”¾¶Ł³¢³¢£³”æ20170904³å“”±õ„¬„¤„Ʉ鄤„ó³å±Ź¹ó±·Ķčɽ
?
0 likes?123 views

»śŠµŃ§Ļ°¤ĪÖŖ²Ę¤ņ¤į¤°¤ė¶Æ¤¤Ź¤É¤ņÕhĆ÷






![8
¾tÕŹ””øAIé_°k„¬„¤„Ʉ鄤„󔹤Ī×hÕ£Ø2016Äź12ŌĀ£©
”ń „Č„ķ„Ć„³ī}”¢”øŅ°Į¼AI”¹”¢¤Ź¤É¤Īī}Ņā×R¤«¤é„¹„æ©`„Č
”ń ”øgæŠŌ¤Ī¤¢¤ė”¹„¬„¤„Ʉ鄤„ó¤Č¤·¤Ę”øé_°kÕß”¹¤ĖŲČĪ¤ņŲ¤ļ¤»¤ė
”ń ¤æ¤Ą¤·”øAI”¹¤ņ¶ØĮx¤»¤ŗ
”Ŗ CŠµŃ§Į¤Ź¤É”øČĖ¹¤ÖŖÄܼ¼Šg”¹¤Č”¢¤½¤ģ¤ņźÓƤ·¤æ”ø„·„¹„Ę„ą”¹¤ņĒų
e¤»¤ŗ
”ń ”øĶøĆ÷ŠŌ£ØÕhĆ÷æÉÄÜŠŌ£©”¹¤ņŅŖĒó
”Ŗ ÉīÓѧĮ¤Ė¤ĻoĄķ
”ń ”øé_°kÕß”¹¤Č”øĄūÓĆÕß”¹¤Ī¶žŌŖգؤā¤Ī¤Å¤Æ¤ź„Ń„é„Ą„¤„ą£©
”ń ÉīÓѧĮ¤Īé_°k?ĄūÓƤņĪ®æs¤µ¤»¤ėæ¹ū¤ņæ¼]¤»¤ŗ
”ń £ŗ](https://image.slidesharecdn.com/20170904dllpfn-170906050844/85/DLL-20170904_AI-_PFN-8-320.jpg)















”¾¶Ł³¢³¢£³”æ20170904³å“”±õ„¬„¤„Ʉ鄤„ó³å±Ź¹ó±·Ķčɽ
- 3. 3 AIÉś³ÉĪļ¤Ī¹²ÓŠ?ŌŁĄūÓƤĖév¤¹¤ė„ļ©`„Æ„·„ē„Ć„× ”ń ®b¾tŃŠ?½U®bŹ”?PFN?UEI¤Ź¤É¤¬ÖŠŠÄ¤Č¤Ź¤Ć¤Ę×hÕ¤· ¤Ę¤¤æ¤ā¤Ī ”Ŗ https://sites.google.com/view/srai-2017/ ”Ŗ ѧĮg¤ß„ā„Ē„ė¤Ī¹²ÓŠ?ŌŁĄūÓƤĖ±ŲŅŖ¤Ź¼¼Šg?„ė©`„ė¤ĻŗĪ¤«£æ ”Ŗ »ĘŚµÄ¤ŹČÕ±¾¤ĪÖų×÷Ų·Ø47Ģõ7
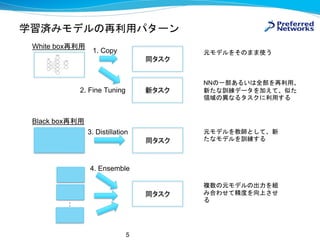
- 5. ѧĮg¤ß„ā„Ē„ė¤ĪŌŁĄūÓĆ„Ń„æ©`„ó 5 Ķ¬„愹„Æ ŠĀ„愹„Æ Ķ¬„愹„Æ 2. Fine Tuning White boxŌŁĄūÓĆ 1. Copy : 3. Distillation Black boxŌŁĄūÓĆ Ķ¬„愹„Æ 4. Ensemble ŌŖ„ā„Ē„ė¤ņ¤½¤Ī¤Ž¤ŽŹ¹¤¦ NN¤ĪŅ»²æ¤¢¤ė¤¤¤ĻČ«²æ¤ņŌŁĄūÓĆ”¢ ŠĀ¤æ¤ŹÓ¾„Ē©`„æ¤ņ¼Ó¤Ø¤Ę”¢Ėʤæ īIÓņ¤Ī®¤Ź¤ė„愹„ƤĖĄūÓƤ¹¤ė ŌŖ„ā„Ē„ė¤ņ½Ģ¤Č¤·¤Ę”¢ŠĀ ¤æ¤Ź„ā„Ē„ė¤ņÓ¾¤¹¤ė Ń}Źż¤ĪŌŖ„ā„Ē„ė¤Ī³öĮ¦¤ņ½M ¤ßŗĻ¤ļ¤»¤Ę¾«¶Č¤ņĻņÉĻ¤µ¤» ¤ė
- 6. CŠµŃ§Į¤ĪÖŖŲ¤ņ¤į¤°¤ėÓ¤ ”ń RIETI, ĘóI¤Ė¤Ŗ¤¤¤Ę°kÉś¤¹¤ė„Ē©`„æ¤Ī¹ÜĄķ¤Č»īÓƤĖév¤¹¤ėgŌ^ŃŠ¾æ, ”øIoT,BD,AI„Ē©`„æÖŖŲ¤Ėév¤¹¤ėŃŠ¾æ»į”¹ ”Ŗ http://www.rieti.go.jp/jp/projects/program_2016/pg-04/005.html ”ń ÄŚéwø® ÖŖµÄŲ®béĀŌ±¾²æ”øŠĀ¤æ¤ŹĒéóŲŹÓĪÆT»į”¹ ”Ŗ http://www.kantei.go.jp/jp/singi/titeki2/tyousakai/kensho_hyoka_kikaku/2017/joho zai/dai1/gijisidai.html ”ń ½Ug®bIŹ””¢”øµŚĖÄ“Ī®bIøļĆü¤ņŅŅ°¤ĖČė¤ģ¤æÖŖŲ„·„¹„Ę„ą¤ĪŌŚ¤ź·½¤Ėév ¤¹¤ėŹÓ»į”¹ ”Ŗ http://www.meti.go.jp/committee/kenkyukai/sansei/daiyoji_sangyo_chizai/001_hai fu.html ”ń MLEP (CŠµŃ§ĮĄūÓĆ“ŁßMĆć»į) ”ń Deep Learning©Õ»į£ØĖÉĪ²ĻČÉś£©
- 8. 8 ¾tÕŹ””øAIé_°k„¬„¤„Ʉ鄤„󔹤Ī×hÕ£Ø2016Äź12ŌĀ£© ”ń „Č„ķ„Ć„³ī}”¢”øŅ°Į¼AI”¹”¢¤Ź¤É¤Īī}Ņā×R¤«¤é„¹„æ©`„Č ”ń ”øgæŠŌ¤Ī¤¢¤ė”¹„¬„¤„Ʉ鄤„ó¤Č¤·¤Ę”øé_°kÕß”¹¤ĖŲČĪ¤ņŲ¤ļ¤»¤ė ”ń ¤æ¤Ą¤·”øAI”¹¤ņ¶ØĮx¤»¤ŗ ”Ŗ CŠµŃ§Į¤Ź¤É”øČĖ¹¤ÖŖÄܼ¼Šg”¹¤Č”¢¤½¤ģ¤ņźÓƤ·¤æ”ø„·„¹„Ę„ą”¹¤ņĒų e¤»¤ŗ ”ń ”øĶøĆ÷ŠŌ£ØÕhĆ÷æÉÄÜŠŌ£©”¹¤ņŅŖĒó ”Ŗ ÉīÓѧĮ¤Ė¤ĻoĄķ ”ń ”øé_°kÕß”¹¤Č”øĄūÓĆÕß”¹¤Ī¶žŌŖգؤā¤Ī¤Å¤Æ¤ź„Ń„é„Ą„¤„ą£© ”ń ÉīÓѧĮ¤Īé_°k?ĄūÓƤņĪ®æs¤µ¤»¤ėæ¹ū¤ņæ¼]¤»¤ŗ ”ń £ŗ
- 10. 10 2017Äź7ŌĀ ”ń ¹śėHµÄ¤Ź×hÕ¤Ī¤æ¤į¤Ī £Į£Éé_°k„¬„¤„Ʉ鄤„ó°ø ”ń ”øé_°kÕߤ¬×ńŹŲ¤¹¤Ł¤»łŹ¤ņ¶Ø¤į¤ė¤ā¤Ī¤Č¤·¤Ę¤Ē¤Ļ¤Ź¤Æ”¢é_°kÕߤ¬ĮōŅā¤· ¤Ęź¤·”¢ź×“r¤Ė¤Ä¤¤¤ĘĄūÓĆÕߵȤĖ¤·„¢„«„¦„ó„æ„Ó„ź„Ę„£¤ņ¹ū¤æ¤¹ ¤³¤Č¤¬ĘŚ“ż¤µ¤ģ¤ėŹĀķ¤Ėév¤·¹śėHµÄ¤Ė¹²ÓŠ¤µ¤ģ¤ė¤³¤Č¤¬ĘŚ“ż¤µ¤ģ¤ė·Ē¾ŠŹų µÄ¤ŹÖøį”¹ ”ń AI¤Č¤Ļ”¢”øѧĮµČ¤Ė¤č¤ź×Ō¤é¤Ī³öĮ¦¤ä„ׄķ„°„é„ą¤ņä»Æ¤µ¤»¤ė„½„Õ„Č„¦„§ „¢”¹ ”ń Google¤äamazon.com¤¬¤Ž¤ŗ„¬„¤„Ʉ鄤„ó¤ņŹŲ¤Ć¤Ę¤Æ¤ģ¤ė¤Ī¤Ź¤éZÓ
- 12. ”øČĖ¹¤ÖŖÄÜ”¹¤Ī£²¤Ä¤ĪÕZĮx ”ń ųÓĆČĖ¹¤ÖŖÄܣؔø¤¤ČĖ¹¤ÖŖÄÜ”¹£© ”Ŗ ¤¢¤é¤ę¤ėדr¤ĒČĖég¤ČĶ¬µČŅŌÉĻ¤ĪÖŖŠŌ¤ņŹ¾¤¹CŠµ ”Ŗ „æ©`„ß„Ķ©`„æ©`”¢HAL9000”¢āĶó„¢„Č„ą” ”ń ĢŲ»ÆŠĶČĖ¹¤ÖŖÄܣؔøČõ¤¤ČĖ¹¤ÖŖÄÜ”¹£© ”Ŗ £Ø¤½¤ģ¤Ž¤Ē×ŌӻƤ¬Ą§ėy¤Ē¤¢¤Ć¤æ£©ĢŲ¶Ø¤Ī„愹„Ƥņ½ā¤Æ„·„¹„Ę„ą ”Ŗ ½UĀ·Ģ½Ė÷”¢¤«¤Źh×ÖäQ”¢ĪļĮ÷×īßm»Æ”¢ÓÉĻÓčy”¢””¢CŠµ·ŌU”¢»ĻńÕJ×R”¢ ”Ŗ ¬FŌŚ×¢Ä椵¤ģ¤Ę¤¤¤ėŅŖĖŲ¼¼Šg¤Ļ ÉīÓѧĮ £Ø½yÓµÄCŠµŃ§Į¤ĪŅ»·ÖŅ°£© 12 “󤤏„®„ć„Ć„×
- 13. 13 IJCAI¤Ė¤Ŗ¤±¤ė×ŌĀÉŠŌ¤Ėév¤¹¤ė×hÕ ”ń Keynote by Stuart Russell, ”°Provably Beneficial AI”± ”Ŗ „ķ„܄ƄȤĖ„„ė„¹„¤„Ć„Į¤ņ¤Ä¤±¤ė¤Č£æ ”ō ČĖ£ŗ”ø„³©`„Ņ©`¤ņ¤Č¤Ć¤Ę¤¤Ę”¹ ”ō „ķ„Ü„Ć„Č£ŗ ”°×Ō·Ö¤¬Ó¤±¤Ź¤Æ¤Ź¤Ć¤æ¤éÄæµÄ¤¬ß_³É¤Ē¤¤Ź¤¤”± ”ś ¤Ž¤ŗ „„ė„¹„¤„Ć„Į¤ņoæ»Æ ”Ŗ ČĖ¤ĪŅāķ¤¬³£¤ĖįĆĮ¤Ē¤¢¤ė¤³¤Č¤ņ½Ģ¤Ø¤Ź¤±¤ģ¤Š¤Ź¤é¤Ź¤¤ ”ń Tom Everitt, ”°Reinforcement Learning with a Corrupted Reward Channel”± ”Ŗ ”°Wirehead”±ī}”£»ÆѧĮ¤Ė¤Ŗ¤¤¤Ęó³źévŹż¤¬Õż¤·¤Æ¤Ź¤«¤Ć¤æ¤éŗĪ¤¬Ęš ¤¤ė¤«”£ ¤É¤Į¤é¤ā”¢×īßm»Æī}¤Ė¤Ŗ¤±¤ė”øÕż¤·¤¤ŹĖ¤Ī¤¢¤ź·½”¹¤Īī}¤ņĢįĘš
- 15. CŠµŃ§Į„·„¹„Ę„ą¤Ļ”¢øß½šĄū„Æ„ģ„ø„Ć„Č£” ? CACE (Changing Anything Changes Everything) ŌĄķ ØC ¤¹¤Ł¤Ę¤¬½j¤ßŗĻ¤Ć ¤Ę¤¤¤ė ? „°„ė©`„³©`„É”¢ŌņYµÄ¤Ź„³©`„Éʬ¤Ź ¤É”¢¤¹¤Ł¤Ę¤¬½«Ą“¤Ī„į„¤„ó„Ę„Ź„¹¤Ī ō¤Ė¤Ä¤Ź¤¬¤ė ? ” https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43146.pdf
- 16. „Ń„¤„ׄ鄤„ó¤Č„¤„󄹄Ąė„į„ó„Ę©`„·„ē„ó ETL Data prep Training Serving Data prep Data Source Raw Data Training data set Trained Model Pipeline Instrumentation
- 17. „Ļ„¤„Ń©`„Ń„é„į„æ¤Ī„Į„å©`„Ė„ó„° „ā„Ē„ė¤ĪŃ}ėj¤µ¤¬×椟¤Ź¤¤īIÓņ - More layer / nodes ß^ѧĮ¤ĪīIÓņ - Reduce model size - More generalization (dropout etc.) - More training data ”°Typical relationship between capacity and error”±, p. 115 of Goodfellow, I., Bengio, Y., and Courville, A.: Deep Learning, MIT Press, 2016
- 18. Learning Rate ¤Ļ¤¤¤ķ¤¤¤ķŌ¤·¤Ę¤ß¤ė¤Ł¤ ”°If you have time to tune only one hyperparameter, tune the learning rate”±, p. 431 of Goodfellow, I., Bengio, Y., and Courville, A.: Deep Learning, MIT Press, 2016
- 22. 22 Ķ¬¤Ė”¢½ń¤³¤½ ”°CŠµŃ§Į¹¤Ń§”± ¤ņ! ”ń ŅŖĒó¹¤Ń§ ”Ŗ CŠµŃ§Į¤Ī„į„ź„Ć„Č?ĻŽ½ē¤ņ¤É¤Ī¤č¤¦¤Ė„¹„Ę©`„Æ„Ū„ė„Ą¤Č¹²ÓŠ¤¹¤ė¤«£æ ”Ŗ ÄæµÄévŹż¤ņ¤É¤Ī¤č¤¦¤ĖŌO¶Ø¤¹¤ė¤« ”ń „Ä©`„ė ”Ŗ CŠµŃ§Į¤Ė¤Ŗ¤±¤ėIDE¤Č¤Ļ? ”Ŗ CŠµŃ§Į¤Ī³É¹ūĪļ”¢ĢŲ¤ĖÓ¾„Ē©`„æ„»„ƄȤČѧĮg¤ß„ā„Ē„ė¤ņ¤É¤Ī¤č¤¦¤Ė„ź„Ż „ø„Č„ź¹ÜĄķ¤¹¤ė¤«£æ ”Ŗ ß^¶Č¤Ė×ŌӻƤµ¤ģ¤æ„Ä©`„ė¤Ė¤č¤ėß^ѧĮ¤ņ¤É¤Ī¤č¤¦¤Ė±Ü¤±¤ė¤«? ”ń „Ę„¹„Č ”Ŗ CŠµŃ§Į¤Ė¤Ŗ¤±¤ė ”°„ź„°„ģ„Ć„·„ē„ó?„Ę„¹„Č”± ¤Č¤Ļ? ”Ŗ „Ę„¹„ČńlÓé_°k(TDD)¤«¤éѧ¤Ł¤ė¤³¤Č¤ĻŗĪ¤«? ”ń ß\ÓĆ ”Ŗ ѧĮg¤ß„ā„Ē„ė¤Ī”øŁpĪ¶ĘŚĻŽ”¹¤ņ¤É¤Ī¤č¤¦¤ĖŹ³ö¤¹¤ė¤«?