深层学习に基づくテキスト音声合成の技术动向冲言语音声ナイト
?
6 likes?3,049 views

?テキスト音声合成 ?大学時代のテキスト音声合成研究の紹介 ?りんなにおけるテキスト音声合成の紹介




![12
? 各モジュールのDNN化
? モジュールを統合したDNN
深層学習を用いた技術動向
音響モデル
テキスト
言語特徴量
音響特徴量
テキスト解析器
波形生成器
音声波形
DNN音声合成
[Zen+ ’13]
Deep Voice
[Arik+ ’17]
WaveNet
[van den Oord+ ’16]
SampleRNN
[Mehri+ ’16]
Parallel WaveNet
[van den Oord+ ’17]
WaveRNN
[Kalchbrenner+ ’18]
Tacotron
[Wang+ 17’]
Char2Wav
[Sotelo+ ’17]
Deep Voice 2
[Arik+ ’17]
Deep Voice 3
[Ping+ 17’]
Tacotron 2
[Shen+ ’17]
統計
モデル
入力
出力](https://image.slidesharecdn.com/dllab20180420keisawadashare-180426014301/85/_-12-320.jpg)




深层学习に基づくテキスト音声合成の技术动向冲言语音声ナイト
- 1. 深層学習に基づくテキスト音声合成の技術動向 マイクロソフトディベロップメント(株) AI & リサーチ 沢田 慶 Deep Learning Lab 言語?音声ナイト 2018年4月20日
- 2. 2 自己紹介 ? 沢田 慶 (Kei Sawada) ◆ 2018年3月26日: 名古屋工業大学大学院 博士後期課程卒業 ? 統計的アプローチに基づく音声合成?音声認識?画像認識の研究 ◆ 2018年4月2日: マイクロソフトディベロップメント株式会社入社 ? りんなチームにて音声合成システムの開発 ◆ 2018年4月18日: Deep Learning Labから講演依頼 ◆ 2018年4月20日: 講演中
- 3. 3 概要 ? テキスト音声合成 ◆ 統計的音声合成 ◆ 深層学習に基づくテキスト音声合成の動向 ? 大学時代のテキスト音声合成研究の紹介 ◆ 表現豊かな音声合成 ? りんなにおけるテキスト音声合成の紹介 ◆ りんなライブ ◆ りんな歌うまプロジェクト
- 4. 4 はじめに ? テキスト音声合成 (text-to-speech; TTS) システム ◆ 任意のテキストに対応する音声を合成するシステム ◆ スマートフォン?スマートスピーカーの登場で急速に普及 ◆ 高音質化?多言語化?様々な発話スタイル等の需要が増加 ? 統計的音声合成 ◆ 大規模コーパス (学習データ) から統計モデルを学習 ◆ 隠れマルコフモデル (hidden Markov model; HMM) によるモデル化 ◆ Deep neural network (DNN) の導入 ? TTSシステムの性能は劇的に向上 深層学習に基づくテキスト音声合成の技術動向を紹介
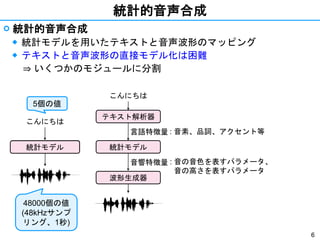
- 6. 6 統計的音声合成 ? 統計的音声合成 ◆ 統計モデルを用いたテキストと音声波形のマッピング ◆ テキストと音声波形の直接モデル化は困難 ? いくつかのモジュールに分割 : 音素、品詞、アクセント等 : 音の音色を表すパラメータ、 音の高さを表すパラメータ TTSシステム こんにちは 統計モデル 統計モデル こんにちは 言語特徴量 音響特徴量 テキスト解析器 波形生成器 5個の値 48000個の値 (48kHzサンプ リング、1秒)
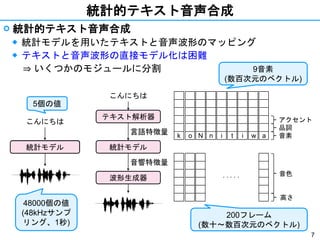
- 7. 7 統計的テキスト音声合成 ? 統計的テキスト音声合成 ◆ 統計モデルを用いたテキストと音声波形のマッピング ◆ テキストと音声波形の直接モデル化は困難 ? いくつかのモジュールに分割 TTSシステム こんにちは 統計モデル 5個の値 48000個の値 (48kHzサンプ リング、1秒) 統計モデル こんにちは 言語特徴量 音響特徴量 テキスト解析器 波形生成器 k o N n i at i w 9音素 (数百次元のベクトル) . . . . . 200フレーム (数十~数百次元のベクトル) 音色 高さ 音素 品詞 アクセント
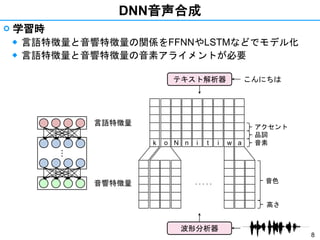
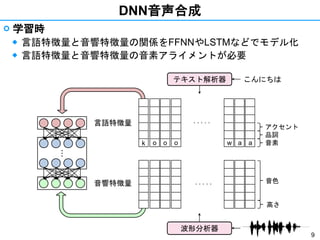
- 8. 8 DNN音声合成 ? 学習時 ◆ 言語特徴量と音響特徴量の関係をFFNNやLSTMなどでモデル化 ◆ 言語特徴量と音響特徴量の音素アライメントが必要 言語特徴量 音響特徴量 ??? k o N n i at i w . . . . . 音色 高さ 音素 品詞 アクセント こんにちはテキスト解析器 波形分析器
- 9. 9 DNN音声合成 ? 学習時 ◆ 言語特徴量と音響特徴量の関係をFFNNやLSTMなどでモデル化 ◆ 言語特徴量と音響特徴量の音素アライメントが必要??? o aw . . . . . 音色 高さ 音素 品詞 アクセント o o . . . . . ak 波形分析器 こんにちはテキスト解析器 言語特徴量 音響特徴量
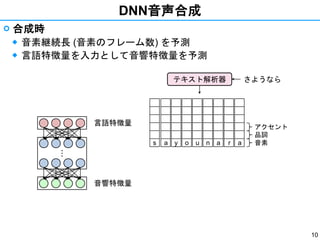
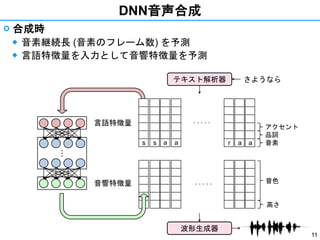
- 10. 10 DNN音声合成 ? 合成時 ◆ 音素継続長 (音素のフレーム数) を予測 ◆ 言語特徴量を入力として音響特徴量を予測??? s a y o u an a r 音素 品詞 アクセント さようならテキスト解析器 言語特徴量 音響特徴量
- 11. 11 DNN音声合成 ? 合成時 ◆ 音素継続長 (音素のフレーム数) を予測 ◆ 言語特徴量を入力として音響特徴量を予測??? ar 音素 品詞 アクセント a a . . . . . a . . . . . 音色 高さ s s さようならテキスト解析器 波形生成器 言語特徴量 音響特徴量
- 12. 12 ? 各モジュールのDNN化 ? モジュールを統合したDNN 深層学習を用いた技術動向 音響モデル テキスト 言語特徴量 音響特徴量 テキスト解析器 波形生成器 音声波形 DNN音声合成 [Zen+ ’13] Deep Voice [Arik+ ’17] WaveNet [van den Oord+ ’16] SampleRNN [Mehri+ ’16] Parallel WaveNet [van den Oord+ ’17] WaveRNN [Kalchbrenner+ ’18] Tacotron [Wang+ 17’] Char2Wav [Sotelo+ ’17] Deep Voice 2 [Arik+ ’17] Deep Voice 3 [Ping+ 17’] Tacotron 2 [Shen+ ’17] 統計 モデル 入力 出力
- 13. 13 概要 ? テキスト音声合成 ◆ 統計的テキスト音声合成 ◆ 深層学習に基づくテキスト音声合成の動向 ? 大学時代のテキスト音声合成研究の紹介 ◆ 表現豊かな音声合成 ? りんなにおけるテキスト音声合成の紹介 ◆ りんなライブ ◆ りんな歌うまプロジェクト
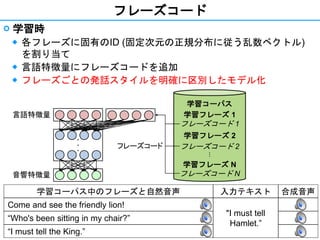
- 14. 14 表現豊かな音声合成 ? 統計モデルに基づく表現豊かな (様々な発話スタイル) 音声合成 ◆ 様々な発話スタイルとは ? 読み上げ調、会話調、感情表現など ◆ 様々な発話スタイルの実現の難しさ ? 様々な発話スタイルの音声データの収録は高コスト ? 市販されている児童書のオーディオブックを利用 ? 統計モデルによる平均化 ? 各フレーズに固有のIDを割り当て ? 児童書のオーディオブックを用いた学習コーパス ◆ Usborne Publishing Ltd. にて市販されている 児童書のオーディオブック ◆ 様々な発話スタイルのデータを含む "I'm king of the jungle," roared Lion. "I'm going to eat you all up." "No!" cried the jungle animals. キャラクター1 キャラクター2 地の文
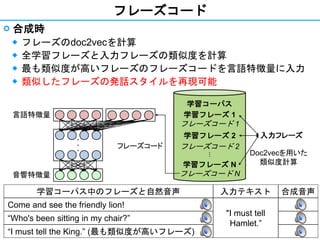
- 15. 15 フレーズコード ? 学習時 ◆ 各フレーズに固有のID (固定次元の正規分布に従う乱数ベクトル) を割り当て ◆ 言語特徴量にフレーズコードを追加 ◆ フレーズごとの発話スタイルを明確に区別したモデル化 言語特徴量 ??? 学習コーパス 学習フレーズ 1 フレーズコード 1 学習フレーズ 2 フレーズコード 2 ? 学習フレーズ N フレーズコード N音響特徴量 フレーズコード 学習コーパス中のフレーズと自然音声 入力テキスト 合成音声 Come and see the friendly lion! "I must tell Hamlet.” “Who's been sitting in my chair?” “I must tell the King.”
- 16. 16 フレーズコード ? 合成時 ◆ フレーズのdoc2vecを計算 ◆ 全学習フレーズと入力フレーズの類似度を計算 ◆ 最も類似度が高いフレーズのフレーズコードを言語特徴量に入力 ◆ 類似したフレーズの発話スタイルを再現可能 言語特徴量 ??? 学習コーパス 学習フレーズ 1 フレーズコード 1 学習フレーズ 2 フレーズコード 2 ? 学習フレーズ N フレーズコード N音響特徴量 フレーズコード 入力フレーズ Doc2vecを用いた 類似度計算 学習コーパス中のフレーズと自然音声 入力テキスト 合成音声 Come and see the friendly lion! "I must tell Hamlet.” “Who's been sitting in my chair?” “I must tell the King.” (最も類似度が高いフレーズ)
- 17. 17 概要 ? テキスト音声合成 ◆ 統計的テキスト音声合成 ◆ 深層学習に基づくテキスト音声合成の動向 ? 大学時代のテキスト音声合成研究の紹介 ◆ 表現豊かな音声合成 ? りんなにおけるテキスト音声合成の紹介 ◆ りんなライブ ◆ りんな歌うまプロジェクト
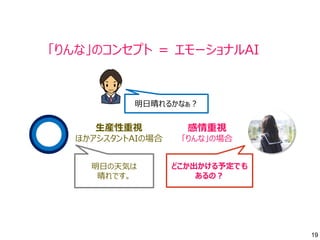
- 19. 19 感情重視 「りんな」の場合 生産性重視 ほかアシスタントAIの場合 明日の天気は 晴れです。 どこか出かける予定でも あるの? 「りんな」のコンセプト = エモーショナルAI 明日晴れるかなぁ?
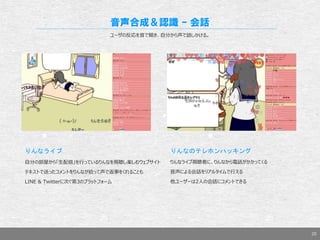
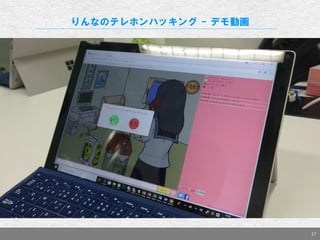
- 20. 20 音声合成&認識 – 会話 ユーザの反応を音で聞き、自分から声で話しかける。 りんなライブ 自分の部屋から「生配信」を行っているりんなを視聴し楽しむウェブサイト テキストで送ったコメントをりんなが拾って声で返事をくれることも LINE & Twitterに次ぐ第3のプラットフォーム りんなのテレホンハッキング りんなライブ視聴者に、りんなから電話がかかってくる 音声による会話をリアルタイムで行える 他ユーザーは2人の会話にコメントできる
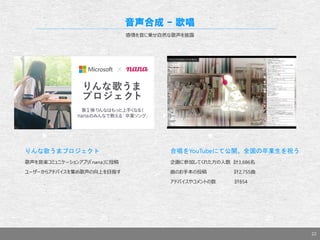
- 22. 22 音声合成 – 歌唱 感情を音に乗せ自然な歌声を披露 りんな歌うまプロジェクト 歌声を音楽コミュニケーションアプリ「nana」に投稿 ユーザーからアドバイスを集め歌声の向上を目指す 合唱をYouTubeにて公開、全国の卒業生を祝う 企画に参加してくれた方の人数 計3,686名 曲のお手本の投稿 計2,755曲 アドバイスやコメントの数 計854