




![SIP
E-ARK Information Package (simplified)
representations
metadata
[schemas/documentation]
Structural metadata
Provenance metadata
Technical metadata
Descriptive metadata
SIP
DIP
DIP
Lifecycle
Metadata edits
Migrations
Add emulation info](https://image.slidesharecdn.com/3f75cccf-63b0-46e1-819b-0797d104740f-161005160201/85/E-ARK-iPRES2016-Bern-October-2016-6-320.jpg)










E-ARK-iPRES2016-Bern-October-2016
- 1. European Archival Records and Knowledge Preservation #earkproject www.eark-project.eu @EARKProject An OAIS-oriented System for Fast Package Creation, Search, and Access Sven Schlarb, Rainer Schmidt, Roman Karl, Mihai Bartha, Jan R├Črden, Janet Delve, Kuldar Aas Presenter: Sven Schlarb <sven.schlarb@ait.ac.at> AIT Austrian Institute of Technology IPRES 2016 Bern, October 3, 2016
- 2. THE E-ARK PROJECT IS CO-FUNDED BY THE EUROPEAN COMMISSION UNDER THE ICT-PSP PROGRAMME www.eark-project.eu
- 3. ŌŚÅ E-ARK has defined a basic structure and recommended metadata standards for information packages. ŌŚÅ E-ARK has created a reference implementation covering the functional entities for ingest, archiving, and access according to the OAIS reference model. ŌŚÅ The SME partners KEEP Solutions and ESS have adapted their archiving solutions. ŌĆō RODA repository (KEEP) ŌĆō ESS Preservation Platform (ESS) ŌŚÅ AIT has developed an environment for processing information packages (SIP, AIP, DIP). ŌĆō Providing a graphical front-end called earkweb. ŌŚÅ AIT has developed a scalable backend repository for storing, discovering, and accessing data contained in information packages. ŌĆō Initially based on the Lily repository project, now Cloudera Search. Main outcomes
- 4. ŌĆó Modular package transformation workflows & metadata creation ŌĆó Parallelize full-text indexing ŌĆóFast random access to individual files ŌĆóAggregating data using facet queries ŌĆóData mining (Classification, NER) Faceted Search & Data Mining Access Full-text indexing & search Package transformation and Ingest Reference Implementation Functionality
- 5. ŌĆó Pre-Ingest (Producer) ŌĆō Tasks: SIP Creation, Validation, Submission ŌĆō E-ARK Tools: Database Preservation Tooklit, RODA/EPP Tools, earkweb ŌĆó Ingest ŌĆō Tasks: SIP Validation, Archival Processing, AIP Creation ŌĆō E-ARK Tools: earkweb, RODA, EPP ŌĆó Archival Storage ŌĆō Tasks: Storage to Archival Repository ŌĆō E-ARK Tools: Lily Repository (Cloudera Search), RODA, EPP ŌĆó Data Management ŌĆō Tasks: Discover, Select, and Manipulate Records ŌĆō E-ARK Tools: Lily Repository, RODA, EPP ŌĆó Access ŌĆō Tasks: DIP Creation and activation (e.g. within an RDBMS) ŌĆō E-ARK Tools: earkweb, RODA E-ARK Archival Workflow
- 6. SIP E-ARK Information Package (simplified) representations metadata [schemas/documentation] Structural metadata Provenance metadata Technical metadata Descriptive metadata SIP DIP DIP Lifecycle Metadata edits Migrations Add emulation info
- 7. ŌĆó earkweb is based on Phython and the Celery task execution system. ŌĆō Create archival workflows from predefined tasks which can be executed in parallel on a computer cluster. ŌĆō Examples are data validation, format migration, content extraction, database transformation, packaging, interfacing with storage systems. ŌĆō earkweb provides a graphical interface and can be used interactively as well as in batch mode. earkweb
- 8. ŌĆó The E-ARK Lily repository provides a scalable backend for storing, discovering, and accessing AIPs based on technologies like SolR, MapReduce, and HBase. ŌĆō The repository is entirely distributed allowing us to handle huge amounts of data ŌĆō It provides full-text search, browsing, random access to data contained in IPs. ŌĆō It provides APIs allowing one to carry out computations (like data mining tasks) across the archived content. E-ARK Lily/Hadoop Repository
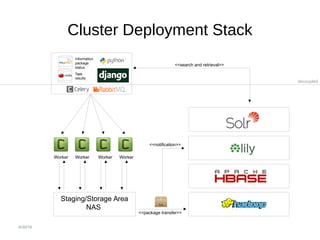
- 9. 6/30/16 Worker Worker Worker Worker Staging/Storage Area NAS <<package transfer>> decoupled <<notification>> <<search and retrieval>> Information package status Task results Cluster Deployment Stack
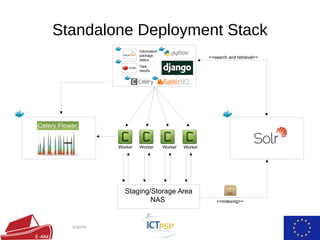
- 10. Standalone Deployment Stack 6/30/16 Worker Worker Worker Worker Staging/Storage Area NAS <<indexing>> <<search and retrieval>> Information package status Task results
- 11. Search & Access ŌĆó Search within and across information packages ŌĆō Full text index for office documents, PDF, MS Word, etc. ŌĆō Search based on defined fields, e.g. size, mime-type, package, etc. ŌĆō Results directly linked with the Lily content repository ŌĆó Faceted queries allowing to cluster search results into different categories ŌĆó Spatio-temporal search in geographical datasets ŌĆó Filter search according to estimated text category (machine learning/text classification)
- 14. Data Mining/NLP ŌĆó Purpose: ŌŚÅ Show how to analyse digital resources contained in the archive in an exemplary manner. ŌĆó Selected use cases: ŌŚÅ Location names occurring in texts. ŌŚÅ Named entity recognition and incorporation of geo- information ŌŚÅ Text classification
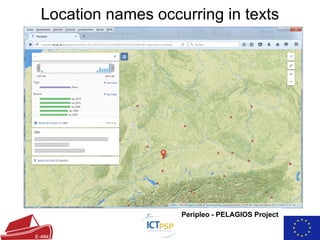
- 15. Location names occurring in texts ŌŚÅ StanfordNER for NER ŌŚÅ nominatim (database behind openstreetmap.org) for georeferencing ŌŚÅ peripleo for visualization
- 16. Location names occurring in texts Peripleo - PELAGIOS Project
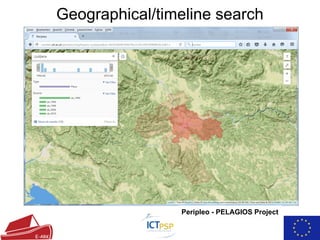
- 17. Geographical/timeline search Peripleo - PELAGIOS Project ŌŚÅ Provided: GML data and TIFF images of maps with metadata (coordinate system, time, etc.) ŌŚÅ Convert GML data to Peripleo RDF ŌŚÅ Translate coordinate system if necessary ŌŚÅ Use peripleo to search for and visualize regions and filter by time
- 18. Geographical/timeline search Peripleo - PELAGIOS Project
- 19. Text classification using scikit-learn ŌŚÅ Prepare data to train SVM classifier ŌŚÅ Dump full-texts of the repository into re- usable packages ŌŚÅ Apply text classification and update SolR records accordingly
- 20. Database archiving, rebuilding and analysis source: wikipedia SIARD RDBMS data (up to 80TB) e.g. Postgres e.g. Oracle Submit ... Archive ... Reconstruct ... Analyse.
- 21. ŌĆó National Archive of Hungary ŌĆō Full scale cluster deployment of earkweb and Hadoop/lily back-end. ŌĆō Ingest, search, and access on large-volumes of AIPs. ŌĆó National Archive of Slovenia ŌĆō earkweb and Peripleo installation for ingesting, visualising, and searching geo-data. ŌĆó Danish National Archives ŌĆō earkweb standalone installation Current Pilots
- 22. Want to try it out? ŌĆó Single-machine deployment of the E-ARK Reference Implementation available online: http://earkdev.ait.ac.at/earkweb ŌĆó Oracle Virtualbox VM (Standalone Deployment!) available for download: http://earkdev.ait.ac.at/eark/pilots/eark- pilot-vm.ova ŌĆó General information about E-ARK: http://www.eark-project.eu