Documents, services, and data on the web
ŌĆó
1 likeŌĆó656 views

The document discusses the Research and Education Space (RES) project, which aims to create a web-based platform called Acropolis that aggregates and interconnects cultural heritage resources from various institutions like the British Library, British Museum, BBC archive, and others. It describes Acropolis' technical approach of using crawlers, indexes, and APIs to make these resources searchable. It also outlines challenges around standardizing heterogeneous metadata, reliably linking entities, and usability issues regarding tools, licensing, and stakeholder engagement. The author is looking to provide guidance on publishing cultural data as linked open data to help address these challenges.











Documents, services, and data on the web
- 1. The Research and Education Space a pathway to bring our cultural heritage (including the BBC archive) to life Dr Chiara Del Vescovo Data Architect at BBC
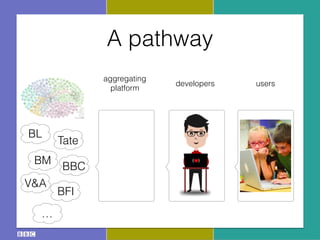
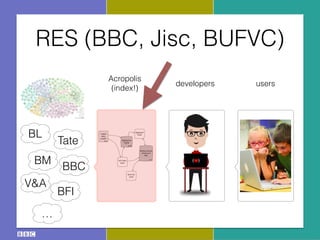
- 11. RES (BBC, Jisc, BUFVC) Core Platform: ŌĆ£AcropolisŌĆØ Project RES: Technical Approach 1 The crawler fetches data via HTTP from published sources. Once retrieved, it is indexed by the full-text store and passed to the aggregation engine for evaluation. 2 The results of the aggregation engine's evaluation process are stored in the aggregate store, which contains minimal browse information and information about the similarity of entities. 3 The public face of the core platform is an extremely basic browsing interface (which presents the data in tabular form to aid application developers), and read-write RESTful APIs. 4 Applications may use the APIs to locate information about aggregated entities, and also to store annotations and activity data. 5 Each component employs standard protocols and formats. For example, we can make use of any capable quad-store as our aggregate store. Linked data crawler Anansi Aggregation engine Spindle Full-text store Aggregate store Minimal browse interface & APIs Quilt Activity store usersdevelopers Acropolis (index!) BL BM BFI Tate V&A ŌĆ” BBC
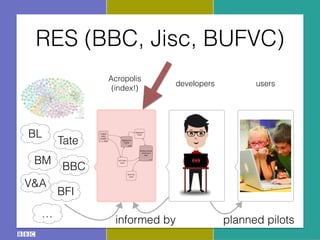
- 12. RES (BBC, Jisc, BUFVC) Core Platform: ŌĆ£AcropolisŌĆØ Project RES: Technical Approach 1 The crawler fetches data via HTTP from published sources. Once retrieved, it is indexed by the full-text store and passed to the aggregation engine for evaluation. 2 The results of the aggregation engine's evaluation process are stored in the aggregate store, which contains minimal browse information and information about the similarity of entities. 3 The public face of the core platform is an extremely basic browsing interface (which presents the data in tabular form to aid application developers), and read-write RESTful APIs. 4 Applications may use the APIs to locate information about aggregated entities, and also to store annotations and activity data. 5 Each component employs standard protocols and formats. For example, we can make use of any capable quad-store as our aggregate store. Linked data crawler Anansi Aggregation engine Spindle Full-text store Aggregate store Minimal browse interface & APIs Quilt Activity store informed by usersdevelopers Acropolis (index!) planned pilots BL BM BFI Tate V&A ŌĆ” BBC
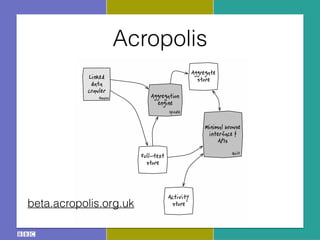
- 13. AcropolisCore Platform: ŌĆ£AcropolisŌĆØ 1 The crawler fetches data sources. Once retrieved store and passed to the 2 The results of the aggre are stored in the aggreg browse information and entities. 3 The public face of the c browsing interface (whi to aid application develo 4 Applications may use th aggregated entities, and data. 5 Each component emplo For example, we can ma as our aggregate store. Linked data crawler Anansi Aggregation engine Spindle Full-text store Aggregate store Minimal browse interface & APIs Quilt Activity storebeta.acropolis.org.uk
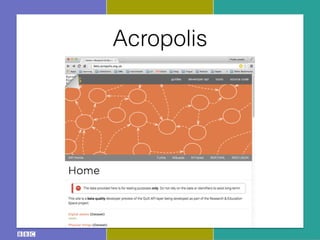
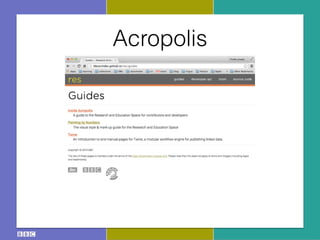
- 14. Acropolis
- 15. Acropolis
- 16. Acropolis
- 17. Acropolis
- 18. Core Platform: ŌĆ£AcropolisŌĆØ Project RES: Technical Approach 1 The crawler fetches data via HTTP from published sources. Once retrieved, it is indexed by the full-text store and passed to the aggregation engine for evaluation. 2 The results of the aggregation engine's evaluation process are stored in the aggregate store, which contains minimal browse information and information about the similarity of entities. 3 The public face of the core platform is an extremely basic browsing interface (which presents the data in tabular form to aid application developers), and read-write RESTful APIs. 4 Applications may use the APIs to locate information about aggregated entities, and also to store annotations and activity data. 5 Each component employs standard protocols and formats. For example, we can make use of any capable quad-store as our aggregate store. Linked data crawler Anansi Aggregation engine Spindle Full-text store Aggregate store Minimal browse interface & APIs Quilt Activity store informed by usersdevelopersAcropolis What I do (with my colleague Alex) planned pilots BL BM BFI Tate V&A ŌĆ” BBC
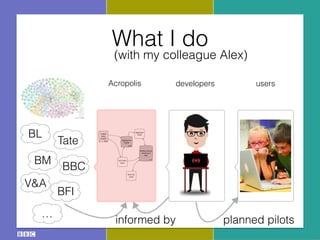
- 19. What I do (with my colleague Alex) BL BM BFI Tate V&A ŌĆ” BBC
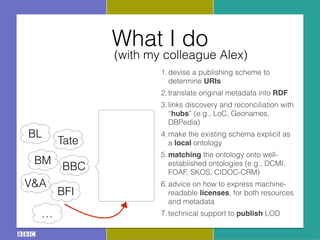
- 20. What I do (with my colleague Alex) 1.devise a publishing scheme to determine URIs 2.translate original metadata into RDF 3.links discovery and reconciliation with ŌĆ£hubsŌĆØ (e.g., LoC, Geonames, DBPedia) 4.make the existing schema explicit as a local ontology 5.matching the ontology onto well- established ontologies (e.g., DCMI, FOAF, SKOS, CIDOC-CRM) 6.advice on how to express machine- readable licenses, for both resources and metadata 7.technical support to publish LOD BL BM BFI Tate V&A ŌĆ” BBC
- 21. DBPedialite
- 22. DBPedialite
- 23. DBPedialite
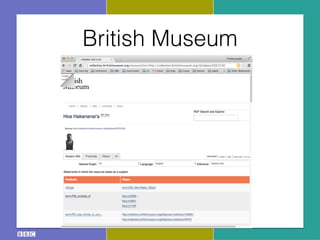
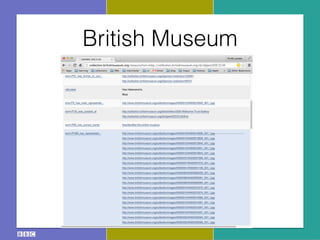
- 24. British Museum
- 25. British Museum
- 26. British Museum
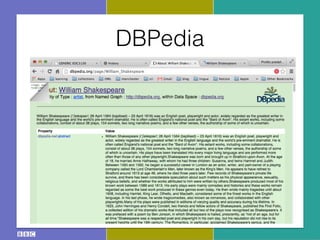
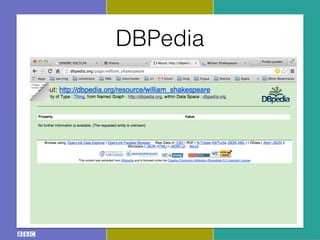
- 27. DBPedia
- 28. DBPedia
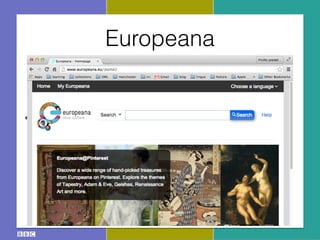
- 29. ŌĆó Europeana ŌĆó ŌĆ£generalŌĆØ Data Model (EDM) ŌĆó collection holders responsible to ’¼üt their resources and metadata in EDM Europeana
- 30. ŌĆó Europeana ŌĆó ŌĆ£generalŌĆØ Data Model (EDM) ŌĆó collection holders responsible to ’¼üt their resources and metadata in EDM Europeana
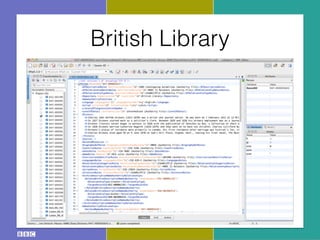
- 31. British Library
- 32. Extreme cases
- 34. 1. Which metadata? ŌĆó Currently, resources metadata mostly oriented towards ŌĆ£physical proximityŌĆØŌĆ© i.e., indexes re’¼éect similarity of authorŌĆÖs surname, broad subject, format, media, etc. ŌĆó Heterogeneous platforms and data modelsŌĆ© incompatibility, transformations needed ŌĆó Even when RDF is used, thereŌĆÖs a proliferation of terms, vocabularies, formats adoptedŌĆ© little (if any) validation
- 35. 2. Linking ŌĆó Systems that do not use RDF do not allow collection holders to express their knowledge as they wishŌĆ© underspeci’¼üed knowledge ŌĆó Even when RDF is used, information often provided as literals rather than links to URIsŌĆ© ad hoc solutions unavailable in a machine-readable format
- 36. 3. Usability ŌĆó Reliability ŌĆó Lack of toolsŌĆ© developers have little contact with collection holders ŌĆó Licensing issuesŌĆ© resources licensing (not always explicit)ŌĆ© metadata licensingŌĆ© users need to be aware of what that meanŌĆ© (note that in educations things are slightly easier - blanket licensing etc.)
- 37. Interested? ŌĆó get in touch! ŌĆó chiara.delvescovo@bbc.co.uk ŌĆó alex.tucker@bbc.co.uk ŌĆó new advertised position asŌĆ© Junior Data ArchitectŌĆ© careershub.bbc.co.uk