Dutch Journalism in the Digital Age
Download as pptx, pdf0 likes1,106 views

Presentation for Etmaal van de Communicatie 2013 (http://etmaal2013.nefca.eu/). Research is ongoing, please do not cite
1 of 14
Download to read offline













Ad
Recommended
Achtergondinfo cijfers en links
Achtergondinfo cijfers en linksB Walburgh Schmidt
╠²
achtergrondinfo bij workshop social media op inspiratiedag oranjefonds #zomerscholen 28-02-2012Local/Digital: Challenges and opportunities
Local/Digital: Challenges and opportunitiesJesse Holcomb
╠²
The document discusses the challenges and opportunities facing local news in a digital age, highlighting high interest in local news among underserved populations. It notes that local audiences are increasingly accessing news digitally, though at varying paces across different communities, with TV still dominating the market. Digital publishers, often nonprofit and small-staffed, are emerging to fill gaps in news coverage, particularly in areas where traditional outlets have struggled.Networked Journalism and the Arab Spring
Networked Journalism and the Arab SpringRob Jewitt
╠²
The document explores the concept of networked journalism, emphasizing its collaborative nature where professionals and amateurs work together to report news, especially highlighted during events like the Arab Spring and the Iranian protests. It details how social media platforms played pivotal roles in these uprisings by facilitating communication and activism while also addressing the dangers of misinformation and censorship. Ultimately, it concludes that networked journalism contributes to a dynamic flow of information but recognizes its limitations in fostering genuine revolutions.Networked Journalism, Prague, Tol
Networked Journalism, Prague, Tolhubthe
╠²
The document discusses six key drivers for why communities are important to newspapers: 1) Level of usage - from simply reading to creating and consuming content, 2) Type of storytelling - from pure content to embedding links, 3) Distribution channels - from print paper to converging digital channels, 4) Building reputation and relevance - from the newspaper brand to social context, 5) Products and services offered - from written content to additional services, and 6) Reaching audiences - from mass markets to fragmented online communities. The document examines how newspapers can leverage online communities across these six areas.Foundations in Networked Journalism
Foundations in Networked Journalism Edelman
╠²
The document discusses the evolution of networked journalism, highlighting the transition from traditional mass media to user-driven social media platforms. It emphasizes the importance of building a strong user community for journalists and outlines strategies for content optimization, source verification, and community engagement. Key principles include authenticity, simplicity, and maximizing interactions among users to foster deeper connections with their communities.Social media and news: Key trends in networked information
Social media and news: Key trends in networked informationJesse Holcomb
╠²
The document discusses trends in how news is consumed on social media platforms, highlighting differences between Facebook and Twitter. Facebook users typically encounter news passively, while Twitter is used more actively for breaking news despite having lower overall adoption for news consumption. Additionally, the document notes that social media can enhance participation in news discussions, particularly among different demographic groups.Search Joins with the Web - ICDT2014 Invited Lecture
Search Joins with the Web - ICDT2014 Invited LectureChris Bizer
╠²
The document presents an invited lecture on 'Search Joins with the Web' at the ICDT 2014 conference, highlighting methods to extend local tables using structured web data. It discusses the motivation and feasibility of search joins, providing an overview of the various data models and available structured data on the web. Key concepts include the operation of search joins, the role of linked data, and the challenges of integrating heterogeneous web tables.Big Data Warsaw
Big Data WarsawMaximilian Michels
╠²
This document provides an overview of Apache Flink, an open-source framework for distributed stream and batch data processing. It discusses key aspects of Flink including that it executes everything as data streams, supports iterative and cyclic data flows, allows mutable state in operators, and provides high availability and checkpointing of operator state. It also provides examples of using Flink's DataStream API to perform operations like hourly and daily tweet impression counts on a continuous stream of tweet data from Kafka.Create your-own-gem-with-github-jeweler-rubygems
Create your-own-gem-with-github-jeweler-rubygemsNico Hagenburger
╠²
This document provides instructions for creating your own Ruby gem with GitHub, Jeweler, and RubyGems. It outlines setting up a GitHub account and RubyGems account, using Jeweler to generate the gem scaffolding and Rakefile, writing a description, committing to a GitHub repository, locally installing and releasing the gem to RubyGems.org with the rake release task. It concludes with reminders to add documentation and tests to the new gem.3 Steps to Make Better & Faster Frontends
3 Steps to Make Better & Faster FrontendsNico Hagenburger
╠²
The document outlines techniques for creating efficient front-end stylesheets using SCSS, focusing on features like color manipulation, mixins, and extending styles. It introduces tools like Compass and Lemonade for generating sprites and managing CSS, while providing code examples for practical implementation. It also includes links for further reading and resources related to SCSS and styling frameworks.Big Frontends Made Simple
Big Frontends Made SimpleNico Hagenburger
╠²
The document provides an overview of using Sass and Compass to structure CSS projects. It discusses folder organization, file naming conventions, and handling different browsers through conditional browser classes rather than browser hacks or separate CSS files. Structuring projects with Sass partials and Compass modules allows for modular and extensible CSS development.3 ways-to-create-sprites-in-rails
3 ways-to-create-sprites-in-railsNico Hagenburger
╠²
The document discusses different ways to create CSS sprites in Rails applications. It describes image sprites and how they can improve website performance by reducing HTTP requests. It then provides information on the integrated sprite support in Rails 3.1, the css_sprite gem for generating sprites, and the lemonade gem which provides an easy way to generate sprites. It includes code examples and discusses pros and cons of different sprite approaches.Lien entre le pib et l'├®nergie, par Ga├½l Giraud ads - 2014.03.06
Lien entre le pib et l'├®nergie, par Ga├½l Giraud ads - 2014.03.06The Shift Project
╠²
The document discusses the dependency of output growth on primary energy, highlighting its importance through Kaya's equation and the implications of ignoring this relationship. It presents empirical estimations using different approaches, including a PMG approach and Bayesian estimations within a DSGE model framework. Additionally, the document reviews historical data to analyze trends and patterns in output growth relative to energy consumption and efficiency.Mining the Web of Linked Data with RapidMiner
Mining the Web of Linked Data with RapidMinerHeiko Paulheim
╠²
The document introduces the RapidMiner Linked Open Data extension, which enables users to mine linked data from the web without needing to know SPARQL. It provides various operators for data loading, transformation, modeling, and analysis, allowing for the combination and enrichment of local and remote data sources. The extension's applications include analyzing factors influencing scientific publication rates and improving predictive models, along with deployment on the RapidMiner marketplace.Is the Semantic Web what we expected? Adoption Patterns and Content-driven Ch...
Is the Semantic Web what we expected? Adoption Patterns and Content-driven Ch...Chris Bizer
╠²
The document discusses expectations and realities of the semantic web, highlighting that while there was hope for structured data publishing and comprehensive ontologies, the actual landscape shows limited data sharing and varying quality. It compares linked data and HTML-embedded data, revealing challenges such as low identifier usage and the complexity of product categorization. Ultimately, it notes a significant gap between initial aspirations and current implementations, suggesting the need for improved incentives for data providers.Graph Structure in the Web - Revisited. WWW2014 Web Science Track
Graph Structure in the Web - Revisited. WWW2014 Web Science TrackChris Bizer
╠²
The document discusses research that revisits the graph structure of the web using a new large crawl from Common Crawl. It finds that the web has become more dense and connected over time, with the largest strongly connected component growing significantly. While previous research found power laws for in- and out-degrees, this data does not fit power laws and instead has heavy-tailed distributions. The shape of the bow-tie structure also depends on the specific crawl used. The authors provide the new crawl data and analysis to enable further research on the evolving structure of the web graph.New Directions in Mahout's Recommenders
New Directions in Mahout's Recommenderssscdotopen
╠²
This document summarizes recent developments in Mahout's recommender systems since the publication of Mahout in Action over two years ago. It describes new single machine recommenders, factor models, and item-based collaborative filtering algorithms that can be computed in parallel on Hadoop. Experimental results show these new methods can analyze the Yahoo! Songs dataset of 700 million ratings across 26 machines in under 40 minutes for item similarities and 2 minutes per iteration for matrix factorization. Extending Tables with Data from over a Million Websites
Extending Tables with Data from over a Million WebsitesChris Bizer
╠²
The document presents research on extending local tables with data from the web, specifically focusing on the integration of big data from over a million websites during a conference in 2014. It discusses various operations for adding columns to tables, types of web data used, and details on datasets like the web data commons and indexed tables. The conclusion highlights the feasibility of simple queries for merging data from diverse web sources and suggests potential applications beyond web data.Introduction to Collaborative Filtering with Apache Mahout
Introduction to Collaborative Filtering with Apache Mahoutsscdotopen
╠²
This document provides an overview of Apache Mahout, an open-source library for scalable machine learning and data mining. It describes Mahout's collaborative filtering module and how it can be used to build recommender systems. Key classes and algorithms are explained, including item-based collaborative filtering, latent factor models like SVD, and tools for evaluating recommender quality. Potential student projects are outlined, such as implementing a novel similarity measure or improving Mahout's capabilities for temporal recommendation evaluation.Next directions in Mahout's recommenders
Next directions in Mahout's recommenderssscdotopen
╠²
This document summarizes Sebastian Schelter's presentation on next directions in Mahout's recommenders. It discusses how Mahout has expanded its recommender capabilities since the Mahout in Action book was published over two years ago. Specifically, it now includes several popular latent factor models for matrix factorization and tools for scaling neighborhood and matrix factorization methods using MapReduce. Future directions discussed include improved tools for evaluation, more memory-efficient models, and deploying recommenders using search engines.ActiveMQ In Action
ActiveMQ In ActionBruce Snyder
╠²
This document summarizes common problems and solutions when using ActiveMQ. It addresses questions about creating JMS clients from scratch, efficiently managing connections, consuming only certain messages, reasons for locking/freezing, when a network of brokers is needed, and using a master/slave configuration. Spring JMS and selectors are recommended over building clients from scratch. Connection pooling and caching are advised for efficiency. Selectors and proper design can filter messages. Memory, prefetch limits, and cursors impact performance and need configuration. Networked brokers improve availability while master/slave configurations provide high availability.The Graph Structure of the Web - Aggregated by Pay-Level Domain
The Graph Structure of the Web - Aggregated by Pay-Level Domainoli-unima
╠²
The document summarizes research on analyzing the structure of the 2012 web graph when aggregated by pay-level domain (PLD) rather than by individual pages. Some key findings include: the indegree distribution follows a power law but the outdegree distribution does not; the bow-tie structure is unbalanced with a large OUT component compared to previous studies; approximately 42% of domains are connected by paths and the average path length is 4.27 hops; and high connectivity depends more on links to hubs than on hubs themselves. Analysis of topic-specific subgraphs and the public suffix graph show varying patterns of internal and external links.2015 Denver User Group Salary Survey
2015 Denver User Group Salary SurveySalesforce Denver User Group
╠²
The 2015 Colorado salary survey, conducted by the Denver user group, reported an average annual salary of $93,160, reflecting a 4.9% increase from 2014. The survey included responses from various roles, with Salesforce consultants earning the highest average salary at $113,785. Additionally, the survey highlighted a gender salary gap, with females earning an average of $89,320 compared to males at $98,980.Adoption of the Linked Data Best Practices in Different Topical Domains
Adoption of the Linked Data Best Practices in Different Topical DomainsChris Bizer
╠²
The document outlines the adoption of linked data best practices across various topical domains, highlighting the importance of RDF links, vocabulary reuse, and metadata publication for data discoverability and integration. It presents findings from a 2014 update to the state of the Linked Open Data (LOD) cloud, indicating a 93% growth in datasets since 2011, while assessing the adherence to best practices. Additionally, it compares linked data practices to schema.org implementations, noting the latter's wider adoption despite narrower focus on complex data structures.Sydney
Sydneyvinitshah2811
╠²
This document provides information about Sydney, Australia. It includes sections on:
- Capital, language, population, time zone, currency of Australia
- Facts about the size and population density of Australia and its political divisions
- Details on Sydney's climate, popular times to visit, and average temperatures by month
- Prohibitions on importing certain food items and agricultural products to Australia
- Overviews of different itinerary options in and around Sydney, including hotels and activities
- Descriptions of popular tourist attractions in and near Sydney like the Harbour Bridge, Opera House, Blue Mountains, and Sydney TowerAustralian history
Australian historyClaudia Ca├▒as
╠²
The first settlers arrived in Australia around 50,000 years ago, with population growth 10,000 years ago as the climate improved. Fighting decimated Aboriginal populations, especially in Tasmania. In 1788, the First Fleet established the first European settlement in Sydney as a penal colony, founding modern Australia on 26 January. In 1901, the federation of Australian colonies created the Commonwealth of Australia.Gathering Alternative Surface Forms for DBpedia Entities
Gathering Alternative Surface Forms for DBpedia EntitiesHeiko Paulheim
╠²
The paper discusses the importance of surface forms for entities in DBpedia, which are critical for various NLP tasks such as co-reference resolution and entity linking. It highlights the extraction and evaluation process of surface forms from Wikipedia, with a focus on improving quality through filtering techniques. The authors present their findings and contributions, including a gold standard dataset and improved precision for popular and random entities, while emphasizing the often-overlooked quality of Wikipedia-based surface forms.Bibliothecaris deŌĆ© Content Curator?
Bibliothecaris deŌĆ© Content Curator?Jan de Waal
╠²
Content Curator, content curation, contentcuartie een nieuwe hype, een nieuw vak. Een aanzet met veel tools, bronnen. Deze lezingen gehouden voor http://cnin2010.blogspot.nl/ en mediatheek politieacademie ApeldoornPresentatie voor smc0413
Presentatie voor smc0413Jan de Waal
╠²
Wie zoekt vindt niet alles meer in Google. Internet worden gesloten eilanden en wie informatie wilt vinden moet meerdere tools gebruiken en sociale media vereist weer geheel andere technieken. Mobiel internet verandert het zoek gedraag nog meer.....en meer van dit soort vragen en handige trucs om te zoeken. More Related Content
Viewers also liked (20)
Big Data Warsaw
Big Data WarsawMaximilian Michels
╠²
This document provides an overview of Apache Flink, an open-source framework for distributed stream and batch data processing. It discusses key aspects of Flink including that it executes everything as data streams, supports iterative and cyclic data flows, allows mutable state in operators, and provides high availability and checkpointing of operator state. It also provides examples of using Flink's DataStream API to perform operations like hourly and daily tweet impression counts on a continuous stream of tweet data from Kafka.Create your-own-gem-with-github-jeweler-rubygems
Create your-own-gem-with-github-jeweler-rubygemsNico Hagenburger
╠²
This document provides instructions for creating your own Ruby gem with GitHub, Jeweler, and RubyGems. It outlines setting up a GitHub account and RubyGems account, using Jeweler to generate the gem scaffolding and Rakefile, writing a description, committing to a GitHub repository, locally installing and releasing the gem to RubyGems.org with the rake release task. It concludes with reminders to add documentation and tests to the new gem.3 Steps to Make Better & Faster Frontends
3 Steps to Make Better & Faster FrontendsNico Hagenburger
╠²
The document outlines techniques for creating efficient front-end stylesheets using SCSS, focusing on features like color manipulation, mixins, and extending styles. It introduces tools like Compass and Lemonade for generating sprites and managing CSS, while providing code examples for practical implementation. It also includes links for further reading and resources related to SCSS and styling frameworks.Big Frontends Made Simple
Big Frontends Made SimpleNico Hagenburger
╠²
The document provides an overview of using Sass and Compass to structure CSS projects. It discusses folder organization, file naming conventions, and handling different browsers through conditional browser classes rather than browser hacks or separate CSS files. Structuring projects with Sass partials and Compass modules allows for modular and extensible CSS development.3 ways-to-create-sprites-in-rails
3 ways-to-create-sprites-in-railsNico Hagenburger
╠²
The document discusses different ways to create CSS sprites in Rails applications. It describes image sprites and how they can improve website performance by reducing HTTP requests. It then provides information on the integrated sprite support in Rails 3.1, the css_sprite gem for generating sprites, and the lemonade gem which provides an easy way to generate sprites. It includes code examples and discusses pros and cons of different sprite approaches.Lien entre le pib et l'├®nergie, par Ga├½l Giraud ads - 2014.03.06
Lien entre le pib et l'├®nergie, par Ga├½l Giraud ads - 2014.03.06The Shift Project
╠²
The document discusses the dependency of output growth on primary energy, highlighting its importance through Kaya's equation and the implications of ignoring this relationship. It presents empirical estimations using different approaches, including a PMG approach and Bayesian estimations within a DSGE model framework. Additionally, the document reviews historical data to analyze trends and patterns in output growth relative to energy consumption and efficiency.Mining the Web of Linked Data with RapidMiner
Mining the Web of Linked Data with RapidMinerHeiko Paulheim
╠²
The document introduces the RapidMiner Linked Open Data extension, which enables users to mine linked data from the web without needing to know SPARQL. It provides various operators for data loading, transformation, modeling, and analysis, allowing for the combination and enrichment of local and remote data sources. The extension's applications include analyzing factors influencing scientific publication rates and improving predictive models, along with deployment on the RapidMiner marketplace.Is the Semantic Web what we expected? Adoption Patterns and Content-driven Ch...
Is the Semantic Web what we expected? Adoption Patterns and Content-driven Ch...Chris Bizer
╠²
The document discusses expectations and realities of the semantic web, highlighting that while there was hope for structured data publishing and comprehensive ontologies, the actual landscape shows limited data sharing and varying quality. It compares linked data and HTML-embedded data, revealing challenges such as low identifier usage and the complexity of product categorization. Ultimately, it notes a significant gap between initial aspirations and current implementations, suggesting the need for improved incentives for data providers.Graph Structure in the Web - Revisited. WWW2014 Web Science Track
Graph Structure in the Web - Revisited. WWW2014 Web Science TrackChris Bizer
╠²
The document discusses research that revisits the graph structure of the web using a new large crawl from Common Crawl. It finds that the web has become more dense and connected over time, with the largest strongly connected component growing significantly. While previous research found power laws for in- and out-degrees, this data does not fit power laws and instead has heavy-tailed distributions. The shape of the bow-tie structure also depends on the specific crawl used. The authors provide the new crawl data and analysis to enable further research on the evolving structure of the web graph.New Directions in Mahout's Recommenders
New Directions in Mahout's Recommenderssscdotopen
╠²
This document summarizes recent developments in Mahout's recommender systems since the publication of Mahout in Action over two years ago. It describes new single machine recommenders, factor models, and item-based collaborative filtering algorithms that can be computed in parallel on Hadoop. Experimental results show these new methods can analyze the Yahoo! Songs dataset of 700 million ratings across 26 machines in under 40 minutes for item similarities and 2 minutes per iteration for matrix factorization. Extending Tables with Data from over a Million Websites
Extending Tables with Data from over a Million WebsitesChris Bizer
╠²
The document presents research on extending local tables with data from the web, specifically focusing on the integration of big data from over a million websites during a conference in 2014. It discusses various operations for adding columns to tables, types of web data used, and details on datasets like the web data commons and indexed tables. The conclusion highlights the feasibility of simple queries for merging data from diverse web sources and suggests potential applications beyond web data.Introduction to Collaborative Filtering with Apache Mahout
Introduction to Collaborative Filtering with Apache Mahoutsscdotopen
╠²
This document provides an overview of Apache Mahout, an open-source library for scalable machine learning and data mining. It describes Mahout's collaborative filtering module and how it can be used to build recommender systems. Key classes and algorithms are explained, including item-based collaborative filtering, latent factor models like SVD, and tools for evaluating recommender quality. Potential student projects are outlined, such as implementing a novel similarity measure or improving Mahout's capabilities for temporal recommendation evaluation.Next directions in Mahout's recommenders
Next directions in Mahout's recommenderssscdotopen
╠²
This document summarizes Sebastian Schelter's presentation on next directions in Mahout's recommenders. It discusses how Mahout has expanded its recommender capabilities since the Mahout in Action book was published over two years ago. Specifically, it now includes several popular latent factor models for matrix factorization and tools for scaling neighborhood and matrix factorization methods using MapReduce. Future directions discussed include improved tools for evaluation, more memory-efficient models, and deploying recommenders using search engines.ActiveMQ In Action
ActiveMQ In ActionBruce Snyder
╠²
This document summarizes common problems and solutions when using ActiveMQ. It addresses questions about creating JMS clients from scratch, efficiently managing connections, consuming only certain messages, reasons for locking/freezing, when a network of brokers is needed, and using a master/slave configuration. Spring JMS and selectors are recommended over building clients from scratch. Connection pooling and caching are advised for efficiency. Selectors and proper design can filter messages. Memory, prefetch limits, and cursors impact performance and need configuration. Networked brokers improve availability while master/slave configurations provide high availability.The Graph Structure of the Web - Aggregated by Pay-Level Domain
The Graph Structure of the Web - Aggregated by Pay-Level Domainoli-unima
╠²
The document summarizes research on analyzing the structure of the 2012 web graph when aggregated by pay-level domain (PLD) rather than by individual pages. Some key findings include: the indegree distribution follows a power law but the outdegree distribution does not; the bow-tie structure is unbalanced with a large OUT component compared to previous studies; approximately 42% of domains are connected by paths and the average path length is 4.27 hops; and high connectivity depends more on links to hubs than on hubs themselves. Analysis of topic-specific subgraphs and the public suffix graph show varying patterns of internal and external links.2015 Denver User Group Salary Survey
2015 Denver User Group Salary SurveySalesforce Denver User Group
╠²
The 2015 Colorado salary survey, conducted by the Denver user group, reported an average annual salary of $93,160, reflecting a 4.9% increase from 2014. The survey included responses from various roles, with Salesforce consultants earning the highest average salary at $113,785. Additionally, the survey highlighted a gender salary gap, with females earning an average of $89,320 compared to males at $98,980.Adoption of the Linked Data Best Practices in Different Topical Domains
Adoption of the Linked Data Best Practices in Different Topical DomainsChris Bizer
╠²
The document outlines the adoption of linked data best practices across various topical domains, highlighting the importance of RDF links, vocabulary reuse, and metadata publication for data discoverability and integration. It presents findings from a 2014 update to the state of the Linked Open Data (LOD) cloud, indicating a 93% growth in datasets since 2011, while assessing the adherence to best practices. Additionally, it compares linked data practices to schema.org implementations, noting the latter's wider adoption despite narrower focus on complex data structures.Sydney
Sydneyvinitshah2811
╠²
This document provides information about Sydney, Australia. It includes sections on:
- Capital, language, population, time zone, currency of Australia
- Facts about the size and population density of Australia and its political divisions
- Details on Sydney's climate, popular times to visit, and average temperatures by month
- Prohibitions on importing certain food items and agricultural products to Australia
- Overviews of different itinerary options in and around Sydney, including hotels and activities
- Descriptions of popular tourist attractions in and near Sydney like the Harbour Bridge, Opera House, Blue Mountains, and Sydney TowerAustralian history
Australian historyClaudia Ca├▒as
╠²
The first settlers arrived in Australia around 50,000 years ago, with population growth 10,000 years ago as the climate improved. Fighting decimated Aboriginal populations, especially in Tasmania. In 1788, the First Fleet established the first European settlement in Sydney as a penal colony, founding modern Australia on 26 January. In 1901, the federation of Australian colonies created the Commonwealth of Australia.Gathering Alternative Surface Forms for DBpedia Entities
Gathering Alternative Surface Forms for DBpedia EntitiesHeiko Paulheim
╠²
The paper discusses the importance of surface forms for entities in DBpedia, which are critical for various NLP tasks such as co-reference resolution and entity linking. It highlights the extraction and evaluation process of surface forms from Wikipedia, with a focus on improving quality through filtering techniques. The authors present their findings and contributions, including a gold standard dataset and improved precision for popular and random entities, while emphasizing the often-overlooked quality of Wikipedia-based surface forms.Similar to Dutch Journalism in the Digital Age (20)
Bibliothecaris deŌĆ© Content Curator?
Bibliothecaris deŌĆ© Content Curator?Jan de Waal
╠²
Content Curator, content curation, contentcuartie een nieuwe hype, een nieuw vak. Een aanzet met veel tools, bronnen. Deze lezingen gehouden voor http://cnin2010.blogspot.nl/ en mediatheek politieacademie ApeldoornPresentatie voor smc0413
Presentatie voor smc0413Jan de Waal
╠²
Wie zoekt vindt niet alles meer in Google. Internet worden gesloten eilanden en wie informatie wilt vinden moet meerdere tools gebruiken en sociale media vereist weer geheel andere technieken. Mobiel internet verandert het zoek gedraag nog meer.....en meer van dit soort vragen en handige trucs om te zoeken. Beeldbank UT en Social Media
Beeldbank UT en Social MediaJulia Meijvogel
╠²
Een adviesrapport voor Universiteit Twente m.b.t. de beeldbank en social media Social mediawatching en monitoring
Social mediawatching en monitoringHuib Koeleman
╠²
presentatie over de mogelijkheden van mediawatching en monitoring van social media. Hoe kan je makkelijk informatie en mensen vinden. Een inventarisatie zonder de pretentie volledig te zijn.Digitaal bijblijven
Digitaal bijblijvenJan de Waal
╠²
De offline versie van de "Digitaal bijblijven" lezing/workshop in de bibliotheek Weert. Nieuwe ontwikkelingen op digitaal gebied.
In vogelvlucht door het digitale landschap van iPad tot Twitter
Welke digitale ontwikkelingen en mogelijkheden zijn er in de huidige maatschappij?
Jan de Waal, ook wel 'digitale duizendpoot' genoemd en digitaal bibliothecaris bij de bibliotheek Oss, geeft in vogelvlucht een beeld van de nieuwste digitale ontwikkelingen.
Zo krijgt u meer informatie over:
zoeken in Twitter zonder een Twitteraccount te hebben
een Ereader, Ipad of andere tablet kiezen
spraakbesturing
automatisch vertalen
QR-codes
een goed wachtwoord kiezen.
Ook gaat hij in op de digitale gevaren van 'gratis'. Kortom: een middag om u helemaal digitaal te laten bijspijkeren met veel voorbeelden en filmpjes.Een andere blik op Google
Een andere blik op GoogleEric Sieverts
╠²
Lezing bij "Broodje kennis - Google bij de lunch" - Universiteitsbibliotheek Leiden, 12 juni 2014Content & context in het audiovisuele erfgoeddomein
Content & context in het audiovisuele erfgoeddomeinErwin Verbruggen
╠²
Presentatie voor het Contentcaf├® #3 over 'de goudmijnen van Hilversum'. Onderwerp: onderzoek naar en programma's rond contextualisering van televisie-erfgoed bij de afdeling R&D bij Beeld en Geluid.40 jaar informatiegebruik
40 jaar informatiegebruikEric Sieverts
╠²
Over informatiegroei, informatieinflatie, evolutie van zoeksystemen en van literatuuronderzoek (Afscheidsseminar Eric Sieverts)Sociale media en tablets. Wat kan je ermee in het basisonderwijs
Sociale media en tablets. Wat kan je ermee in het basisonderwijsSteven Verjans
╠²
Deze presentatie was een deel vand e training die ik gaf aan de docenten van de Vlissingse Schoolvereniging (http://www.vsvsite.nl/), de winnaar van de publieksprijs van de Jos van Kemenade award 2012. http://look.ou.nl/portal/app/index.jsp?module=316 De video over hun winnende project vind je op http://www.leraar24.nl/video/3624Digitaal zoeken deel 1
Digitaal zoeken deel 1Jan de Waal
╠²
Het valt niet mee om digitaal bij te blijven. Het internet is een levend mechanisme, dat iedere dag verandert. Veel oefenen is nodig om digitaal bij te blijven, zeker als bibliothecaris.
Jan de Waal heeft, samen met Bibliotheekblad, een online workshop ontwikkeld om op een leuke manier te oefenen in het zoeken in allerlei databanken en zo al doende een aantal handige tools te leren kennen. Het gaat om een serie van drie artikelen, gekoppeld aan een aantal vragen, om het digitale kennisniveau van de deelnemers bij te slijpen en te testen. Sommige vragen laten je nadenken en andere zorgen voor een grappige wending. Het is ook leuk om digitaal te puzzelen. Het verhoogt je kennis en zoekvaardigheden en biedt je daarmee de gereedschappen om klanten met zoekvragen beter te kunnen helpen.Informatievaardigheden
Informatievaardigheden Private
╠²
Presentatie voor collega bibliothecarissen van Bibliotheek Rotterdam over informatievaardigheden in 2017Roeland Ordelman en Lotte Belice Baltussen (Beeld en Geluid) @ CMC Uit het lab
Roeland Ordelman en Lotte Belice Baltussen (Beeld en Geluid) @ CMC Uit het labMedia Perspectives
╠²
Roeland Ordelman en Lotte Belice Baltussen (Beeld en Geluid) tijdens het iMMovator Cross Media Cafe Uit het lab (12 februari 2013). Meer informatie: http://www.immovator.nl/cross-media-cafe-uit-het-labAd
More from MaxKemman (16)
Boundary practices in digital humanities
Boundary practices in digital humanitiesMaxKemman
╠²
This document summarizes the findings of a survey on boundary practices in digital humanities collaborations. The survey found that digital humanities collaborations often involve more humanities researchers than computational researchers, and are led primarily by those from the humanities. Additionally, most collaborators work in separate buildings and communicate remotely, rather than meeting in person as commonly assumed. The frequency of disciplinary communication was higher than interdisciplinary communication, suggesting scholars remain aligned with their own disciplines rather than developing common ground across disciplines as collaborations assume. Overall, the realities of digital humanities collaborations diverge from assumptions of equal participation, shared physical space, and development of interdisciplinary identities.Infrastructure As Afterthought
Infrastructure As AfterthoughtMaxKemman
╠²
The document presents an ethnographic study on digital history collaborations in the Benelux region, focusing on the infrastructure's role in these projects. It discusses the incentives for developing digital infrastructures, the alignment of technology with scholarly practices, and the concept of 'infrastructuring' as a continuous process rather than a fixed entity. The findings suggest that scholars may not prioritize infrastructure as a primary concern, indicating the need for a broader understanding of how digital humanities project practices align with technology.Interdisciplinary Ignorance
Interdisciplinary IgnoranceMaxKemman
╠²
The document discusses interdisciplinary collaboration, particularly in digital history, highlighting the issues of knowledge asymmetry between historians and computer scientists. It presents case studies revealing how this asymmetry leads to power struggles and undesirable project outcomes due to a lack of understanding of each other's methods. The conclusions emphasize that collaboration does not guarantee information symmetry, raising questions about the nature of trading zones in academic partnerships.Digital History Projects as Boundary Objects
Digital History Projects as Boundary ObjectsMaxKemman
╠²
Digital history projects can act as boundary objects that coordinate different incentives and allow participation across disciplines. They bring together researchers with different goals, like tool developers focused on technology, historians interested in research, and others focused on building the tool. While the official goal is to build a new tool for historical research, in reality the tool may not be stable enough for research in the project timeframe. This leads the different communities of practice within a project to shape it individually according to their own needs and incentives. Digital history projects require coordination to manage risks and expectations when incentives do not directly align with the overall goals of the project.Digital History Projects as Boundary Objects
Digital History Projects as Boundary ObjectsMaxKemman
╠²
This document summarizes a study of incentives for participants in digital history projects. It finds that while the official incentive is to build new tools for historical research, the realities are different for each community of practice (CoP). The research CoP prioritizes their own thesis work over the tool. The technology CoP focuses on building interfaces rather than ensuring the tool is stable for research. And the tool CoP sees the project as a way to prove concepts and gain continued funding. As a result, the project functions more as a boundary object that coordinates these different incentives rather than achieving the goal of a finished tool for historians to use. There are open questions around whether historians can do big data analysis before tools are ready, and howUser Required? On the Value of User Research in the Digital Humanities
User Required? On the Value of User Research in the Digital HumanitiesMaxKemman
╠²
This document discusses the value of user research in developing digital tools for humanities research. It describes user research conducted for two tools: PoliMedia, which links Dutch parliamentary debates to media items, and Oral History Today, a search interface for oral histories. The research identified user requirements for both tools, though some requirements were deemed out of scope. Common requirements included searching by time period and names/roles of people. The discussion concludes that while generalizing requirements is difficult, user research helps ensure tools are usable and support researchers' broader workflows.Too Many Varied User Requirements for Digital Humanities Projects
Too Many Varied User Requirements for Digital Humanities ProjectsMaxKemman
╠²
The document discusses two digital humanities projects that developed tools for scholars: PoliMedia and Oral History Today. User requirements were collected from scholars through interviews and evaluations. For both projects, there was a small overlap between user requirements and the project goals. Many requirements were deemed out of scope. This suggests that while scholars have clear ideas for their own research, their tool requirements are too varied for single projects to address. The conclusion is that repurposing data and tools in new ways may better meet scholars' diverse needs.Talking With Scholars - Developing a Research Environment for Oral History Co...
Talking With Scholars - Developing a Research Environment for Oral History Co...MaxKemman
╠²
Max Kemman discusses developing a research environment for oral history collections. He outlines four stages of research that scholars may go through: exploration and selection of collections, exploration and investigation of materials, presentation of results, and data curation. The system was evaluated in multiple cycles with scholars and is meant to provide search, filtering, bookmarking, and sharing capabilities for oral history collections.Oral History Today
Oral History TodayMaxKemman
╠²
Oral History Today - Search Interface for Oral History Research
Presented at CLARIAH meeting 11 September 2013 by Roeland Ordelman (NISV) and Max Kemman (EUR)
║▌║▌▀Żs in Dutch, slide notes in EnglishBuilding the PoliMedia search system; data- and user-driven
Building the PoliMedia search system; data- and user-drivenMaxKemman
╠²
The Polimedia system aims to link media coverage of political debates with data from various sources, such as newspapers and radio bulletins. It utilizes a user-driven approach to ensure that the interface meets the needs of researchers by incorporating user feedback into the design process. The system employs semantic web standards to make the data openly accessible and facilitate effective searches linked to Dutch parliamentary debates.User research in the development of PoliMedia
User research in the development of PoliMediaMaxKemman
╠²
The document outlines user research conducted for the development of Polimedia, emphasizing the importance of understanding user search behavior, preferences, and requirements. It includes findings from surveys and interviews about user experiences with various search engines, notably Google, and highlights key issues and user wishes for the new system. Wireframes for the interface and a general usability evaluation process are also described, aiming to create an intuitive and effective search experience.User research for the development of search systems
User research for the development of search systemsMaxKemman
╠²
The document discusses user research for the development of audiovisual search systems, focusing on the needs of diverse user groups such as broadcast professionals, academics, and home users. It presents findings from surveys and interviews about how different disciplines utilize digital sources and the effectiveness of various search techniques, highlighting the dominance of text-based data and user trust based on experience. The research emphasizes the importance of user-centered design in creating intuitive and effective search systems for digital heritage collections.Who are the users of a video search system?
Who are the users of a video search system?MaxKemman
╠²
The document explores the classification of users in a video search system using a profile matrix that distinguishes users by experience and goal-directedness. A survey of 970 users identifies a majority as inexperienced and goal-directed, highlighting distinct demographic differences in video consumption. The findings aim to improve user understanding and inform usability research for video search systems.Mapping the use of digital sources amongst Humanities scholars in the Netherl...
Mapping the use of digital sources amongst Humanities scholars in the Netherl...MaxKemman
╠²
1) The document reports on a survey of 294 Dutch and Belgian academics regarding their use of digital sources and databases.
2) It finds that text is the most commonly used digital medium, and Google is the dominant search tool and platform. Younger academics are more confident in using audiovisual search tools.
3) Disciplines like history and literature most commonly use images and digitized objects, while fields like social studies and linguistics make more use of video, audio, and statistical data.
4) The study has implications for how to increase awareness, appeal and adoption of digital humanities approaches through user-focused design and inclusion in education.PoliMedia presentation NOTaS meeting
PoliMedia presentation NOTaS meetingMaxKemman
╠²
1) The PoliMedia project aims to link multimedia sources like newspaper articles and radio bulletins to discussions in the Dutch parliament to allow for better analysis of how media covered political debates.
2) It extracts structure and named entities from parliamentary debates and uses dates, topics, entities and speakers to automatically query media archives.
3) The current approach links debates to media coverage within a one-month period by searching archives for mentions of entities from each debate. This allows insight into how different media portrayed the same political discussions and events.Polimedia kick-off presentation
Polimedia kick-off presentationMaxKemman
╠²
The document discusses a research project called PoliMedia that aims to analyze media coverage of political debates in the Dutch parliament from 1956 to 1995. The project will link multimedia sources like newspapers, television, and radio to provide insight into how different media covered topics and people over time. By connecting these sources through a portal, researchers can more easily browse and search debates and gain a better understanding of the relationships between media items. The project seeks collaboration to build structured datasets and a virtual workspace to support academic research.Ad
Dutch Journalism in the Digital Age
- 1. Work in progress Please do not cite Dutch Journalism in the Digital Age Bob Nieman, Max Kemman @bobnl001 @MaxJ_K Martijn Kleppe, Henri Beunders ESHCC - Erasmus Universiteit Rotterdam www.axes-project.eu
- 2. Aanleiding ŌĆó Informatie voor nieuwsitems lijkt slechts een muisklik verder ŌĆó Digitale tools kunnen journalisten helpen (Van Ess, 2010) ŌĆó Tot dusver beperkt onderzocht (Hermans, Vergeer & Pleijter, 2011; Machill & Beiler, 2009; Pleijter & Deuze, 2003) Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 3. Aanleiding data.overheid.nl www.axes-project.eu
- 4. Onderzoeksvraag ŌĆó Op welke manier worden digitale bronnen gebruikt in het werkproces door Nederlandse journalisten? ŌĆó Deelvragen 1. In hoeverre worden online databases en zoekmachines gebruikt? 2. Welke zoektechnieken worden daarbij toegepast? Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 5. Methode ŌĆó Etnografische studie ŌĆó 13 journalisten van een landelijk dagblad ŌĆó Gevolgd tijdens productie van een artikel ongeveer 4 uur ŌĆó Observaties en interviews ŌĆó Survey ŌĆó Online survey ŌĆó 298 respondenten Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
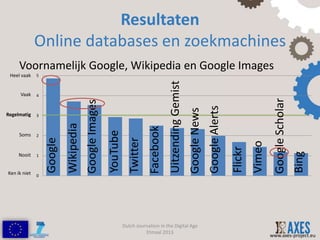
- 6. Resultaten Online databases en zoekmachines Voornamelijk Google, Wikipedia en Google Images Heel vaak 5 Uitzending Gemist Vaak 4 Google Scholar Google Images Google Alerts Google News Regelmatig 3 Wikipedia Facebook YouTube Soms 2 Twitter Google Vimeo Flickr Bing Nooit 1 Ken ik niet 0 Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 7. ŌĆ£Websites die ik gebruik zijn geselecteerd op eerdere ervaring, bewezen betrouwbaarheid en journalistieke normen die de websites zichzelf opleggen.ŌĆØ Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 8. Resultaten Online databases en zoekmachines data.overheid.nl www.axes-project.eu
- 9. Resultaten Zoektechnieken ŌĆó Leunen sterk op trefwoorden ŌĆó Bladwijzers zijn belangrijk beginpunt, en leveren input voor zoekvragen Heel vaak 5 Vaak 4 Trefwoorden Geavanceerde Visualisaties Gerelateerde Regelmatig 3 Thesaurus Categorieen Booleaans zoekpagina Soms 2 browsen termen Filters Nooit 1 Ken ik niet 0 Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 10. ŌĆ£In het begin gaat het erom greep te krijgen op het verhaal en ben je op zoek naar een structuur; wat is de kern, basis, rode draad in het verhaal.ŌĆØ Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 11. Resultaten Zoekruit Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 12. Conclusie ŌĆó Standaard zoektechnieken; voornamelijk Google ŌĆó Ervaren journalisten kiezen sneller invalshoek ŌĆó Onervaren journalisten meer afhankelijk van anderen Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 13. Aanbevelingen ŌĆó Verbeteren van digitale vaardigheden ŌĆó Digitale vaardigheden verdienen meer aandacht in opleiding van huidige en toekomstige journalisten ŌĆó Specialisatie van journalisten in specifieke disciplines Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu
- 14. Bedankt! Bob Nieman Max Kemman bobniemannl@gmail.com kemman@eshcc.eur.nl Referenties Ess, H. van (2010), De Google Code. Amsterdam: Pearson Addison Wesle Hermans, L., Vergeer, M., Pleijter, A. (2011), Nederlandse journalisten in 2010. Nijmegen: Radboud Universiteit. Machill, M. and Beiler, M. (2009) ŌĆśThe importance of the internet for journalistic researchŌĆÖ, Journalism Studies 10: 2, pp. 178-203. Pleijter, A. & Deuze, M. (2003) ŌĆśInternet in de JournalistiekŌĆÖ In H. Blanken & M. Deuze, De mediarevolutie. Meppel: Boom. pp. 33-49. Dutch Journalism in the Digital Age Etmaal 2013 www.axes-project.eu