`ź┐żŽŪ▒į┌┐šķgżŌ═¼śöż╦č}ļjżŪżóżļżŽż║ 1. 1ż─ż╬Ū▒į┌ēõ╩²ż╬Č└┴óżŪ£gżÓę“ūė(e.g. ╠½żĄ) 2. Ū▒į┌ēõ╩²ż¼ź╗ź├ź╚żŪČ└┴óż╬▒žę¬ż¼żóżļę“ūė(e.g. ╚╦ĘN) ż│ż╬Č■ż─ż“£║ż┐żĘĪóŪ▒į┌┐šķgż╬śŗįņż“š²żĘż»│ķ│÷ż╣żļż┘żŁżŪżóżļ
- 50. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╚įuü²│▀Č╚┬ę┴óż╬ĮKų╣Ę¹ŻĪŻ┐ Disentanglementż╬ę╗░Ń╗»żžĪó▒Š└┤żõżĻż┐żżż│ż╚ż╚żŽŻ┐ 1. DisentanglementżĄżņż┐Ū▒į┌ēõ╩²ż“ų▒ĖąĄ─ż╦ÆQż” 2. Ū▒į┌┐šķg(Ū▒į┌ēõ╩²zż¼Åłżļ┐šķg)ż╬śŗįņż“š²żĘż»│ķ│÷ż╣żļ Disentangling Disentanglement(3/4) 50 VAE-based
- 51. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╚įuü²│▀Č╚┬ę┴óż╬ĮKų╣Ę¹ŻĪŻ┐ Disentanglementż╬ę╗░Ń╗»żžĪó▒Š└┤żõżĻż┐żżż│ż╚ż╚żŽŻ┐ 1. DisentanglementżĄżņż┐Ū▒į┌ēõ╩²ż“ų▒ĖąĄ─ż╦╩╣ż” 2. Ū▒į┌┐šķg(Ū▒į┌ēõ╩²zż¼Åłżļ┐šķg)ż╬śŗįņż“š²żĘż»│ķ│÷ż╣żļ Disentangling Disentanglement(3/4) 51 VAE-based ╝╚┤µ╩ųĘ©żŽ(1)ż╬ż▀ż╦ūó┴”żĘżŲż¬żĻĪó(2)ż╦ū┼─┐żĘżŲżżż╩żż
- 52. ╩ĮĘųĮŌæķ╣·Ģr┤·ż╚įuü²│▀Č╚┬ę┴óż╬ĮKų╣Ę¹ŻĪŻ┐ Disentanglementż╬ę╗░Ń╗»żžĪó▒Š└┤żõżĻż┐żżż│ż╚ż╚żŽŻ┐ 1. DisentanglementżĄżņż┐Ū▒į┌ēõ╩²ż“ų▒ĖąĄ─ż╦╩╣ż” 2. Ū▒į┌┐šķg(Ū▒į┌ēõ╩²zż¼Åłżļ┐šķg)ż╬śŗįņż“š²żĘż»│ķ│÷ż╣żļ Disentangling Disentanglement(3/4) 52 VAE-based (2)żŌ═¼Ģrż╦┐╝ż©żŲżżż»ż│ż╚żŪDisentanglementż“ę╗░Ń╗» Decomposition(ĘųĮŌ)ż╚żżż”šZż╬╠ß│¬ ”┬-VAEż╦(2)ż╦īØÅĻż╣żļųŲ╝sĒŚż“ūĘ╝ėż╣żļż│ż╚żŪDecomposition įuü²żŽFactorVAEż╬Metricż“╩╣ė├ Ī∙ ╩Įżõ╩Įż╬ęŌ╬Čż╬įö╝ÜżŽż│ż│żŪżŽ╩Ī┬įżĘż▐ż╣
- 54. ? InfoGANĪó”┬-VAEż½żķ╩╝ż▐żļDisentanglement ? ŪĘĄŃż“čaż”ż┐żßĪó╩²Ī®ż╬└ĒšōĄ─ĮŌ╬÷ż¼ąąż’żņżŲżŁż┐ ? ╩²Ī®ż╬å¢Ņ}įOČ©ż┤ż╚ż╬Metricż╚ą┬─┐Ą─ķv╩² ? Disentanglementż╬ę╗░Ń╗»ĪóDecompositionż╬╠ß│¬ ż│ż╬ź╗ź»źĘźńź¾ż╬ż▐ż╚żß 54 VAE-based
- 55. Contents 55 Disentanglementż╬ŽĄūVĪó│▀Č╚ĪóÅĻė├ i. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬ŽĄūV ii. ╩ĮĘųĮŌæķ╣·Ģr┤· iii. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬įuü²│▀Č╚ iv. Go Beyond Disentanglement v. źßź┐źĄ®`ź┘źż
- 56. Contents 56 Disentanglementż╬ŽĄūVĪó│▀Č╚ĪóÅĻė├ iv. Go Beyond Disentanglement ? Disentanglementż╬Ė„ź┐ź╣ź»żžż╬ÅĻė├ ? ICLR2020╦┘ł¾ in Disentanglement
- 69. ICLR2020ż╬Disentanglementż╬šō╬─żŽ36▒ŠŻĪ Ü▌ż╦ż╩ż├ż┐żŌż╬ż“źįź├ź»źóź├źūŻĪŻĪ 1. Unsupervised Distillation of Syntactic Information from Contextualized Word Representations Į╠Ĥż╩żĘżŪ╬─śŗįņż╚╬─ż╬ęŌ╬Čż╬Disentanglementż“▀_│╔ ╬─śŗįņż¼═¼żĖżŪęŌ╬Čż¼«Éż╩żļśŗ╬─ż“š²żĘż»Ęųż▒żņżļż╚ų„Åł 69 ICLR 2020ICLR2020╦┘ł¾ in Disentanglement
- 70. ICLR2020ż╬Disentanglementż╬šō╬─żŽ36▒ŠŻĪ Ü▌ż╦ż╩ż├ż┐żŌż╬ż“źįź├ź»źóź├źūŻĪŻĪ 2. Embodied Multimodal Multitask Learning ź¬źųźĖź¦ź»ź╚żõ╬╗ų├ķvéSż“źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╣żļż│ż╚żŪ ╔Ē╠Õż“▒Ż│ųż╣żļź©®`źĖź¦ź¾ź╚ż¼VQAż“┐╔─▄ż╚żĘżŲżżżļ 70 ICLR 2020ICLR2020╦┘ł¾ in Disentanglement
- 71. ICLR2020ż╬Disentanglementż╬šō╬─żŽ36▒ŠŻĪ Ü▌ż╦ż╩ż├ż┐żŌż╬ż“źįź├ź»źóź├źūŻĪŻĪ 3. Disentangling Improves VAEs' Robustness to Adversarial Attacks Adversarial Examplesżžż╬ŅBĮĪąįż“źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ żĄżņż┐▒Ē¼FżŪŽ“╔ŽżĄż╗żļż╚żżż”šō╬─ 71 ICLR 2020ICLR2020╦┘ł¾ in Disentanglement
- 72. Contents 72 Disentanglementż╬ŽĄūVĪó│▀Č╚ĪóÅĻė├ i. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬ŽĄūV ii. ╩ĮĘųĮŌæķ╣·Ģr┤· iii. źŪźŻź╣ź©ź¾ź┐ź¾ź░źļźßź¾ź╚ż╬įuü²│▀Č╚ iv. Go Beyond Disentanglement v. źßź┐źĄ®`ź┘źż
- 73. Disentanglementż╦żŲūó─┐ż╣ż┘żŁčąŠ┐š▀Īó蹊┐ÖCķv Ż╝蹊┐š▀ŻŠ ? Irina HigginsŻ║DeepMind ? Alessandro AchilleŻ║University of California, Los Angeles Ż╝蹊┐ÖCķvŻŠ ? DeepMind źßź┐źĄ®`ź┘źż 73 蹊┐š▀, 蹊┐ÖCķv
- 74. ”┬-VAEż╬╔·ż▀ż╬ėHĪóDisentanglementż╬ź╚ź├źū蹊┐š▀ Irina Higgins źßź┐źĄ®`ź┘źż 74 蹊┐š▀, 蹊┐ÖCķv ? DeepMind Research Scientist ? Neuroscienceź┴®`źÓ╦∙╩¶ ? Disentanglementż╬šō╬─ż“╩²ČÓż» ╔·ż▀│÷ż╣ ? HigginsżĄż¾ż¼╣▓ų°ż╦╚ļż├żŲżżżļ šō╬─żŽ┴╝šō╬─ŻĪ
- 75. ╔±ĮU┐Ų覿╚ÖCąĄč¦┴Ģż╬╚┌║ŽĪó╔·╬’─ŻéŹż╬AIżž Alessandro Achille źßź┐źĄ®`ź┘źż 75 蹊┐š▀, 蹊┐ÖCķv ? UCLA PhD student ? Computer Science Department ? ╔±ĮU┐Ų覥─ų¬ęŖż“ÖCąĄč¦┴Ģż╦╩óżĻ ▐zżÓż│ż╚żŪČ└äōĄ─ż╩šō╬─ż“ł╠╣P ? DeepMindźżź¾ź┐®`ź¾żŪżŽ Neuroscienceź┴®`źÓżŪNeurIPSż╦ ═©żĘżŲżżżļ(HigginsżĄż¾żŌ╣▓ų°)
- 76. Googleż¼┘Iģ¦żĘż┐ź╚ź├źūAI Research╝»ćŌ źßź┐źĄ®`ź┘źż 76 蹊┐š▀, 蹊┐ÖCķv ? ╩²ČÓż»ż╬Researcherż“╣═żżĪóź╚ź├źūź½ź¾źšźĪźņź¾ź╣ż╦═© żĘŠAż▒żļź╚ź├źūźņź┘źļż╬蹊┐š▀╝»ćŌ ? Disentanglementż╬šō╬─żŽNeuroscienceź┴®`źÓ ż└ż▒żŪż╩ż»╦¹ż╬ź┴®`źÓż½żķż╬═ČĖÕżĄżņżŲżżżļ (e.g. FactorVAE) ? DeepMindż╬ėļż©żļė░ĒæżŽÅŖ╗»č¦┴Ģż└ż▒ż╦┴¶ż▐żķż╩żż
- 77. ? DisentanglementżŽśöĪ®ż╩╩²└ĒĄ─ĮŌßŗż╚Metricż¼ ╠ß░ĖżĄżņżŲżŁż┐ż¼Īóę╗░Ń╗»ż¼╩╝ż▐ż├ż┐ ? ÅĻė├蹊┐żŪżŽų▒ĖąĄ─ż╩ĮŌßŗż╬ę“ūėż╦ĘųĮŌżĘżŲ└¹ė├ ż╣żļ蹊┐ż¼ČÓżż ? DisentanglementżŽ╚╦ķgż╬ų▒ĖąĄ─ĮŌßŗż╚żżż”╬╗ų├ ż┼ż▒ż½żķżŌ╔±ĮU┐Ųč¦Ęųę░ż╬蹊┐š▀ż¼ÅŖżż ż▐ż╚żß 77
- 78. ? ▒Š░k▒Ēė├ź╣źķźżź╔żŽ╦Įż╬twitterż╦▌dż╗żŲżżż▐ż╣ Ī· @maguroIsland ? ─┌╚▌Æł│õż“żĘż┐═Ļ╚½░µżŽCVPRż╬ķvéSżŪ12į┬ż╦źóź├źū ż╣żļėĶČ©żŪż╣ ═Ļ╚½░µ╣½ķ_ż╦ż─żżżŲ 78
- 79. 79 Thank you for attention