More Related Content What's hot (20) PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ« Xml б„Ӣб…өб„’б…ўб„’б…Ўб„Җб…ө
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ« class л°Ҹ function namespace мқҙн•ҙн•ҳкё°
Yong Joon Moon Мэ
PDF
[WELC] 22. I Need to Change a Monster Method and I CanвҖҷt Write Tests for It
мў…л№Ҳ мҳӨ Мэ
PPTX
б„Ӣб…ҰбҶҜб„…б…Ўб„үб…іб„җб…өбҶЁб„үб…Ҙб„Һб…ө б„Ӣб…өб„’б…ўб„’б…Ўб„Җб…ө 20160613
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ«+Json+б„Ӣб…өб„’б…ўб„’б…Ўб„Җб…ө 20160301
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ« Descriptorб„Ӣб…өб„’б…ўб„’б…Ўб„Җб…ө 20160403
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ«+б„Ҹб…ібҶҜб„…б…ўб„үб…і+б„Җб…®б„Ңб…©+б„Ӣб…өб„’б…ўб„’б…Ўб„Җб…ө 20160310
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ«+б„Ңб…®б„Ӣб…ӯ+б„Ӣб…ӯбҶјб„Ӣб…Ҙ+б„Ңб…ҘбҶјб„…б…ө 20160304
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ« б„‘б…іб„…б…©б„‘б…Ҙб„җб…ө б„ғб…өб„үб…іб„Ҹб…іб„…б…өбҶёб„җб…Ҙ б„Ӣб…өб„’б…ўб„’б…Ўб„Җб…ө
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ« к°қмІҙ нҒҙлһҳмҠӨ б„Ӣб…өб„’б…ўб„’б…Ўб„Җб…ө
Yong Joon Moon Мэ
PPTX
б„‘б…Ўб„Ӣб…өб„Ҡб…ҘбҶ« class л°Ҹ мқёмҠӨн„ҙмҠӨ мғқм„ұ мқҙн•ҙн•ҳкё°
Yong Joon Moon Мэ
Viewers also liked (20) PDF
б„Үб…өб„Җб…ўб„Үб…ЎбҶҜб„Ңб…Ўб„…б…ібҶҜ б„Ӣб…ұб„’б…ЎбҶ« Javascript б„Ӣб…ЎбҶҜб„Ӣб…Ўб„Җб…Ўб„Җб…ө #4.1
лҜјнғң к№Җ Мэ
PDF
[NDC14] нҢҢмӣҢнҸ¬мқёнҠёлЎң к·ёлһҳн”Ҫ лҰ¬мҶҢмҠӨ л§Ңл“Өкё°
Sun Park Мэ
PDF
[KGC2014] мҡён”„лӮҳмқҙмё м—”м§„ н”„лЎңк·ёлһҳл°Қ кё°лЎқ
JiUng Choi Мэ
PPTX
мқҙк¶Ңмқј Sse лҘј мқҙмҡ©н•ң мөңм Ғнҷ”мҷҖ мӢӨм ң мӮ¬мҡ© мҳҲ
zupet Мэ
Similar to Dom мғқм„ұкіјм • (20)
PPT
Daejeon IT Developer Conference Hibernate3
plusperson Мэ
PDF
Secrets of the JavaScript Ninja - Chapter 12. DOM modification
Hyuncheol Jeon Мэ
PDF
5б„Ңб…ЎбҶј б„Җб…ўбҶЁб„Һб…Ұб„Ӣб…Әб„Ҹб…ібҶҜб„…б…ўб„үб…і
SeoYeong Мэ
PDF
б„үб…Ұб„үб…§бҶ«1. block chain as a platform
Jay JH Park Мэ
PPT
Daejeon IT Developer Conference iBATIS2
plusperson Мэ
PPT
Daejeon IT Developer Conference Hibernate3
plusperson Мэ
PDF
HTTP мҷ„лІҪк°Җмқҙл“ң- 19мһҘ л°°нҸ¬мӢңмҠӨн…ң
л°• лҜјк·ң Мэ
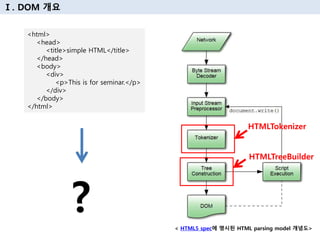
3. в… . DOMмқҙлһҖ
в–Ј DOM(Document Object Model) мқҙлһҖ?
1. л¬ём„ңлҘј к°қмІҙлЎң н‘ңнҳ„н•ҳкё° мң„н•ң н‘ңмӨҖмңјлЎңм„ң HTMLмқҙлӮҳ XMLл“ұмқҳ л¬ём„ңлҘј к°қмІҙлЎң
н‘ңнҳ„н• л•Ң мӮ¬мҡ© н•ҳлҠ” API мқҙлӢӨ.
2. л¬ём„ңмқҳ к°қмІҙ лӘЁлҚё(Document Object Model)мқҖ HTMLлӮҙм—җ л“Өм–ҙ мһҲлҠ” мҡ”мҶҢлҘј
кө¬мЎ°нҷ” к°қмІҙ лӘЁлҚёлЎң н‘ңнҳ„ н•ҳлҠ” м–‘мӢқмқҙлӢӨ.
3. DOMмқҖ HTMLкіј XMLл¬ём„ңм—җ лҢҖн•ҳм—¬, мқҙл“Ө л¬ём„ңмқҳ кө¬мЎ°м Ғмқё н‘ңнҳ„л°©лІ•мқ„ м ңкіөн•ҳл©°
м–ҙл–»кІҢ н•ҳл©ҙ мҠӨнҒ¬лҰҪнҠёлҘј мқҙмҡ©н•ҳм—¬ мқҙлҹ¬н•ң кө¬мЎ°м—җ м ‘к·јн• мҲҳ мһҲлҠ”м§ҖлҘј м •мқҳн•ҳлҠ”
API мқҙлӢӨ.
в–Ј л¬ём„ңлҘј нҠёлҰ¬лЎң н‘ңнҳ„н•ҳкё°
- HTML л¬ём„ңлҠ” мӨ‘мІ©лҗң нғңк·ёлЎң кө¬м„ұлҗң кі„мёөм Ғмқё кө¬мЎ°лҘј мқҙл©°, мқҙлҠ” DOMм—җм„ң
к°қмІҙ нҠёлҰ¬лЎң н‘ңнҳ„лҗңлӢӨ.
- DOM нҠёлҰ¬м—җлҠ” HTML нғңк·ёлӮҳ м—ҳлҰ¬лЁјнҠёлҘј лӮҳнғҖлӮҙлҠ” л…ёл“ңк°Җ лӢҙкёҙлӢӨ.
в–Ј нҶ нҒ°нҷ”
- м „лӢ¬ л°ӣмқҖ HTML л¬ём„ң(Source)м—җ лҢҖн•ҳм—¬ Char лӢЁмң„лЎң н•ҙм„қ нҶ нҒ°нҷ” мІҳлҰ¬лҘј 진н–үн•ңлӢӨ.
4. в… . DOM к°ңмҡ”
< HTML5 specм—җ лӘ…мӢңлҗң HTML parsing model к°ңл…җлҸ„>
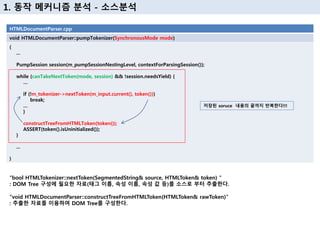
HTMLTokenizer
<html>
<head>
<title>simple HTML</title>
</head>
<body>
<div>
<p>This is for seminar.</p>
</div>
</body>
</html>
?
HTMLTreeBuilder
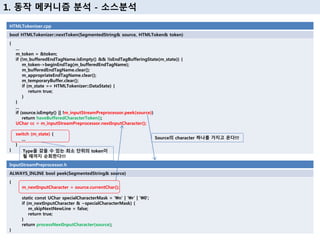
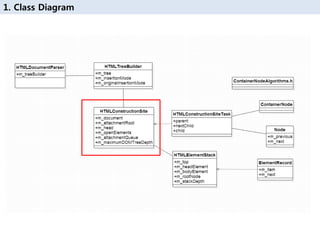
6. 1. лҸҷмһ‘ л©”м»ӨлӢҲмҰҳ 분м„қ - мҶҢмҠӨ분м„қ
HTMLDocumentParser.cpp
void
HTMLDocumentParser::append(PassRefPtr<StringImpl>
inputSource)
void HTMLDocumentParser::insert(const SegmentedString&
source)
{
if (isStopped())
return;
...
RefPtr<HTMLDocumentParser> protect(this);
String source(inputSource);
вҖҰ
m_input.appendToEnd(source);
вҖҰ
pumpTokenizerIfPossible(AllowYield);
endIfDelayed();
}
{
if (isStopped())
return;
...
RefPtr<HTMLDocumentParser> protect(this);
вҖҰ
SegmentedString excludedLineNumberSource(source);
excludedLineNumberSource.setExcludeLineNumbers();
m_input.insertAtCurrentInsertionPoint(excludedLineNumberSource
);
pumpTokenizerIfPossible(ForceSynchronous);
endIfDelayed();
}
HTMLDocumentParser.cpp
void HTMLDocumentParser::pumpTokenizerIfPossible(SynchronousMode
mode)
{
вҖҰ
pumpTokenizer(mode);
}
в–· Synchronous Mode
- AllowYield
- ForceSynchronous
7. 1. лҸҷмһ‘ л©”м»ӨлӢҲмҰҳ 분м„қ - мҶҢмҠӨ분м„қ
HTMLDocumentParser.cpp
void HTMLDocumentParser::pumpTokenizer(SynchronousMode mode)
{
...
PumpSession session(m_pumpSessionNestingLevel, contextForParsingSession());
while (canTakeNextToken(mode, session) && !session.needsYield) {
вҖҰ
if (!m_tokenizer->nextToken(m_input.current(), token()))
break;
вҖҰ
}
constructTreeFromHTMLToken(token());
ASSERT(token().isUninitialized());
}
...
}
м ҖмһҘлҗң soruce лӮҙмҡ©мқҳ лҒқк№Ңм§Җ л°ҳліөн•ңлӢӨ!!!
вҖңbool HTMLTokenizer::nextToken(SegmentedString& source, HTMLToken& token) вҖң
: DOM Tree кө¬м„ұм—җ н•„мҡ”н•ң мһҗлЈҢ(нғңк·ё мқҙлҰ„, мҶҚм„ұ мқҙлҰ„, мҶҚм„ұ к°’ л“ұ)лҘј мҶҢмҠӨлЎң л¶Җн„° 추м¶ңн•ңлӢӨ.
вҖңvoid HTMLDocumentParser::constructTreeFromHTMLToken(HTMLToken& rawToken)вҖқ
: 추м¶ңн•ң мһҗлЈҢлҘј мқҙмҡ©н•ҳм—¬ DOM TreeлҘј кө¬м„ұн•ңлӢӨ.
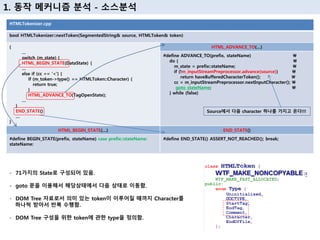
8. 1. лҸҷмһ‘ л©”м»ӨлӢҲмҰҳ 분м„қ - мҶҢмҠӨ분м„қ
HTMLTokenizer.cpp
bool HTMLTokenizer::nextToken(SegmentedString& source, HTMLToken& token)
{
...
m_token = &token;
if (!m_bufferedEndTagName.isEmpty() && !isEndTagBufferingState(m_state)) {
m_token->beginEndTag(m_bufferedEndTagName);
m_bufferedEndTagName.clear();
m_appropriateEndTagName.clear();
m_temporaryBuffer.clear();
if (m_state == HTMLTokenizer::DataState) {
return true;
}
}
...
if (source.isEmpty() || !m_inputStreamPreprocessor.peek(source))
return haveBufferedCharacterToken();
UChar cc = m_inputStreamPreprocessor.nextInputCharacter();
switch (m_state) {
...
}
}
InputStreamPreprocessor.h
ALWAYS_INLINE bool peek(SegmentedString& source)
{
m_nextInputCharacter = source.currentChar();
static const UChar specialCharacterMask = 'n' | 'r' | '0';
if (m_nextInputCharacter & ~specialCharacterMask) {
m_skipNextNewLine = false;
return true;
}
return processNextInputCharacter(source);
}
Sourceмқҳ character н•ҳлӮҳлҘј к°Җм§Җкі мҳЁлӢӨ!!!
Typeмқ„ к°–мқ„ мҲҳ мһҲлҠ” мөңмҶҢ лӢЁмң„мқҳ tokenмқҙ
лҗ л•Ңк№Ңм§Җ мҲңнҡҢн•ңлӢӨ!!!
9. 1. лҸҷмһ‘ л©”м»ӨлӢҲмҰҳ 분м„қ - мҶҢмҠӨ분м„қ
HTMLTokenizer.cpp
bool HTMLTokenizer::nextToken(SegmentedString& source, HTMLToken& token)
{
вҖҰ
switch (m_state) {
HTML_BEGIN_STATE(DataState) {
вҖҰ
else if (cc == '<') {
if (m_token->type() == HTMLToken::Character) {
return true;
}
HTML_ADVANCE_TO(TagOpenState);
вҖҰ
}
END_STATE()
вҖҰ
}
HTML_ADVANCE_TO(вҖҰ)
#define ADVANCE_TO(prefix, stateName)
do {
m_state = prefix::stateName;
if (!m_inputStreamPreprocessor.advance(source))
return haveBufferedCharacterToken();
cc = m_inputStreamPreprocessor.nextInputCharacter();
goto stateName;
} while (false)
HTML_BEGIN_STATE(вҖҰ) END_STATE()
#define BEGIN_STATE(prefix, stateName) case prefix::stateName:
stateName:
#define END_STATE() ASSERT_NOT_REACHED(); break;
- 71к°Җм§Җмқҳ StateлЎң кө¬м„ұлҗҳм–ҙ мһҲмқҢ.
- goto л¬ёмқ„ мқҙмҡ©н•ҙм„ң н•ҙлӢ№мғҒнғңм—җм„ң лӢӨмқҢ мғҒнғңлЎң мқҙлҸҷн•Ё.
- DOM Tree мһҗлЈҢлЎңм„ң мқҳлҜё мһҲлҠ” tokenмқҙ мқҙлЈЁм–ҙм§Ҳ л•Ңк№Ңм§Җ CharacterлҘј
н•ҳлӮҳм”© л°ӣм•„м„ң л°ҳліө мҲҳн–үн•Ё.
- DOM Tree кө¬м„ұмқ„ мң„н•ң tokenм—җ кҙҖн•ң typeмқ„ м •мқҳн•Ё.
Sourceм—җм„ң лӢӨмқҢ character н•ҳлӮҳлҘј к°Җм§Җкі мҳЁлӢӨ!!!
10. 1. лҸҷмһ‘ л©”м»ӨлӢҲмҰҳ 분м„қ вҖ“ nextToken мҲңнҡҢ м•Ңкі лҰ¬мҰҳ
DataState
TagOpenState
TagNameState
BeforeAttributeName
State
AttributeName
State
AfterAttributeName
State
BeforAttributeValue
State
AttributeValue
SingleQuote
State
AttributeValue
DoubleQuote
State
AfterAttributeValue
QuoteState
(1) DataState - вҖң < вҖң л¬ёмһҗлҘј нҷ•мқё.
(2) TagOpenState вҖ“ m_typeмқ„ StartTagлЎң ліҖкІҪ.
(3) TagNameState вҖ“ TagnNameмқ„ m_dataм—җ м ҖмһҘн•ҳкі , кіөл°ұмқём§Җ нҷ•мқё.
(4) BeforeAttributeNameState вҖ“ m_currentAttribute.м—җ мһ…л Ҙ мӨҖ비함.
(5) AttributeNameState вҖ“ m_currentAttribute.nameм—җ AttributeNameмқ„ мһ…
л Ҙн•Ё. кіөл°ұмқём§Җ нҷ•мқё.
(6) AfterAttributeNameState - вҖң = вҖң л¬ёмһҗнҷ•мқё.
(7) BeforAttributeValueState - нҒ°л”°мҳҙн‘ң лҳҗлҠ” мһ‘мқҖл”°мҳҙн‘ң л¬ёмһҗмқём§Җ нҷ•мқё.
(8-1) AttributeValueDoubleQuoteState - нҒ°л”°мҳҙн‘ңмқҙл©ҙ
m_currentAttribute .valueм—җ AttributeValueмқ„ м ҖмһҘн•ҳкі , нҒ°л”°мҳҙн‘ң л¬ёмһҗнҷ•мқё.
(8-2) AttributeValueSingleQuoteState - мһ‘мқҖл”°мҳҙн‘ң мқҙл©ҙ
m_currentAttribute .valueм—җ AttributeValueмқ„ м ҖмһҘн•ҳкі , мһ‘мқҖл”°мҳҙн‘ң л¬ёмһҗнҷ•мқё.
(9) AfterAttributeValueQuoteState вҖ“ вҖң > вҖң л¬ёмһҗлҘј нҷ•мқён•ҳкі gotoл¬ё мҲңнҡҢлҘј
л§Ҳм№Ё.
DataStateлҘј м ңмҷён•ң мң„мқҳ лӘЁл“ кІҪмҡ° вҖң>вҖқл¬ёмһҗлҘј нҷ•мқён•ҳл©ҙ gotoл¬ё мҲңнҡҢлҘј л§Ҳм№Ё.
< StartTag >
11. 1. лҸҷмһ‘ л©”м»ӨлӢҲмҰҳ 분м„қ вҖ“ nextToken мҲңнҡҢ м•Ңкі лҰ¬мҰҳ
DataState
TagOpenState
EndTagOpenState
TagNameState
(1) DataState - вҖң < вҖң л¬ёмһҗлҘј нҷ•мқё.
(2) TagOpenState вҖ“ вҖң / вҖң л¬ёмһҗлҘј нҷ•мқё.
(3) EndTagOpenState вҖ“ m_typeмқ„ EndTagлЎң ліҖкІҪ
(4) TagNameState вҖ“ TagnNameмқ„ m_dataм—җ м ҖмһҘн•ҳкі , вҖң > вҖң л¬ёмһҗлҘј нҷ•мқён•ҳкі
gotoл¬ё мҲңнҡҢлҘј л§Ҳм№Ё.
DataStateлҘј м ңмҷён•ң мң„мқҳ лӘЁл“ кІҪмҡ° вҖң>вҖқл¬ёмһҗлҘј нҷ•мқён•ҳл©ҙ gotoл¬ё мҲңнҡҢлҘј л§Ҳм№Ё.
< EndTag >
< Comment >
DataState
TagOpenState
MarkupDeclaration
OpenState
CommentStartState
CommentEndDashState
CommentEndState
(1) DataState - вҖң < вҖң л¬ёмһҗлҘј нҷ•мқё.
(2) TagOpenState вҖ“ вҖң ! вҖң л¬ёмһҗлҘј нҷ•мқё.
(3) MarkupDeclarationOpenState вҖ“ вҖң--вҖң л¬ёмһҗлҘј нҷ•мқён•ҳкі m_typeмқ„
CommentлЎң ліҖкІҪ.
(4) CommentStartState вҖ“ CommentлҘј m_dataм—җ м ҖмһҘ.
(5) CommentEndDashState вҖ“ вҖң-вҖқлҘј нҷ•мқё.
(6) CommentEndState - вҖң > вҖң л¬ёмһҗлҘј нҷ•мқён•ҳкі gotoл¬ё мҲңнҡҢлҘј л§Ҳм№Ё.
DataStatedмҷҖ CommentEndDashStateлҘј м ңмҷён•ң мң„мқҳ лӘЁл“ кІҪмҡ° вҖң>вҖқл¬ёмһҗлҘј нҷ•
мқён•ҳл©ҙ gotoл¬ё мҲңнҡҢлҘј л§Ҳм№Ё.
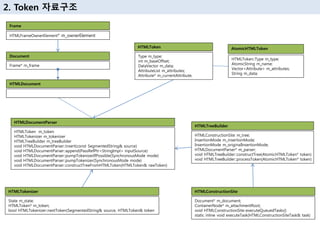
12. 2. Token мһҗлЈҢкө¬мЎ°
Frame
HTMLFrameOwnerElement* m_ownerElement
Document
Frame* m_frame
HTMLDocument
HTMLDocumentParser
HTMLToken m_token
HTMLTokenizer m_tokenizer
HTMLTreeBuilder m_treeBuilder
void HTMLDocumentParser::insert(const SegmentedString& source)
void HTMLDocumentParser::append(PassRefPtr<StringImpl> inputSource)
void HTMLDocumentParser::pumpTokenizerIfPossible(SynchronousMode mode)
void HTMLDocumentParser::pumpTokenizer(SynchronousMode mode)
void HTMLDocumentParser::constructTreeFromHTMLToken(HTMLToken& rawToken)
HTMLTokenizer
State m_state;
HTMLToken* m_token;
bool HTMLTokenizer::nextToken(SegmentedString& source, HTMLToken& token
HTMLConstructionSite
Document* m_document;
ContainerNode* m_attachmentRoot;
void HTMLConstructionSite::executeQueuedTasks()
static inline void executeTask(HTMLConstructionSiteTask& task)
HTMLTreeBuilder
HTMLConstructionSite m_tree;
InsertionMode m_insertionMode;
InsertionMode m_originalInsertionMode;
HTMLDocumentParser* m_parser;
void HTMLTreeBuilder::constructTree(AtomicHTMLToken* token)
void HTMLTreeBuilder::processToken(AtomicHTMLToken* token)
HTMLToken
Type m_type;
int m_baseOffset;
DataVector m_data;
AttributeList m_attributes;
Attribute* m_currentAttribute;
AtomicHTMLToken
HTMLToken::Type m_type;
AtomicString m_name;
Vector<Attribute> m_attributes;
String m_data;
15. while ( вҖҰ ) {
пёҷ
if (!m_tokenizer->nextToken(m_input.current(), token()))
break;
пёҷ
constructTreeFromHTMLToken (token());
}
HTMLDocumentParser::pumpTokenizer (вҖҰ)
н•ҳлӮҳмқҳ token мҷ„м„ұлҗЁ.
н•ҳлӮҳмқҳ tokenмқҙ мғқм„ұлҗҳл©ҙ мқҙлҘј Tree кө¬мЎ°м—җ нҸ¬н•Ён•ңлӢӨ.
HTMLTreeBuilder::constructTree (token)
switch (token->type()) {
пёҷ
case HTMLToken::DOCTYPE:
processDoctypeToken(token);
case HTMLToken::StartTag:
processStartTag(token);
case HTMLToken::EndTag:
processEndTag(token);
case HTMLToken::Comment:
processComment(token);
case HTMLToken::Character:
processCharacter(token);
case HTMLToken::EndOfFile:
processEndOfFile(token);
}
HTMLTreeBuilder::processToken(AtomicHTMLToken* token)
tokenмқҳ typeм—җ л”°лқј к°Ғк°Ғмқҳ process н•ЁмҲҳлҘј нҳём¶ң.
2. Dom Tree кө¬м¶•
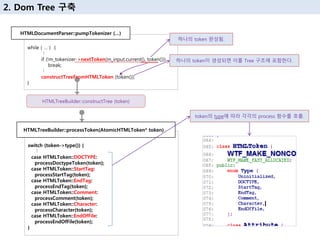
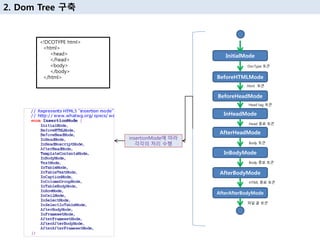
17. 2. Dom Tree кө¬м¶•
InitialMode
AfterAfterBodyMode
BeforeHTMLMode
AfterBodyMode
BeforeHeadMode
InBodyMode
AfterHeadMode
InHeadMode
Html нҶ нҒ°
нҢҢмқј лҒқ нҶ нҒ°
DocType нҶ нҒ°
Head tag нҶ нҒ°
Head мў…лЈҢ нҶ нҒ°
Body нҶ нҒ°
Body мў…лЈҢ нҶ нҒ°
insertionModeм—җ л”°лқј
к°Ғк°Ғмқҳ мІҳлҰ¬ мҲҳн–ү
HTML мў…лЈҢ нҶ нҒ°
<!DCOTYPE html>
<html>
<head>
</head>
<body>
</body>
</html>
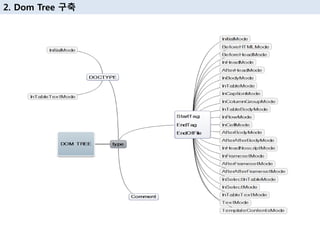
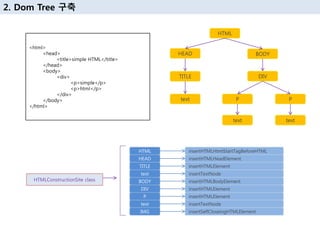
18. 2. Dom Tree кө¬м¶•
HTML
HEAD
TITLE
text
BODY
DIV
P
text
IMG
insertHTMLHtmlStartTagBeforeHTML
insertHTMLHeadElement
insertHTMLElement
insertTextNode
insertHTMLBodyElement
insertHTMLElement
insertHTMLElement
insertTextNode
insertSelfCloseingHTMLElement
HTMLConstructionSite class
HTML
HEAD
TITLE
text
BODY
DIV
P
text
P
text
<html>
<head>
<title>simple HTML</title>
</head>
<body>
<div>
<p>simple</p>
<p>html</p>
</div>
</body>
</html>
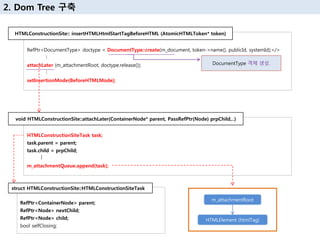
19. RefPtr<DocumentType> doctype = DocumentType::create(m_document, token->name(), publicId, systemId);</>
пёҷ
attachLater (m_attachmentRoot, doctype.release());
пёҷ
setInsertionMode(BeforeHTMLMode);
HTMLConstructionSite:: insertHTMLHtmlStartTagBeforeHTML (AtomicHTMLToken* token)
2. Dom Tree кө¬м¶•
DocumentType к°қмІҙ мғқм„ұ.
HTMLConstructionSiteTask task;
task.parent = parent;
task.child = prpChild;
пёҷ
m_attachmentQueue.append(task);
void HTMLConstructionSite::attachLater(ContainerNode* parent, PassRefPtr(Node) prpChild,..)
RefPtr<ContainerNode> parent;
RefPtr<Node> nextChild;
RefPtr<Node> child;
bool selfClosing;
struct HTMLConstructionSite::HTMLConstructionSiteTask
m_attachmentRoot
HTMLElement (htmlTag)
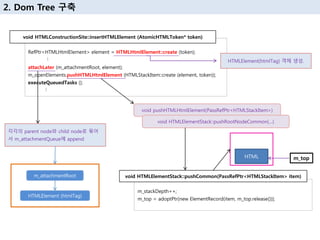
20. RefPtr<HTMLHtmlElement> element = HTMLHtmlElement::create (token);
пёҷ
attachLater (m_attachmentRoot, element);
m_openElements.pushHTMLHtmlElement (HTMLStackItem::create (element, token));
executeQueuedTasks ();
пёҷ
void HTMLConstructionSite::insertHTMLElement (AtomicHTMLToken* token)
к°Ғк°Ғмқҳ parent nodeмҷҖ child nodeлЎң 묶м–ҙ
м„ң m_attachmentQueueм—җ append
m_attachmentRoot
HTMLElement (htmlTag)
2. Dom Tree кө¬м¶•
HTMLElement(htmlTag) к°қмІҙ мғқм„ұ.
m_stackDepth++;
m_top = adoptPtr(new ElementRecord(item, m_top.release()));
void HTMLElementStack::pushCommon(PassRefPtr<HTMLStackItem> item)
void pushHTMLHtmlElement(PassRefPtr<HTMLStackItem>)
HTML
void HTMLElementStack::pushRootNodeCommon(вҖҰ)
m_top
21. в‘Ў Html
m_document : в‘
m_firstChild : в‘ў
m_lastChild : в‘Ј
в‘ў Head
parent : в‘Ў
m_next : в‘Ј
m_firstChild : в‘Ө
в‘Ј Body
parent : в‘Ў
m_previous : в‘ў
m_firstChild : в‘Ұ
в‘Ҙ Text
data : Simple
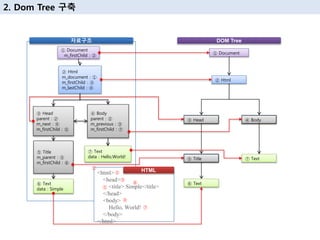
в‘ Document
m_firstChild : в‘Ў
в‘ Document
в‘Ў Html
<html>
<head>
<title> Simple</title>
</head>
<body>
Hello, World!
</body>
</html>
в‘Ө Title
m_parent : в‘ў
m_firstChild : в‘Ҙ
в‘Ұ Text
data : Hello,World!
Head Body
Title в‘Ұ Text
в‘Ҙ Text
в‘ў Head в‘Ј Body
в‘Ө Title
в‘
в‘Ў
в‘Ө
в‘Ҙ
в‘Ј
в‘Ұ
в‘ў
мһҗлЈҢкө¬мЎ° DOM Tree
HTML
2. Dom Tree кө¬м¶•
22. HTMLTreeBuilder.cpp
void HTMLTreeBuilder::processToken(AtomicHTMLToken* token)
switch (token->type()) {
case HTMLToken::Uninitialized:
вҖҰ.
case HTMLToken::StartTag:
processStartTag(token);
вҖҰ.
}
HTMLTreeBuilder.cpp
void HTMLTreeBuilder::processStartTag(AtomicHTMLToken* token)
{
switch (insertionMode()) {
вҖҰ.
case BeforeHTMLMode:
if (token->name() == htmlTag) {
m_tree.insertHTMLHtmlStartTagBeforeHTML(token);
setInsertionMode(BeforeHeadMode);
return;
}
}
HTMLConstructionSite.cpp
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomicHTMLToken* token)
{
RefPtr<HTMLHtmlElement> element = HTMLHtmlElement::create(m_document);
setAttributes(element.get(), token, m_parserContentPolicy);
attachLater(m_attachmentRoot, element);
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element, token));
executeQueuedTasks();
вҖҰ
}
HTMLConstructionSite.cpp
void HTMLElementStack::pushHTMLHtmlElement(PassRefPtr(HTMLStackItem) item)
{
pushRootNodeCommon(item);
}
к°Ғк°Ғмқҳ parent node(document)мҷҖ child
node(HTML)лЎң 묶м–ҙм„ң m_attachmentQueueм—җ
append
m_attachmentRoot
HTMLhtmlElement
(htmlTag)
HTML
HTMLConstructionSite.cpp
void HTMLElementStack::pushRootNodeCommon(PassRefPtr<HTMLStackItem> rootItem)
{
m_rootNode = rootItem->node();
pushCommon(rootItem);
}
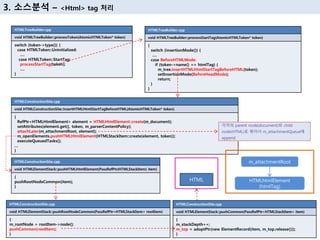
3. мҶҢмҠӨ분м„қ вҖ“ <Html> tag мІҳлҰ¬
HTMLConstructionSite.cpp
void HTMLElementStack::pushCommon(PassRefPtr<HTMLStackItem> item)
{
m_stackDepth++;
m_top = adoptPtr(new ElementRecord(item, m_top.release()));
}
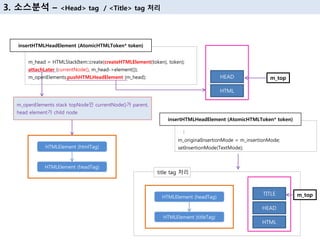
23. HTMLConstructionSite.cpp
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomicHTMLToken* token)
{
RefPtr<HTMLHtmlElement> element = HTMLHtmlElement::create(m_document);
setAttributes(element.get(), token, m_parserContentPolicy);
attachLater(m_attachmentRoot, element);
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element, token));
executeQueuedTasks();
вҖҰ
}
3. мҶҢмҠӨ분м„қ вҖ“ <Html> tag мІҳлҰ¬
HTMLConstructionSite.cpp
void HTMLConstructionSite::executeQueuedTasks()
const size_t size = m_attachmentQueue.size();
вҖҰ
AttachmentQueue queue;
for (size_t i = 0; i < size; ++i)
{
executeTask(queue[i])
}
вҖҰ
}
HTMLConstructionSite.cpp
void static inline void executeTask(вҖҰ)
{
вҖҰ
if (task.nextChild)
task.parent->parserInsertBefore(task.child.get(),
task.nextChild.get());
else
task.parent->parserAppendChild(task.child.get());
вҖҰ
}
ContainerNode.cpp
void ContainerNode::parserAppendChild
{
вҖҰ
Node* last = m_lastChild;
вҖҰ
appendChildToContainer(newChild.get(), this);
вҖҰ
вҖҰ
}
ContainerNodeAlgorithms.h
<inline void appendChildToContainer(GenericNode* child,
GenericNodeContainer* container)>
{
const size_t size = m_attachmentQueue.size();
вҖҰ
if (lastChild) {
child->setPreviousSibling(lastChild);
lastChild->setNextSibling(child);
} else
container->setFirstChild(child);
container->setLastChild(child);
}
HTML
Document
24. HTMLElement (htmlTag)
HTMLElement (headTag)
m_head = HTMLStackItem::create(createHTMLElement(token), token);
attachLater (currentNode(), m_head->element());
m_openElements.pushHTMLHeadElement (m_head);
insertHTMLHeadElement (AtomicHTMLToken* token)
m_openElements stack topNodeмқё currentNode()к°Җ parent,
head elementк°Җ child node
HEAD
HTML
HEAD
HTML
TITLE
HTMLElement (headTag)
HTMLElement (titleTag)
title tag мІҳлҰ¬
3. мҶҢмҠӨ분м„қ вҖ“ <Head> tag / <Title> tag мІҳлҰ¬
пёҷ
m_originalInsertionMode = m_insertionMode;
setInsertionMode(TextMode);
insertHTMLHeadElement (AtomicHTMLToken* token)
m_top
m_top
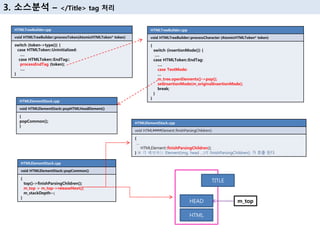
26. 3. мҶҢмҠӨ분м„қ вҖ“ </Title> tag мІҳлҰ¬
HTMLElementStack.cpp
void HTMLElementStack::popCommon()
{
top()->finishParsingChildren();
m_top = m_top->releaseNext();
m_stackDepth--;
}
HTMLTreeBuilder.cpp
void HTMLTreeBuilder::processToken(AtomicHTMLToken* token)
switch (token->type()) {
case HTMLToken::Uninitialized:
вҖҰ.
case HTMLToken::EndTag::
processEndTag (token);
вҖҰ.
}
HTMLTreeBuilder.cpp
void HTMLTreeBuilder::processCharacter (AtomicHTMLToken* token)
{
switch (insertionMode()) {
вҖҰ.
case HTMLToken::EndTag:
вҖҰ.
case TextMode:
вҖҰ
m_tree.openElements()->pop();
setInsertionMode(m_originalInsertionMode);
break;
}
}
HTMLElementStack.cpp
void HTMLElementStack::popHTMLHeadElement()
{
popCommon();
}
HTMLElementStack.cpp
void HTML####Element::finishParsingChildren()
{
вҖҰ
HTMLElement::finishParsingChildren();
} вҖ» к°Ғ н•ҙлӢ№н•ҳлҠ” Element(img, head вҖҰ)мқҳ finishParsingChildren() к°Җ нҳём¶ң лҗңлӢӨ
HEAD
HTML
TITLE
m_top
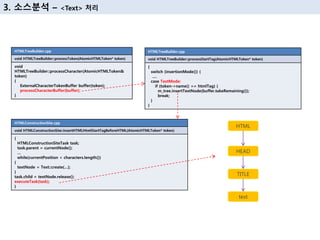
27. switch (insertionMode()) {
вҖҰ
}
m_tree.openElements()->popAll();
вҖҰ
void HTMLTreeBuilder::processEndOfFile(AtomicHTMLToken* token)
3. мҶҢмҠӨ분м„қ вҖ“ <Head> tag / <Title> tag мІҳлҰ¬
const size_t size = m_attachmentQueue.size();
вҖҰ
AttachmentQueue queue;
for (size_t i = 0; i < size; ++i)
{
executeTask(queue[i])
}
if (task.nextChild)
task.parent->parserInsertBefore(task.child.get(), task.nextChild.get());
Else
task.parent->parserAppendChild(task.child.get());
вҖҰ
}
void HTMLConstructionSite::executeQueuedTasks()
HTML
HEAD
TITLE
text
BODY
P
text
Editor's Notes #4: DOM(Document Object Model)мқҖ HTML л¬ём„ңмқҳ лӘЁл“ мҡ”мҶҢм—җ м ‘к·јн•ҳлҠ” л°©лІ•мқ„ м •мқҳн•ң APIлӢӨ.
DOM к°қмІҙлҠ” н…ҚмҠӨнҠёмҷҖ мқҙлҜём§Җ, н•ҳмқҙнҚјл§ҒнҒ¬, нҸј м—ҳлҰ¬лЁјнҠё л“ұмқҳ к°Ғ л¬ём„ң м—ҳлҰ¬лЁјнҠёлҘј лӮҳнғҖлӮёлӢӨ. мһҗл°”мҠӨнҒ¬лҰҪнҠё мҪ”л“ңм—җм„ңлҠ” лҸҷм Ғмқё HTMLмқ„ л§Ңл“Өм–ҙлӮҙкё° мң„н•ҙ DOM к°қмІҙм—җ м ‘к·јн•ҙм„ң мЎ°мһ‘н• мҲҳ мһҲлӢӨ
#7: Synchronous Mode(лҸҷкё°л°©мӢқ)
Allow Yield(м–‘ліҙ н—Ҳмҡ©)
Force Synchronous (к°•м ң лҸҷкё°)
#10: Goto л¬ёмқ„ мқҙмҡ©н•ҳм—¬ н•ҙлӢ№ мғҒнғңлЎң Directн•ҳкІҢ мқҙлҸҷ.#11: Goto л¬ёмқ„ мқҙмҡ©н•ҳм—¬ н•ҙлӢ№ мғҒнғңлЎң Directн•ҳкІҢ мқҙлҸҷ.#12: Goto л¬ёмқ„ мқҙмҡ©н•ҳм—¬ н•ҙлӢ№ мғҒнғңлЎң Directн•ҳкІҢ мқҙлҸҷ.#13: Vector<Attribute, 10> AttributeList;
Vector<UChar, 256> DataVector;
Attribute вҖ“ in a class вҖ“ in a class Rage(start, end), Range nameRange, Range valueRange, Vector<UChar, 32> name, Vector<UChar, 32> value;
#21: Start








![HTMLConstructionSite.cpp
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomicHTMLToken* token)
{
RefPtr<HTMLHtmlElement> element = HTMLHtmlElement::create(m_document);
setAttributes(element.get(), token, m_parserContentPolicy);
attachLater(m_attachmentRoot, element);
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element, token));
executeQueuedTasks();
вҖҰ
}
3. мҶҢмҠӨ분м„қ вҖ“ <Html> tag мІҳлҰ¬
HTMLConstructionSite.cpp
void HTMLConstructionSite::executeQueuedTasks()
const size_t size = m_attachmentQueue.size();
вҖҰ
AttachmentQueue queue;
for (size_t i = 0; i < size; ++i)
{
executeTask(queue[i])
}
вҖҰ
}
HTMLConstructionSite.cpp
void static inline void executeTask(вҖҰ)
{
вҖҰ
if (task.nextChild)
task.parent->parserInsertBefore(task.child.get(),
task.nextChild.get());
else
task.parent->parserAppendChild(task.child.get());
вҖҰ
}
ContainerNode.cpp
void ContainerNode::parserAppendChild
{
вҖҰ
Node* last = m_lastChild;
вҖҰ
appendChildToContainer(newChild.get(), this);
вҖҰ
вҖҰ
}
ContainerNodeAlgorithms.h
<inline void appendChildToContainer(GenericNode* child,
GenericNodeContainer* container)>
{
const size_t size = m_attachmentQueue.size();
вҖҰ
if (lastChild) {
child->setPreviousSibling(lastChild);
lastChild->setNextSibling(child);
} else
container->setFirstChild(child);
container->setLastChild(child);
}
HTML
Document](https://image.slidesharecdn.com/dom-150601114037-lva1-app6892/85/Dom-23-320.jpg)
![switch (insertionMode()) {
вҖҰ
}
m_tree.openElements()->popAll();
вҖҰ
void HTMLTreeBuilder::processEndOfFile(AtomicHTMLToken* token)
3. мҶҢмҠӨ분м„қ вҖ“ <Head> tag / <Title> tag мІҳлҰ¬
const size_t size = m_attachmentQueue.size();
вҖҰ
AttachmentQueue queue;
for (size_t i = 0; i < size; ++i)
{
executeTask(queue[i])
}
if (task.nextChild)
task.parent->parserInsertBefore(task.child.get(), task.nextChild.get());
Else
task.parent->parserAppendChild(task.child.get());
вҖҰ
}
void HTMLConstructionSite::executeQueuedTasks()
HTML
HEAD
TITLE
text
BODY
P
text](https://image.slidesharecdn.com/dom-150601114037-lva1-app6892/85/Dom-27-320.jpg)
