°ŚÉēÄŚĆćĒæ»į±Õ·”³¢µž¤Č“”³¢µž¤ČŹżĶņ„¹„Ļ?„¤„ÆøŗŗÉ„Ę„¹„Č
?Download as PPTX, PDF?
33 likes?29,864 views

ÉēÄŚĆć»įŁYĮĻ ~ELB¤ČALB¤ČŹżĶņ„¹„Ļ?„¤„ÆŲŗÉ„Ę„¹„Č~



















































°ŚÉēÄŚĆćĒæ»į±Õ·”³¢µž¤Č“”³¢µž¤ČŹżĶņ„¹„Ļ?„¤„ÆøŗŗÉ„Ę„¹„Č
- 2. ¤ā¤Ę¤ ¤æ¤«¤Ņ¤ķ ? ÖźŹ½»įÉēCyberZ ? „Ó„Ć„°„Ē©`„æ„Ø„ó„ø„Ė„¢ ? ŅŌĒ°¤Ļ„Ŗ©`„ׄ󄽩`„¹¤Ī„ź„¢„ė„愤„ąkernel¤Č ¤«é_°k „ź„¢„ė„愤„ąkernel„³„ó„Ę„„¹„Č„¹„¤„Ć„Į„ó„°¤Īg×° „ā„Ī„ź„·„Ć„Æ/„Ž„¤„Æ„ķ/„Ļ„¤„Ö„ź„Ć„Ékernel„¢©`„¤ĪŌOÓ/g×° ? µĆŅā¤Ź¼¼Šg:„Ø„ó„ø„Ė„¢¤Ī¤æ¤į¤Ī³¬×Ō“¶ https://www.facebook.com/takahiro.moteki.31
- 3. »°¤¹ŹĀ
- 5. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~½U¾~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
- 6. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~½U¾~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
- 9. ½U¾:„ß„Ć„·„ē„ó ? „Ŗ„ó„ׄģ¤«¤éAWS¤ĖŅĘŠŠ¤µ¤»¤ė ? ŹżĶņRPS„Ƅ鄹¤Ī„¹„Ń„¤„Æ°kÉś¤·¤Ę¤āHTTP„Ø„é©` °kÉś¤µ¤»¤Ź¤¤¤č¤¦¤Ź„¢©`„„Ę„Æ„Į„ć/³É¤Ė¤·”¢Ō ņY¤ņŠŠ¤¦ ? „Š„Ć„Æ„Ø„ó„É(¶Łµž/°³Õ³§/µž¾±²µ¶Ł²¹³Ł²¹)¤Ļ½ń»ŲĻóĶā
- 11. ·½Õė¤Ļ“ó¤¤Æ2¤Ä
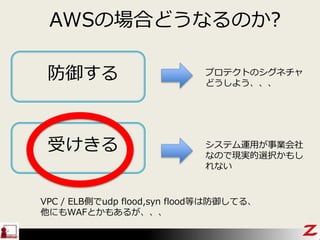
- 12. “”°Ā³§¤Ī³”ŗĻ¤É¤¦¤Ź¤ė¤Ī¤«? ·ĄÓł¤¹¤ė ŹÜ¤±¤¤ė „ׄķ„Ę„Æ„Č¤Ī„·„°„Ķ„Į„ć ¤É¤¦¤·¤č¤¦”¢”¢”¢ „·„¹„Ę„ąß\ÓƤ¬ŹĀI»įÉē ¤Ź¤Ī¤Ē¬FgµÄßxk¤«¤ā¤· ¤ģ¤Ź¤¤ VPC / ELBȤĒudp flood,syn floodµČ¤Ļ·ĄÓł¤·¤Ę¤ė”¢ Ėū¤Ė¤āWAF¤Č¤«¤ā¤¢¤ė¤¬”¢”¢”¢
- 13. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~½U¾~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
- 22. Ńa×ć ? ŲŗÉŌņYĻ󄢄ׄź ĢŲÕ ØC Cloudfront¤Ī¤č¤¦¤Ź¤ā¤Ī¤ĻŹ¹¤Ø¤Ź¤¤(¤ā¤Į¤ķ¤óELB¤Īorigin¤Ė¤ā “Ģ¤»¤Ź¤¤) ØC „»„Ć„·„ē„󤬶Ģ¤Æ”¢keep alived¤Ī¤č¤¦¤Ź¾S³Ö¤Ļ¤Ē¤¤Ź¤¤ ØC HTTP¤Ī„Ø„é©`¤ĻæÉÄܤŹĻŽ¤ź¤Ź¤Æ¤¹ ØC „ģ„¤„Ę„ó„·¤ā¤¢¤ė³Ģ¶Čµ£±£(ŹżŹ®msecŅŌÄŚ)
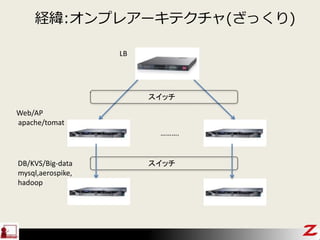
- 24. ELB¤Ė¤Ä¤¤¤Ę ? AWSÉĻ¤Ī„ķ©`„É„Š„é„ó„·„ó„°„µ©`„Ó„¹(„Ž„Ķ©`„ø„É„µ©`„Ó„¹) ? EC2µČ¤ņŲŗÉ·ÖÉ¢ ? L4¤ĪLB ? ĢŲÕ ØC „¹„±©`„é„Ö„ė(AutoScalingŠĶ¤ĪLB) ØC øßæÉÓĆŠŌ(Ń}ŹżAZź/EC2¤ĪÕż³£ŠŌÅŠ¶Ļ¤Ė¤č¤ė„ź„Æ„Ø„¹„Č Õń¤ź·Ö¤±) ØC ß\ÓĆ¹ÜĄķ¤¬S(„Ž„Ķ©`„ø„É„µ©`„Ó„¹¤Ź¤Ī¤Ē) ØC Ķس£¤ĪLB¤Č±Č¤Ł¤ė¤ČCÄÜŠŌ¤ĻÉŁ¤Ź¤¤
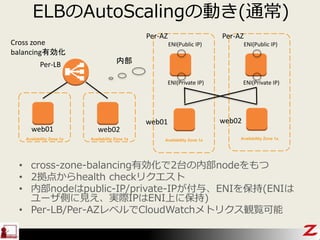
- 25. ELB¤ĪAutoScaling¤ĪÓ¤(Ķس£) ? cross-zone-balancingÓŠæ»Æ¤Ē2ĢؤĪÄŚ²ænode¤ņ¤ā¤Ä ? 2µć¤«¤éhealth check„ź„Æ„Ø„¹„Č ? ÄŚ²ænode¤Ļpublic-IP/private-IP¤¬ø¶Óė”¢ENI¤ņ±£³Ö(ENI¤Ļ „ę©`„¶Č¤ĖŅ¤Ø”¢gėHIP¤ĻENIÉĻ¤Ė±£³Ö) ? Per-LB/Per-AZ„ģ„Ł„ė¤ĒCloudWatch„į„Č„ź„Æ„¹ÓQÓEæÉÄÜ Availability Zone 1a Cross zone balancingÓŠæ»Æ ENI(Public IP) ENI(Private IP) Availability Zone 1a ENI(Public IP) ENI(Private IP) ÄŚ²æ Availability Zone 1a Availability Zone 1a web01 web02 web01 web02 Per-AZ Per-AZ Per-LB
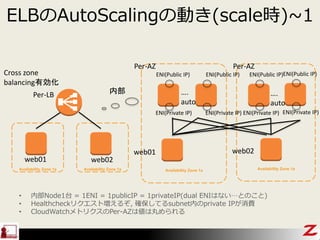
- 26. ELB¤ĪAutoScaling¤ĪÓ¤(scaler)~1 Availability Zone 1a Cross zone balancingÓŠæ»Æ ENI(Public IP) ENI(Private IP) Availability Zone 1a ENI(Public IP) ENI(Private IP) ÄŚ²æ Availability Zone 1a Availability Zone 1a web01 web02 web01 web02 Per-AZ Per-AZ Per-LB ENI(Public IP) ENI(Private IP) ”. auto ”. auto ENI(Public IP) ENI(Private IP) ? ÄŚ²æNode1ĢØ = 1ENI = 1publicIP = 1privateIP(dual ENI¤Ļ¤Ź¤¤”¤Č¤Ī¤³¤Č) ? Healthcheck„ź„Æ„Ø„¹„Č¤Ø¤ė¤¾, “_±£¤·¤Ę¤ėsubnetÄŚ¤Īprivate IP¤¬ĻūŁM ? CloudWatch„į„Č„ź„Æ„¹¤ĪPer-AZ¤Ļ¤ĻĶč¤į¤é¤ģ¤ė
- 27. ELB¤ĪAutoScaling¤ĪÓ¤(scaler)~2 ? ÄŚ²ænode¤Ē¤Ī×·¼ÓÕn½š¤Ļ¤Ź¤· ? ELB¤ĪÄŚ²ænode¤¬p¤¹¤ė ØC ¤¤¤Änode¤Ø¤ė¤«? -> Ņ»Ąż)„ź„Æ„Ø„¹„Č(surge queue length) ØC ¤¤¤Änodep¤ė¤«? -> Ņ»Ąż)„ź„Æ„Ø„¹„Čp(surge queue length) ØC pr¤Ė„³„Ķ„Æ„·„ē„ó¤Ī¶Ļ¤Ļ¤Ź¤¤(EC2¤«¤éŅ¤æöŗĻ) ØC (ŗĪ)p¤·¤æ¤«¤Ī“_ÕJ·½·Ø ? dig„³„Ž„ó„ɵȤĒĆūĒ°¤ņŅż¤¤¤ĘIP¤ņŹż¤Ø¤ė ? ENI¤¬¤Ø¤Ę¤ė¤³¤Č¤ņ“_ÕJ¤¹¤ė ? „¢„Æ„»„¹„ķ„° ? VPC flow logs ØC ¤¤¤Äp¤·¤æ¤« ? Cloudtrai¤ĒENI¤ĪÉś³É/ĘʤĪČÕø¶¤ņ“_ÕJ¤¹¤ė ? „¢„Æ„»„¹„ķ„°¤Ē¤Īµć¼Ó¤ņ“_ÕJ¤¹¤ė ? VPC flow logs ? 2µćELB¤ĪÄŚ²ænode¤ĪČė¤ģĢę¤Ø ØC ¤¤¤ÄČė¤ģĢę¤ļ¤ė¤«? -> Ņ»Ąż)„ź„Æ„Ø„¹„Č(surge queue length) ØC Čė¤ģĢę¤ļ¤źr¤Ī„³„Ķ„Æ„·„ē„ó¶Ļ¤Ļ¤Ź¤¤¤¬”¢TTL„„ć„Ć„·„åĻūŹ§ ØC Čė¤ģĢę¤ļ¤Ć¤æ¤«¤Ī“_ÕJ·½·Ø ? dig„³„Ž„ó„ɤĒĆūĒ°¤ņŅż¤¤¤ĘIP¤Īä»Æ¤ņŅ¤ė ? ENI¤«¤é¤ĪpublicIP/privateIP¤ņ“_ÕJ¤¹¤ė ? „¢„Æ„»„¹„ķ„° ? VPC flow logs ¤¤¤ķ¤¤¤ķ¤Ź¤Č¤³¤ķ¤Ē ”±¤Ą¤¤¤æ¤¤”±¤ļ¤«¤ź¤Ž¤¹
- 28. ELB¤Ī¤Ž¤Č¤į(„„ć„Ń„·„Ę„£Ćę) ? „¹„Ń„¤„ƤĖČõ¤¤ ØC ÄŚ²æNode¤ĒAutoScale¤¹¤ė¤¬”¢Źż+Ćė~Źż·Ö¤Æ¤é¤¤¤«¤«¤ė ? ÄŚ²æNode¤ĪAutoScale¤·¤æÓ¤¤¬¤ļ¤«¤ź¤Ė¤Æ¤¤(„ā„Ė„椷¤Ė ¤Æ¤¤) ? ÄŚ²æNode¤ĪAutoScale¤Ė×·¼ÓÕn½š¤Ź¤· ? ÄŚ²æNode¤ĪAutoScale¤Ļ¤¢¤ė¤¬”¢AutoHealing¤ĻĪ¢Ćī ØC Cross zone balancingÓŠæ»Æ¤Ź¤é¤Š”¢×īŠ”nodeŹż¤ņ2ĢؤŲ±£¤Ä ØC ¤æ¤Ą¤·”¢ELBÄŚ²æ„Ī©`„ɤĖÕĻŗ¦°kÉś¤·AWS„µ„Ż©`„ȤŲČė¤ģĢę¤Ø ¤ņ¤·¤Ę¤ā¤é¤Ć¤æŹĀ¤¢¤ź ÄŚ²æNode¤ĪÓ¤¤Ļ±¾Ą“¤ĻŅā×R¤·¤Ź¤Æ¤ĘĮ¼¤¤¤ā¤Ī”£¤æ¤Ą¤·”¢ ELB¤Ē„¹„Ń„¤„ƤČ餦r¤Ļ¤½¤¦¤ā¤¤¤«¤Ź¤¤
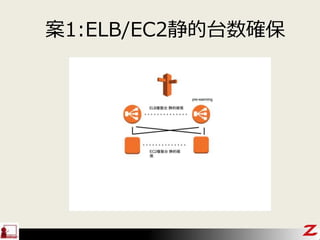
- 29. pre-warming¤Ė¤Ä¤¤¤Ę ? ×ŌĒ°pre-warming ØC ×ŌĒ°¤Ē¶ĪėAµÄ¤ĖŲŗɤ«¤«¤Ęscale¤µ¤»¤Ę¤Ŗ¤”¢„æ „¤„ß„ó„°¤ĒĒŠ¤źĢę¤Ø¤ė ? ÉźÕpre-warming ØC ¾²µÄ¤ĖELB¤ĪÄŚ²æNode¤Ī„„ć„Ń„·„Ę„£¤ņµ£±£¤· ¤Ę¤Ŗ¤Æ(¤ä¤·¤Ę¤Ŗ¤Æ)CÄÜ ØC BusinessŅŌÉĻ¤Ī„µ„Ż©`„Č¼ÓČė&AWS„µ„Ż©`„ȤŲ ÉźÕ¤¹¤ė¤³¤Č¤ĒæÉÄÜ ØC ×·¼ÓÕn½š¤Ź¤·
- 30. ÉźÕpre-warming¤ĪŹĖ ? „Õ„ķ©` ØC ÉźÕ„Õ„©©`„Ž„Ć„ČČėĮ¦¤·¤ĘAWS„µ„Ż©`„Č -> AWSČ×÷I(¼s1~Źżrég) -> “_ÕJ ? 1¶ČÉźÕ¤Ē¤ĪÉĻĻŽĘŚég¤Ļ3„öŌĀ ? pre-warming×ī“ó„„ć„Ń„·„Ę„£ ØC „³„Ķ„Æ„·„ē„óŹż ØC „¤„󄹄æ„󄹄愤„×/ĢØŹż¤Ēpre-warming „„ć„Ń„·„Ę„£ÉĻĻŽ¤¬¤¢¤ė
- 32. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~½U¾~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
- 33. ŲŗÉh¾³/„Ä©`„ė¤Ė¤Ä¤¤¤Ę(„«„Ę„“„鄤„ŗ) ? „Ž„Ķ©`„ø„É„µ©`„Ó„¹/„½„ź„å©`„·„ē„󄵩`„Ó„¹¤ņŹ¹¤¦ ? „¢„ׄ鄤„¢„󄹤ņŹ¹¤¦ ? „Ļ„³¤Ļ×ŌĒ°¤Ē¾²µÄ¤ĖÓĆŅā¤·¤ĘŲŗÉ„Ä©`„ė¤ņŗB¤·¤ĘŹ¹¤¦ „Ŗ„ó„ׄģr“ś ¤Ž¤ŗ”¢„Ļ„³¤¬¤Ź¤¤¤ó¤ø¤ć”¢ »ł±P¤¬Ķ¬¤ø¤Ź¤ó¤ø¤ć(NWÓ°ķŹÜ¤±¤ė)
- 34. ? „Ž„Ķ©`„ø„É„µ©`„Ó„¹/„½„ź„å©`„·„ē„󄵩`„Ó„¹¤ņŹ¹¤¦ ? „¢„ׄ鄤„¢„󄹤ņŹ¹¤¦ ? „Ļ„³¤Ļ×ŌĒ°¤Ē¾²µÄ¤ĖÓĆŅā¤·¤ĘŲŗÉ„Ä©`„ė¤ņŗB¤·¤ĘŹ¹¤¦ ? „Ļ„³¤Ļ„Ƅ鄦„É„Ł„ó„ĄÉĻ¤ĒÓµÄÉś³É¤ņŠŠ¤¤ŲŗÉ„Ä©`„ė¤ņŗB¤·¤ĘŹ¹¤¦ ? „Ƅ鄦„É„Ł„ó„ĄÉĻ¤Ī„Ž„Ķ©`„ø„É„µ©`„Ó„¹¤ņŹ¹¤¦ „Ƅ鄦„ɤĖ¤Ź¤Ć¤ær“ś ßxk¤¬¤Ø¤æ ŲŗÉh¾³/„Ä©`„ė¤Ė¤Ä¤¤¤Ę(„«„Ę„“„鄤„ŗ)
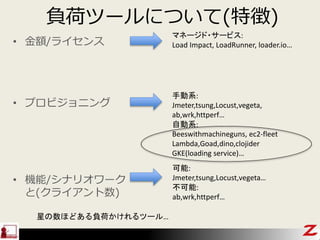
- 35. ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę(ĢŲÕ) ? ½šī~/„鄤„»„ó„¹ ? „ׄķ„Ó„ø„ē„Ė„ó„° ? CÄÜ/„·„Ź„ź„Ŗ„ļ©`„Æ ¤Č(„Ƅ鄤„¢„ó„ČŹż) ŹÖÓĻµ: Jmeter,tsung,Locust,vegeta, ab,wrk,httperf” ×ŌÓĻµ: Beeswithmachineguns, ec2-fleet Lambda,Goad,dino,clojider GKE(loading service)” æÉÄÜ: Jmeter,tsung,Locust,vegeta” ²»æÉÄÜ: ab,wrk,httperf” „Ž„Ķ©`„ø„É?„µ©`„Ó„¹: Load Impact, LoadRunner, loader.io” ŠĒ¤ĪŹż¤Ū¤É¤¢¤ėŲŗɤ«¤±¤ģ¤ė„Ä©`„ė”
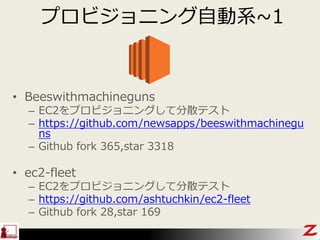
- 37. „ׄķ„Ó„ø„ē„Ė„ó„°×ŌÓĻµ~1 ? Beeswithmachineguns ØC EC2¤ņ„ׄķ„Ó„ø„ē„Ė„ó„°¤·¤Ę·ÖÉ¢„Ę„¹„Č ØC https://github.com/newsapps/beeswithmachinegu ns ØC Github fork 365,star 3318 ? ec2-fleet ØC EC2¤ņ„ׄķ„Ó„ø„ē„Ė„ó„°¤·¤Ę·ÖÉ¢„Ę„¹„Č ØC https://github.com/ashtuchkin/ec2-fleet ØC Github fork 28,star 169
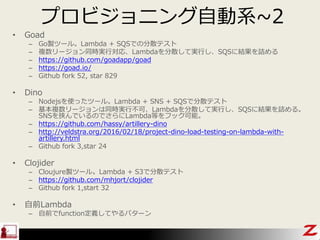
- 39. „ׄķ„Ó„ø„ē„Ė„ó„°×ŌÓĻµ~2 ? Goad ØC GoŃu„Ä©`„ė”£Lambda + SQS¤Ē¤Ī·ÖÉ¢„Ę„¹„Č ØC Ń}Źż„ź©`„ø„ē„óĶ¬rgŠŠź”¢Lambda¤ņ·ÖÉ¢¤·¤ĘgŠŠ¤·”¢SQS¤Ė½Y¹ū¤ņŌ¤į¤ė ØC https://github.com/goadapp/goad ØC https://goad.io/ ØC Github fork 52, star 829 ? Dino ØC Nodejs¤ņŹ¹¤Ć¤æ„Ä©`„ė”£Lambda + SNS + SQS¤Ē·ÖÉ¢„Ę„¹„Č ØC »ł±¾Ń}Źż„ź©`„ø„ē„ó¤ĻĶ¬rgŠŠ²»æÉ”¢Lambda¤ņ·ÖÉ¢¤·¤ĘgŠŠ¤·”¢SQS¤Ė½Y¹ū¤ņŌ¤į¤ė”£ SNS¤ņŠ®¤ó¤Ē¤¤¤ė¤Ī¤Ē¤µ¤é¤ĖLambdaµČ¤ņ„Õ„Ć„ÆæÉÄÜ”£ ØC https://github.com/hassy/artillery-dino ØC http://veldstra.org/2016/02/18/project-dino-load-testing-on-lambda-with- artillery.html ØC Github fork 3,star 24 ? Clojider ØC CloujureŃu„Ä©`„ė”£Lambda + S3¤Ē·ÖÉ¢„Ę„¹„Č ØC https://github.com/mhjort/clojider ØC Github fork 1,start 32 ? ×ŌĒ°Lambda ØC ×ŌĒ°¤Ēfunction¶ØĮx¤·¤Ę¤ä¤ė„Ń„æ©`„ó
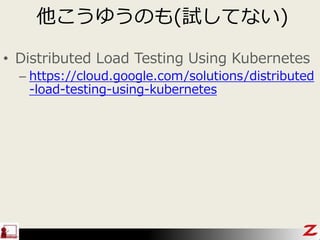
- 40. Ėū¤³¤¦¤ę¤¦¤Ī¤ā(Ō¤·¤Ę¤Ź¤¤) ? Distributed Load Testing Using Kubernetes ØC https://cloud.google.com/solutions/distributed -load-testing-using-kubernetes
- 41. ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę(ßxk ¼¤¤¤ä¤Ä) ? gŠŠ„Ø„ó„ø„ó/„ׄķ„Ó„ø„ē„Ė„ó„° ? „¹„Ń„¤„Æ„¢„Æ„»„¹ ? ·ÖÉ¢„ā©`„É ? long running ? RPS„¹„±„ø„å©`„ź„ó„° ? „·„Ź„ź„Ŗ„ļ©`„Æ ? „µ„Ž„ź„ģ„Ż©`„Č(·ÖÉ¢„ā©`„É) ? „Ƅ鄤„¢„ó„ȤĪßxk ? GUI ? „ā„Š„¤„ė„ā©`„É ? web¤ĪĒéóĮæ ? gæ ? ½ü¤Æ¤ĖŌ¤·¤¤ČĖ¤¬¤¤¤ė¤«? ? ¤½¤ĪĖū(ÕJŌ^¤äcookie„Ę„¹„Č) ? ½šī~/„鄤„»„ó„¹
- 43. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~½U¾~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
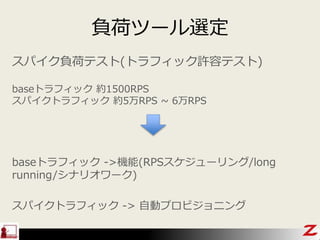
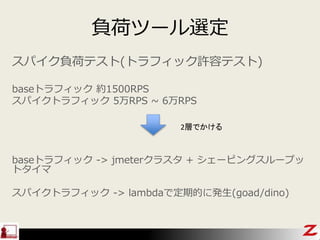
- 44. ŅŖ¼ž“_ÕJ „¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č(„Č„é„Õ„£„Ć„ÆŌSČŻ„Ę„¹„Č) base¤Ī„Č„é„Õ„£„Ć„Æ ¼s1500RPS „¹„Ń„¤„ƤĪ„Č„é„Õ„£„Ć„Æ ¼s5ĶņRPS ~ 6ĶņRPS ? Ņ¤æ¤¤¤Č¤³¤ķ ØC ELB¤Ī„„ć„Ń„·„Ę„£ -> 1„·„Ź„ź„Ŗ ØC EC2Č(OS+„ß„É„ė)¤Č„Ķ„Ć„Č„ļ©`„ƤĪ„„ć„Ń„·„Ę„£ -> 1„·„Ź„ź„Ŗ ØC HTTP¤ĪŠŌÄÜ ØC „¢„ׄź„±©`„·„ē„ó„ģ„¤„ä ? ¤æ¤Ą¤·„¢„ׄź„±©`„·„ē„ó¤Ļ„Ē„ׄķ„¤
- 46. base¤Ē1500RPS¤Ļī}¤Ź¤¤¤¬”¢ŹżĆė¤ĒŅ»Ż¤Ė5ĶņRPS¤«¤± ¤ė”¢Ųŗɤ«¤±¤ėȤɤ¦¤ä¤ė¤ó¤Ą¤³¤ģ£æ „Ƅ鄦„ɤĄ¤·”¢ŹżĆė¤ĒĢØŹż“_±£¤¹¤ģ¤ŠŲŗɤ«¤±¤é¤ģ ¤ė¤«£æ ŅÄī„Ż„¤„ó„Č ŹżĆė -> ¤³¤³¤ĒŹżŹ®Ćė¤«¤«¤Ć¤ĘŲŗɤ«¤±¤ė¤Č”¢ELB¤¬ŁŹÖ ¤Ė„¹„±©`„ė¤·Ź¼¤į¤ė”£æÉÄܤŹ¤é¤Š„ź„Æ„Ø„¹„ČäÓĘŚég¤Ź¤·”£ -> ±¾Ą“¤Ī„Č„é„Õ„£„Ć„ÆŌŁĻÖ„Ę„¹„ȤĖ¤Ź¤Ć¤Ę¤¤¤Ź¤¤
- 47. ¤É¤¦¤ä¤ė¤«”?
- 48. ŲŗÉ„Ä©`„ėßx¶Ø „¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č(„Č„é„Õ„£„Ć„ÆŌSČŻ„Ę„¹„Č) base„Č„é„Õ„£„Ć„Æ ¼s1500RPS „¹„Ń„¤„Æ„Č„é„Õ„£„Ć„Æ ¼s5ĶņRPS ~ 6ĶņRPS base„Č„é„Õ„£„Ć„Æ ->CÄÜ(RPS„¹„±„ø„å©`„ź„ó„°/long running/„·„Ź„ź„Ŗ„ļ©`„Æ) „¹„Ń„¤„Æ„Č„é„Õ„£„Ć„Æ -> ×Ōӄׄķ„Ó„ø„ē„Ė„ó„°
- 49. ŲŗÉ„Ä©`„ėßx¶Ø „¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č(„Č„é„Õ„£„Ć„ÆŌSČŻ„Ę„¹„Č) base„Č„é„Õ„£„Ć„Æ ¼s1500RPS „¹„Ń„¤„Æ„Č„é„Õ„£„Ć„Æ 5ĶņRPS ~ 6ĶņRPS base„Č„é„Õ„£„Ć„Æ -> jmeter„Ƅ鄹„æ + „·„§©`„Ō„ó„°„¹„ė©`„×„Ć „Č„æ„¤„Ž „¹„Ń„¤„Æ„Č„é„Õ„£„Ć„Æ -> lambda¤Ē¶ØĘŚµÄ¤Ė°kÉś(goad/dino) 2Ó¤Ē¤«¤±¤ė
- 50. »·¾³(Č«Ģå¹¹³É)
- 52. ¤ä¤Ć¤Č¤Æ¤Č¤Ŗ¤¹¤¹¤į¤ŹŹĀ(×ć»Ų¤ź) ? Ņ»Ķؤźcacti¤Č¤«„ā„Ė„æ„ź„ó„°„Ä©`„ė¤Ė„į„Č „ź„Æ„¹¤ņÓåh¤µ¤»¤č¤¦ ØC įį¤Ē”¢¤¢”¢¤¢¤Ī„ź„½©`„¹×“rŅĶü¤ģ¤æ”£Ėū¤ĪČĖ¤¬ “_ÕJ¤·¤æ¤¤¤Č¤«¤Č¤«”£ ØC CloudWatch¤Ą¤ČĶس£2ßLég¤ĒĻū¤Ø¤Ž¤¹”£ ? „ķ„°¤ņ¤¦¤Ž¤ÆO¤ģ¤ė¤č¤¦¤Ė¤·¤Ę¤Ŗ¤³¤¦ ØC 1ĢØ1ĢØweb/apČė¤Ć¤Ę„ķ„° §¼Æ¤Ą¤Č¤±¤Ć¤³¤¦Ćęµ¹ ? é_Ź¼¤Č½KĮĖræĢ¤ņÓåh¤·¤Ę¤Ŗ¤³¤¦ ØC ¼¤«¤Æ¤ä¤Ć¤Ę¤¤¤Ę”¢„ź„½©`„¹„į„Č„ź„Æ„¹¤¬¤ļ¤«¤é ¤Ź¤Æ¤Ź¤Ć¤æ¤Č¤«”£
- 53. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~±³¾°~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
- 54. ŌņY„·„Ź„ź„Ŗ ? Ņ¤æ¤¤¤Č¤³¤ķ ØC ELB¤Ī„„ć„Ń„·„Ę„£ -> 1„·„Ź„ź„Ŗ ØC EC2Č(OS+„ß„É„ė)¤Č„Ķ„Ć„Č„ļ©`„ƤĪ„„ć„Ń„·„Ę„£ -> 1 „·„Ź„ź„Ŗ ØC HTTPŠŌÄÜ ØC „¢„ׄź„±©`„·„ē„ó„ģ„¤„ä ? ¤æ¤Ą¤·„¢„ׄź„±©`„·„ē„ó¤Ļ„Ē„ׄķ„¤ ? ¾²µÄ„³„ó„Ę„ó„Ä/ӵĄ³„ó„Ę„ó„Ä ? „ź„½©`„¹µÄ¤Ź„Æ„ź„Ę„£„«„ė„Ń„¹ ? régµÄ¤Ź„Æ„ź„Ę„£„«„ė„Ń„¹
- 55. gŹ©
- 57. ½Y¹ū EC2 38ĢØ ? ±į°Õ°Õ±Ź¤Ī„Ø„é©`¤Ź¤·
- 58. æąŗ¤·¤æ¤Č¤³¤ķ
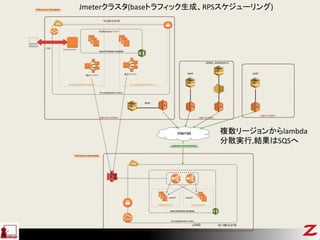
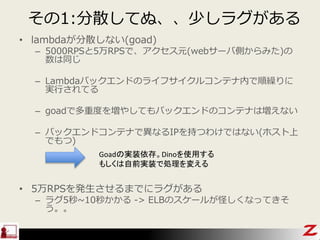
- 59. ¤½¤Ī1:·ÖÉ¢¤·¤Ę¤Ģ”¢”¢ÉŁ¤·„é„°¤¬¤¢¤ė ? lambda¤¬·ÖÉ¢¤·¤Ź¤¤(goad) ØC 5000RPS¤Č5ĶņRPS¤Ē”¢„¢„Æ„»„¹ŌŖ(web„µ©`„ŠČ¤«¤é¤ß¤æ)¤Ī Źż¤ĻĶ¬¤ø ØC Lambda„Š„Ć„Æ„Ø„ó„ɤĪ„鄤„Õ„µ„¤„Æ„ė„³„ó„Ę„ŹÄŚ¤ĒķĄR¤ź¤Ė gŠŠ¤µ¤ģ¤Ę¤ė ØC goad¤Ē¶ąÖŲ¶Č¤ņ¤ä¤·¤Ę¤ā„Š„Ć„Æ„Ø„ó„ɤĪ„³„ó„Ę„Ź¤Ļ¤Ø¤Ź¤¤ ØC „Š„Ć„Æ„Ø„ó„É„³„ó„Ę„Ź¤Ē®¤Ź¤ėIP¤ņ³Ö¤Ä¤ļ¤±¤Ē¤Ļ¤Ź¤¤(„Ū„¹„ČÉĻ ¤Ē¤ā¤Ä) Goad¤Īg×°ŅĄ“ę”£Dino¤ņŹ¹ÓƤ¹¤ė ¤ā¤·¤Æ¤Ļ×ŌĒ°g×°¤ĒIĄķ¤ņä¤Ø¤ė ? 5ĶņRPS¤ņ°kÉś¤µ¤»¤ė¤Ž¤Ē¤Ė„é„°¤¬¤¢¤ė ØC „é„°5Ćė~10Ćė¤«¤«¤ė -> ELB¤Ī„¹„±©`„ė¤¬¹Ö¤·¤Æ¤Ź¤Ć¤Ę¤¤½ ¤¦”£”£
- 61. ¤½¤Ī3:Ćėég„ā„Ė„æ„ź„ó„°¤Īæąŗ ? „¹„Ń„¤„ƤĪ„Ę„¹„Ȥņ¤ä¤Ć¤Ę¤ė¤Ī¤Ē»ł±¾Ćėég„ā „Ė„æ ØC Zabbix(2.4)Ȥ¬ź¤·¤Ę¤¤¤Ź¤¤(„Ē©`„æČ”¤ģ¤Ę ¤ā„°„é„ÕȤ¬Ņ¤Ø¤ó) ? ½Y¾ÖlinuxÉĻ¤Ēscript½M¤ó¤Ē¤ä¤Ć¤æ ØC ½yӤȤėlinuxĖŹ„³„Ž„ó„ɤĻ”¢¤Ū¤ÜŹ¹¤Ø¤Ź¤¤(Ąż netstat¤Č¤«¤Ēestablish connection„«„¦„ó„Č¤Č ¤«)”£1Ćė¤Ē½K¤ļ¤é¤Ź¤¤¤«¤é ØC proc„Õ„”„¤„ė„·„¹„Ę„ą¤ņŹ¹¤Ø
- 62. ¤½¤Ī4:syn cookie°kÓ ? Syn cookie¤Ļ±¾Ą“¤ĻOS¤ĪDDoS¤Ī„ׄķ„Ę „Æ„·„ē„óCÄÜ ØC Õż³£„¹„Ń„¤„Æ„Ę„¹„Č(DDoS¤Ļ¤«¤±¤Ę¤Ź¤¤)¤Ą ¤¬°kÓ¤·„³„Ķ„Æ„·„ē„ó„ź„»„Ć„Č ? ¤æ¤Ą”¢¤³¤ĪC¤¬¤Ź¤¤¤ČTCP„ģ„¤„ä¤Ēdrop ØC ŌŅņ¤ĻKernelȤĪsyn queue„Ŗ©`„Š©`„Õ„ķ©`
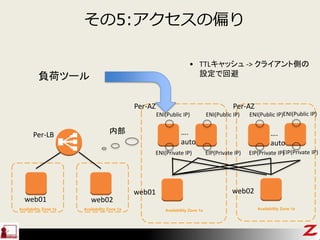
- 63. ¤½¤Ī5:„¢„Æ„»„¹¤ĪĘ«¤ź Availability Zone 1a ŲŗÉ„Ä©`„ė ENI(Public IP) ENI(Private IP) Availability Zone 1a ENI(Public IP) EIP(Private IP) ÄŚ²æ Availability Zone 1a Availability Zone 1a web01 web02 web01 web02 Per-AZ Per-AZ Per-LB ENI(Public IP) EIP(Private IP) ”. auto ”. auto ENI(Public IP) EIP(Private IP) ? TTL„„ć„Ć„·„å -> „Ƅ鄤„¢„ó„ČȤĪ ŌO¶Ø¤Ē»Ų±Ü
- 64. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~±³¾°~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
- 65. „¤„ó„Õ„é„Į„å©`„Ė„ó„°(¼¤¤¤Č¤³¤ķ¤Ļ»ł±¾¤Ź¤·) ? kernelȤĪsyn queue¤äTCP„Į„å©`„Ė„ó„°¤· ¤ĘTCP„³„Ķ„Æ„·„ē„ó¤ņ±£³Ö/×īßm»Æ¤¹¤ė ? ±£³Ö¤·¤æsyn queue¤ņŌē¤Æ¤µ¤Š¤±¤ė¤č¤¦¤Ė„ß „É„ė„¦„§„¢Č¤Īø÷·N„ļ©`„«©`„¹„ģ„Ć„É/¹²ÓŠ „į„ā„źµČ„Į„å©`„Ė„ó„°¤·¤Ę”¢IĄķŠŌÄܤņÉĻ¤² ¤ė ØC MaxRequestWorkersµČ¤Ī„Ø„é©`¤ņĶ¬r¤Ė½āQ ? OSŁYŌ“(CPU/„į„ā„ź)¤¬×ć¤é¤Ź¤Æ¤Ź¤Ć¤æ¤é”¢ EC2×ŌĢå¤ņ„¹„±©`„ė„¢„Ƅפ¹¤ė
- 66. Ėū¤Ī¤ä¤Ć¤æ¤³¤Č ? OS 3“óŁYŌ“(CPU/IO/memory)¤ĻOS„Į„å©`„Ė „ó„° „Ƅ鄦„ɤĒ¤ä¤Ć¤Ę¤āĪ¢Ćī ØC Ėū¤Ī¤Č¤³¤ķ¤ĖĮ¦¤ņŹ¹¤Ŗ¤¦ ØC øī¤źĒŠ¤Ć¤Ę„¹„±©`„ė„¢„Ƅה¢„¢„Ć„× ? AWS¤Ļ„µ©`„Ó„¹„ģ„Ł„ė(EC2/RDS/S3”)¤Ē 10Gź¤Ą¤¬„ģ„¤„Ę„ó„·¤ĻøÄÉʤ·¤Ė¤Æ¤¤(PG¤Č ¤«¤Ļ³ż¤Æ) ØC MultiAZź¤·¤Ä¤Ä”¢„Ķ„Ć„Č„ļ©`„Æ„ģ„¤„Ę„ó„·øÄÉĘ ? enhanced network(SR-IOV)ź ? RPS/RFS/XFS
- 67. ½Y¹ū EC2 38ĢØ -> 19ĢØ ? ±į°Õ°Õ±Ź¤Ī„Ø„é©`¤Ź¤· ? Ķس£¤ĪHTTP„ģ„¤„Ę„ó„·ŹżMSEC -> Źż+MSEC¤Ž¤ĒDOWN
- 68. Ō¤¹¤³¤Č ? ELB¤ČŹżĶņRPS„¹„Ń„¤„ÆŲŗÉ„Ę„¹„Č ØC ~±³¾°~ ØC ~„¢©`„„Ę„Æ„Į„ć(Ųŗɤ«¤±¤é¤ģ¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉ„Ä©`„ė¤Ė¤Ä¤¤¤Ę~ ØC ~ŲŗÉh¾³(Ųŗɤ«¤±¤ėČ)¤Ė¤Ä¤¤¤Ę~ ØC ~„¹„Ń„¤„ÆŲŗÉ„Ę„¹„ČgŹ©~ ? „¤„ó„Õ„é„Į„å©`„Ė„ó„° ? ALBÉŁ¤·
- 69. ALB ? 8/12„ź„ź©`„¹ ? CÄÜ ØC L7„Š„é„ó„·„ó„° ØC HTTP/2„µ„Ż©`„Č ØC WebSocket„µ„Ż©`„Č ØC Ėū„Ń„Õ„©©`„Ž„ó„¹/„Ń„Õ„©©`„Ž„ó„¹ĻņÉĻ
- 70. ALB„Ń„Õ„©©`„Ž„ó„¹(„„ć„Ń„·„Ę„£) ? ELBĶ¬ AutoScalingŠĶ¤ĪLB ? Pre-warming¤¢¤ź ØC ×ŌĒ°Pre-warming ØC ÉźÕPre-warming
- 72. ½ńįį ? ALBŹŌ^ßM¤į¤ė ? g„Č„é„Õ„£„Ć„Æ¤ĒÉŁ¤·¤ŗ¤ÄÖŲ¤ß¤ņ¤Ä¤±¤Ę·ÖÉ¢ ¤·¤Ä¤ÄדB¤ņŅ¤ė ? ŲŗÉ»ł±PøÄĮ¼ ØC EMR¼ÆÓ»ł±P½yŗĻ»Æ ØC Č«×ŌÓjmeter„ź„½©`„¹·ÖÅä¤Č¤«½yŗĻ»Æ ØC „³„ó„Ę„Źź¤Ī„Ž„Ķ©`„ø„É„µ©`„Ó„¹(GKE¤¢¤æ¤ź) “„¤Ć¤Ę¤ß¤æ¤¤¤Ź
Editor's Notes
- #4: Į÷¤·
- #5: Į÷¤·
- #8: Į÷¤·
- #11: Į÷¤·
- #12: Į÷¤·
- #14: Į÷¤·
- #15: Į÷¤·
- #16: Į÷¤·
- #17: Į÷¤·
- #18: Į÷¤·
- #19: Į÷¤·
- #20: Į÷¤·
- #21: Į÷¤·
- #22: Į÷¤·
- #27: ¤³¤³¤Ž¤Ē 10·Ö
- #32: Į÷¤·
- #33: Į÷¤·
- #37: Į÷¤·
- #39: Į÷¤·
- #42: Į÷¤·
- #44: Į÷¤·
- #46: Į÷¤·
- #48: Į÷¤·
- #51: Į÷¤·
- #53: ¤³¤³¤Ž¤Ē 20·Ö
- #54: Į÷¤·
- #56: Į÷¤·
- #57: Į÷¤·
- #58: Į÷¤·
- #59: Į÷¤·
- #65: Į÷¤·
- #66: Į÷¤·
- #67: Į÷¤·
- #68: Į÷¤·