Extendible hashing
Download as pptx, pdf3 likes11,793 views

Extendible Hashing Example Extendible hashing solves bucket overflow by splitting the bucket into two and if necessary increasing the directory size. When the directory size increases it doubles its size a certain number of times.
1 of 12
Downloaded 165 times








Recommended
Sorting Algorithms
Sorting AlgorithmsPranay Neema
╠²
This document discusses various sorting algorithms and their complexities. It begins by defining an algorithm and complexity measures like time and space complexity. It then defines sorting and common sorting algorithms like bubble sort, selection sort, insertion sort, quicksort, and mergesort. For each algorithm, it provides a high-level overview of the approach and time complexity. It also covers sorting algorithm concepts like stable and unstable sorting. The document concludes by discussing future directions for sorting algorithms and their applications.Optimal binary search tree dynamic programming
Optimal binary search tree dynamic programmingP. Subathra Kishore, KAMARAJ College of Engineering and Technology, Madurai
╠²
The document discusses optimal binary search trees (OBST) and describes the process of creating one. It begins by introducing OBST and noting that the method can minimize average number of comparisons in a successful search. It then shows the step-by-step process of calculating the costs for different partitions to arrive at the optimal binary search tree for a given sample dataset with keys and frequencies. The process involves calculating Catalan numbers for each partition and choosing the minimum cost at each step as the optimal is determined.AI_Session 7 Greedy Best first search algorithm.pptx
AI_Session 7 Greedy Best first search algorithm.pptxGuru Nanak Technical Institutions
╠²
This document summarizes key topics from a session on problem solving by search algorithms in artificial intelligence. It discusses uninformed search strategies like breadth-first search and depth-first search. It also covers informed, heuristic search strategies such as greedy best-first search and A* search which use heuristic functions to estimate distance to the goal. Examples are provided to illustrate best first search, and it describes how this algorithm expands nodes and uses priority queues to order nodes by estimated cost. The next session is slated to cover the A* search algorithm in more detail.Lecture optimal binary search tree 
Lecture optimal binary search tree Divya Ks
╠²
This document discusses optimal binary search trees and provides an example problem. It begins with basic definitions of binary search trees and optimal binary search trees. It then shows an example problem with keys 1, 2, 3 and calculates the cost as 17. The document explains how to use dynamic programming to find the optimal binary search tree for keys 10, 12, 16, 21 with frequencies 4, 2, 6, 3. It provides the solution matrix and explains that the minimum cost is 2 with the optimal tree as 10, 12, 16, 21.Assignment problem branch and bound.pptx
Assignment problem branch and bound.pptxKrishnaVardhan50
╠²
1. Branch and bound is an algorithm that uses a state space tree to solve optimization problems like the knapsack problem and traveling salesman problem. It works by recursively dividing the solution space and minimizing costs at each step.
2. The document then provides an example of using branch and bound to solve a job assignment problem with 4 jobs and 4 people. It calculates lower bounds at each step of the algorithm and prunes branches that cannot lead to an optimal solution.
3. After exploring the solution space, the algorithm arrives at the optimal assignment of Person A to Job 2, Person B to Job 1, Person C to Job 3, and Person D to Job 4, with a minimum total cost of 21.01 Knapsack using Dynamic Programming
01 Knapsack using Dynamic ProgrammingFenil Shah
╠²
Intoduction on Dynamic Programming & 0-1 Knapsack problem,
Implementation of 0-1 Knapsack using DP with example, its algorithm & analysisdaa-unit-3-greedy method
daa-unit-3-greedy methodhodcsencet
╠²
The document discusses the greedy method algorithmic approach. It provides an overview of greedy algorithms including that they make locally optimal choices at each step to find a global optimal solution. The document also provides examples of problems that can be solved using greedy methods like job sequencing, the knapsack problem, finding minimum spanning trees, and single source shortest paths. It summarizes control flow and applications of greedy algorithms.I.BEST FIRST SEARCH IN AI
I.BEST FIRST SEARCH IN AIvikas dhakane
╠²
Artificial Intelligence: Introduction, Typical Applications. State Space Search: Depth Bounded
DFS, Depth First Iterative Deepening. Heuristic Search: Heuristic Functions, Best First Search,
Hill Climbing, Variable Neighborhood Descent, Beam Search, Tabu Search. Optimal Search: A
*
algorithm, Iterative Deepening A*
, Recursive Best First Search, Pruning the CLOSED and OPEN
Lists12. Indexing and Hashing in DBMS
12. Indexing and Hashing in DBMSkoolkampus
╠²
The document discusses various indexing techniques used to improve data access performance in databases, including ordered indices like B-trees and B+-trees, as well as hashing techniques. It covers the basic concepts, data structures, operations, advantages and disadvantages of each approach. B-trees and B+-trees store index entries in sorted order to support range queries efficiently, while hashing distributes entries uniformly across buckets using a hash function but does not support ranges.Knapsack problem using greedy approach
Knapsack problem using greedy approachpadmeshagrekar
╠²
In shared PPT we have discussed Knapsack problem using greedy approach and its two types i.e Fractional and 0-1Map reduce in BIG DATA
Map reduce in BIG DATAGauravBiswas9
╠²
MapReduce is a programming framework that allows for distributed and parallel processing of large datasets. It consists of a map step that processes key-value pairs in parallel, and a reduce step that aggregates the outputs of the map step. As an example, a word counting problem is presented where words are counted by mapping each word to a key-value pair of the word and 1, and then reducing by summing the counts of each unique word. MapReduce jobs are executed on a cluster in a reliable way using YARN to schedule tasks across nodes, restarting failed tasks when needed.Code generation
Code generationAparna Nayak
╠²
The document discusses code generation in compilers. It describes the main tasks of the code generator as instruction selection, register allocation and assignment, and instruction ordering. It then discusses various issues in designing a code generator such as the input and output formats, memory management, different instruction selection and register allocation approaches, and choice of evaluation order. The target machine used is a hypothetical machine with general purpose registers, different addressing modes, and fixed instruction costs. Examples of instruction selection and utilization of addressing modes are provided.Critical section problem in operating system.
Critical section problem in operating system.MOHIT DADU
╠²
The critical section problem refers to ensuring that at most one process can execute its critical section, a code segment that accesses shared resources, at any given time. There are three requirements for a correct solution: mutual exclusion, meaning no two processes can be in their critical section simultaneously; progress, ensuring a process can enter its critical section if it wants; and bounded waiting, placing a limit on how long a process may wait to enter the critical section. Early attempts to solve this using flags or a turn variable were incorrect as they did not guarantee all three requirements.Knapsack Problem
Knapsack ProblemJenny Galino
╠²
The document discusses the knapsack problem, which involves selecting a subset of items that fit within a knapsack of limited capacity to maximize the total value. There are two versions - the 0-1 knapsack problem where items can only be selected entirely or not at all, and the fractional knapsack problem where items can be partially selected. Solutions include brute force, greedy algorithms, and dynamic programming. Dynamic programming builds up the optimal solution by considering all sub-problems.0 1 knapsack using branch and bound
0 1 knapsack using branch and boundAbhishek Singh
╠²
Given two integer arrays val[0...n-1] and wt[0...n-1] that represents values and weights associated with n items respectively. Find out the maximum value subset of val[] such that sum of the weights of this subset is smaller than or equal to knapsack capacity W. Here the BRANCH AND BOUND ALGORITHM is discussed .System Programming Unit II
System Programming Unit IIManoj Patil
╠²
A macro processor allows programmers to define macros, which are single line abbreviations for blocks of code. The macro processor performs macro expansion by replacing macro calls with the corresponding block of instructions defined in the macro. It uses a two pass approach, where the first pass identifies macro definitions and saves them to a table, and the second pass identifies macro calls and replaces them with the defined code, substituting any arguments.Evolutionary models
Evolutionary modelsPihu Goel
╠²
Evolutionary models are iterative and incremental software development approaches that combine iterative and incremental processes. There are two main types: prototyping and spiral models. The prototyping model develops prototypes that are tested and refined based on customer feedback until requirements are met, while the spiral model proceeds through multiple loops or phases of planning, risk analysis, engineering, and evaluation. Both approaches allow requirements to evolve through development and support risk handling.Informed and Uninformed search Strategies
Informed and Uninformed search StrategiesAmey Kerkar
╠²
1. The document discusses various search strategies used to solve problems including uninformed search strategies like breadth-first search and depth-first search, and informed search strategies like best-first search and A* search that use heuristics.
2. It provides examples and explanations of breadth-first search, depth-first search, hill climbing, and best-first search algorithms. Key advantages and disadvantages of each strategy are outlined.
3. The document focuses on explaining control strategies for problem solving, different types of search strategies classified as uninformed or informed, and algorithms for breadth-first search, depth-first search, hill climbing, and best-first search.Merge sort algorithm
Merge sort algorithmShubham Dwivedi
╠²
Merge sort is a sorting technique based on divide and conquer technique. With worst-case time complexity being ╬¤(n log n), it is one of the most respected algorithms.
Merge sort first divides the array into equal halves and then combines them in a sorted manner.Breadth First Search & Depth First Search
Breadth First Search & Depth First SearchKevin Jadiya
╠²
The slides attached here describes how Breadth first search and Depth First Search technique is used in Traversing a graph/tree with Algorithm and simple code snippet.
Double Hashing.pptx
Double Hashing.pptxVikasNirgude2
╠²
Double hashing uses two hash functions, h1 and h2. If h1 causes a collision, h2 is used to compute an increment to probe for the next empty slot. Common definitions for h2 include h2(key)=1+key%(tablesize) or h2(key)=M-(key%M) where M is a prime smaller than the table size. Quadratic probing probes locations using the formula h(key)=[h(key)+i^2]%table_size. Rehashing doubles the table size when the load factor exceeds 0.75, reinserting all elements to maintain a low load factor.queue & its applications
queue & its applicationssomendra kumar
╠²
The document discusses different types of queues including their representations, operations, and applications. It describes queues as linear data structures that follow a first-in, first-out principle. Common queue operations are insertion at the rear and deletion at the front. Queues can be represented using arrays or linked lists. Circular queues and priority queues are also described as variants that address limitations of standard queues. Real-world and technical applications of queues include CPU scheduling, cashier lines, and data transfer between processes.Asymptotic Notation
Asymptotic NotationProtap Mondal
╠²
The document discusses algorithm analysis and asymptotic notation. It defines algorithm analysis as comparing algorithms based on running time and other factors as problem size increases. Asymptotic notation such as Big-O, Big-Omega, and Big-Theta are introduced to classify algorithms based on how their running times grow relative to input size. Common time complexities like constant, logarithmic, linear, quadratic, and exponential are also covered. The properties and uses of asymptotic notation for equations and inequalities are explained.Planning in Artificial Intelligence
Planning in Artificial Intelligencekitsenthilkumarcse
╠²
In the field of artificial intelligence (AI), planning refers to the process of developing a sequence of actions or steps that an intelligent agent should take to achieve a specific goal or solve a particular problem. AI planning is a fundamental component of many AI systems and has applications in various domains, including robotics, autonomous systems, scheduling, logistics, and more. Here are some key aspects of planning in AI:
Definition of Planning: Planning involves defining a problem, specifying the initial state, setting a goal state, and finding a sequence of actions or a plan that transforms the initial state into the desired goal state while adhering to certain constraints.
State-Space Representation: In AI planning, the problem is often represented as a state-space, where each state represents a snapshot of the system, and actions transform one state into another. The goal is to find a path through this state-space from the initial state to the goal state.
Search Algorithms: AI planning typically relies on search algorithms to explore the state-space efficiently. Uninformed search algorithms, such as depth-first search and breadth-first search, can be used, as well as informed search algorithms, like A* search, which incorporates heuristics to guide the search.
Heuristics: Heuristics are used in planning to estimate the cost or distance from a state to the goal. Heuristic functions help inform the search algorithms by providing an estimate of how close a state is to the solution. Good heuristics can significantly improve the efficiency of the search.
Plan Execution: Once a plan is generated, the next step is plan execution, where the agent carries out the actions in the plan to achieve the desired goal. This often requires monitoring the environment to ensure that the actions are executed as planned.
Temporal and Hierarchical Planning: In more complex scenarios, temporal planning deals with actions that have temporal constraints, and hierarchical planning involves creating plans at multiple levels of abstraction, making planning more manageable in complex domains.
Partial and Incremental Planning: Sometimes, it may not be necessary to create a complete plan from scratch. Partial and incremental planning allows agents to adapt and modify existing plans to respond to changing circumstances.
Applications: Planning is used in a wide range of applications, from manufacturing and logistics (e.g., scheduling production and delivery) to robotics (e.g., path planning for robots) and game playing (e.g., chess and video games).
Challenges: Challenges in AI planning include dealing with large search spaces, handling uncertainty, addressing resource constraints, and optimizing plans for efficiency and performance.
AI planning is a critical component in creating intelligent systems that can autonomously make decisions and solve complex problems. Lecture: Automata
Lecture: AutomataMarina Santini
╠²
The document provides an introduction to automata theory and finite state automata (FSA). It defines an automaton as an abstract computing device or mathematical model used in computer science and computational linguistics. The reading discusses pioneers in automata theory like Alan Turing and his development of Turing machines. It then gives an overview of finite state automata, explaining concepts like states, transitions, alphabets, and using a example of building an FSA for a "sheeptalk" language to demonstrate these components.Simulated Annealing
Simulated AnnealingJoy Dutta
╠²
SA is a global optimization technique.
It distinguishes between different local optima.
It is a memory less algorithm & the algorithm does not use any information gathered during the search.
SA is motivated by an analogy to annealing in solids.
& it is an iterative improvement algorithm.
Segmentation in operating systems
Segmentation in operating systemsDr. Jasmine Beulah Gnanadurai
╠²
This document discusses segmentation in operating systems. Segmentation divides memory into variable-sized segments rather than fixed pages. Each process is divided into segments like the main program, functions, variables, etc. There are two types of segmentation: virtual memory segmentation which loads segments non-contiguously and simple segmentation which loads all segments together at once but non-contiguously in memory. Segmentation uses a segment table to map the two-part logical address to the single physical address through looking up the segment base address.Topological Sorting
Topological SortingShahDhruv21
╠²
It is related to Analysis and Design Of Algorithms Subject.Basically it describe basic of topological sorting, it's algorithm and step by step process to solve the example of topological sort.Chapter13
Chapter13gourab87
╠²
The document discusses various topics related to secondary storage and file organization in databases:
1) Secondary storage devices like magnetic disks are used to permanently store large databases and provide high storage capacity compared to main memory.
2) Files are organized on disks using various methods like heap files, sorted files, and hashing to allow efficient retrieval, insertion, and deletion of records.
3) RAID (Redundant Array of Independent Disks) technology improves disk performance using data striping across multiple disks and reliability using disk mirroring.Application of Stack - Yadraj Meena
Application of Stack - Yadraj MeenaDipayan Sarkar
╠²
The document discusses stacks and their applications. It provides 3 key points:
1. A stack is an abstract data type that follows LIFO (last-in, first-out) principles with push and pop operations. Functions like stack_full and stack_empty are used to implement stacks.
2. Stacks have applications in converting infix notation to postfix notation and evaluating postfix expressions. The algorithms pop and push operators and operands to produce the postfix form or calculate values.
3. Examples show converting the infix expression (A * B + (C - D / E)) to postfix AB*C(D-F/)++ and evaluating the postfix form of True, False, NOT, AND,More Related Content
What's hot (20)
12. Indexing and Hashing in DBMS
12. Indexing and Hashing in DBMSkoolkampus
╠²
The document discusses various indexing techniques used to improve data access performance in databases, including ordered indices like B-trees and B+-trees, as well as hashing techniques. It covers the basic concepts, data structures, operations, advantages and disadvantages of each approach. B-trees and B+-trees store index entries in sorted order to support range queries efficiently, while hashing distributes entries uniformly across buckets using a hash function but does not support ranges.Knapsack problem using greedy approach
Knapsack problem using greedy approachpadmeshagrekar
╠²
In shared PPT we have discussed Knapsack problem using greedy approach and its two types i.e Fractional and 0-1Map reduce in BIG DATA
Map reduce in BIG DATAGauravBiswas9
╠²
MapReduce is a programming framework that allows for distributed and parallel processing of large datasets. It consists of a map step that processes key-value pairs in parallel, and a reduce step that aggregates the outputs of the map step. As an example, a word counting problem is presented where words are counted by mapping each word to a key-value pair of the word and 1, and then reducing by summing the counts of each unique word. MapReduce jobs are executed on a cluster in a reliable way using YARN to schedule tasks across nodes, restarting failed tasks when needed.Code generation
Code generationAparna Nayak
╠²
The document discusses code generation in compilers. It describes the main tasks of the code generator as instruction selection, register allocation and assignment, and instruction ordering. It then discusses various issues in designing a code generator such as the input and output formats, memory management, different instruction selection and register allocation approaches, and choice of evaluation order. The target machine used is a hypothetical machine with general purpose registers, different addressing modes, and fixed instruction costs. Examples of instruction selection and utilization of addressing modes are provided.Critical section problem in operating system.
Critical section problem in operating system.MOHIT DADU
╠²
The critical section problem refers to ensuring that at most one process can execute its critical section, a code segment that accesses shared resources, at any given time. There are three requirements for a correct solution: mutual exclusion, meaning no two processes can be in their critical section simultaneously; progress, ensuring a process can enter its critical section if it wants; and bounded waiting, placing a limit on how long a process may wait to enter the critical section. Early attempts to solve this using flags or a turn variable were incorrect as they did not guarantee all three requirements.Knapsack Problem
Knapsack ProblemJenny Galino
╠²
The document discusses the knapsack problem, which involves selecting a subset of items that fit within a knapsack of limited capacity to maximize the total value. There are two versions - the 0-1 knapsack problem where items can only be selected entirely or not at all, and the fractional knapsack problem where items can be partially selected. Solutions include brute force, greedy algorithms, and dynamic programming. Dynamic programming builds up the optimal solution by considering all sub-problems.0 1 knapsack using branch and bound
0 1 knapsack using branch and boundAbhishek Singh
╠²
Given two integer arrays val[0...n-1] and wt[0...n-1] that represents values and weights associated with n items respectively. Find out the maximum value subset of val[] such that sum of the weights of this subset is smaller than or equal to knapsack capacity W. Here the BRANCH AND BOUND ALGORITHM is discussed .System Programming Unit II
System Programming Unit IIManoj Patil
╠²
A macro processor allows programmers to define macros, which are single line abbreviations for blocks of code. The macro processor performs macro expansion by replacing macro calls with the corresponding block of instructions defined in the macro. It uses a two pass approach, where the first pass identifies macro definitions and saves them to a table, and the second pass identifies macro calls and replaces them with the defined code, substituting any arguments.Evolutionary models
Evolutionary modelsPihu Goel
╠²
Evolutionary models are iterative and incremental software development approaches that combine iterative and incremental processes. There are two main types: prototyping and spiral models. The prototyping model develops prototypes that are tested and refined based on customer feedback until requirements are met, while the spiral model proceeds through multiple loops or phases of planning, risk analysis, engineering, and evaluation. Both approaches allow requirements to evolve through development and support risk handling.Informed and Uninformed search Strategies
Informed and Uninformed search StrategiesAmey Kerkar
╠²
1. The document discusses various search strategies used to solve problems including uninformed search strategies like breadth-first search and depth-first search, and informed search strategies like best-first search and A* search that use heuristics.
2. It provides examples and explanations of breadth-first search, depth-first search, hill climbing, and best-first search algorithms. Key advantages and disadvantages of each strategy are outlined.
3. The document focuses on explaining control strategies for problem solving, different types of search strategies classified as uninformed or informed, and algorithms for breadth-first search, depth-first search, hill climbing, and best-first search.Merge sort algorithm
Merge sort algorithmShubham Dwivedi
╠²
Merge sort is a sorting technique based on divide and conquer technique. With worst-case time complexity being ╬¤(n log n), it is one of the most respected algorithms.
Merge sort first divides the array into equal halves and then combines them in a sorted manner.Breadth First Search & Depth First Search
Breadth First Search & Depth First SearchKevin Jadiya
╠²
The slides attached here describes how Breadth first search and Depth First Search technique is used in Traversing a graph/tree with Algorithm and simple code snippet.
Double Hashing.pptx
Double Hashing.pptxVikasNirgude2
╠²
Double hashing uses two hash functions, h1 and h2. If h1 causes a collision, h2 is used to compute an increment to probe for the next empty slot. Common definitions for h2 include h2(key)=1+key%(tablesize) or h2(key)=M-(key%M) where M is a prime smaller than the table size. Quadratic probing probes locations using the formula h(key)=[h(key)+i^2]%table_size. Rehashing doubles the table size when the load factor exceeds 0.75, reinserting all elements to maintain a low load factor.queue & its applications
queue & its applicationssomendra kumar
╠²
The document discusses different types of queues including their representations, operations, and applications. It describes queues as linear data structures that follow a first-in, first-out principle. Common queue operations are insertion at the rear and deletion at the front. Queues can be represented using arrays or linked lists. Circular queues and priority queues are also described as variants that address limitations of standard queues. Real-world and technical applications of queues include CPU scheduling, cashier lines, and data transfer between processes.Asymptotic Notation
Asymptotic NotationProtap Mondal
╠²
The document discusses algorithm analysis and asymptotic notation. It defines algorithm analysis as comparing algorithms based on running time and other factors as problem size increases. Asymptotic notation such as Big-O, Big-Omega, and Big-Theta are introduced to classify algorithms based on how their running times grow relative to input size. Common time complexities like constant, logarithmic, linear, quadratic, and exponential are also covered. The properties and uses of asymptotic notation for equations and inequalities are explained.Planning in Artificial Intelligence
Planning in Artificial Intelligencekitsenthilkumarcse
╠²
In the field of artificial intelligence (AI), planning refers to the process of developing a sequence of actions or steps that an intelligent agent should take to achieve a specific goal or solve a particular problem. AI planning is a fundamental component of many AI systems and has applications in various domains, including robotics, autonomous systems, scheduling, logistics, and more. Here are some key aspects of planning in AI:
Definition of Planning: Planning involves defining a problem, specifying the initial state, setting a goal state, and finding a sequence of actions or a plan that transforms the initial state into the desired goal state while adhering to certain constraints.
State-Space Representation: In AI planning, the problem is often represented as a state-space, where each state represents a snapshot of the system, and actions transform one state into another. The goal is to find a path through this state-space from the initial state to the goal state.
Search Algorithms: AI planning typically relies on search algorithms to explore the state-space efficiently. Uninformed search algorithms, such as depth-first search and breadth-first search, can be used, as well as informed search algorithms, like A* search, which incorporates heuristics to guide the search.
Heuristics: Heuristics are used in planning to estimate the cost or distance from a state to the goal. Heuristic functions help inform the search algorithms by providing an estimate of how close a state is to the solution. Good heuristics can significantly improve the efficiency of the search.
Plan Execution: Once a plan is generated, the next step is plan execution, where the agent carries out the actions in the plan to achieve the desired goal. This often requires monitoring the environment to ensure that the actions are executed as planned.
Temporal and Hierarchical Planning: In more complex scenarios, temporal planning deals with actions that have temporal constraints, and hierarchical planning involves creating plans at multiple levels of abstraction, making planning more manageable in complex domains.
Partial and Incremental Planning: Sometimes, it may not be necessary to create a complete plan from scratch. Partial and incremental planning allows agents to adapt and modify existing plans to respond to changing circumstances.
Applications: Planning is used in a wide range of applications, from manufacturing and logistics (e.g., scheduling production and delivery) to robotics (e.g., path planning for robots) and game playing (e.g., chess and video games).
Challenges: Challenges in AI planning include dealing with large search spaces, handling uncertainty, addressing resource constraints, and optimizing plans for efficiency and performance.
AI planning is a critical component in creating intelligent systems that can autonomously make decisions and solve complex problems. Lecture: Automata
Lecture: AutomataMarina Santini
╠²
The document provides an introduction to automata theory and finite state automata (FSA). It defines an automaton as an abstract computing device or mathematical model used in computer science and computational linguistics. The reading discusses pioneers in automata theory like Alan Turing and his development of Turing machines. It then gives an overview of finite state automata, explaining concepts like states, transitions, alphabets, and using a example of building an FSA for a "sheeptalk" language to demonstrate these components.Simulated Annealing
Simulated AnnealingJoy Dutta
╠²
SA is a global optimization technique.
It distinguishes between different local optima.
It is a memory less algorithm & the algorithm does not use any information gathered during the search.
SA is motivated by an analogy to annealing in solids.
& it is an iterative improvement algorithm.
Segmentation in operating systems
Segmentation in operating systemsDr. Jasmine Beulah Gnanadurai
╠²
This document discusses segmentation in operating systems. Segmentation divides memory into variable-sized segments rather than fixed pages. Each process is divided into segments like the main program, functions, variables, etc. There are two types of segmentation: virtual memory segmentation which loads segments non-contiguously and simple segmentation which loads all segments together at once but non-contiguously in memory. Segmentation uses a segment table to map the two-part logical address to the single physical address through looking up the segment base address.Topological Sorting
Topological SortingShahDhruv21
╠²
It is related to Analysis and Design Of Algorithms Subject.Basically it describe basic of topological sorting, it's algorithm and step by step process to solve the example of topological sort.Viewers also liked (7)
Chapter13
Chapter13gourab87
╠²
The document discusses various topics related to secondary storage and file organization in databases:
1) Secondary storage devices like magnetic disks are used to permanently store large databases and provide high storage capacity compared to main memory.
2) Files are organized on disks using various methods like heap files, sorted files, and hashing to allow efficient retrieval, insertion, and deletion of records.
3) RAID (Redundant Array of Independent Disks) technology improves disk performance using data striping across multiple disks and reliability using disk mirroring.Application of Stack - Yadraj Meena
Application of Stack - Yadraj MeenaDipayan Sarkar
╠²
The document discusses stacks and their applications. It provides 3 key points:
1. A stack is an abstract data type that follows LIFO (last-in, first-out) principles with push and pop operations. Functions like stack_full and stack_empty are used to implement stacks.
2. Stacks have applications in converting infix notation to postfix notation and evaluating postfix expressions. The algorithms pop and push operators and operands to produce the postfix form or calculate values.
3. Examples show converting the infix expression (A * B + (C - D / E)) to postfix AB*C(D-F/)++ and evaluating the postfix form of True, False, NOT, AND,stack presentation
stack presentationShivalik college of engineering
╠²
The document introduces stacks and discusses their implementation and applications. It defines a stack as a data structure that follows LIFO order, where elements can only be added and removed from one end. Stacks have two main implementations - using arrays and linked lists. Common applications of stacks include undo/redo in editors, browser history, and evaluating postfix expressions.Computer ethics
Computer ethicsonur karaman
╠²
Computer ethics deals with how computing professionals should make ethical decisions regarding professional and social conduct. It originated in the 1950s when Norbert Wiener published a book laying the foundations of computer ethics. Copyright laws are designed to protect intellectual property like computer codes and digital content from being stolen or used without permission. Some basic rules of computer ethics are to not harm others, steal information, access files without permission, copy copyrighted software, misuse internet resources, or use other users' computers without consent.Seminar algorithms of web
Seminar algorithms of webStefanos Anastasiadis
╠²
This document outlines the organization of a seminar on algorithms of the internet. It provides motivation for studying internet algorithms and how crises have spurred algorithmic solutions. The goals of the seminar are for students to research literature, write a survey, and give presentations. Topics covered include mobile networks, peer-to-peer networks, web caching, search engines, internet structure, security, denial of service attacks, viruses/spam, epidemic algorithms, DNS, TCP bandwidth allocation, routing, broadcasting, and the self-organization of the internet. Students will complete two presentations and a 5-10 page written survey assignment on their selected topic.Stack implementation using c
Stack implementation using cRajendran
╠²
This section presents a simple non-abstract data type (non-ADT) implementation of a stack in C by developing a program that inserts random characters into a stack and then prints them out. It then discusses the stack abstract data type (ADT) by covering the stack structure, its application interface, and developing the required ADT functions.4.4 external hashing
4.4 external hashingKrish_ver2
╠²
This document discusses extendible hashing, which is a hashing technique for dynamic files that allows efficient insertion and deletion of records. It works by using a directory to map hash values to buckets, and dynamically expanding the directory size and number of buckets as needed to accommodate new records. When a bucket overflows, it is split into two buckets, and the directory is expanded to distinguish them. The directory size can also be contracted when buckets can be combined due to deletions. Alternative approaches like dynamic hashing and linear hashing that address the same problem of dynamic files are also overviewed.Recently uploaded (7)

┘ģ┘ä┘ü│Õž│┘Ŗž¦┘é│Õž¦┘äžó┘Ŗž¦ž¬│Õž¦┘äž▓└Ąž▒ž¦┘ł┘Ŗ┘å│Õ(ž¦┘äž©┘éž▒ž®│Õžó┘ä│Õž╣┘ģž▒ž¦┘å)
┘ģ┘ä┘ü│Õž│┘Ŗž¦┘é│Õž¦┘äžó┘Ŗž¦ž¬│Õž¦┘äž▓└Ąž▒ž¦┘ł┘Ŗ┘å│Õ(ž¦┘äž©┘éž▒ž®│Õžó┘ä│Õž╣┘ģž▒ž¦┘å)Qalb Salim T'alim Qur'an
╠²
ž│┘Ŗž¦┘é ž¦┘äžó┘Ŗž¦ž¬ ┘ü┘Ŗ ž¦┘äž▓┘ćž▒ž¦┘ł┘Ŗ┘å ž¬ž│ž¦ž╣ž» ž╣┘ä┘ē ž¬ž»ž©ž▒ ž¦┘äžó┘Ŗž¦ž¬ ┘łž¬ž½ž©┘Ŗž¬ ž¦┘䞣┘üžĖ ┘ģ┘ä┘ü ž¼ž¦┘ćž▓ ┘䞣┘ä┘鞦ž¬ ž¦┘䞬žŁ┘ü┘ŖžĖ ┘łž»┘łž▒ ž¦┘ä┘éž▒žó┘å ž¦┘ä┘āž▒┘Ŗ┘ģ
┘ä┘ģž¬ž¦ž©ž╣ž® ž»ž▒┘łž│ ž¦┘䞬ž»ž©ž▒ ž╣┘ä┘ē ┘é┘垦ž® ž¦┘ä┘Ŗ┘łž¬┘Ŗ┘łž©
https://www.youtube.com/@qalbosalim┘ģž¬ž┤ž¦ž©┘枦ž¬ ž│┘łž▒ž® ž¦┘ä┘å┘ģ┘ä ┘ģž╣ ┘å┘üž│┘枦 ž¦┘łž¦ž”┘ä ┘ł┘ģ┘垬žĄ┘ü ┘łžŻ┘łžóž«ž▒ž¦┘䞦┘Ŗž¦ž¬
┘ģž¬ž┤ž¦ž©┘枦ž¬ ž│┘łž▒ž® ž¦┘ä┘å┘ģ┘ä ┘ģž╣ ┘å┘üž│┘枦 ž¦┘łž¦ž”┘ä ┘ł┘ģ┘垬žĄ┘ü ┘łžŻ┘łžóž«ž▒ž¦┘䞦┘Ŗž¦ž¬Qalb Salim T'alim Qur'an
╠²
┘ģž¬ž┤ž¦ž©┘枦ž¬ ž¦┘ä┘éž▒žó┘å ž¬ž│ž¦ž╣ž» ž╣┘ä┘ē ž¦┘ä┘ģž▒ž¦ž¼ž╣ž® ┘łž¬ž½ž©┘Ŗž¬ ž¦┘䞣┘üžĖ ┘ģ┘ä┘ü ž¼ž¦┘ćž▓ ┘äž│┘łž▒ž® ž¦┘ä┘å┘ģ┘ä ┘䞣┘ä┘鞦ž¬ ž¦┘䞬žŁ┘ü┘ŖžĖ ┘łž»┘łž▒ ž¦┘ä┘éž▒žó┘å ž¦┘ä┘āž▒┘Ŗ┘ģ
┘ä┘ģž¬ž¦ž©ž╣ž® ž»ž▒┘łž│ ž¦┘䞬ž»ž©ž▒ ž╣┘ä┘ē ┘é┘垦ž® ž¦┘ä┘Ŗ┘łž¬┘Ŗ┘łž©
https://www.youtube.com/@qalbosalim
Presentaci├│n Universitaria Trabajo de Fin de Grado Geom├®trico Minimalista Cre...
Presentaci├│n Universitaria Trabajo de Fin de Grado Geom├®trico Minimalista Cre...MirandaGonzlez12
╠²
Plantilla para TesisComprehensive Dictionary Of Ket Elizaveta Kotorova Andrey Nefedov Eds
Comprehensive Dictionary Of Ket Elizaveta Kotorova Andrey Nefedov Edswadudehnot0t
╠²
Comprehensive Dictionary Of Ket Elizaveta Kotorova Andrey Nefedov Eds
Comprehensive Dictionary Of Ket Elizaveta Kotorova Andrey Nefedov Eds
Comprehensive Dictionary Of Ket Elizaveta Kotorova Andrey Nefedov EdsEssentials Of Vascular Surgery For The General Surgeon 1st Edition Vivian Gahtan
Essentials Of Vascular Surgery For The General Surgeon 1st Edition Vivian Gahtankrkgtkuyp896
╠²
Essentials Of Vascular Surgery For The General Surgeon 1st Edition Vivian Gahtan
Essentials Of Vascular Surgery For The General Surgeon 1st Edition Vivian Gahtan
Essentials Of Vascular Surgery For The General Surgeon 1st Edition Vivian Gahtan┘ģž¬ž┤ž¦ž©└Ąž¦ž¬│Õ┘ģ┘å│Õž│┘łž▒ž®│Õž¦┘ä┘üž¦ž¬žŁž®│Õžź┘ä┘ē│Õ│Õž│┘łž▒ž®│Õž¦┘ä┘ģž¦ž”ž»ž®
┘ģž¬ž┤ž¦ž©└Ąž¦ž¬│Õ┘ģ┘å│Õž│┘łž▒ž®│Õž¦┘ä┘üž¦ž¬žŁž®│Õžź┘ä┘ē│Õ│Õž│┘łž▒ž®│Õž¦┘ä┘ģž¦ž”ž»ž®Qalb Salim T'alim Qur'an
╠²
┘ģž¬ž┤ž¦ž©┘枦ž¬ ž¦┘ä┘éž▒žó┘å ž¬ž│ž¦ž╣ž» ž╣┘ä┘ē ž¦┘ä┘ģž▒ž¦ž¼ž╣ž® ┘łž¬ž½ž©┘Ŗž¬ ž¦┘䞣┘üžĖ ┘ģ┘ä┘ü ž¼ž¦┘ćž▓┘ģž¬ž┤ž¦ž©└Ąž¦ž¬│Õ┘ģ┘å│Õž│┘łž▒ž®│Õž¦┘ä┘üž¦ž¬žŁž®│Õžź┘ä┘ē│Õ│Õž│┘łž▒ž®│Õž¦┘ä┘ģž¦ž”ž»ž® ┘䞣┘ä┘鞦ž¬ ž¦┘䞬žŁ┘ü┘ŖžĖ ┘łž»┘łž▒ ž¦┘ä┘éž▒žó┘å ž¦┘ä┘āž▒┘Ŗ┘ģ
┘ģ┘ä┘ü│Õž│┘Ŗž¦┘é│Õž¦┘äžó┘Ŗž¦ž¬│Õž¦┘äž▓└Ąž▒ž¦┘ł┘Ŗ┘å│Õ(ž¦┘äž©┘éž▒ž®│Õžó┘ä│Õž╣┘ģž▒ž¦┘å)
┘ģ┘ä┘ü│Õž│┘Ŗž¦┘é│Õž¦┘äžó┘Ŗž¦ž¬│Õž¦┘äž▓└Ąž▒ž¦┘ł┘Ŗ┘å│Õ(ž¦┘äž©┘éž▒ž®│Õžó┘ä│Õž╣┘ģž▒ž¦┘å)Qalb Salim T'alim Qur'an
╠²
┘ģž¬ž┤ž¦ž©┘枦ž¬ ž│┘łž▒ž® ž¦┘ä┘å┘ģ┘ä ┘ģž╣ ┘å┘üž│┘枦 ž¦┘łž¦ž”┘ä ┘ł┘ģ┘垬žĄ┘ü ┘łžŻ┘łžóž«ž▒ž¦┘䞦┘Ŗž¦ž¬
┘ģž¬ž┤ž¦ž©┘枦ž¬ ž│┘łž▒ž® ž¦┘ä┘å┘ģ┘ä ┘ģž╣ ┘å┘üž│┘枦 ž¦┘łž¦ž”┘ä ┘ł┘ģ┘垬žĄ┘ü ┘łžŻ┘łžóž«ž▒ž¦┘䞦┘Ŗž¦ž¬Qalb Salim T'alim Qur'an
╠²
Presentaci├│n Universitaria Trabajo de Fin de Grado Geom├®trico Minimalista Cre...
Presentaci├│n Universitaria Trabajo de Fin de Grado Geom├®trico Minimalista Cre...MirandaGonzlez12
╠²
┘ģž¬ž┤ž¦ž©└Ąž¦ž¬│Õ┘ģ┘å│Õž│┘łž▒ž®│Õž¦┘ä┘üž¦ž¬žŁž®│Õžź┘ä┘ē│Õ│Õž│┘łž▒ž®│Õž¦┘ä┘ģž¦ž”ž»ž®
┘ģž¬ž┤ž¦ž©└Ąž¦ž¬│Õ┘ģ┘å│Õž│┘łž▒ž®│Õž¦┘ä┘üž¦ž¬žŁž®│Õžź┘ä┘ē│Õ│Õž│┘łž▒ž®│Õž¦┘ä┘ģž¦ž”ž»ž®Qalb Salim T'alim Qur'an
╠²
Extendible hashing
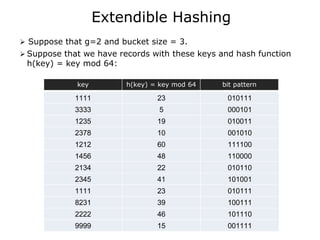
- 1. Extendible Hashing ’āś Suppose that g=2 and bucket size = 3. ’āś Suppose that we have records with these keys and hash function h(key) = key mod 64: 1111 23 010111 3333 5 000101 1235 19 010011 2378 10 001010 1212 60 111100 1456 48 110000 2134 22 010110 2345 41 101001 1111 23 010111 8231 39 100111 2222 46 101110 9999 15 001111 key h(key) = key mod 64 bit pattern
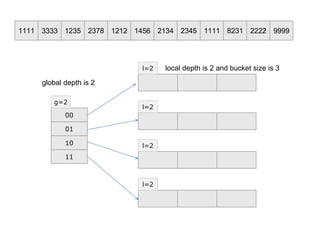
- 2. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 00 01 10 11 g=2 l=2 l=2 l=2 l=2 global depth is 2 local depth is 2 and bucket size is 3
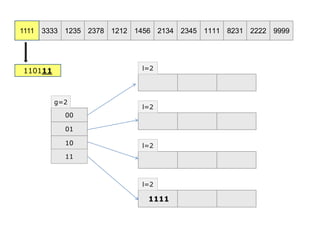
- 3. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 00 01 10 11 g=2 l=2 l=2 l=2 l=2 1111 110111 11 1111
- 4. 000101 00 01 10 11 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 g=2 l=2 l=2 l=2 1111 l=2 3333 01 3333
- 5. 00 01 10 11 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 g=2 l=2 3333 l=2 l=2 1111 l=2 1235 010011 1235 11
- 6. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 00 01 10 11 g=2 1212 1456 l=2 3333 2345 l=2 2378 2134 l=2 1111 1235 1111 l=2
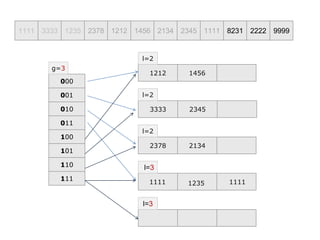
- 7. 00 01 10 11 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 g=2 1212 1456 l=2 3333 2345 l=2 2378 2134 l=2 1111 1235 1111 l=2 8231 100111 11 Bucket overflow occurs. As g = l, directory structure is doubled.
- 8. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 00 01 10 11 g=3 1212 1456 l=2 3333 2345 l=2 2378 2134 l=2 1111 1235 1111 l=2 00 01 10 11
- 9. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 000 001 010 011 g=3 1212 1456 l=2 3333 2345 l=2 2378 2134 l=2 l=2 100 101 110 111 l=3 l=3 1111 1235 1111
- 10. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 000 001 010 011 g=3 1212 1456 l=2 3333 2345 l=2 2378 2134 l=2 1235 l=2 100 101 110 111 1111 1111 l=3 l=3 8231 100111 111 8231
- 11. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 000 001 010 011 g=3 1212 1456 l=2 3333 2345 l=2 2378 2134 l=2 1235 l=2 100 101 110 111 1111 1111 8211 l=3 l=3 2222 101110 110 2222
- 12. 1111 3333 1235 2378 1212 1456 2134 2345 1111 8231 2222 9999 000 001 010 011 g=3 1212 1456 l=2 3333 2345 l=2 2378 2134 l=2 1235 l=2 100 101 110 111 1111 1111 8211 l=3 l=3 9999 001111 111 Bucket overflow occurs again. As g = l, directory structure should be doubled again and same process will repeat.