




![ҳOӮҺӨО·ЦІј
7
Ұ«EinfТФЙПӨЛӨПЎў
kӨ¬?РЎӨөӨӨҳOӮҺӨП
ӨЫӨИӨуӨЙіц¬FӨ·ӨКӨӨ
ЈЁҙщӨЙӨ¬°°өгЈ©
ЎъҗҷӨӨҳO?РЎӮҺӨП
?ЎЎ?ТҠТҠӨДӨ«ӨйӨКӨӨ
ӨЮӨҝЈ¬[Ұ«E0, ?Ұ«Einf]
ӨО?ҙуӨӯӨӨ?·ҪӨЛӨПkӨ¬
?ҙуӨӯӨӨӨОӨ¬¶аӨҜЎў
?РЎӨөӨӨ?·ҪӨПkӨ¬?РЎӨөӨӨ
ӨОӨ¬¶аӨӨ
ЎъҳO?РЎӮҺӨПӨЯӨуӨК
?ЎЎЧо?РЎӮҺӨОҪьӨҜӨЗ
?ЎЎ?ТҠТҠӨДӨ«Өл](https://image.slidesharecdn.com/dnnunsolvedproblems-160520091046/85/DNN-7-320.jpg)








![GANӨПәОӨтӨ·ӨЖӨӨӨлӨіӨИӨЛӨКӨлӨОӨ«Јҝ
l?? GANӨОGӨЛӨДӨӨӨЖӨОҘӘҘкҘёҘКҘлӨОёьёьРВКҪӨПҙОӨОНЁӨкӨЗӨўӨл
l?? Ө·Ө«Ө·Ўўlog(1 ?ЁC ?x)ӨПxӨ¬?РЎӨөӨӨҲцәПЎў№ҙЕдӨ¬?РЎӨөӨӨӨОӨЗҙъӨпӨкӨЛҙОӨтК№ӨҰ
l?? ӨіӨО?¶юӨДӨОКҪӨтҪMӨЯәПӨпӨ»Өҝ
?ЎЎӨіӨмӨПKL[Q||P]ӨОЧо?РЎ»ҜӨтӨ·ӨЖӨӨӨлӨіӨИӨЛҢқҸкӨ№Өл
?ЎЎ?ЎЎ?ЎЎQ ?: ??ЙъіЙҘвҘЗҘлӨО·ЦІј, ?PЈәҪUтY·ЦІј
17](https://image.slidesharecdn.com/dnnunsolvedproblems-160520091046/85/DNN-17-320.jpg)


![ОҙҪвӣQҶ–о}
l?? ҝЙүд??йL-©\??>№М¶Ё??йLӨОЗйҲуӨОВсӨбЮzӨЯӨПӨЙӨОӨиӨҰӨЛҢg¬FӨөӨмӨЖӨӨӨлӨОӨ«Јҝ
ЁC? АэАэӨЁӨРЎў?Ил?БҰБҰ?ОДӨ«ӨйҳӢ?ОДҪвОцӨ№ӨлАэАэӨЗӨПЎўҘ№ҘҝҘГҘҜӨОҷCДЬӨПҢg¬FӨөӨмӨЖӨӨӨл
ЁC? ФЩҺўӨтә¬Өа?ОДӨКӨЙӨПӨЙӨОӨиӨҰӨЛВсӨбЮzӨЮӨмӨЖӨӨӨлӨОӨ«ЈҝӨвӨ·ӨҜӨПВсӨбЮzӨЮӨмӨЖӨӨӨК
ӨӨӨОӨ«
l?? №М¶Ё??йL ?-©\??> ?ҝЙүд??йLӨОЗйҲуӨОХ№й_ӨПӨЙӨОӨиӨҰӨЛҢg¬FӨөӨмӨЖӨӨӨлӨОӨ«Јҝ
l?? ӨіӨОҲцәПЎў¶МЖЪУӣ‘ӣӨОИЭБҝБҝӨПДЪІҝұн¬FӨОhn+1ӨЛҘРҘҰҘуҘЙӨөӨмӨЖӨӨӨл
ЁC? ?Т»·NӨОAutoEncoderӨОХэ„t»ҜӨОӨиӨҰӨКТЫёоӨт№ыӨҝӨ·ӨЖӨӨӨлӨ«ӨвӨ·ӨмӨКӨӨ
l?? ¶МЖЪУӣ‘ӣӨОИЭБҝБҝӨтӨўӨІӨлӨЛӨПӨЙӨҰӨ№ӨмӨРӨиӨӨӨ«Јҝ
ЁC? AttentionӨтК№ӨГӨЖ?Ил?БҰБҰӨ«ӨйЦұҪУЛјӨӨіцӨ№ЈЁјИҙжСРҫҝ¶аКэЈ©
l?? ЦШӨЯӨт?Т»ҙОөДӨЛүдӨЁӨлӨіӨИӨЗУӣ‘ӣӨ№ӨлӨіӨИӨвҝЙДЬ
ЁC? ЯBПлУӣ‘ӣӨОҢg¬F
ЁC? HintonӨ¬МбіӘӨ·ӨЖӨӨӨл[2015]Ө¬Ј¬Ңg¬FӨПӨЮӨАӨИЛјӨпӨмӨлЈЁЯ^ИҘӨЛјИӨЛӨўӨлӨ«ЈҝЈ©
21](https://image.slidesharecdn.com/dnnunsolvedproblems-160520091046/85/DNN-21-320.jpg)





ПЦФЪӨО¶Щұ·ұ·ӨЛӨӘӨұӨлОҙҪвҫцОКМв
- 1. ¬FФЪӨОDNNӨО ОҙҪвӣQҶ–о} ҢщТ°Фӯ?ЎЎ?ҙуЭo hillbig@preferred.jp Preferred ?Networks, ?Inc. 2016/5/20 Г—РНјЖЛглjМё»б
- 2. DNNӨООҙҪвӣQҶ–о} l?? ¬FФЪӨОDNNӨПҢg?УГөДӨЛіЙ№ҰӨ·ӨЖӨӨӨлӨ¬ЎўФӯАнАнӨтАнАнҪвӨЗӨӯӨЖӨӨӨКӨӨӨҝӨбЎўӨКӨј ӨіӨіӨЮӨЗӨҰӨЮӨҜӨӨӨҜӨОӨ«ЈЁӨЮӨҝЎўӨҰӨЮӨҜӨӨӨ«ӨКӨӨӨОӨ«Ј©ӨпӨ«ӨГӨЖӨӨӨКӨӨ l?? ӨіӨіӨЗӨПЎў¬FФЪӨОDNNӨОҙъұнөДӨКОҙҪвӣQҶ–о}ӨтҪBҪйӨ·ӨҝӨӨ l?? Ө№ӨЗӨЛЯ^ИҘӨЛҙрӨЁӨ¬ӨЗӨЖӨӨӨлҶ–о}Ө«ӨвӨ·ӨмӨәЎўӨЯӨКӨөӨЮӨО?БҰБҰӨтӨӘҪиӨкӨ·ӨҝӨӨ 2
- 3. ¬FФЪӨОDNNӨт1Г¶ӨЗӨӘӨөӨйӨӨ l?? »оРФ»ҜйvКэӨЛӨПЗш·ЦҫҖРОйvКэӨтК№ӨӨЎўҒ»°бӨПңpЛҘ/°kЙўӨвӨ·ӨКӨҜӨКӨГӨҝ ЁC? АэАэЈәRelu ?f(x) ?= ?max(0, ?x) ? ? ? ? ? ?ӨіӨмӨПsoftplus ?log(1+exp(x))ӨОhard°ж l?? ЧоЯm»ҜӨЛӨПRMSPropӨдAdamӨКӨЙHessianӨОҘӘҘуҘйҘӨҘуНЖ¶Ё°жӨтК№ӨҰ l?? BatchХэТҺ»ҜҢУӨЗЎўёчҢУӨО?Ил?БҰБҰӨПіЈӨЛЖҪҫщ0, ?·ЦЙў1ӨЛХэТҺ»ҜӨ·С§Б•ӨтИЭТЧТЧӨЛ l?? ResNet: ?f(x) ?= ?x ?+ ?h(x) ?ӨтК№ӨҰӨіӨИӨЗ ?1000ҢУӨті¬ӨЁӨЖӨвС§Б•ҝЙДЬӨЛ l?? үд·ЦҘЩҘӨҘәӨИӨОИЪәПӨЗЎў?·ЗҫҖРОӨО?ЙъіЙҘвҘЗҘлӨОС§Б•ӨвИЭТЧТЧӨЛ ЁC? МШӨЛЗұФЪүдКэӨ¬ЯBҫAүдКэӨОҲцәПӨПүдКэүд“QҘИҘкҘГҘҜӨЗ„ҝВКВКВКӨиӨҜС§Б•ҝЙДЬ ЁC? °лҪМҺҹӨўӨкС§Б•Ўў1Ҙ·ҘзҘГҘИС§Б•Ө¬ҝЙДЬӨЛ l?? ҸҠ»ҜС§Б•ӨИӨОИЪәПӨЗЎў?ЙъӨО?Ил?БҰБҰӨ«ӨйӨОФuҒэйvКэӨд?РРРР„УЯx’kӨ¬ҝЙДЬӨЛ l?? ҘўҘЖҘуҘ·ҘзҘуӨОКЛҪMӨЯӨЛӨиӨГӨЖЎў?Иліц?БҰБҰӨО?Т»ІҝӨт„УөДӨЛҘХҘ©©`Ҙ«Ҙ№ӨЗӨӯӨл l?? GPUӨтАыАы?УГӨ·Ј¬Кэ?К®T?opsіМ¶И¶ИӨОУӢЛгҘкҘҪ©`Ҙ№ӨЗС§Б•ЎўҘСҘйҘб©`ҘҝКэӨПКэғ| 3
- 4. 1. ??ҙуӨӯӨКNNӨОС§Б•ӨПӨКӨј?Т»ҳ”ӨЛіЙ№ҰӨ№ӨлӨ« l?? ?ҙуӨӯӨКNNЈЁFeedForwardЈ©ӨОҲцәПЎўӨЙӨОӨиӨҰӨКіхЖЪӮҺӨЗӨвЎўҫЦЛщЧоЯmҪвӨЗҪK БЛБЛӨ·ӨЖӨвС§Б•ҪY№ыӨПӨЯӨКН¬іМ¶И¶ИӨЛғһӨмӨЖӨӨӨлӨіӨИӨ¬ҢgтYҪY№ыӨ«ӨйӨпӨ«ӨГӨЖӨӨӨл ЁC? ҹoКэӨОҫЦЛщҪвӨ¬ӨўӨлӨЛӨвӨ«Ө«ӨпӨйӨәЎўӨҪӨмӨйӨОҫЦЛщҪвӨП?ТҠТҠӨДӨұӨлӨОӨ¬әҶ…gӨЗӨўӨкЎў Ө«ӨДЎўӨҪӨмӨйӨОҘЖҘ№ҘИҘЁҘй©`ӨПҙщӨЙН¬ӨёӨЗӨўӨл l?? МШӨЛҙОӨОИэӨДӨО¬FПуӨ¬ӨЯӨйӨмӨл 1.? ?ҙуӨӯӨКҘНҘГҘИҘп©`ҘҜӨЗӨПЈ¬ӨЫӨИӨуӨЙӨОҫЦЛщҪвӨОҘЖҘ№ҘИҘЁҘй©`Ө¬Н¬ӨёӨЗӨўӨл 2.? җҷӨӨҫЦЛщҪвӨт?ТҠТҠӨДӨұӨлҙ_ВКВКВКӨП?РЎӨөӨӨҘНҘГҘИҘп©`ҘҜӨАӨИ?ҙуӨӯӨҜЈ¬ҘөҘӨҘәӨ¬?ҙуӨӯ ӨҜӨКӨлӨЛҸҫӨГӨЖЎўјұЛЩӨЛ?РЎӨөӨҜӨКӨл 3.? ?ҙуУтЧоЯmҪвӨт?ТҠТҠӨДӨұӨлӨОӨПІ»І»ҝЙДЬӨКӨЫӨЙӨЛлyӨ·ӨӨӨ¬Ўў?ТҠТҠӨДӨұӨйӨмӨҝӨИӨ·ӨЖӨв С§Б•ҘЗ©`ҘҝӨЛЯ^ЯmәПӨ·ӨЖӨӘӨкЎўҘЖҘ№ҘИҘЁҘй©`ӨП?ҙуӨӯӨӨ ӨКӨјЎўӨіӨОӨиӨҰӨКӨіӨИӨ¬ЖрӨӯӨлӨОӨ«Јҝ 4
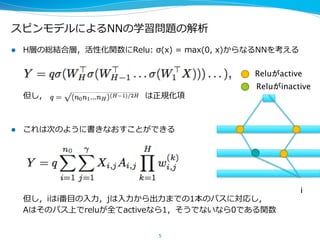
- 5. Ҙ№ҘФҘуҘвҘЗҘлӨЛӨиӨлNNӨОС§Б•Ҷ–о}ӨОҪвОц l?? HҢУӨОҫtҪYәПҢУЈ¬»оРФ»ҜйvКэӨЛRelu: ?ҰТ(x) ?= ?max(0, ?x)Ө«ӨйӨКӨлNNӨтҝјӨЁӨл ө«Ө·Ј¬ ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?ӨПХэТҺ»Ҝн— l?? ӨіӨмӨПҙОӨОӨиӨҰӨЛ•шӨӯӨКӨӘӨ№ӨіӨИӨ¬ӨЗӨӯӨл ө«Ө·Ј¬iӨПi·¬?ДҝӨО?Ил?БҰБҰЈ¬jӨП?Ил?БҰБҰӨ«Өйіц?БҰБҰӨЮӨЗӨО1ұҫӨОҘСҘ№ӨЛҢқҸкӨ·Ј¬ AӨПӨҪӨОҘСҘ№ЙПӨЗreluӨ¬И«ӨЖactiveӨКӨй1Ј¬ӨҪӨҰӨЗӨКӨӨӨКӨй0ӨЗӨўӨлйvКэ 5 i ReluӨ¬active ReluӨ¬inactive
- 6. l?? ӨөӨӯӨЫӨЙӨОйvКэӨОҪ~ҢқӮҺ“pК§йvКэЈ¬ӨЮӨҝӨПҘТҘуҘё“pК§йvКэӨПЎў ҳ”Ў©ӨКҒў¶ЁЈЁббКцЈ©ӨтјУӨЁӨлӨИҙОӨОЗтРОҘ№ҘФҘуҘ°ҘйҘ№ҘвҘЗҘлӨИӨЯӨКӨ»Өл ?ЎЎ ө«Ө·Ј¬ ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ӨіӨОЗтРОҘ№ҘФҘуҘ°ҘйҘ№ҘвҘЗҘлӨЛӨДӨӨӨЖӨПҳ”Ў©ӨКРФЩ|Ө¬ӨпӨ«ӨГӨЖӨӨӨл МШӨЛЈ¬ӨҪӨОҳOӮҺӨЛӨДӨӨӨЖӨОРФЩ|ӨЛӨДӨӨӨЖ·ЦОцӨЗӨӯӨл ?ЎЎk ?: ?ҳOӮҺӨОҘШҘ·ҘўҘуӨЛӨДӨӨӨЖЎўШ“ӨО№МУРӮҺӨ¬ӨӨӨҜӨДӨўӨлӨ« ?ЎЎ?ЎЎШ“ӨО№МУРӮҺ=ПВПтӨӯӨЛЗъӨ¬ӨГӨЖӨӨӨл?·ҪПт ?ЎЎk=0 ?ҳO?РЎӮҺ, ?k>0 ?°°өг ??ЎЎ 6
- 8. 8
- 9. Ҙ№ҘФҘуҘвҘЗҘлӨЛӨиӨлNNӨОҪвОц l?? ҢgтYҪY№ыӨИӨўӨҰӨ¬Ўў?·З¬FҢgөДӨКҒў¶ЁӨ¬ӨўӨўӨкЎўӨіӨмӨйӨОҒў¶ЁӨтіэӨұӨлӨ«ЎўӨЮ ӨҝӨПҘЗ©`ҘҝӨдҘвҘЗҘлӨ¬ӨҪӨОҒў¶ЁӨтңәӨҝӨ·ӨЖӨӨӨлӨИӨӨӨЁӨлӨ«Ө¬Ҷ–о}ӨИӨКӨл l?? МШӨЛЎўЎё»оРФӨП?Ил?БҰБҰӨЛТАҙжӨ»Өә¶А?БўБўӨЗӨўӨлЎ№ЎёёчҘСҘ№ӨО?Ил?БҰБҰӨП¶А?БўБўӨЗӨўӨлЎ№ ӨИӨӨӨҰҒў¶ЁӨ¬Ҷ–о} l?? Щ|Ҷ–ӨиӨк ?ЎЎӨіӨОМхјюӨтңәӨҝӨ№ӨиӨҰӨЛNNӨтЧчӨмӨмӨРС§Б•Ө¬Ө·ӨдӨ№ӨҜӨКӨлӨ« ?ЎЎЎъ?ЎЎӨҪӨҰӨЗӨўӨлЎЈ?Т»?·ҪӨЗҪсӨОNNӨ¬јИӨЛӨіӨОМхјюӨтӨЯӨҝӨ·ӨЖӨӨӨлҝЙДЬРФӨвӨўӨл ?ЎЎ?ЎЎ?ЎЎLDPCӨ¬¶МӨӨҘөҘӨҘҜҘлӨтә¬ӨЮӨКӨӨӨиӨҰӨК?РРРРБРБРӨтК№ӨГӨЖӨӨӨлӨОӨИН¬ҳ”ӨЛNN ?ЎЎ?ЎЎ?ЎЎӨОҪУҫAӨвӨіӨОМхјюӨтңәӨҝӨ№ӨиӨҰӨЛ?№ӨС§өДӨЛФOУӢӨЗӨӯӨКӨӨӨ« ?ЎЎ?ҙуӨӯӨӨӨИӨӨӨҰӨОӨПӨЙӨҰӨӨӨҰТвО¶Ө« ?ЎЎЎъ?ЎЎЙоӨөӨЛӨДӨӨӨЖӨП2ҢУТФЙПӨЗӨўӨмӨРӨіӨмӨ¬іЙӨк?БўБўӨДЎЈЦШТӘӨКӨОӨПёчҢУӨО ?ЎЎ?ЎЎ?ЎЎЖҪҫщӨОҘжҘЛҘГҘИКэ?ЎЎ100Өті¬ӨЁӨҝӨўӨҝӨкӨ«ӨйӨіӨО¬FПуӨ¬ӨӘӨіӨл ?ЎЎ 9
- 10. 2.?ЎЎ”іҢқөД?ЙъіЙҘНҘГҘИҘп©`ҘҜ(GAN)ӨОҪвОц ? l?? GANӨПҙОӨО?¶юӨДӨОҘНҘГҘИҘп©`ҘҜӨтёӮәПӨөӨ»ӨЖС§Б•Ө№Өл G(z) ?: ??ЙъіЙҘНҘГҘИҘп©`ҘҜ ? ?zӨ«ӨйxӨт?ЙъіЙӨ№ӨлӣQ¶ЁөДӨКҘНҘГҘИҘп©`ҘҜ ?ЎЎ?ЎЎ?ЎЎ ?ӨПӨёӨбӨЛp(z)ӨЛҸҫӨГӨЖzӨт?ЙъіЙӨ·Ј¬ӨДӨ®ӨЛx=G(z)ӨтЗуӨбӨл D(x) ?: ?ЧRЧR„eҘНҘГҘИҘп©`ҘҜ ? ?xӨ¬ХжӨОҘЗ©`ҘҝУЙАҙӨКӨОӨ«Ўў?ЙъіЙУЙАҙӨ«ӨтЧRЧR„e ӨіӨО•rЎўҙОӨОЧоЯm»ҜҶ–о}ӨтG, ?DӨҪӨмӨҫӨмӨЛӨДӨӨӨЖҪвӨҜ GӨПDӨЛ?ТҠТҠЖЖӨйӨмӨКӨӨӨиӨҰӨЛӨиӨкХжӨОҘЗ©`ҘҝӨЛЛЖӨлӨиӨҰӨЛ?ЙъіЙӨ·Ўў DӨПҘЗ©`ҘҝУЙАҙӨ«GУЙАҙӨ«ӨтЧRЧR„eӨЗӨӯӨлӨиӨҰӨЛіЙ??йLӨ№Өл ӨіӨОЧоЯm»ҜҶ–о}ӨОЧоЯmҪвӨПЈ¬pG=pdataӨЗӨўӨкЎўӨЮӨҝGӨИDӨтҪ»»ҘӨЛС§Б•Ө№Өл?·Ҫ·Ё ӨЗЧоЯmҪвӨЛөҪЯ_Ө№ӨлӨіӨИӨ¬ЦӘӨйӨмӨЖӨӨӨл 10
- 13. 2•rйgбб 13
- 14. 1?ИХбб 14
- 15. 15
- 16. GANӨОМШҸХ l?? ·ЦёойvКэӨдMCMCӨтК№ӨҰӨіӨИӨКӨҜЈ¬?ЙъіЙҘвҘЗҘлӨОС§Б•Ө¬ҝЙДЬ ЁC? G(x)ӨПD(x)ӨО№ҙЕдЗйҲуӨтАыАы?УГӨ·ӨЖ?ЙъіЙҘвҘЗҘлӨтС§Б•ӨЗӨӯӨл ӨіӨмӨПҸҠ»ҜС§Б•ӨЛӨӘӨұӨлActor/CriticӨОйvӮSӨИН¬ҳ” l?? ?ЙъіЙҘвҘЗҘлӨПЧоіхӨЛzӨтp(z)ӨЛҸҫӨГӨЖ?ЙъіЙӨ·ЎўҙОӨЛӣQ¶ЁөДӨКйvКэӨЗxӨт?ЙъіЙӨ№Өл ЁC? ¶аӨҜӨОNNӨтК№ӨГӨҝ?ЙъіЙҘвҘЗҘлӨП№ҙЕдӨ¬ЗуӨбӨйӨмӨлӨиӨҰӨЛЎў?ЙъіЙӨОЦұЗ°ӨЗҘ¬ҘҰҘ·Ҙў ҘуӨтК№ӨҰӨ¬ЎўӨіӨмӨ¬ӨЬӨдӨұӨҝ»ӯПс?ЙъіЙӨОФӯТтӨЛӨКӨГӨЖӨӨӨҝ l?? ?ЙъіЙҘвҘЗҘлЎўЧRЧR„eҘвҘЗҘлӨЛКВЗ°ЦӘЧRЧRӨтВсӨбЮzӨбӨл ЁC? ЧRЧR„eҘвҘЗҘлӨЛCNNӨтК№ӨГӨҝҲцәПЎўТЖ„УЖХұйРФӨ¬ВсӨбЮzӨбӨйӨмӨлӨ¬Ўў ЧоҪKөДӨК?ЙъіЙҘвҘЗҘлӨЛӨЙӨОӨиӨҰӨКУ°н‘Ө¬ӨўӨлӨ«·ЦӨ«ӨйӨКӨӨ l?? GANӨПMCMCӨИЯ`ӨГӨЖ„ҝВКВКВКӨиӨҜ?ЙъіЙӨ¬ӨЗӨӯӨлӨАӨұӨЗӨКӨҜЈЁҒ»іРҘөҘуҘЧҘк ҘуҘ°Ј©ЎўЈЁ?ИЛӨ«ӨйӨЯӨЖЈ©?·ЗіЈӨЛ?ёЯЖ·Щ|ӨКҘЗ©`ҘҝӨт?ЙъіЙӨЗӨӯӨл 16
- 17. GANӨПәОӨтӨ·ӨЖӨӨӨлӨіӨИӨЛӨКӨлӨОӨ«Јҝ l?? GANӨОGӨЛӨДӨӨӨЖӨОҘӘҘкҘёҘКҘлӨОёьёьРВКҪӨПҙОӨОНЁӨкӨЗӨўӨл l?? Ө·Ө«Ө·Ўўlog(1 ?ЁC ?x)ӨПxӨ¬?РЎӨөӨӨҲцәПЎў№ҙЕдӨ¬?РЎӨөӨӨӨОӨЗҙъӨпӨкӨЛҙОӨтК№ӨҰ l?? ӨіӨО?¶юӨДӨОКҪӨтҪMӨЯәПӨпӨ»Өҝ ?ЎЎӨіӨмӨПKL[Q||P]ӨОЧо?РЎ»ҜӨтӨ·ӨЖӨӨӨлӨіӨИӨЛҢқҸкӨ№Өл ?ЎЎ?ЎЎ?ЎЎQ ?: ??ЙъіЙҘвҘЗҘлӨО·ЦІј, ?PЈәҪUтY·ЦІј 17
- 18. GANӨОҶ–о} l?? НҫЦРӨЗDӨ«GӨЙӨБӨйӨ«Ө¬ҸҠӨҜӨКӨкӨ№Ө®ӨЖС§Б•ӨЛК§”ЎӨ№Өл ЁC? ӨЙӨҰӨӨӨҰӨРӨўӨӨӨЛЎўҸҠӨҜӨКӨкӨ№Ө®ӨлӨ«ӨЛӨДӨӨӨЖӨпӨ«ӨГӨЖӨӨӨКӨӨ l?? С§Б•Ө¬ӨЙӨОіМ¶И¶ИЯMӨуӨЗӨӨӨлӨОӨ«Ө¬·ЦӨ«ӨйӨКӨӨ ЁC? …g?Т»ӨО?ДҝөДйvКэӨ¬ӨКӨҜЎў¬FЧҙЎўҪY№ыӨОҙ_ХJӨП?ДҝТ• l?? D(x)ӨПҘЗ©`Ҙҝ?Т»ӨДӨЛҢқӨ·ӨЖ·ЦоҗӨ·ӨЖӨӨӨлӨАӨұӨКӨОӨЗЎўАэАэӨЁӨРGӨ¬Н¬Өё»ӯПсӨР Ө«ӨкӨт?ЙъіЙӨ·ӨЖӨӨӨЖӨв·ЦӨ«ӨйӨКӨӨ ЁC? ұҫөұӨПGӨ¬?ЙъіЙӨ№ӨлҘЗ©`ҘҝјҜәПӨЛӨДӨӨӨЖ?ұИЭ^Ө·ӨКӨӨӨИӨӨӨұӨКӨӨ l?? ЙПӨИН¬ҳ”ӨОҶ–о}ӨЗЈ¬GӨПҘЗ©`ҘҝӨОӨӨӨҜӨДӨ«ӨОҘв©`ҘЙӨт?ЙъіЙӨ·Ө¬ӨБӨЛӨКӨкЎўІРӨк ӨОҘв©`ҘЙӨт?ЙъіЙӨ·ӨКӨҜӨКӨл ЁC? ¬FЧҙЎўіхЖЪӮҺӨ¬ЦШТӘӨЗӨўӨкЎўӨҪӨОббӨПНкИ«ӨЛgreedyӨЛЯMӨа l?? GӨИDӨОФOУӢӨЛӨДӨӨӨЖӨО»щұҫЦёбҳӨ¬ӨКӨӨ 18
- 19. Щ|Ҷ–Ө«Өй l?? ЧоЯmҪвӨ¬pdataӨИӨ·ӨҝӨйӨКӨјӨҪӨмӨтЦұҪУК№ӨпӨКӨӨӨОӨ« ЁC? GANӨЗС§Б•Ө·ӨҝӨӨӨОӨПpdataӨЗӨПӨКӨҜЎўӨҪӨмӨтӨКӨЮӨ·ӨҝОҙЦӘӨОХжӨО·ЦІјp*ЎўGANӨП ЧоЯm»ҜӨтНҫЦРӨЗ?Ц№ӨбӨлӨіӨИӨЗЈЁӨЮӨҝӨПҳO?РЎҪвӨЛөҪЯ_Ө·ӨЖЈ©Ўўp*ӨтНЖ¶ЁӨ№Өл ЁC? ӨКӨОӨЗЎўұҫөұӨПGANӨОС§Б•ҘАҘӨҘКҘЯҘҜҘ№ӨтҪвОцӨ·ӨЖЎўӨҪӨмӨ¬ӨЙӨОӨиӨҰӨКХэ„t»ҜӨт Я_іЙӨ·ӨЖӨӨӨлӨОӨ«ӨтХ{ӨЩӨҝӨӨ ЈЁEarly ?StoppingӨ¬L2Хэ„t»ҜӨЛҢқҸкӨ·ӨЖӨӨӨлӨОӨИН¬ҳ”ӨЛЈ© l?? GANӨ¬?ёЯЖ·Щ|ӨКҘЗ©`ҘҝӨт?ЙъіЙӨЗӨӯӨлӨОӨПӨКӨјӨ« ЁC? ҘОҘӨҘәӨПЧоіхӨЛӨ·Ө«?ИлӨйӨәЎўӨўӨИӨПӣQ¶ЁөДӨКйvКэӨтК№ӨГӨЖӨӨӨлӨҝӨбЎўҸҫАҙӨП№ҙЕдӨ¬ ӨвӨИӨбӨйӨмӨлӨиӨҰӨЛҘОҘӨҘәӨ¬ЧоббӨЛӨв?ИлӨГӨЖӨЬӨдӨұӨЖӨӨӨҝЎЈ 19
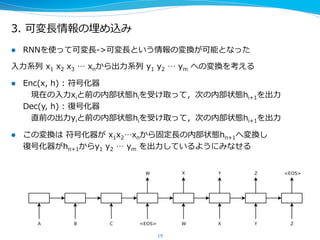
- 20. 3. ?ҝЙүд??йLЗйҲуӨОВсӨбЮzӨЯ l?? RNNӨтК№ӨГӨЖҝЙүд??йL-©\??>ҝЙүд??йLӨИӨӨӨҰЗйҲуӨОүд“QӨ¬ҝЙДЬӨИӨКӨГӨҝ ?Ил?БҰБҰПөБРБР ?x1 ?x2 ?x3 ?Ўӯ ?xnӨ«Өйіц?БҰБҰПөБРБР ?y1 ?y2 ?Ўӯ ?ym ?ӨШӨОүд“QӨтҝјӨЁӨл l?? Enc(x, ?h) ?: ?·ыәЕ»ҜЖч ?ЎЎ¬FФЪӨО?Ил?БҰБҰxiӨИЗ°ӨОДЪІҝЧҙ‘BhiӨтКЬӨұИЎӨГӨЖЈ¬ҙОӨОДЪІҝЧҙ‘Bhi+1Өтіц?БҰБҰ Dec(y, ?h) ?: ?ҸНҸНәЕ»ҜЖч ?ЎЎЦұЗ°ӨОіц?БҰБҰyiӨИЗ°ӨОДЪІҝЧҙ‘BhiӨтКЬӨұИЎӨГӨЖЈ¬ҙОӨОДЪІҝЧҙ‘Bhi+1Өтіц?БҰБҰ l?? ӨіӨОүд“QӨП ?·ыәЕ»ҜЖчӨ¬ ?x1x2ЎӯxnӨ«Өй№М¶Ё??йLӨОДЪІҝЧҙ‘Bhn+1ӨШүд“QӨ· ҸНҸНәЕ»ҜЖчӨ¬hn+1Ө«Өйy1 ?y2 ?Ўӯ ?ym ?Өтіц?БҰБҰӨ·ӨЖӨӨӨлӨиӨҰӨЛӨЯӨКӨ»Өл 20
- 21. ОҙҪвӣQҶ–о} l?? ҝЙүд??йL-©\??>№М¶Ё??йLӨОЗйҲуӨОВсӨбЮzӨЯӨПӨЙӨОӨиӨҰӨЛҢg¬FӨөӨмӨЖӨӨӨлӨОӨ«Јҝ ЁC? АэАэӨЁӨРЎў?Ил?БҰБҰ?ОДӨ«ӨйҳӢ?ОДҪвОцӨ№ӨлАэАэӨЗӨПЎўҘ№ҘҝҘГҘҜӨОҷCДЬӨПҢg¬FӨөӨмӨЖӨӨӨл ЁC? ФЩҺўӨтә¬Өа?ОДӨКӨЙӨПӨЙӨОӨиӨҰӨЛВсӨбЮzӨЮӨмӨЖӨӨӨлӨОӨ«ЈҝӨвӨ·ӨҜӨПВсӨбЮzӨЮӨмӨЖӨӨӨК ӨӨӨОӨ« l?? №М¶Ё??йL ?-©\??> ?ҝЙүд??йLӨОЗйҲуӨОХ№й_ӨПӨЙӨОӨиӨҰӨЛҢg¬FӨөӨмӨЖӨӨӨлӨОӨ«Јҝ l?? ӨіӨОҲцәПЎў¶МЖЪУӣ‘ӣӨОИЭБҝБҝӨПДЪІҝұн¬FӨОhn+1ӨЛҘРҘҰҘуҘЙӨөӨмӨЖӨӨӨл ЁC? ?Т»·NӨОAutoEncoderӨОХэ„t»ҜӨОӨиӨҰӨКТЫёоӨт№ыӨҝӨ·ӨЖӨӨӨлӨ«ӨвӨ·ӨмӨКӨӨ l?? ¶МЖЪУӣ‘ӣӨОИЭБҝБҝӨтӨўӨІӨлӨЛӨПӨЙӨҰӨ№ӨмӨРӨиӨӨӨ«Јҝ ЁC? AttentionӨтК№ӨГӨЖ?Ил?БҰБҰӨ«ӨйЦұҪУЛјӨӨіцӨ№ЈЁјИҙжСРҫҝ¶аКэЈ© l?? ЦШӨЯӨт?Т»ҙОөДӨЛүдӨЁӨлӨіӨИӨЗУӣ‘ӣӨ№ӨлӨіӨИӨвҝЙДЬ ЁC? ЯBПлУӣ‘ӣӨОҢg¬F ЁC? HintonӨ¬МбіӘӨ·ӨЖӨӨӨл[2015]Ө¬Ј¬Ңg¬FӨПӨЮӨАӨИЛјӨпӨмӨлЈЁЯ^ИҘӨЛјИӨЛӨўӨлӨ«ЈҝЈ© 21
- 22. 4. ?Ladder ?NetworkӨОҪвОц 22 ?? °лҪМҺҹӨўӨкС§Б•ӨЗLadder ?NetworkӨ¬¬FФЪЧо?ёЯҫ«¶И¶ИӨтЯ_іЙӨ·ӨЖӨӨӨл ?? ӨҪӨОббЈ¬ӨЫӨЬН¬Өёҫ«¶И¶ИӨтлAҢУөДНЖХ“Х“ҘНҘГҘИҘп©`ҘҜӨтК№ӨГӨҝҘвҘЗҘлӨвЯ_іЙ ?? Ladder ?NetworkӨПҘОҘӨҘәіэИҘҘӘ©`ҘИҘЁҘуҘі©`ҘА©`(DenoiseAEЈ©ӨИ ҪМҺҹӨўӨкС§Б•ӨтҪMӨЯӨўӨпӨ»Өл ёчҢУҡ°ӨОDenoiseAEӨЛӨи ӨлҪМҺҹӨКӨ·С§Б• ҪМҺҹӨўӨкС§Б• ёчҢУҡ°ӨЛҘОҘӨҘәӨтјУӨЁӨл әбӨОӨДӨКӨ¬ӨкӨ¬Өў ӨкЎўAEӨПФ”јҡӨтХh ГчӨ№ӨлұШТӘӨПӨКӨӨ
- 23. Ladder ?NetworkӨОЦi l?? ҸҫАҙӨОҘЛҘе©`ҘйҘлҘНҘГҘИҘп©`ҘҜӨИӨПЯ`ӨҰҘўҘӨҘЗҘЈҘўӨ¬ӨҝӨҜӨөӨуӨўӨл 1.? әбӨОӨДӨКӨ¬ӨкЈЁLateral ?ConnectionЈ©Ө¬ӨўӨлЎЈӨіӨмӨ¬ЙоӨӨҢУӨЛӨӘӨӨӨЖФ”јҡӨт ХhГчӨ№ӨлұШТӘӨ¬ӨКӨӨӨОӨЛТЫ?БўБўӨГӨЖӨӨӨл ?ЎЎDenoise ?AEӨПҙ_ВКВКВКҘвҘЗҘлӨтС§Б•Ө·ӨЖӨӨӨлӨіӨИӨ¬·ЦӨ«ӨГӨЖӨӨӨл 2.? И«ҢУӨЛҘОҘӨҘәӨтЧў?ИлӨ№Өл 3.? ёчҢУҡ°ӨЛҘОҘӨҘәіэИҘҘӘ©`ҘИҘЁҘуҘі©`ҘА©`Ө¬ӨўӨл 4.? ҪМҺҹӨКӨ·ӨОС§Б•ӨИҪМҺҹӨўӨкӨОС§Б•Ө¬Н¬•rӨЛ?РРРРӨпӨмӨл l?? әбӨОӨДӨКӨ¬ӨкӨОТвО¶ӨПәОӨ«ЈҝәбӨОӨДӨКӨ¬ӨкӨ¬ӨКӨӨҲцәПӨЛ?ұИӨЩӨЖЎўӨіӨОЗйҲуӨП ӨЙӨОӨиӨҰӨКТЫёоӨт№ыӨҝӨ·ӨЖӨӨӨлӨОӨ«Јҝ l?? И«ҢУӨЛҘОҘӨҘәӨт?ИлӨмӨЖӨӨӨлӨОӨПЎў¶аҢУӨОҙ_ВКВКВКҢУӨтә¬Өа?ЙъіЙҘвҘЗҘлӨОНЖХ“Х“ҘНҘГ ҘИҘп©`ҘҜӨО№ҙЕдНЖ¶ЁӨИ?Т»ҫwӨАӨИУиПлӨ·ӨЖӨӨӨл 23
- 25. ІОҝј?ОДПЧ l?? ҘЛҘе©`ҘйҘлҘНҘГҘИҘп©`ҘҜӨОС§Б•ӨОЦi ЁC? Ў°The ?loss ?surfaces ?of ?multilayer ?networksЎұ, ?A. ?Choromanska, ?et. ?al. ? AISTATS2015 ЁC? Ў°Open ?Problem: ?The ?landscape ?of ?the ?loss ?surfaces ?of ?multilayer ?networksЎұ, ?A. ? Choromanska, ?et. ?al. ?2015 ?COLT l?? ”іҢқөД?ЙъіЙҘвҘЗҘл ЁC? Generative ?Adversarial ?Networks, ?I. ?J. ?Goodfellow, ?et. ?al. ?2014 ЁC? Unsupervised ?Representation ?Learning ?with ?Deep ?Convolutional ?Generative ? Adversarial ?Networks, ?A. ?Radford, ?ICLR ?2016 l?? ПөБРБРӨ«ӨйПөБРБРӨШӨОүд“Q ЁC? Ў°Sequence ?to ?sequence ?learning ?with ?neural ?networksЎұ, ?I. ?Sutskever, ?2014 ЁC? Ў°Aetherial ?SymbolsЎұ, ?G. ?Hinton ?2015 25
- 26. l?? Ladder ?Networks ЁC? Ў°Semi-©\??supervised ?Learning ?with ?Ladder ?NetworksЎұ, ?A. ?Rasmus, ?et. ?al. ?2015 ЁC? Ў°Deconstructing ?the ?Ladder ?Network ?ArchtectureЎұ, ?M. ?Pezeshki, ?2015 26