




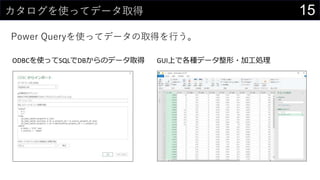
![14½ń¤¢¤ė„Ē©`„æ¤ņ„«„æ„ķ„°»Æ¤¹¤ė
„Ē©`„æ¤ĪĒéó¤ņ„ź„¹„Č»Æ¤·”¢HYPERLINKévŹż¤ņŹ¹¤Ć¤Ę¼~¤Å¤±¤ė”£
HYPERLINK(”°https://dev.classmethod.jp/”±, ”°Developers.IO”±)
HYPERLINK(”°Z:analysisdata”±, ”°„Ē©`„æ„Õ„©„ė„Ą”±)
HYPERLINK(”°[iris.xlsx]iris!A1”±, ”°¾±°ł¾±²õ„Ē©`„æ„»„Ć„Č”±)](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-14-320.jpg)

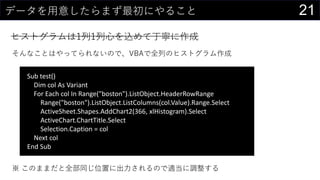
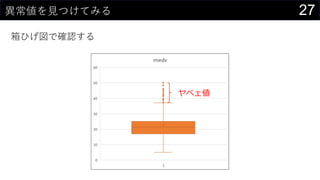
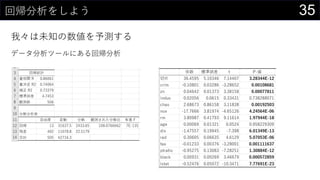
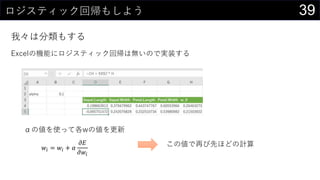
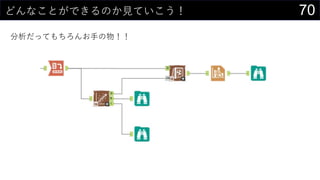
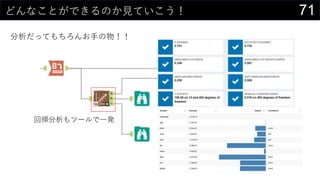
![23„«©`„Ķ„ėĆܶČĶĘ¶Ø¤ā¤·¤Ę¤ß¤č¤¦
„«©`„Ķ„ėévŹż¤Ė¤Ö¤Ć¤³¤ó¤Ē¤¢¤ėÖÜŽx¤Ī“_ĀŹ¤ņĒó¤į¤ė
Č”¤ź¤¦¤ėx¤Ī¹ ģ¤ņ„Ē©`„椫¤éQ¤į¤ė
? ×ī“ó : MAX(boston[medv])
? ×īŠ” : MIN(boston[medv])
? „Ē©`„漞Źż : COUNT(boston[medv])
? ¤Ä¤¤¤Ē¤Ė„Ń„é„į©`„æh¤ā„»„ė¤ĖČė¤ģ¤Ę¤Ŗ¤Æ
¾¼Æ > „Õ„£„ė > ßB¾A„Ē©`„æ¤Ī×÷³É ¤Ēmin/max¤ņ²ĪÕÕ¤Ėx¤Ī¤ņÉś³É¤¹¤ė
? ½ń»Ų¤Ļ0”«60¤Ž¤Ē¤ņ0.1æĢ¤ß¤ĒÉś³É](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-23-320.jpg)


![28®³£¤ņŅ¤Ä¤±¤Ę¤ß¤ė
z¤ņÓĖć¤¹¤ė
? ? = (? ? ?) ?
? Ę½¾ł¤ņÓĖć
? Q2„»„ė : AVERAGE(boston[medv])
? ĖŹĘ«²ī¤ņÓĖć
? Q3„»„ė : STDEV.S(boston[medv])
? ø÷¤Īz¤ņÓĖć¤¹¤ė
? ([@medv] - $Q$2) / $Q$3
? ¤Ž¤Č¤į¤ĘÓĖ椷¤Į¤ć¤¦¤³¤Č¤āæÉÄÜ
? ([@medv] - AVERAGE([medv])) / STDEV.S([medv])
„Ę©`„Ö„ė¤ĪĮŠĆū¤Ē¹ ģ¤ņÖø¶Ø
¤³¤ĪĮŠ¤Ė×·¼Ó](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-28-320.jpg)
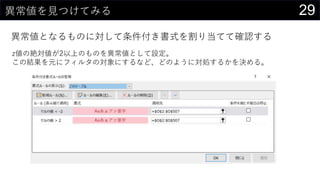


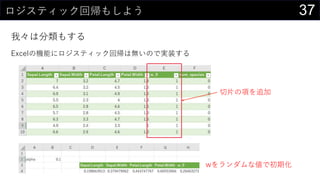

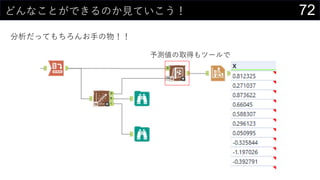
![41„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤ā¤·¤č¤¦
ĪŅ”©¤Ļ·Öī¤ā¤¹¤ė
g×°¤Ē¤¤æ„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤ĒĶĘÕ¤¹¤ė
? {=1 / (1 + EXP(-MMULT(iris[@[Sepal.Length]:[w_0]], TRANSPOSE(Sheet1!$D$300:$H$300))))}
? =IF([@predict] > 0.5, 1, 0)](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-41-320.jpg)

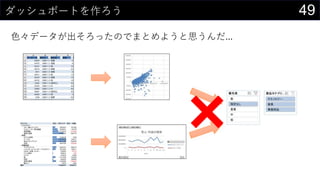
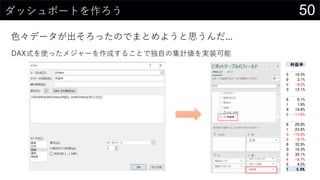
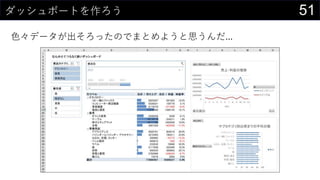









Č«²æ·”³ę³¦±š±ō¤Ē¤ä¤ķ¤¦¤Č¤·¤Ęŗ󻌤¹¤ė„Ē©`„æ·ÖĪö
- 2. 2¤ŖĒ°Õl¤č£æ ¤ø¤ē¤ó¤¹¤ß¤¹ „Ƅ鄹„į„½„Ć„É „Ē©`„æ„¢„Ź„ź„Ę„£„Æ„¹ŹĀI±¾²æ„¤„ó„Ę„°„ģ©`„·„ē„ó²æ MLĶĘßM„Į©`„ą „ź©`„Ą©` ĘÕ¶Ī¤Ī¤ŖŹĖŹĀ ? CŠµŃ§Į, SageMaker¤Ŗ¤ø¤µ¤ó ? Hadoop, EMR¤Ŗ¤ø¤µ¤ó ? Alteryx ACE¤ĪČĖ ? „Æ„½Excel¤Ė„ā„ó„ÆŃŌ¤¦¤Ŗ¤ø¤µ¤ó
- 4. 4¤Ŗī}Äæ ? ¤Ź¤¼Excel¤ĻĶņÄܤĒČĖ”©¤ĖŪ¤µ¤ģ¤ė¤Ī¤«£æ ? „Ē©`„æ·ÖĪö¤Ī¤æ¤į¤ĪExcel»īÓĆ ? Alteryx ”«Excel¤Ī¤½¤ĪĻȤŲ”«
- 5. 5¤Ŗī}Äæ ? ¤Ź¤¼Excel¤ĻĶņÄܤĒČĖ”©¤ĖŪ¤µ¤ģ¤ė¤Ī¤«£æ ? „Ē©`„æ·ÖĪö¤Ī¤æ¤į¤ĪExcel»īÓĆ ? Alteryx ”«Excel¤Ī¤½¤ĪĻȤŲ”«
- 6. 6¤Ź¤¼Excel¤ĻĶņÄܤĒČĖ”©¤ĖŪ¤µ¤ģ¤Ę¤¤¤ė¤Ī¤«£æ ŹĄ½ē¤Ē×ī¤ā¶ą¤ÆŹ¹¤ļ¤ģ¤Ę¤¤¤ė„½„Õ„Č„¦„§„¢¤Ī1¤Ä”¢¤½¤ģ¤¬Excel¤ČŃŌ¤Ć¤Ę¤ā ß^ŃŌ¤Ē¤Ļ¤Ź¤¤¤Ē¤·¤ē¤¦”£ ? Õl¤Ē¤āŗ g¤Ė”ø¤Č¤ź¤¢¤Ø¤ŗŹ¹¤Ć¤Ę¤ß¤ė”¹¤¬æÉÄÜ ? ×ŌÓɤ¹¤®¤ė„»„ė¤ČRµ¹µÄ¶ąCÄܤĖ¤č¤źøī¤ČŗĪ¤Ē¤āg¬F ? ×ŌÓɤĖŹ¹¤Ø¤¹¤®¤ė¤Ī¤ĒĖū¤ĪČĖ¤ĪExcel¤ĻŗĪ¤·¤Ę¤ė¤«¤ļ¤«¤é¤ó ? ”øÕż¤·¤¤Excel¤ĪŹ¹¤¤·½”¹¤Ź¤ó¤ĘøÅÄī¤¹¤é¤ā... ? Õl¤Ē¤ā„Õ„ź©`„Ą„ą¤ĖŹ¹¤Ø¤ė¤Ī¤Ē„Ø„ó„ø„Ė„¢¤Ė¤Č¤Ć¤Ę¼É¤ßĻÓ¤ļ¤ģ¤ė“ęŌŚ ? ×ŌӻƤäæĀŹ»Æ¤Ī·Į¤²µÄ“ęŌŚ¤Č¤·¤ĘQ¤ļ¤ģ¤ė ? ¤ā¤Ć¤ČßmĒŠ¤Ź„Ä©`„ė¤¬¤¢¤ė¤Ē¤·¤ē...¤ČŃŌ¤ļ¤ģ¤ė
- 9. 9„Ē©`„æ·ÖĪö¤ĪĮ÷¤ģ¤Ē漤ؤė±ŲŅŖ¤ŹŅŖĖŲ „Ē©`„æ¤ĪČ”µĆ ·ÖĪö „ģ„Ż©`„Ę„£„ó„° „Ę©`„Ö„ė„Ē©`„æ ŅŌĻĀ¤ĪÄŚČŻ¤ņĆ÷“_»Æ ? Č”µĆŌŖ ? „Õ„©©`„Ž„Ć„Č ? ŗ¬¤Ž¤ģ¤ėĒéó ¶ØĘŚµÄ¤ŹČ”µĆ?øüŠĀ¤ĪŹÓ ·ÖĪöÄŚČŻ¤ĖŗĻ¤ļ¤»¤æ¼Ó¹¤ ·ÖĪöIĄķ¤ĪgŹ© éTÖŖ×R¤¬±ŲŅŖ ŅāĖ¼Q¶Ø¤Ē»īÓĆæÉÄܤŹŠĪŹ½ ¤Ę±¤ä„Ą„Ć„·„å„Ü©`„É×÷³É ¤³¤Ī²æ·Ö¤Ē„ģ„¤„¢„¦„Ȥä Ó”Ė¢ŠĪŹ½¤ņÕū¤Ø¤ė
- 10. 10¤Ŗī}Äæ ? ¤Ź¤¼Excel¤ĻĶņÄܤĒČĖ”©¤ĖŪ¤µ¤ģ¤ė¤Ī¤«£æ ? „Ē©`„æ·ÖĪö¤Ī¤æ¤į¤ĪExcel»īÓĆ ? Alteryx ”«Excel¤Ī¤½¤ĪĻȤŲ”«
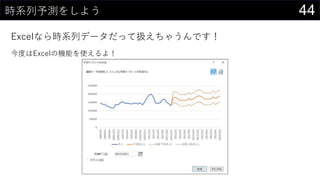
- 14. 14½ń¤¢¤ė„Ē©`„æ¤ņ„«„æ„ķ„°»Æ¤¹¤ė „Ē©`„æ¤ĪĒéó¤ņ„ź„¹„Č»Æ¤·”¢HYPERLINKévŹż¤ņŹ¹¤Ć¤Ę¼~¤Å¤±¤ė”£ HYPERLINK(”°https://dev.classmethod.jp/”±, ”°Developers.IO”±) HYPERLINK(”°Z:analysisdata”±, ”°„Ē©`„æ„Õ„©„ė„Ą”±) HYPERLINK(”°[iris.xlsx]iris!A1”±, ”°¾±°ł¾±²õ„Ē©`„æ„»„Ć„Č”±)
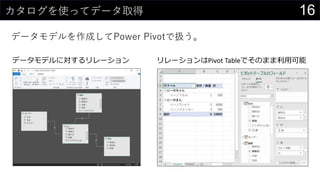
- 16. 16„«„æ„ķ„°¤ņŹ¹¤Ć¤Ę„Ē©`„æČ”µĆ „Ē©`„æ„ā„Ē„ė¤ņ×÷³É¤·¤ĘPower Pivot¤ĒQ¤¦”£ „Ē©`„æ„ā„Ē„ė¤Ė¤¹¤ė„ź„ģ©`„·„ē„ó „ź„ģ©`„·„ē„ó¤ĻPivot °Õ²¹²ś±ō±š¤Ē¤½¤Ī¤Ž¤ŽĄūÓĆæÉÄÜ
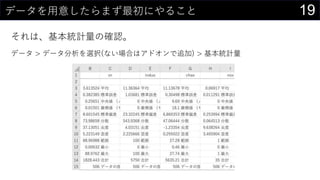
- 19. 19„Ē©`„æ¤ņÓĆŅā¤·¤æ¤é¤Ž¤ŗ×ī³õ¤Ė¤ä¤ė¤³¤Č ¤½¤ģ¤Ļ”¢»ł±¾½yÓĮæ¤Ī“_ÕJ”£ „Ē©`„æ > „Ē©`„æ·ÖĪö¤ņßxk(¤Ź¤¤öŗĻ¤Ļ„¢„É„Ŗ„ó¤Ē×·¼Ó) > »ł±¾½yÓĮæ
- 21. 21„Ē©`„æ¤ņÓĆŅā¤·¤æ¤é¤Ž¤ŗ×ī³õ¤Ė¤ä¤ė¤³¤Č „Ņ„¹„Č„°„é„ą¤Ļ1ĮŠ1ĮŠŠÄ¤ņŽz¤į¤Ę¶”¤Ė×÷³É ¤½¤ó¤Ź¤³¤Č¤Ļ¤ä¤Ć¤Ę¤é¤ģ¤Ź¤¤¤Ī¤Ē”¢VBA¤ĒČ«ĮŠ¤Ī„Ņ„¹„Č„°„é„ą×÷³É Sub test() Dim col As Variant For Each col In Range("boston").ListObject.HeaderRowRange Range("boston").ListObject.ListColumns(col.Value).Range.Select ActiveSheet.Shapes.AddChart2(366, xlHistogram).Select ActiveChart.ChartTitle.Select Selection.Caption = col Next col End Sub ”ł ¤³¤Ī¤Ž¤Ž¤Ą¤ČČ«²æĶ¬¤øĪ»ÖƤĖ³öĮ¦¤µ¤ģ¤ė¤Ī¤Ēßmµ±¤ĖÕ{Õū¤¹¤ė
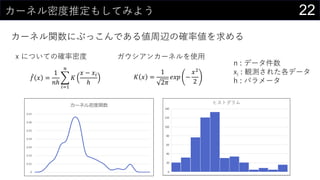
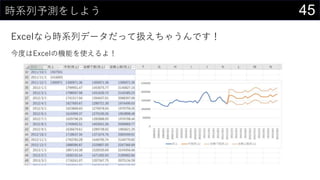
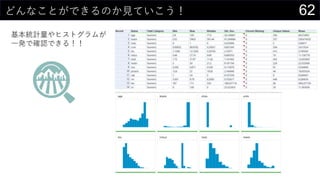
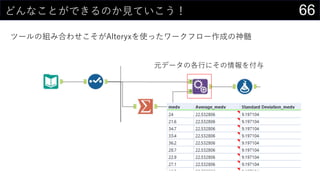
- 22. 22„«©`„Ķ„ėĆܶČĶĘ¶Ø¤ā¤·¤Ę¤ß¤č¤¦ „«©`„Ķ„ėévŹż¤Ė¤Ö¤Ć¤³¤ó¤Ē¤¢¤ėÖÜŽx¤Ī“_ĀŹ¤ņĒó¤į¤ė ? ? = 1 ?? ?=1 ? ? ? ? ?? ? ? ? = 1 2? ??? ? ?2 2 x ¤Ė¤Ä¤¤¤Ę¤Ī“_ĀŹĆÜ¶Č „¬„¦„·„¢„ó„«©`„Ķ„ė¤ņŹ¹ÓĆ n : „Ē©`„漞Źż xi : ÓQy¤µ¤ģ¤æø÷„Ē©`„æ h : „Ń„é„į©`„æ 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 „«©`„Ķ„ėĆܶČévŹż
- 23. 23„«©`„Ķ„ėĆܶČĶĘ¶Ø¤ā¤·¤Ę¤ß¤č¤¦ „«©`„Ķ„ėévŹż¤Ė¤Ö¤Ć¤³¤ó¤Ē¤¢¤ėÖÜŽx¤Ī“_ĀŹ¤ņĒó¤į¤ė Č”¤ź¤¦¤ėx¤Ī¹ ģ¤ņ„Ē©`„椫¤éQ¤į¤ė ? ×ī“ó : MAX(boston[medv]) ? ×īŠ” : MIN(boston[medv]) ? „Ē©`„漞Źż : COUNT(boston[medv]) ? ¤Ä¤¤¤Ē¤Ė„Ń„é„į©`„æh¤ā„»„ė¤ĖČė¤ģ¤Ę¤Ŗ¤Æ ¾¼Æ > „Õ„£„ė > ßB¾A„Ē©`„æ¤Ī×÷³É ¤Ēmin/max¤ņ²ĪÕÕ¤Ėx¤Ī¤ņÉś³É¤¹¤ė ? ½ń»Ų¤Ļ0”«60¤Ž¤Ē¤ņ0.1æĢ¤ß¤ĒÉś³É
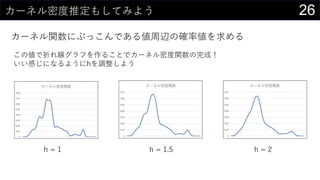
- 24. 24„«©`„Ķ„ėĆܶČĶĘ¶Ø¤ā¤·¤Ę¤ß¤č¤¦ „«©`„Ķ„ėévŹż¤Ė¤Ö¤Ć¤³¤ó¤Ē¤¢¤ėÖÜŽx¤Ī“_ĀŹ¤ņĒó¤į¤ė „«©`„Ķ„ėévŹż¤ĪÖŠÉķ¤ņÓĖć 1 / SQRT(2 * PI()) * EXP(-POWER((D$2 - Sheet2!$N2) / $B$6, 2) / 2) 1 2? ? ?2 2 xi¤ĪŹż¤Ą¤±¤³¤Ī¤ņÓĖć¤¹¤ė ×ī³õ¤ĖÉś³É¤·¤æx¤Ī¤Č¤Ź¤ėĮŠ·½Ļņ¤āĶ¬ ”ł „Ŗ©`„Č„Õ„£„ė¤¹¤ė¤Ą¤±
- 25. 25„«©`„Ķ„ėĆܶČĶĘ¶Ø¤ā¤·¤Ę¤ß¤č¤¦ „«©`„Ķ„ėévŹż¤Ė¤Ö¤Ć¤³¤ó¤Ē¤¢¤ėÖÜŽx¤Ī“_ĀŹ¤ņĒó¤į¤ė “_ĀŹĆܶȤņÓĖć¤¹¤ė SUM(D3:D508) / ($B$5 * $B$6) ¤Ŗ¤Ž¤± : ÅäĮŠŹżŹ½¤ņŹ¹¤Ø¤ŠŅ»°k¤ĒÓĖć¤¹¤ė¤³¤Č¤āæÉÄÜ ?=1 ? ? ? ? ?? ? 1 ??
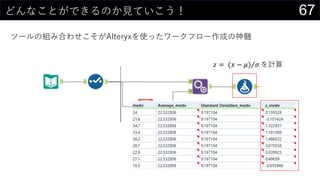
- 28. 28®³£¤ņŅ¤Ä¤±¤Ę¤ß¤ė z¤ņÓĖć¤¹¤ė ? ? = (? ? ?) ? ? Ę½¾ł¤ņÓĖć ? Q2„»„ė : AVERAGE(boston[medv]) ? ĖŹĘ«²ī¤ņÓĖć ? Q3„»„ė : STDEV.S(boston[medv]) ? ø÷¤Īz¤ņÓĖć¤¹¤ė ? ([@medv] - $Q$2) / $Q$3 ? ¤Ž¤Č¤į¤ĘÓĖ椷¤Į¤ć¤¦¤³¤Č¤āæÉÄÜ ? ([@medv] - AVERAGE([medv])) / STDEV.S([medv]) „Ę©`„Ö„ė¤ĪĮŠĆū¤Ē¹ ģ¤ņÖø¶Ø ¤³¤ĪĮŠ¤Ė×·¼Ó
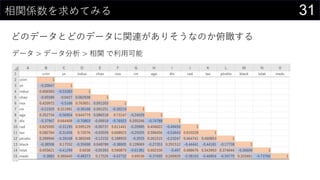
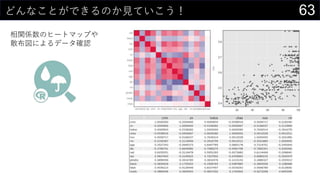
- 30. 30ĻąévSŹż¤ņĒó¤į¤Ę¤ß¤ė ¤É¤Ī„Ē©`„æ¤Č¤É¤Ī„Ē©`„æ¤ĖévßB¤¬¤¢¤ź¤½¤¦¤Ź¤Ī¤«ø©ī«¤¹¤ė ? = 1 ? ?=1 ? (?? ? ?)(?? ? ?) 1 ? ?=1 ? (?? ? ?)2 1 ? ?=1 ? (?? ? ?)2 ? ĻąévSŹż¤Ļ2¤Ä¤ĪĮŠ„Ē©`„æ¤Ė¤ĪévßBŠŌ¤ņŹż¤Ē±ķ¤¹ ? ¤¬1¤Ė½ü¤¤¤Ū¤ÉÕż¤ĪĻąév(ʬ·½¤¬øߤƤŹ¤ģ¤Š¤ā¤¦Ę¬·½¤āøߤƤŹ¤ė)¤¬¤¢¤ė ? ¤¬-1¤Ė½ü¤¤¤Ū¤ÉŲ¤ĪĻąév(ʬ·½¤¬øߤƤŹ¤ģ¤Š¤ā¤¦Ę¬·½¤ĻµĶ¤Æ¤Ź¤ė)¤¬¤¢¤ė ? ¤¬0¤Ė½ü¤±¤ģ¤ŠĻąév¤Ź¤· ? ĮŠ¤Ī½M¤ßŗĻ¤ļ¤»·Ö¤Ą¤±ĻąévSŹż¤¬ÓĖć¤Ē¤¤ė¤Ī¤ĒŠŠĮŠ¤Ē±ķ¤»¤ė ĻąévSŹż¤ĪĒó¤į·½
- 31. 31ĻąévSŹż¤ņĒó¤į¤Ę¤ß¤ė ¤É¤Ī„Ē©`„æ¤Č¤É¤Ī„Ē©`„æ¤ĖévßB¤¬¤¢¤ź¤½¤¦¤Ź¤Ī¤«ø©ī«¤¹¤ė „Ē©`„æ > „Ē©`„æ·ÖĪö > Ļąév ¤ĒĄūÓĆæÉÄÜ
- 32. 32ĻąévSŹż¤ņĒó¤į¤Ę¤ß¤ė e½ā : īB¤Ć¤ĘÓĖć¤¹¤ė ø÷„Ē©`„æ¤Īz¤ņÓĖć ŠŠĮŠ»ż¤ņ¼ĘĖ椷¤Ę„Ē©`„漞Źż-1¤Ēøī¤ė
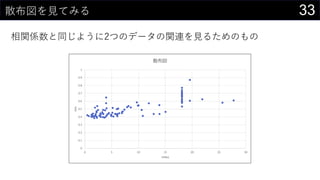
- 33. 33É¢²¼ķ¤ņŅ¤Ę¤ß¤ė ĻąévSŹż¤ČĶ¬¤ø¤č¤¦¤Ė2¤Ä¤Ī„Ē©`„æ¤ĪévßB¤ņŅ¤ė¤æ¤į¤Ī¤ā¤Ī 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 5 10 15 20 25 30 nox indus É¢²¼ķ
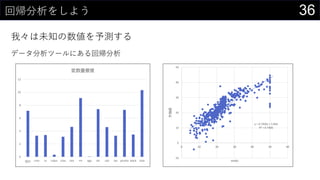
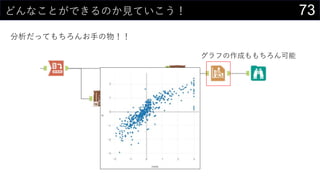
- 36. 36»Ų¢·ÖĪö¤ņ¤·¤č¤¦ ĪŅ”©¤ĻĪ“ÖŖ¤ĪŹż¤ņÓčy¤¹¤ė „Ē©`„æ·ÖĪö„Ä©`„ė¤Ė¤¢¤ė»Ų¢·ÖĪö 0 2 4 6 8 10 12 ĒŠĘ¬ crim zn indus chas nox rm age dis rad tax ptratio black lstat 䏿ÖŲŅŖ¶Č y = 0.7406x + 5.844 R? = 0.7406 -10 0 10 20 30 40 50 0 10 20 30 40 50 60 Óčy medv
- 38. 38„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤ā¤·¤č¤¦ ĪŅ”©¤Ļ·Öī¤ā¤¹¤ė Excel¤ĪCÄܤĖ„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤Ļo¤¤¤Ī¤Ēg×°¤¹¤ė ø÷w¤ĒpŹ§évŹż¤ņĪ¢·Ö¤·¤æ½Y¹ū¤ņÓĖć ?? ?? ? = ? ? ? ? ? ?? ? ? = 1 1 + exp ? ? ? ? = ? ?=1 ? ?? ??? ?? + 1 ? ? ?? 1 ? ? ??
- 39. 39„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤ā¤·¤č¤¦ ĪŅ”©¤Ļ·Öī¤ā¤¹¤ė Excel¤ĪCÄܤĖ„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤Ļo¤¤¤Ī¤Ēg×°¤¹¤ė ¦Į¤Ī¤ņŹ¹¤Ć¤Ęø÷w¤Ī¤ņøüŠĀ ?? = ?? + ? ?? ??? ¤³¤Ī¤ĒŌŁ¤ÓĻȤŪ¤É¤ĪÓĖć
- 41. 41„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤ā¤·¤č¤¦ ĪŅ”©¤Ļ·Öī¤ā¤¹¤ė g×°¤Ē¤¤æ„ķ„ø„¹„Ę„£„Ć„Æ»Ų¢¤ĒĶĘÕ¤¹¤ė ? {=1 / (1 + EXP(-MMULT(iris[@[Sepal.Length]:[w_0]], TRANSPOSE(Sheet1!$D$300:$H$300))))} ? =IF([@predict] > 0.5, 1, 0)
- 44. 44rĻµĮŠÓčy¤ņ¤·¤č¤¦ Excel¤Ź¤érĻµĮŠ„Ē©`„æ¤Ą¤Ć¤ĘQ¤Ø¤Į¤ć¤¦¤ó¤Ē¤¹£” ½ń¶Č¤ĻExcel¤ĪCÄܤņŹ¹¤Ø¤ė¤č£”
- 45. 45rĻµĮŠÓčy¤ņ¤·¤č¤¦ Excel¤Ź¤érĻµĮŠ„Ē©`„æ¤Ą¤Ć¤ĘQ¤Ø¤Į¤ć¤¦¤ó¤Ē¤¹£” ½ń¶Č¤ĻExcel¤ĪCÄܤņŹ¹¤Ø¤ė¤č£”
- 52. 52Excel¾¤Ž¤Č¤į(?) Excel¤ņ»īÓƤ·¤æ„Ē©`„æ·ÖĪö¤Ė¤Ŗ¤¤¤Ę¤³¤Īµć¤Ė×¢Ņā¤·¤Ę¤Ŗ¤³¤¦”£ ? „Ē©`„愽©`„¹¤Č»īÓĆ?³öĮ¦¤ĻĆ÷“_¤Ė·Ö¤±¤ė ? „Ē©`„æ„ā„Ē„ė¤ņ„Ł©`„¹¤Ė¤¹¤ė¤³¤Č¤Ēäøü¤¬¤¢¤Ć¤ær¤ĖøüŠĀ¤¬æÉÄÜ ? Power Query¤ĒŠŠ¤Ć¤æ„Ē©`„æ¾¼Æ?¼Ó¹¤¤Ļ„ׄķ„»„¹¤¬“_ÕJæÉÄÜ ? „»„ė¤Ī¹ ģ¤Ē¤Ļ¤Ź¤Æ„Ę©`„Ö„ė¤ĪĮŠĆū¤ĒÖø¶Ø¤¹¤ė¤³¤Č¤ĒøüŠĀr¤Ė¤āźæÉÄÜ
- 54. 54¤Ŗī}Äæ ? ¤Ź¤¼Excel¤ĻĶņÄܤĒČĖ”©¤ĖŪ¤µ¤ģ¤ė¤Ī¤«£æ ? „Ē©`„æ·ÖĪö¤Ī¤æ¤į¤ĪExcel»īÓĆ ? Alteryx ”«Excel¤Ī¤½¤ĪĻȤŲ”«
- 55. 55×ī½üŗĪ¤«¤ČŌī}¤Ī„ļ©`„É”øĶŃExcel”¹ ”¾„ģ„Ż©`„Č”æŠĀÕJ¶ØŁYøńµĒö£”Alteryx¤ņ¤ā¤Ć¤Čѧ¤ÖTipsŗŻd¤Ī„©`„Ī©`„Č: GET AMPLIFIED ØC Alteryx Inspire 2019
- 56. 56¤Ź¤¼½ń”øĶŃExcel”¹¤Ź¤Ī¤«£æ Excel¤Ć¤Ę¤Ź¤ó¤Ē¤ā¤Ē¤¤ė¤ø¤ć¤ó£” ? ”ø¤Ź¤ó¤Ē¤ā¤Ē¤¤ė”¹¤Č”ø¤Ź¤ó¤Ē¤ā¤ä¤ė¤Ł¤”¹¤Ļ®¤Ź¤ė ? ¤Ē¤¤Ļ¤¹¤ė¤±¤É¤¢¤Ž¤źæĀŹµÄ¤Č¤ĻŃŌ¤Ø¤Ź¤¤¤³¤Č¤ā¤¢¤ė ? ¤č¤źÉī¤Æ”¢¤č¤źéTµÄ¤Ź¤³¤Č¤ņŗ g¤Ė¤Č¤Ź¤ė¤Č¤½¤ĪCÄܤ¬ÓĆŅā¤µ¤ģ¤Ę¤ė¤Č¤¤¤¤ ? Excel¤Ē¤ĪIĄķÄŚČŻ¤Ļ¤¢¤Č¤«¤é„ׄķ„»„¹¤ņ“_ÕJ¤¹¤ė¤Ī¤¬Ą§ėy ? ŗĪ¤ņ¤É¤¦¤¤¤¦ŹÖķ¤Ē¤ä¤Ć¤Ę¤ė¤Ī¤«„É„„å„į„ó„Ȥ¬±ŲŅŖ£æ ? „ė©`„ė¤Ēæ`¤Ć¤æ¤Č¤·¤Ę”¢¤½¤ģ¤ņ“_g¤ĖÖʤ¹¤ė¤³¤Č¤Ļėy¤·¤¤ ? ÓƤĪ„·„¹„Ę„ą¤ņ”ø×÷¤Ć¤Ę¤ā¤é¤¦”¹¤Ē¤Ļ¤Ź¤Æ”ø×Ō·Ö¤æ¤Į¤Ē¤ä¤ė”¹¤ā¤½¤Ī¤Ž¤Ž¤Ė£” ? ”ø„¬„Ć„Ä„ź¤³¤ģ¤Ą¤±£””¹¤ņg¬F¤·¤æ¤ļ¤±¤ø¤ć¤Ź¤¤ ? ¤É¤¦¤·¤Ę¤ā„µ„¤„Æ„ė¤¬éL¤Æ¤Ź¤ė
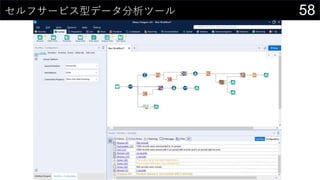
- 61. 61„»„ė„Õ„µ©`„Ó„¹ŠĶ„Ē©`„æ·ÖĪö„Ä©`„ė ? „Ę„„¹„Č„Õ„”„¤„ė¤äø÷·NDB¤Ļ¤ā¤Į¤ķ¤ó”¢ Ėū¤Ė¤ā”©¤Ź„Ē©`„愽©`„¹¤Ėź ? Excel¤ņČėĮ¦¤Č¤·¤ĘDB¤Ė³öĮ¦¤¹¤ė¤Ź¤É ETLIĄķ¤Ė¤āź ? In-DB¤ņŹ¹¤¦¤³¤Č¤ĒÖŲ¤¤IĄķ¤ņDBȤĒ gŠŠ¤µ¤»¤ė¤³¤Č¤āæÉÄÜ
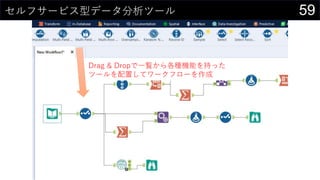
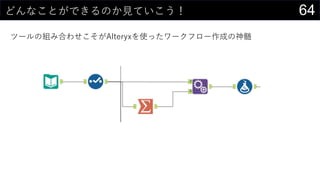
- 64. 64¤É¤ó¤Ź¤³¤Č¤¬¤Ē¤¤ė¤Ī¤«Ņ¤Ę¤¤¤³¤¦£” „Ä©`„ė¤Ī½M¤ßŗĻ¤ļ¤»¤³¤½¤¬Alteryx¤ņŹ¹¤Ć¤æ„ļ©`„Æ„Õ„ķ©`×÷³É¤ĪÉńól
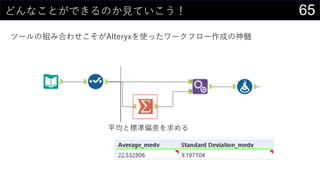
- 67. 67¤É¤ó¤Ź¤³¤Č¤¬¤Ē¤¤ė¤Ī¤«Ņ¤Ę¤¤¤³¤¦£” „Ä©`„ė¤Ī½M¤ßŗĻ¤ļ¤»¤³¤½¤¬Alteryx¤ņŹ¹¤Ć¤æ„ļ©`„Æ„Õ„ķ©`×÷³É¤ĪÉńól ? = (? ? ?) ? ¤ņÓĖć
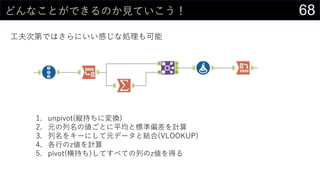
- 68. 68¤É¤ó¤Ź¤³¤Č¤¬¤Ē¤¤ė¤Ī¤«Ņ¤Ę¤¤¤³¤¦£” ¹¤·ņ“ĪµŚ¤Ē¤Ļ¤µ¤é¤Ė¤¤¤¤øŠ¤ø¤ŹIĄķ¤āæÉÄÜ 1. unpivot(æk³Ö¤Į¤ĖäQ) 2. ŌŖ¤ĪĮŠĆū¤Ī¤“¤Č¤ĖĘ½¾ł¤ČĖŹĘ«²ī¤ņÓĖć 3. ĮŠĆū¤ņ„©`¤Ė¤·¤ĘŌŖ„Ē©`„æ¤Č½YŗĻ(VLOOKUP) 4. ø÷ŠŠ¤Īz¤ņÓĖć 5. pivot(ŗį³Ö¤Į)¤·¤Ę¤¹¤Ł¤Ę¤ĪĮŠ¤Īz¤ņµĆ¤ė
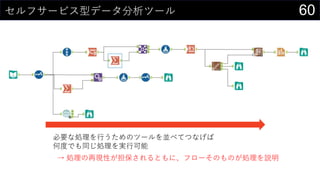
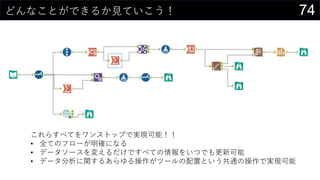
- 74. 74¤É¤ó¤Ź¤³¤Č¤¬¤Ē¤¤ė¤«Ņ¤Ę¤¤¤³¤¦£” ¤³¤ģ¤é¤¹¤Ł¤Ę¤ņ„ļ„ó„¹„Č„Ć„×¤Ēg¬FæÉÄÜ£”£” ? Č«¤Ę¤Ī„Õ„ķ©`¤¬Ć÷“_¤Ė¤Ź¤ė ? „Ē©`„愽©`„¹¤ņä¤Ø¤ė¤Ą¤±¤Ē¤¹¤Ł¤Ę¤ĪĒéó¤ņ¤¤¤Ä¤Ē¤āøüŠĀæÉÄÜ ? „Ē©`„æ·ÖĪö¤Ėév¤¹¤ė¤¢¤é¤ę¤ė²Ł×÷¤¬„Ä©`„ė¤ĪÅäÖƤȤ¤¤¦¹²ĶؤĪ²Ł×÷¤ĒgĻÖæÉÄÜ
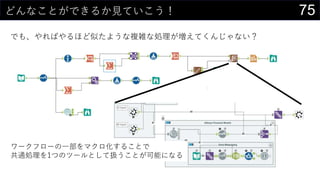
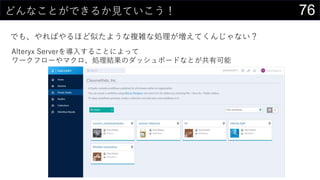
- 79. 79¤Ž¤Č¤įµÄ¤ŹŗĪ¤« „Ē©`„æ·ÖĪö¤ČExcel¤ČAlteryx¤ĪS¤·¤¤¤ŖŌ ? „Ē©`„æ¤ņŠī¤Ø¤ė»ł±P¤Č·ÖĪöh¾³¤ČŅ¤»·½¤Ļ·Ö¤±¤Ęæ¼¤Ø¤č¤¦ ? ßmĒŠ¤Ė·Öøī¤·¤ĘÆE½YŗĻ¤Ė¤¹¤ė¤³¤Č¤ĒŌŁĄūÓƤ¬ČŻŅפĖ¤Ź¤ė ? „Ē©`„æ¤Ļ¤¤Į¤ó¤Č„«„æ„ķ„°¤Ē¹ÜĄķ¤¹¤ė¤ČĮ¼¤µ¤² ? Excel¤Ļ¤ä¤ķ¤¦¤ČĖ¼¤Ø¤ŠŗĪ¤Ē¤ā¤Ē¤¤Ę¤·¤Ž¤¦¤¬¤ä¤ė¤Ł¤¤«¤Ļ¤Ž¤æe¤ŹŌ ? „Ü„æ„ó1¤Ä¤Ēŗ g¤Ėg¬F¤Ē¤¤ėCÄܤ«¤éīB¤Ć¤Ęg¬F¤¹¤ė¤ā¤Ī¤Ž¤Ē”© ? Ń}ėj¤Ź¤³¤Č¤Ļ×÷¤Ć¤Ę¤ė×īÖŠ¤Ē¤āŗĪ¤·¤Ę¤ė¤Ī¤«¤ļ¤«¤é¤ó¤Æ¤Ź¤ė¤³¤Č¤ā¤·¤Š¤·... ? Alteryx¤Ć¤Ę¤¹¤²¤§£”£” ? „Ē©`„æ·ÖĪö¤ĖévßB¤¹¤ė”©¤ŹIĄķ¤ņ„ļ„ó„¹„Č„Ć„×¤Ēg¬F ? IĄķÄŚČŻ¤ĪĆ÷“_»Æ¤ä¹²ÓŠ¤āæÉÄÜ
- 80. 80²Īæ¼ŁYĮĻ ? Excel„Ń„ļ©`„Ō„Ü„Ć„Č ? ×īĖŁ¤Ē §Ņę¤Ė¤Ä¤Ź¤²¤ėĶźČ«×ŌÓ¤Ī„Ē©`„æ·ÖĪö ? Excel¤Ēѧ¤Ö„Ē©`„æ·ÖĪö±¾øńČėéT ? „ׄķ„³„󄵄ė„æ„ó„ȤĪ×ī„Ø„Æ„»„ėŠg ? 2017 Planning Guide for Data and Analytics ? HYPERLINKévŹż¤Ē„Ļ„¤„Ń©`„ź„ó„Ƥņ×÷³É¤¹¤ė ? Ö÷³É·Ö·ÖĪö¤ņExcel¤ĒĄķ½ā¤¹¤ė
- 81. 81
Editor's Notes
- #8: ¤ß¤ó¤Ź“óĻÓ¤¤¤Ź¤ä¤Ä Excel·½ŃŪ¼?Éń„Ø„Æ„»„ė S¤·¤¤„»„ė¤Ī½YŗĻ ķ¤ņ¤Õ¤ó¤Ą¤ó¤ĖŹ¹¤Ć¤æ¤Ŗ½}Ćč¤ ĻÓ¤ļ¤ģ¤ėExcel¤ĪŹ¹¤¤·½¤Ļ±¾µ±¤Ė¤Ź¤Ī¤«£æ ¤½¤ā¤½¤ā¤Ź¤¼±Ė¤é¤¬ĻÓ¤ļ¤ģ¤ė¤Ī¤«æ¼¤Ø¤Ę¤ß¤č¤¦”£ Excel¤ĻŌŖ”©”±±ķÓĖć„½„Õ„Č”±¤Ē¤¢¤ė ”ø¤³¤ó¤ŹŹ¹¤¤·½¤ĻĻÓ¤ļ¤ģ¤ė”¹¤ĪÖ÷¤ŹŌŅņ¤Ļ æĀŹµÄ¤ŹŹ¹¤¤·½¤Ī·Į¤²¤Ė¤Ź¤Ć¤Ę¤¤¤ė „Ē©`„æ¤Č¤·¤ĘŌŁĄūÓƤĒ¤¤Ź¤¤ŠĪŹ½¤Ė¤Ź¤Ć¤Ę¤ė ŹĖ÷ŠŌ¤¬Öų¤·¤Æ¤¤ ĻÓ¤ļ¤ģ¤ėŹ¹¤¤·½¤¬ĀūŃÓ¤ėŌŅņ¤Ļ¤¤¤Ć¤æ¤¤¤É¤³¤Ė¤¢¤ė¤Ī¤« Ó”Ė¢¤¬Ē°Ģį¤Ź¤É”¢¤É¤Ī¤č¤¦¤Ė„ģ„¤„¢„¦„Ȥ¹¤ė¤«¤Ī¤ß¤ņŻ¤Ė¤¹¤ė ¤č¤Æ¤ļ¤«¤Ć¤Ę¤Ź¤¤¤±¤É„°„°¤Ć¤Ę³ö¤Ę¤¤æ¤ä¤ź·½¤ņ„³„Ō„Ś
- #10: „¤„ó„æ©`„Ķ„ƄȤĪsŹ·¤Ė²Š¤ė„ք鄦„¶éÕłHTML/CSS¤Ī·Öėx ¤¢¤Īķ¤Ī„Ū©`„ą„Ś©`„ø×÷³É¤ĒĘš¤³¤Ć¤Ę¤¤¤æ³öĄ“ŹĀ maquee„æ„°¤äblink„æ„°¤Ź¤ÉŅ¤æÄæ×°ļÓƤĪ„æ„°ĀŅĮ¢ table¤Ī„Ķ„¹„Ȥä½YŗĻ¤ņĄūÓƤ·¤æ„ģ„¤„¢„¦„Č?1x1px¤ĪĶøĆ÷»Ļń¤Ē·łÕ{Õū ½ń¤Ē¤ĻÖ÷Į÷¤Ī漤ط½ HTML¤Ļ„Ē©`„æ¤Č¤·¤Ę»īÓƤņÓĆŅā¤¹¤ė¤æ¤į¤ĖŌģ¤ņ¶ØĮx¤¹¤ė¤ā¤Ī „Ē„¶„¤„ó¤ņÕū¤Ø¤ĘŅ¤æÄæ¤ņ¤¤¤¤øŠ¤ø¤Ė¤¹¤ė¤Ī¤ĻCSS¤ĪŅŪÄæ MVC„ā„Ē„ė¤Ī漤ط½ ½ń¤Ē¤āŹ¹¤ļ¤ģ¤Ę¤ėøÅÄī¤Ź¤Ī¤«¤Ź¤” Õl¤āView¤ĖČ«²æų¤³¤¦¤Č¤Ļ¤·¤Ź¤¤¤Ē¤·¤ē£æ „Š„Ć„Æ„Ø„ó„ɤĻoŅ¤Ē¤¤Ž¤»¤ó Excel¤ĪĄūÓƤĒ¤ā¤¤Į¤ó¤Č¤½¤ģ¤¾¤ģ¤¬·Öėx¤·×“B¤Ē¤¢¤ģ¤Š „Ē©`„æ¤ĻŌŁĄūÓĆæÉÄܤŹ¤Ž¤ŽÓ”Ė¢¤ä¤Ę±ÓƤĪ„ģ„¤„¢„¦„Ȥ¬æÉÄܤĖ¤Ź¤ė
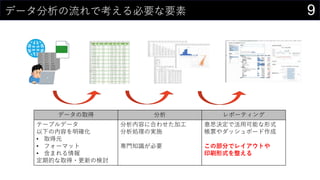
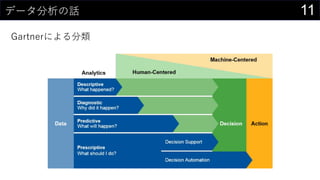
- #12: ŗĪ¤Ļ¤Č¤ā¤¢¤ģ¤Ž¤ŗ¤Ļ„Ē©`„椬o¤¤¤³¤Č¤Ė¤ĻŗĪ¤āŹ¼¤Ž¤é¤Ź¤¤ „Ē©`„æ¤ņßmĒŠ¤Ė¼Æ¼s¤·¤č¤¦ „Ē©`„æ„Õ„©©`„Ž„ƄȤĻ¤Į¤ć¤ó¤Č¤Ķ ¤Č¤Ļ¤¤¤Ø”¢¤ä¤ß¤Æ¤ā¤Ė¼Æ¤į¤ģ¤Š¤¤¤¤¤Ć¤Ę¤ļ¤±¤ø¤ć¤Ź¤Æ”¢·ÖĪö¤¹¤ė¤Ė¤Ļ”ø¤É¤ó¤Ź„Ē©`„椬±ŲŅŖ¤«”¹¤āŹÓ¤¬±ŲŅŖ ½ń¤Ź¤¤„Ē©`„æ¤ņ¼Æ¤į¤ė¤Ė¤Ļ¤Ŗ½š¤ārég¤ā¤«¤«¤ė¤·”¢¤æ¤į¤Ę¤Ŗ¤Æ¤Ī¤ā„æ„Ą¤ø¤ć¤Ź¤¤ ¤Ą¤«¤é”¢½ń¤¢¤ė„Ē©`„æ¤Ī¹ ģ¤«¤éßM¤į¤Ę¤¤¤Æ¤Ī¤¬¤¤¤¤¤ó¤Ą¤±¤É”¢ŗĪ¤¬¤¢¤ė¤«¤ļ¤«¤é¤ó¤ČŹ¹¤Ø¤Ź¤¤¤Ī¤Ē”¢„Ē©`„æ„«„æ„ķ„°¤¬±ŲŅŖ¤Ė¤Ź¤ė”£ Descriptive(ÓŹöµÄ)¤Ē¤Ļ”¢”ø½ńŗĪ¤¬Ęš¤³¤Ć¤Ę¤ė¤Ī¤«”¹¤ņ„Ē©`„椫¤éÕi¤ß½ā¤Æ ¾Ą“¤Ī„Ē©`„æ¼ÆÓ?æÉŅ»Æ?½yÓ¤ņŹ¹¤¦”£ Diagnostic(Ō\¶ĻµÄ)¤Ē¤Ļ”¢”ø¤Ź¤¼¤½¤ģ¤¬Ęš¤³¤Ć¤Ę¤ė¤Ī¤«”¹¤ņÕ{¤Ł¤ėß^³Ģ ŅŖŅņ·ÖĪö¤Č¤« ½yÓµÄŅņ¹ūĶĘÕ¤Č¤«¤Ļ¤ļ¤«¤ó¤Ź¤¤ Predictive(Óčy)¤Ē¤Ļ”¢”ø¤³¤ģ¤«¤éŗĪ¤¬Ęš¤³¤ė¤Ī¤«”¹¤ņÓčy¤¹¤ė ½yÓ„ā„Ē„ė¤äCŠµŃ§Į¤Ź¤É¤¬µĒö¤¹¤ė¤č Prescriptive(I·½µÄ)¤Ē¤Ļ”¢”øŗĪ¤ņ¤¹¤Ł¤¤«”¹¤ņQ¶Ø¤¹¤ė ½ń¤Ž¤ĒŅāĖ¼Q¶Ø¤ĻČĖég¤¬ŠŠ¤Ć¤Ę¤¤¤æ²æ·Ö¤Ž¤Ēŗ¬¤į¤Ę„Ē©`„æ¤Ē¤ä¤Ć¤Ę¤·¤Ž¤Ŗ¤¦¤Ć¤Ę¤ó¤Ą¤«¤é¤¹¤“¤¤”£ Ī“Ą“¤ŗ¤é©`¤Ć¤ĘŃŌ¤ļ¤ģ¤Ę¤ė”£ ¤³¤Ī°k±ķ¤Ē¤Ļ”¢Excel¤Ē Data Descriptive Diagnostic Predictive ¤ņ¤ä¤Ć¤Ę¤ß¤č¤¦£”
- #13: ĄūÓĆæÉÄܤŹŠĪŹ½¤Ė¤Ź¤Ć¤Ę¤Ź¤¤„Ē©`„æ = „Æ„½Excel ×ó : ”©¤Ź„Ē©`„愽©`„¹(„Ö„é„Ć„Æ„Ü„Ć„Æ„¹»Æ¤µ¤ģ¤Ę¤ė¤ā¤Ī¤Ļé) ÖŠŃė : „Ē©`„æ·ÖĪö»ł±P ÓŅÉĻ : „Ē©`„æ„«„æ„ķ„° ÓŅĻĀ : ·ÖĪöh¾³(Excel) ”©¤Ź„½©`„¹¤Ė¤Ž¤æ¤¬¤ė„Ē©`„æ¤ņ»ł±P¤Ė¼Æ¼s¤¹¤ė ¤³¤Īß^³Ģ¤Ē„Ē©`„æ¤ĪÕūĄķ¤äÕūŠĪ(ETLIĄķ)¤Ź¤É¤ā±ŲŅŖ¤Ė¤Ź¤ė „Ē©`„æ¤ņŠī¤Ø¤ė»ł±P¤Č¤·¤Ę „Ē©`„æ„ģ„¤„Æ DWH „Ē©`„æ„Ž©`„Č ¤Ź¤É¤¬¤¢¤²¤é¤ģ¤ė”£ „Ę©`„Ö„ėŌģ¤Ė¤Ź¤Ć¤Ę¤ė¤³¤Č¤¬±£Ō^¤µ¤ģ¤Ę¤¤¤ė¤ČęŅ¤·¤¤¤Ī¤Ē”¢¤½¤ģ¤é¤¬¤¢¤ė¤Ī¤¬Ķū¤Ž¤·¤¤¤¬ ¤«¤Ź¤é¤ŗ¤·¤ā×ī³õ¤«¤é“óģ¤«¤ź¤Ź¤ā¤Ī¤ņÓĆŅā¤¹¤ė±ŲŅŖ¤Ļ¤Ź¤Æ”¢×ī³õ¤Ļ¹²ÓŠ„Õ„©„ė„Ą¤ĖCSV¤äExcel„Õ„”„¤„ė¤ņČė¤ģ¤Č¤Æ¤Ē¤ā¤¤¤¤ ¼Æ¼s¤·¤æ„Ē©`„æ¤ņ„Ē©`„æ„«„æ„ķ„°»Æ¤·¤Ę ¤É¤Ī¤č¤¦¤Ź„½©`„¹¤«¤éČ”µĆ¤·¤æ„Ē©`„椫 ¤É¤Ī¤č¤¦¤Ź·½·Ø¤ĒČ”µĆ¤·¤æ„Ē©`„椫 ¤É¤Ī¤č¤¦¤ŹČĖ¤ņĻó¤Č¤·¤ĘČ”µĆ¤·¤æ„Ē©`„椫 ¤É¤Ī„愤„ß„ó„°¤ĒČ”µĆ¤·¤æ„Ē©`„椫 ¤É¤Ī¤č¤¦¤ŹÄŚČŻ(ĮŠŅ»ÓE¤Č¤½¤ĪŅāĪ¶¤ä gĪ»¤Ź¤É)¤« ±£“ꤵ¤ģ¤Ę¤ė„Ē©`„æ¤ĪĘŚég¤Ļ ¤Ź¤É¤ĪĒéó¤ņøń¼{¤·¤Ę¤Ŗ¤Æ ¤³¤ĪĒé󤬷ÖĪöÕߤ«¤é²ĪÕÕæÉÄܤŹ×“B¤Ė¤Ź¤Ć¤Ę¤¤¤ė±ŲŅŖ¤¬¤¢¤ė ·ÖĪöÕߤĻ„«„æ„ķ„°Ēéó¤ņ²ĪÕÕ¤·¤Ę”¢±ŲŅŖ¤Ź„Ē©`„æ¤ņŅ¤Ä¤±¤ė gėH¤Ī„Ē©`„æ¤ņČ”µĆ¤·¤Ę”¢·ÖĪö×÷I¤ĖČ”¤źģ¤«¤ė”£ „Ē©`„愬„Š„Ź„󄹤ĪŌ¤Ļ¤·¤Ź¤¤
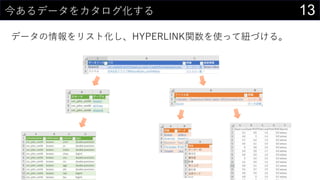
- #14: „Ē©`„æŅ»ÓEĒéó¤ņ×÷³É¤¹¤ė DB¤Ī„Ę©`„Ö„ėĒéó¤äĮŠŅ»ÓEĒéó¤ĻPower Query¤ĒSQLų¤±¤ŠČ”µĆæÉÄÜ „Õ„”„¤„ė¤Ē¹ÜĄķ¤µ¤ģ¤Ę¤¤¤ė¤ā¤Ī¤Ļ¹²ÓŠ„Õ„©„ė„Ą¤Ź¤É¤ņŹ¹¤Ć¤ĘŅ»¤«Ėł¤Ė¤Ž¤Č¤į¤ė ¤½¤ģ¤¾¤ģ¤Ī„Õ„”„¤„ė¤Ė„ź„ó„Ƥņ¤ė¤Č¤Č¤ā¤ĖĮŠĆūĒéó¤ĻPower Query¤ĒČ”µĆ ½ń»Ų¤Ļ¤ä¤Ć¤Ę¤Ź¤¤¤±¤É”¢„Õ„”„¤„ėŅ»ÓE¤ņČ”µĆ¤¹¤ė²æ·Ö¤äø÷„Ę©`„Ö„ėĒéó¤ņČ”µĆ¤¹¤ė²æ·Ö¤ĻVBAŹ¹¤Ć¤Ę×ŌӻƤāæÉÄÜ hyperlinkévŹż¤ņŹ¹¤¦¤³¤Č¤Ē ČĪŅā¤ĪExcel„Õ„”„¤„ė¤ĪĢŲ¶Ø¤Ī„·©`„ȤŹ¤É¤ĖŅĘÓ WebÉĻ¤Ī„Ē©`„æ¤Ė„ź„ó„Ƥņ¤ė ¤Ź¤É¤¹¤ė ŗĪ¤¬ęŅ¤·¤¤¤« ¤³¤Ī¤č¤¦¤Ė¤Ž¤Č¤į¤Ę¤Ŗ¤±¤ŠŌŖ„Ē©`„æ¤Ļ¤³¤ĪĒéó¤ņ²ĪÕÕ¤·¤ĘPower Query¤ĒČ”µĆæÉÄܤĖ¤Ź¤ė (“Ī¤Ī·ÖĪö¤ĪŌ¤Ė¾A¤Æ)
- #15: ČĪŅā¤ĪöĖł¤Ė„ź„ó„ÆæÉÄܤŹŠŌŁ|¤ņĄūÓƤ·¤Ę webÉĻ¤Ī„Ē©`„椫¤éĖū¤ĪExcel„Õ„”„¤„ė¤Ž¤Ē”©¤Ź„Ē©`„愽©`„¹¤Ų¤Ī„ź„ó„ƤņŁN¤ģ¤ė ²ĪÕÕĻȤ¬Excel¤Ē¤¢¤ģ¤Š¤µ¤é¤Ė¤½¤³¤«¤éHYPERLINKévŹż¤ĒėAӻƤ¹¤ė¤³¤Č¤āæÉÄÜ Power Query¤Ē¤Ļhttp½UÓɤĒcsv¤äjson¤ņČ”µĆ¤Ē¤¤ė¤Ī¤Ļ¤ā¤Į¤ķ¤ó¤Ī¤³¤Č”¢ HTML¤Ī„Ę©`„Ö„ė¤ņÖø¶Ø¤·¤ĘČ”µĆ¤¹¤ė¤³¤Č¤āæÉÄܤĒ¤¹”£ ¤½¤¦¤¤¤Ć¤æweb¤«¤é„Ē©`„æ¤ņČ”µĆ¤¹¤ė¤č¤¦¤ŹėH¤Ė¤Ļ¤½¤Ī„Ś©`„ø¤Ų¤Ī„ź„ó„ƤņŁN¤Ć¤Ę¤Ŗ¤Æ¤Č¤¤¤¤¤Ē¤·¤ē¤¦”£
- #16: „Ē©`„æČ”µĆŌŖ¤¬RDB¤Ē¤¢¤ģ¤Š„Ę©`„Ö„ėŅ»ÓE¤«¤éĄūÓƤ¹¤ė¤ā¤Ī¤ņßxk¤Ē¤¤ė¤Ū¤«”¢ SQL¤ņÓŹö¤·¤Ę„Ē©`„æČ”µĆ¤¹¤ė¤³¤Č¤āæÉÄÜ ODBC¤ņŹ¹¤Ć¤æRDB¤«¤é¤Ī„Ē©`„æČ”µĆ¤Ī¤Ū¤« Excel CSV Web ¤Ź¤É”©¤Ź„Ē©`„愽©`„¹¤«¤éĶ¬Ņ»¤Ī²Ł×÷øŠ¤ĒČ”µĆæÉÄÜ Õi¤ßŽz¤ó¤Ą„Ē©`„æ¤Ļ„Ę©`„Ö„ė¤ä„Ē©`„æ„ā„Ē„ė¤Č¤·¤Ę±£³Ö¤¹¤ė”£ PowerQuery¤ĒÕi¤ßŽz¤ó¤Ą„Ē©`„æ¤Ļ ŌŖ„Ē©`„椽¤Ī¤ā¤Ī¤ņ¾¼Æ¤¹¤ė¤ļ¤±¤Ē¤Ļ¤Ź¤¤¤Ī¤ĒŹĀ¹Ź¤¬¤Ź¤¤ ŌŖ„Ē©`„æ¤Ėäøü¤¬¤¢¤Ć¤æöŗĻ¤ā„Ē©`„æ¤ĪøüŠĀ¤ņŠŠ¤¦¤³¤Č¤ĒźæÉÄÜ „Ē©`„æ„ā„Ē„ė¤Ē¤¢¤ģ¤Š„·©`„ȤĖ¤ĻÕi¤ßŽz¤Ž¤Ź¤¤¤Ī¤Ē1,048,576ŠŠ”¢16,384ĮŠ¤Ī±Ś¤ņ³¬¤Ø¤ė¤³¤Č¤āæÉÄÜ ¤Č¤¤¤¦ĢŲÕ¤ņ³Ö¤Ä
- #17: „Ē©`„æ„ā„Ē„ė¤ĖÕi¤ßŽz¤ą¤³¤Č¤Ē„ź„ģ©`„·„ē„ó¤Ī¶ØĮx¤āŠŠ¤Ø¤ė”£ ¤³¤ģ¤ĻPivot Table¤ĒĄūÓĆæÉÄÜ”£ ¤Ź¤Ŗ”¢„ź„ģ©`„·„ē„ó¤ņ¶ØĮx¤¹¤ė¤Ū¤«”¢¤¢¤é¤«¤ø¤įJOIN¤·¤Ę¤Ŗ¤Æ¤³¤Č¤āæÉÄÜ”£ ČĖī¤¬VLOOKUP¤Ėæąé¤·¤æ¤źXLOOKUP¤ĖZĻ²¤·¤Ę¤ėég¤ĖExcel¤ĻRDB¤Ė¤Ź¤Ć¤Ę¤¤¤æ”£
- #27: ŹŹĒŠ¤Ź³ó¤ņĒó¤į¤ė¤æ¤į¤ĪŹÖ·Ø¤ā¤¢¤ė¤¬¤³¤³¤Ēøī°®
- #28: ĖÄ·ÖĪ»Źż * ĖÄ·ÖĪ»¹ ģ¤Ī1.5±¶¤Ž¤Ē
- #30: |2|ŅŌÉĻ¤ņ®³£¤Č¤·¤Ę¤ė¤Ī¤ĻÕżŅ·Ö²¼¤Ī·ÖÉ¢¤ĖÓÉĄ“¤¹¤ė ·Ö²¼¤¬®¤Ź¤ėöŗĻ¤ĻeĶ¾ŹÓ¤¬±ŲŅŖ”£ ČĪŅā¤Ī·Ö²¼¤Ė¤·¤Ę·ÖÉ¢ÓÉĄ“¤ĪĶā¤ģ¤ņŌO¶Ø¤·¤æ¤¤öŗĻ¤Ļ”ø„Į„§„Ó„·„§„Õ¤Ī²»µČŹ½”¹¤ĒÕ{¤Ł¤Ę¤ß¤č¤¦£”
- #32: ÉĻȤĻĶ¬¤ø¤Ė¤Ź¤ė¤Ī¤ĒĻĀ²Ī»¤Ą¤±³öĮ¦¤µ¤ģ¤ė ³öĮ¦¤ĻŹż×Ö¤Ą¤±¤Ź¤Ī¤Ē”¢Ģõ¼žø¶¤ųŹ½¤ĒÉ«¤ņŌO¶Ø¤·¤Ę¤ė
- #34: ĻąévSŹż¤Ļ¾ŠĪ¤ĪévS¤·¤«±ķ¤»¤Ź¤¤ É¢²¼ķ¤ņŅ¤ė¤³¤Č¤Ē”¢·Ē¾ŠĪ¤ĪévS¤¬Õi¤ßČ”¤ģ¤ė¤³¤Č¤ā¤¢¤ė É¢²¼ķ¤āĻąévSŹż¤ČĶ¬¤ĖŠŠĮŠ¤Ė¤Ē¤¤ė¤±¤É”¢Ķ¬¤ø„Ī„ź¤ĒVBA¤Ē¤ä¤Ć¤Ę¤Ķ
- #36: ±Ź¤ĻĢõ¼žø¶¤ŹéŹ½¤ĒĢ«×Ö¤Ė¤·¤Ę¤ė
- #46: Óč²ā”¢³ö¤æ¤č£”£”
- #47: „Ę©`„Ö„ė¤ä„»„ė¤Ī¹ ģ¤«¤é„Ō„Ü„Ć„Č„Ę©`„Ö„ė¤ä„Ō„Ü„Ć„Č„°„é„Õ¤ņ×÷³É¤¹¤ė”£ Ķس£”¢„Ō„Ü„Ć„Č„°„é„Õ¤Ļ gĢå¤Ē×÷³É¤¹¤ė¤³¤Č¤Ļ¤Ē¤¤ŗ”¢±Ų¤ŗ„Ō„Ü„Ć„Č„Ę©`„Ö„ė¤ČßBÓ¤¹¤ė”£ ¤³¤ģ¤Ą¤Č„Ą„Ć„·„å„Ü©`„ɻƤ¹¤ė¤ĖėH¤·¤Ę¤¤¤ķ¤ó¤ŹÖøĖ¤ņŅ¤æ¤¤¤Č¤¤Ė¤¤¤Į¤¤¤Į»ĆęÉĻ¤Ė¤Ļ±ķŹ¾¤·¤Ź¤¤„Ō„Ü„Ć„Č„Ę©`„Ö„ė¤ā×÷¤é¤Ź¤¤¤Č¤Ź¤Ī¤Ē²ŠÄī
- #48: „Ē©`„æ„ā„Ē„ė¤«¤é¤Ē¤¢¤ģ¤Š¤½¤ģ¤¾¤ģ¤ņ¶ĄĮ¢¤·¤Ę×÷¤ė¤³¤Č¤¬æÉÄÜ
- #49: „¹„鄤„µ¤ņĶؤø¤Ę„ģ„Ż©`„Ȥņ½Ó¾A
- #50: „Ę©`„Ö„ė¤ā„Ō„Ü„Ć„Č„Ę©`„Ö„ė¤ā„¹„鄤„µ¤ņŌO¶ØæÉÄܤĄ¤¬”¢¤½¤ģ¤é¤ņßBÓ¤µ¤»¤ė¤³¤Č¤Ļ¤Ē¤¤Ź¤¤”£ É¢²¼ķ¤ä„Ņ„¹„Č„°„é„ą¤Ļ„Ō„Ü„Ć„Č„Ę©`„Ö„ė¤«¤é¤Ļ×÷³É¤Ē¤¤Ź¤¤¤Ī¤Ē¤³¤ģ¤é¤ņ„Ą„Ć„·„å„Ü©`„ɤĖŗ¬¤į¤ėöŗĻ¤Ļ×¢Ņā¤¬±ŲŅŖ”£ ¤Ž¤æø÷·N·ÖĪöCÄܤĻ„ā„Ī¤Ė¤č¤Ć¤Ę¤Ļ„Ē©`„æ¤ĪøüŠĀr¤ĖŌŁ¶ČgŠŠ¤·¤Ź¤¤¤Č„Ą„į¤Ź¤ā¤Ī¤ā¤¢¤ė¤Ī¤Ē¤½¤ģ¤é¤Ė¤ā×¢Ņā
- #52: ¤³¤ó¤ŹøŠ¤ø¤Ē„Ą„Ć„·„å„Ü©`„ɤ¬×÷¤ģ¤ė
- #57: „É„„å„į„ó„ȤĻ2ÖŲ¹ÜĄķ¤Ė¤Ź¤ź¤¬¤Į¤Ē”¢äøü¤¬¤¢¤Ć¤æ¼Ź¤ĖI·½¤Į¤ć¤ó¤ČŠŽÕż¤µ¤ģ¤ė¤³¤Č¤ņ±£Ō^¤¹¤ė¤Ī¤ĻÄѤ·¤¤
- #78: „Ē©`„愵„¤„Ø„ó„Ę„£„¹„Ȥä„Ø„ó„ø„Ė„¢¤¬×÷³É¤·¤æ„ׄķ„°„é„ą¤ņ„Ž„Æ„ķ»Æ¤·¤Ę„Ä©`„ė¤Č¤·¤Ę½M¤ßŽz¤ą¤³¤Č¤Ē AlteryxÉĻ¤Ē¤ĻÕl¤Ē¤āŗ g¤Ė¤½¤ĪCÄܤņĄūÓƤĒ¤¤ė¤č¤¦¤Ė¤Ź¤ė