











![2. ĘĮĘ©
? ╔·│╔żĄżņżļź╗źļż╬źčź┐®`ź¾╩²
? «Æż▀▐zż▀ź╗źļŻ║(5 x (BŻŁ2)!)2
? «Æż▀▐zż▀ź╗źļ + ┐s?ź╗źļŻ║(5 x (BŻŁ2)!)4
? BŻĮ7 ż╬ł÷║Ž 1.3 x 1011
źčź┐®`ź¾╩²ż╬╩²ż©ĘĮ
[ [ź╬®`ź╔ż╬▀xÆk╩²ŻĄ]
Ī┴ [(BŻŁ2) éĆż╬ź╬®`ź╔ż╬ż─ż╩ż«ĘĮż╬╩² (BŻŁ2)! ]
] ** [ź╗źļż╬╚ļ?ź╬®`ź╔╩² 2]](https://image.slidesharecdn.com/tfugnn6enasitoh-180709035105/85/Efficient-Neural-Architecture-Searchvia-Parameter-Sharing-15-320.jpg)






![Tensorflowīgū░ż“įćż╣ https://github.com/melodyguan/enas
? źó®`źŁźŲź»ź┴źŃż╬│÷?
[2] Ī· Ą┌Ż▒īėżŽ Ī»Ż▓: sepconv 3x3Ī»
[5 0] Ī·Ą┌Ż▓īėżŽ Ī»ŻĄ: max poolĪ» ź╣źŁź├źūż╩żĘ
[5 1 0] Ī·Ą┌Ż│īėżŽ Ī»ŻĄ: max poolĪ» Ą┌Ż▒īėż╚ź╣źŁź├źūĮėŠA
? įćżĘż╦żõż├żŲż▀ż┐ Ī∙ż┴żŃż¾ż╚żĘż┐Ś╩į^żŪżŽż╩żżżŪż╣
? źįźČż╚ż¬║├ż▀¤åżŁż╬╗ŁŽ±ūRäeźŌźŪźļ
? č¦┴Ģ300ĪóŚ╩į^200ĪóźŲź╣ź╚200ż╬╗ŁŽ±ź┌źó
? ╚╦?źŌźŪźļŻ”▄×ęŲč¦┴ĢźŌźŪźļż╚?▌^
? 24īėżŪ90.5Żźż╬š²ĮŌ┬╩
? ▄×ęŲč¦┴ĢźŌźŪźļŻ©93.5%Ż®ż╦żŽ╝░żąż╩ż½ż├ż┐
[2]
[5 0]
[5 1 0]
[1 0 1 1]
[0 1 0 1 0]
[5 0 0 1 1 0]
[1 0 0 0 0 0 0]
[4 0 0 1 0 0 1 1]
[4 0 1 0 1 0 0 0 1]
[2 0 0 0 1 0 0 0 1 0]
[2 0 1 0 0 1 1 1 1 1 1]
[0 0 0 0 0 1 0 0 0 1 0 0]
[0 0 1 0 0 0 0 0 0 1 1 0 0]
[4 1 0 0 0 1 0 0 0 1 1 0 1 1]
[5 0 1 0 1 1 1 0 1 0 1 0 0 0 0]
[4 0 0 1 0 0 0 1 0 1 0 1 0 1 0 0]
[4 0 0 0 1 0 0 0 1 1 1 1 0 0 0 0 0]
[5 0 0 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0]
[5 0 0 1 1 0 0 1 0 1 1 1 0 0 1 1 1 0 0]
[4 0 0 1 0 1 0 1 1 0 0 1 0 0 1 1 0 0 1 0]
[0 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0]
[2 0 0 0 0 0 1 0 0 0 1 0 1 1 0 0 0 0 0 1 0 0]
[2 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 1 0]
[5 0 0 0 0 1 0 0 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 0]
ENASż╦żĶżļ24īėNNż╬
źó®`źŁźŲź»ź┴źŃ│÷?](https://image.slidesharecdn.com/tfugnn6enasitoh-180709035105/85/Efficient-Neural-Architecture-Searchvia-Parameter-Sharing-23-320.jpg)

Efficient Neural Architecture Searchvia Parameter Sharing
- 1. Efficient Neural Architecture Search via Parameter Sharing 2018/07/05 NNšō╬─ż“ļ╚ż╦ŠŲż“’ŗżÓ╗ß #6 ę┴╠┘ ČÓę╗
- 2. ūį╝║ĮBĮķ ? ├¹Ū░ ? ę┴╠┘ ČÓę╗Ż©żżż╚ż” ż┐żżż┴Ż® ? ╩╦╩┬ ? 1998~2004Ż║ź▌ź╣ź╔ź»Ż└Ēn╣·Ż©└Ēšō╬’└ĒŻ® ? 2004~2013Ż║Ż©ųĻŻ®źóźżź║źšźĪź»ź╚źĻ®`żŪźŪ®`ź┐Ęų╬÷ ? 2013~ ¼Fį┌Ż║Ż©ųĻŻ®źųźņźżź¾źčź├ź╔żŪźŪ®`ź┐Ęų╬÷?蹊┐ķ_░k ? ūŅĮ³Ü▌ż╦ż╩ż├żŲżżżļĘųę░ ? ÅŖ╗»č¦┴Ģ ? ┴┐ūėź│ź¾źįźÕ®`ź┐ ? ųĻü²
- 3. šō╬─ż╦ż─żżżŲ Efficient Neural Architecture Search via Parameter Sharing Authors: Hieu PhamŻ©Google Brain, Carnegie Mellon Univ.Ż® Melody Y. Guan (Stanford Univ.) Barret Zoph, Quoc V. Le, Jeff Dean (Google Brain) arxiv: https://arxiv.org/abs/1802.03268 github: https://github.com/melodyguan/enas ?ų°š▀ż╬ę╗╚╦Melody Y. Guan╩Žż╦żĶżļTensorFlowīgū░Ż©Python2ŽĄŻ®
- 4. äėÖC?─┐Ą─ ? AutoMLż“░Ė╝■żŪ╩╣żżż┐żż ? źŌźŪźļśŗ║Bż“ę╗ż½żķ╩╝żßżļ╩ųķgż“ż╩ż»żĘż┐żż ? ź┴źÕ®`ź╦ź¾ź░ż╬╩ųķgż“ż╩ż»żĘż┐żż ? ÅŖ╗»č¦┴Ģż╬└ĒĮŌż“╔Ņżßż┐żż ? ĘĮ▓▀╣┤┼õĘ©ż“Š▀╠ÕĄ─ż╦└ĒĮŌżĘż┐żżŻ©ĘĮ▓▀Īół¾│Ļż╚żŽŻ® ? LSTMź│ź¾ź╚źĒ®`źķ®`ż╚żĘżŲż╬ė├═Š ? ļx╔óūįė╔Č╚ż╬▀xÆkŻ©ūŅ▀m╗»å¢Ņ}Ż® ? ĢrŽĄ┴ążŪż╬ąąäėøQČ©Ż©╗ßįÆĪóźņź│źßź¾ź╔Ż® ? GANż╚ż╬ķv▀Bąį ? ŽĄ┴ąźŪ®`ź┐ż╬╔·│╔źŌźŪźļŻ©čįšZĪó궜SŻ®Ī∙SeqGAN
- 5. 0. Ė┼ę¬ ? ╝╚┤µż╬NASŻ©Neural Architecture SearchŻ®ż╦?ż┘żŲĪóėŗ╦Ńź│ź╣ź╚ż¼Ė±Č╬ż╦ ╔┘ż╩ż»żŲäI└Ēż¼╦┘żżą┬źóźļź┤źĻź║źÓŻ©ENASŻ®ż“╠ß│¬ ? ╗∙▒ŠĄ─źóźżźŪźóżŽĪóźó®`źŁźŲź»ź┴źŃ╠Į╦„ż╬Ė„ź╣źŲź├źūżŪ¼Fżņżļ║“čaźŌźŪźļķgżŪ ź═ź├ź╚ź’®`ź»ųžż▀ż“╣▓ėąż╣żļż│ż╚ ? ║“čaźŌźŪźļż┤ż╚ż╦ź═ź├ź╚ź’®`ź»ųžż▀ż¼ģ¦╩°ż╣żļż▐żŪč¦┴ĢżĘż╩żżżŪ£gżÓż½żķĪó ėŗ╦Ńź│ź╣ź╚ż¼?Ę∙ż╦Ž„£pżŪżŁżļŻ©GPUĢrķgżŪ╝╚┤µ╩ųĘ©ż╬1000Ęųż╬1Ż® ? źó®`źŁźŲź»ź┴źŃż“╠Į╦„ż╣żļź│ź¾ź╚źĒ®`źķżŽĪó?▓▀╣┤┼õĘ©ż“╩╣ż├żŲŲ┌┤²ł¾│Ļż“ ūŅ?╗»ż╣żļ▓┐Ęųź░źķźšż“▀xżųżĶż”č¦┴Ģż╣żļ ? ų°š▀ż╬ę╗╚╦żŽĪóJeff DeanŻ©MapReduce, TensorFlowż╬ķ_░kš▀Ż®
- 6. 1. ī¦╚ļ ? NASż╬ĮŌšh ? ź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»ż╬źó®`źŁźŲź»ź┴źŃż“?äėżŪ╠Į╦„ż╣żļ?Ę©Ż©AutoMLż╬ę╗ż─Ż® ? ╗ŁŽ±ĘųŅÉż╚čįšZźŌźŪźļż╬źó®`źŁźŲź»ź┴źŃ╠Į╦„ż╦╔Ž╩ųż»▀mė├żŪżŁż┐ ? NASż╬źóźļź┤źĻź║źÓ ? RNNż╦żĶżļź│ź¾ź╚źĒ®`źķż“╩╣ż├żŲĪó║“čaźó®`źŁźŲź»ź┴źŃŻ©child modelŻ®ż“│ķ│÷ ? child model ż“ųžż▀ż¼ģ¦╩°ż╣żļż▐żŪč¦┴ĢżĘżŲżĮż╬ąį─▄ż“įuü²ż╣żļ ? żĮż╬ąį─▄ųĖś╦ż“ guiding signal ż╚żĘżŲĪóżĶżĻ┴╝żżźó®`źŁźŲź»ź┴źŃż“│ķ│÷ż╣żļżĶż” RNNź│ź¾ź╚źĒ®`źķż“č¦┴Ģż╣żļ ? ęį╔Žż“└RżĻĘĄż╣ ? NASż╬šnŅ}Ż║ ? ėŗ╦Ńź│ź╣ź╚ż¼?ż»ĪóäI└ĒĢrķgżŌ?żżŻ©450éĆż╬GPU╩╣ż├żŲ3-4?ķgż½ż½żļŻ® ? ąį─▄įuü²ż╦żĘż½╩╣ż’ż╩żż child model ż“ģ¦╩°ż╣żļż▐żŪč¦┴ĢżĘżŲżĘż▐ż”ż╬ż¼ź▄ź╚źļź═ź├ź»
- 7. 1. ī¦╚ļ ? ENASŻ©Efficient NASŻ® ? NASż╬ä┐┬╩Ż©efficiencyŻ®ż“Ė─╔Ųż╣żļ╩ųĘ©ż╚żĘżŲ ? ż╣ż┘żŲż╬ child models ż¼ź═ź├ź╚©Dź’®`ź»ųžż▀ż“╣▓ėąż╣żļżĶż”ÅŖųŲż╣żļ ? ż│ż╬╣▓ėąż╦żĶżĻĪóchild model ż“ģ¦╩°ż╣żļż▐żŪč¦┴Ģż╣żļ¤o±jż“╗ž▒▄ ? ▄×ęŲč¦┴Ģż╬Ū░└²ż½żķĪó╠žČ©ż╬ź┐ź╣ź»ż╬ż┐żßż╦╠žČ©ż╬źŌźŪźļżŪč¦┴ĢżĄżņż┐ź═ź├ź╚ź’®`ź»ųž ż▀ż¼Īó╦¹ź┐ź╣ź»ż╬ż┐żß╦¹źŌźŪźļż╦ż¬żżżŲĪóżĮż╬ż▐ż▐ż½╔┘żĘż╬ą▐š²żŪ▄×ė├żŪżŁżļż│ż╚ż¼Ęų ż½ż├żŲżżżļ ? «Éż╩żļ child models ķgżŪź═ź├ź╚ź’®`ź»ųžż▀ż“╣▓ėążĘż╩ż¼żķč¦┴ĢżĘżŲżŌ╔Ž╩ųż»żżż»ż╚Ų┌ ┤²żŪżŁżļ ? īg“YżĘżŲż▀ż┐żķĪóųžż▀╣▓ėąż╦żĶżĻNASż╬źčźšź®®`ź▐ź¾ź╣ż¼ų°żĘż»Ž“╔ŽżĘż┐ ? CIFAR-10 ż╬╗ŁŽ±ĘųŅÉŻ©ź©źķ®`┬╩Ż®NAS 2.65Żź ? ENAS 2.89ŻźŻ©═¼│╠Č╚Ż® ? Penn Treebank ż╬čįšZźŌźŪźļ Ż©źč®`źūźņźŁźĘźŲźŻŻ®NAS 62.4 ? ENAS 55.8Ż©Ė─╔ŲŻ® ? ėŗ╦Ńź│ź╣ź╚Ż©GPU-hoursŻ®NAS 1,350-1,800 ? ENAS 0.45Ż©1000Ęųż╬1ż╦┐s?Ż®
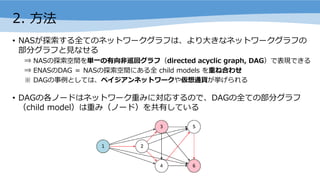
- 8. 2. ĘĮĘ© ? NASż¼╠Į╦„ż╣żļ╚½żŲż╬ź═ź├ź╚ź’®`ź»ź░źķźšżŽĪóżĶżĻ?żŁż╩ź═ź├ź╚ź’®`ź»ź░źķźšż╬ ▓┐Ęųź░źķźšż╚?ż╩ż╗żļ ? NASż╬╠Į╦„┐šķgż“ģg?ż╬ėąŽ“?č▓╗žź░źķźšŻ©directed acyclic graph, DAGŻ®żŪ▒Ē¼FżŪżŁżļ ? ENASż╬DAG ŻĮ NASż╬╠Į╦„┐šķgż╦żóżļ╚½ child models ż“ųžż═║Žż’ż╗ Ī∙ DAGż╬╩┬└²ż╚żĘżŲżŽĪóź┘źżźĖźóź¾ź═ź├ź╚ź’®`ź»żõüóŽļ═©žøż¼Æżż▓żķżņżļ ? DAGż╬Ė„ź╬®`ź╔żŽź═ź├ź╚ź’®`ź»ųžż▀ż╦īØÅĻż╣żļż╬żŪĪóDAGż╬╚½żŲż╬▓┐Ęųź░źķźš Ż©child modelŻ®żŽųžż▀Ż©ź╬®`ź╔Ż®ż“╣▓ėążĘżŲżżżļ
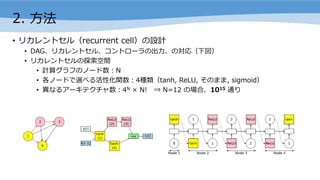
- 9. 2. ĘĮĘ© ? źĻź½źņź¾ź╚ź╗źļŻ©recurrent cellŻ®ż╬įOėŗ ? DAGĪóźĻź½źņź¾ź╚ź╗źļĪóź│ź¾ź╚źĒ®`źķż╬│÷?Īóż╬īØÅĻŻ©Ž┬ćĒŻ® ? źĻź½źņź¾ź╚ź╗źļż╬╠Į╦„┐šķg ? ėŗ╦Ńź░źķźšż╬ź╬®`ź╔╩²Ż║N ? Ė„ź╬®`ź╔żŪ▀xż┘żļ╗Ņąį╗»ķv╩²Ż║4ĘNŅÉŻ©tanh, ReLU, żĮż╬ż▐ż▐, sigmoidŻ® ? «Éż╩żļźó®`źŁźŲź»ź┴źŃ╩²Ż║4N Ī┴ N! ? N=12 ż╬ł÷║ŽĪó1015 ═©żĻ
- 10. 2. ĘĮĘ© ? ENASż╬č¦┴Ģż╚źó®`źŁźŲź»ź┴źŃż╬ī¦│÷ ? ENASż╬č¦┴ĢżŽĪóź│ź¾ź╚źĒ®`źķŻ©źčźķźß®`ź┐ ”╚Ż®ż╚ child modelsŻ©źčźķźß®`ź┐ ”žŻ® ż╬č¦┴Ģż½żķż╩żļ ? ź│ź¾ź╚źĒ®`źķżŽĪó100éĆż╬ļLżņīėż½żķż╩żļLSTMżŪżóżĻĪóźĮźšź╚ź▐ź├ź»ź╣ĘųŅÉŲ„ż“ ĮķżĘżŲ?╝║╗žÄóĄ─ż╦Ż©Ū░ź╣źŲź├źūżŪ│ķ│÷żĘż┐ź╬®`ź╔ż“żĮż╬ź╣źŲź├źūż╬╚ļ┴”ż╚żĘżŲŻ® ź╬®`ź╔ż“│ķ│÷ż╣żļ ? child model ż╬źčźķźß®`ź┐ ”ž żŽĪó╚½żŲż╬ child models żŪ╣▓ėążĄżņżŲżżżļ ? č¦┴ĢżŽĪóź│ź¾ź╚źĒ®`źķż╚ child models ż╬č¦┴Ģż“Į╗╗źż╦└RżĻĘĄż╣ ? Ą┌1źšź¦®`ź║Ż║”žż“č¦┴Ģż╣żļ ? Ą┌2źšź¦®`ź║Ż║”╚ ż“č¦┴Ģż╣żļ ? Ą┌1źšź¦®`ź║ż╚Ą┌2źšź¦®`ź║ż“Į╗╗źż╦└RżĻĘĄż╣
- 11. 2. ĘĮĘ© ? Ą┌1źšź¦®`ź║ż╬įö╝Ü ? ś╦£╩Ą─ż╩Į╗▓Ņź©ź¾ź╚źĒźį®`ōp╩¦L(m; ”ž)ż╬ĘĮ▓▀Ęų▓╝ ”ą(m,”╚) ż½żķ╔·│╔żĄżņżļ child model m ż╦ķvż╣żļŲ┌┤²éÄż╬ ”ž ╣┤┼õż“źŌź¾źŲź½źļźĒĘ©żŪėŗ╦Ńż╣żļ ? ż│ż╬╣┤┼õż╦┤_┬╩Ą─╣┤┼õĘ©Ż©SGDŻ®ż“▀mė├żĘżŲ ”ž ż“Ė³ą┬ż╣żļ ? M=1Ż©child model ż¼1éĆŻ®ż╬ł÷║ŽżŪżŌč¦┴Ģż¼▀MżÓż│ż╚ż¼Ęųż½ż├żŲżżżļ
- 12. 2. ĘĮĘ© ? Ą┌2źšź¦®`ź║ż╬įö╝Ü ? ł¾│Ļķv╩² R(m; ”ž) ż╬ child model m Ī½ ”ą(m,”╚) ż╦ķvż╣żļŲ┌┤²éÄż“ūŅ┤¾╗»ż╣żļżĶż”ż╦ ”╚ ż“Ė³ą┬ż╣żļ ? Š▀╠ÕĄ─ż╦żŽĪóREINFORCEźóźļź┤źĻź║źÓż╦żĶżļĘĮ▓▀╣┤┼õĘ©ż╚AdaŻĒż“╩╣ż├żŲĖ³ą┬ż“īg╩® ? ▀^č¦┴Ģż“▒▄ż▒żļż┐żßĪół¾│Ļķv╩² R(m; ”ž) żŽŚ╩į^ė├źŪ®`ź┐ż╦ż─żżżŲėŗ╦Ńż╣żļ ? ł¾│Ļķv╩²żŽĪóŚ╩į^ė├źŪ®`ź┐żŪėŗ╦ѿʿ┐źŌźŪźļŠ½Č╚ż╚żĘżŲČ©┴xż╣żļ RNNŻ║źč®`źūźņźŁźĘźŲźŻż╬─µ╩² CNNŻ║┼ąäeš²ĮŌ┬╩ ? źó®`źŁźŲź»ź┴źŃż╬ī¦│÷ ? ?▓▀ ”ą(m,”╚) ż╬żŌż╚żŪÄūż─ż½ż╬źŌźŪźļŻ©źó®`źŁźŲź»ź┴źŃ║“čaŻ®ż“╔·│╔ż╣żļ ? Ś╩į^ė├źŪ®`ź┐ż½żķźĄź¾źūźĻź¾ź░żĘż┐ģgę╗ż╬ź▀ź╦źąź├ź┴ż╦ż─żżżŲĪóźŌźŪźļż┤ż╚ż╦ł¾│Ļż“ėŗ╦Ń Ż©ėŗ╦Ńź│ź╣ź╚ż¼╣Ø╝sżŪżŁżļŻ® ? ł¾│Ļż¼ūŅ┤¾ż╚ż╩żļźŌźŪźļż“▀xÆkżĘżŲį┘č¦┴Ģż╣żļ Qż“R(m;”ž)żŪų├żŁōQż©żļ
- 13. 2. ĘĮĘ© ? «Æż▀▐zż▀ź═ź├ź╚ź’®`ź»Ż©CNN, convolutional networkŻ®ż╬įOėŗ ? ź│ź¾ź╚źĒ®`źķż╦żĶżļ▀xÆkøQČ©Ż║ 1. źņźżźõ®`ż╦ż¬ż▒żļėŗ╦ŃäI└Ēż╬▀xÆkŻ©ŻČĘNŅÉż½żķŻ® 2. żĮż╬źņźżźõ®`ż╚ź╣źŁź├źūĮėŠAż╣żļźņźżźõ®`ż╬▀xÆk 3. Ż▒ż╚Ż▓ż“Į╗╗źż╦īg╩®ż╣żļ ? ╔·│╔żĄżņżļź═ź├ź╚ź’®`ź»ż╬źčź┐®`ź¾╩² ? 6L x 2L(LŻŁ1)/2 ? 1.6 x 1029Ż©L=12ż╬ł÷║ŽŻ® ŻČĘNŅÉż╬ėŗ╦ŃäI└Ē ? convolution 3x3, 5x5 ? separable convolution 3x3, 5x5 ? max pooling 3x3 ? average pooling 3x3 LSTMź│ź¾ź╚źĒ®`źķż╦żĶżļ▀xÆk ▀xÆkżĄżņż┐CNNźó®`źŁźŲź»ź┴źŃ Ż©ĄŃŠĆżŽź╣źŁź├źūĮėŠAŻ®
- 14. 2. ĘĮĘ© ? «Æż▀▐zż▀ź╗źļŻ©convolutional cellŻ®ż╬įOėŗ ? «Æż▀▐zż▀ź╗źļż╬ź╬®`ź╔╩²Ż║BŻ©node 1, node 2, ..., node BŻ® ? ź│ź¾ź╚źĒ®`źķż╦żĶżļ▀xÆkøQČ©Ż║ ? node1, node2 żŽ╚ļ┴”ż╚ż╣żļŻ©ų▒Į³ż╬ź═ź├ź╚ź’®`ź»ż╬ź╗źļż½żķ▀xÆkŻ® ? ▓ążĻż╬ BŻŁ2 éĆż╬ź╬®`ź╔ż╦ż─żżżŲęįŽ┬ż╬▀xÆkøQČ©ż“ąąż” ? Ą▒įōź╬®`ź╔ż╬╚ļ?ż╚żĘżŲĪóų▒Ū░ż▐żŪż╬ź╬®`ź╔ż½żķŻ▓ź╬®`ź╔ż“▀xÆk ? żĮżņżķŻ▓ź╬®`ź╔ż╦ū„ė├ż╣żļėŗ╦ŃäI└Ēż“▀xÆkŻ©ŻĄĘNŅÉż½żķŻ® ? ┐s?ź╗źļŻ©reduction cellŻ®ż╬įOėŗżŌ═¼śöż╦ąąż” ŻĄĘNŅÉż╬ėŗ╦ŃäI└Ē ? identityŻ©żĮż╬ż▐ż▐Ż® ? separable convolution 3x3, 5x5 ? average pooling 3x3 ? max pooling 3x3
- 15. 2. ĘĮĘ© ? ╔·│╔żĄżņżļź╗źļż╬źčź┐®`ź¾╩² ? «Æż▀▐zż▀ź╗źļŻ║(5 x (BŻŁ2)!)2 ? «Æż▀▐zż▀ź╗źļ + ┐s?ź╗źļŻ║(5 x (BŻŁ2)!)4 ? BŻĮ7 ż╬ł÷║Ž 1.3 x 1011 źčź┐®`ź¾╩²ż╬╩²ż©ĘĮ [ [ź╬®`ź╔ż╬▀xÆk╩²ŻĄ] Ī┴ [(BŻŁ2) éĆż╬ź╬®`ź╔ż╬ż─ż╩ż«ĘĮż╬╩² (BŻŁ2)! ] ] ** [ź╗źļż╬╚ļ?ź╬®`ź╔╩² 2]
- 16. 3. īg“Y ? Penn Treebank ż“╩╣ż├ż┐čįšZźŌźŪźļ ? GPU 1éĆż“10Ģrķgż▐ż’żĘżŲźĻź½źņź¾ź╚ź╗źļż“╠Į╦„ ? źčźķźß®`ź┐╩²ż╬╔ŽŽ▐ż“ 2,400═“ż╚żĘż┐ ? ąį─▄įuü²żŽźč®`źūźņźŁźĘźŲźŻŻ©PPLŻ®żŪ£yżļ ? īg“YĮY╣¹ źč®`źūźņźŁźĘźŲźŻŻ©PPLŻ® ┤_┬╩ż╬─µ╩² ?▀xÆkų½ż╬╩² PPLż¼?żĄżżż█ż╔Ė▀Š½Č╚
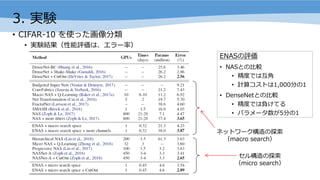
- 17. 3. īg“Y ? ENASż¼░k?żĘż┐źĻź½źņź¾ź╚ź╗źļ ? ENASż╬░k?żĘż┐źó®`źŁźŲź»ź┴źŃżŽĪóūŅßßż╦6ź╬®`ź╔ż╬ŲĮŠ∙ż“ż╚ż├żŲżżżļ ? ż│ż╬śŗįņżŽĪóMoCŻ©Mixture of ContextĪóźŲź»ź╦ź├ź»ż╬ę╗ż─Ż®ż╚ŅÉ╦ŲżĘż┐śŗįņż╦ż╩ż├żŲżżżļ
- 18. 3. īg“Y ? CIFAR-10 ż“╩╣ż├ż┐╗ŁŽ±ĘųŅÉ ? īg“YĮY╣¹Ż©ąį─▄įuü²żŽĪóź©źķ®`┬╩Ż® ź═ź├ź╚ź’®`ź»śŗįņż╬╠Į╦„ Ż©macro searchŻ® ź╗źļśŗįņż╬╠Į╦„ Ż©micro searchŻ® ENASż╬įuü² ? NASż╚ż╬?▌^ ? Š½Č╚żŪżŽ╗źĮŪ ? ėŗ╦Ńź│ź╣ź╚żŽ1,000Ęųż╬1 ? DenseNetż╚ż╬?▌^ ? Š½Č╚żŪżŽžōż▒żŲżļ ? źčźķźß®`ź┐╩²ż¼5Ęųż╬1
- 19. 3. īg“Y ? CIFAR-10 ż“╩╣ż├ż┐╗ŁŽ±ĘųŅÉ ? ENASż¼░k?żĘż┐«Æż▀▐zż▀ź═ź├ź╚ź’®`ź»Ż©ENAS + macro search spaceŻ®
- 20. 3. īg“Y ? CIFAR-10 ż“╩╣ż├ż┐╗ŁŽ±ĘųŅÉ ? ENASż¼░k?żĘż┐«Æż▀▐zż▀ź╗źļż╚┐s?ź╗źļ
- 21. 3. īg“Y ? źķź¾ź└źÓźĄ®`ź┴ż╚ż╬?▌^ ? Penn TreebankŻ©PPLŻ®Ż║źķź¾ź└źÓ 81.2 ŻŠ ENAS 55.8 ? CIFAR-10Ż©ź©źķ®`┬╩Ż®Ż║ ?ENASżŽźķź¾ź└źÓźĄ®`ź┴żĶżĻżŌ?Š½Č╚ż╬źŌźŪźļż“īg¼F ? ź│ź¾ź╚źĒ®`źķż╬Ė³ą┬ż“ąąż’ż╩żżł÷║Ž ? ENAS macro żŪ?▌^Ż©ź©źķ®`┬╩Ż® ? Ė³ą┬ż╩żĘ 5.49% ŻŠ Ė³ą┬żóżĻ 4.23% ?ź│ź¾ź╚źĒ®`źķż╬č¦┴Ģż¼øQČ©Ą─ źķź¾ź└źÓ macro 5.86% ŻŠ ENAS macro 4.23% źķź¾ź└źÓ micro 6.77% ŻŠ ENAS micro 3.54%
- 22. 4. ķv▀B蹊┐ż╚ūhšō ? SMASH ? one-Shot Model Architecture Search through Hypernetworks https://arxiv.org/abs/1708.05344 ? hypernetworksŻ©Ż┐Ż®ż“╩╣ż├żŲź═ź├ź╚ź’®`ź»ųžż▀ż“╔·│╔ż╣żļ ? hypernetworks ż“╩╣ż”ż│ż╚żŪĪó║“čaźó®`źŁźŲź»ź┴źŃż╬ųžż▀ż¼Ą═źķź¾ź»┐šķgż╦ųŲŽ▐żĄżņżļ ? Ą═źķź¾ź»┐šķgżŪźčźšź®®`ź▐ź¾ź╣ż╬żĶżżźó®`źŁźŲź»ź┴źŃżĘż½?ż─ż▒żķżņż╩żż Ż©ENASżŪżŽż│ż”żĘż┐ųŲŽ▐żŽż╩żżŻ®
- 23. Tensorflowīgū░ż“įćż╣ https://github.com/melodyguan/enas ? źó®`źŁźŲź»ź┴źŃż╬│÷? [2] Ī· Ą┌Ż▒īėżŽ Ī»Ż▓: sepconv 3x3Ī» [5 0] Ī·Ą┌Ż▓īėżŽ Ī»ŻĄ: max poolĪ» ź╣źŁź├źūż╩żĘ [5 1 0] Ī·Ą┌Ż│īėżŽ Ī»ŻĄ: max poolĪ» Ą┌Ż▒īėż╚ź╣źŁź├źūĮėŠA ? įćżĘż╦żõż├żŲż▀ż┐ Ī∙ż┴żŃż¾ż╚żĘż┐Ś╩į^żŪżŽż╩żżżŪż╣ ? źįźČż╚ż¬║├ż▀¤åżŁż╬╗ŁŽ±ūRäeźŌźŪźļ ? č¦┴Ģ300ĪóŚ╩į^200ĪóźŲź╣ź╚200ż╬╗ŁŽ±ź┌źó ? ╚╦?źŌźŪźļŻ”▄×ęŲč¦┴ĢźŌźŪźļż╚?▌^ ? 24īėżŪ90.5Żźż╬š²ĮŌ┬╩ ? ▄×ęŲč¦┴ĢźŌźŪźļŻ©93.5%Ż®ż╦żŽ╝░żąż╩ż½ż├ż┐ [2] [5 0] [5 1 0] [1 0 1 1] [0 1 0 1 0] [5 0 0 1 1 0] [1 0 0 0 0 0 0] [4 0 0 1 0 0 1 1] [4 0 1 0 1 0 0 0 1] [2 0 0 0 1 0 0 0 1 0] [2 0 1 0 0 1 1 1 1 1 1] [0 0 0 0 0 1 0 0 0 1 0 0] [0 0 1 0 0 0 0 0 0 1 1 0 0] [4 1 0 0 0 1 0 0 0 1 1 0 1 1] [5 0 1 0 1 1 1 0 1 0 1 0 0 0 0] [4 0 0 1 0 0 0 1 0 1 0 1 0 1 0 0] [4 0 0 0 1 0 0 0 1 1 1 1 0 0 0 0 0] [5 0 0 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0] [5 0 0 1 1 0 0 1 0 1 1 1 0 0 1 1 1 0 0] [4 0 0 1 0 1 0 1 1 0 0 1 0 0 1 1 0 0 1 0] [0 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0] [2 0 0 0 0 0 1 0 0 0 1 0 1 1 0 0 0 0 0 1 0 0] [2 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 1 0] [5 0 0 0 0 1 0 0 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 0] ENASż╦żĶżļ24īėNNż╬ źó®`źŁźŲź»ź┴źŃ│÷?
- 24. ĖąŽļ ? źóźżźŪźóż¼╦žö│ż╦╦╝ż©żļ ? LSTMż“ÅŖ╗»č¦┴Ģż╣żļż╚żżż”░kŽļ ? ▄×ęŲč¦┴Ģż½żķųžż▀╣▓ėąż“╦╝żżż─ż»ż╚ż│żĒ ? ░Ė╝■żŪżŌ╩╣ż©żĮż” ? GPUŻ▒éĆż“1?ż▐ż’ż╗żąĪóżĮżņż╩żĻż╬ĮY╣¹ż¼żŪżļ ? ż┐ż└żĘĪóźņźżźõ®`╩²ĪóźšźŻźļź┐╩²żŽżóżķż½żĖżßøQżßżļ▒žę¬żóżĻ ? TensorFlowīgū░ż╦żŽĪóšō╬─ż╦Ģ°żżżŲż╩żż╣żĘ“ż¼╦µ╦∙ż╦żóżļ ? ź╣źŁź├źūĮėŠAż╬╔·│╔ż╦żŽ attention mechanism ż“╩╣ż├żŲżļ ? ╚╦ķgż¼żóżķż½żĖżß┐╝ż©żŲżļ▓┐ĘųżŌČÓżż ? ╦¹ż╬źŌźŪźļūŅ▀m╗»ż╚?ż┘żŲż╔ż”ż╩ż╬ż½Ż┐ ? ź┘źżź║ūŅ▀m╗» ? żĮż╬╦¹ż╬ NN ż╦żĶżļ╩ųĘ©