Feature scaling
âĒDownload as PPTX, PDFâĒ
1 likeâĒ290 views

The document discusses why feature scaling is required for machine learning algorithms like k-nearest neighbors, k-means clustering, and principal component analysis. It explains that different features can have very different value ranges, which can cause issues for distance-based algorithms. Feature scaling methods like standardization and normalization are presented to rescale features to a common range like -1 to 1 or 0 to 1, to avoid any one feature from dominating the distance calculations due to its original scale. Examples are shown applying standardization and normalization to 'Age' and 'Salary' features from sample data.






Feature scaling
- 1. WhyFeatureScaling Required Copyright ÂĐ Cognitior www.cognitior.com
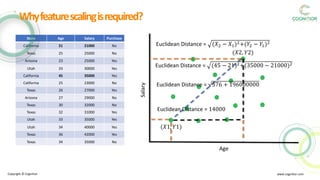
- 2. State Age Salary Purchase California 21 21000 No Texas 25 25000 No Arizona 23 25000 Yes Utah 33 30000 Yes California 45 35000 Yes California 25 23000 No Texas 26 27000 Yes Arizona 27 29000 No Texas 30 32000 No Texas 32 31000 Yes Utah 33 35000 Yes Utah 34 40000 Yes Texas 36 42000 Yes Texas 34 35000 No Copyright ÂĐ Cognitior www.cognitior.com Whyfeaturescalingisrequired? Age Salary (ð1, ð1) (ð2, ð2) Euclidean Distance = (ð2 â ð1)2+(ð2 â ð1)2 Euclidean Distance = (45 â 21)2+(35000 â 21000)2 Euclidean Distance = 576 + 196000000 Euclidean Distance = 14000
- 3. Copyright ÂĐ Cognitior www.cognitior.com âĒ K-Nearest Neighbour âĒ K-Means Whyfeaturescalingisrequired? âĒ Principal Component Analysis (PCA)
- 4. Copyright ÂĐ Cognitior www.cognitior.com Howcanweimplementfeaturescaling? âĒ Standardization âĒ Normalization ðŋ ððð = ðŋð â ðŋ ððð ðŋ ððð â ðŋ ððð ðŋ ððð = ðŋð â ðŋ ðððð ð ðŋ
- 5. State Age Salary Purchase California 21 21000 No Texas 25 25000 No Arizona 23 25000 Yes Utah 33 30000 Yes California 45 35000 Yes California 25 23000 No Texas 26 27000 Yes Arizona 27 29000 No Texas 30 32000 No Texas 32 31000 Yes Utah 33 35000 Yes Utah 34 40000 Yes Texas 36 42000 Yes Texas 34 35000 No Copyright ÂĐ Cognitior www.cognitior.com Standardization ðŋ ððð = ðŋð â ðŋ ðððð ð ðŋ ðŋ ðððð (ðĻðð) = ðð. ðð ð ð (ðĻðð) = ð. ðð STD Age -1.53 -0.87 -1.2 0.45 2.42 -0.87 -0.7 -0.54 -0.05 0.28 0.45 0.61 0.94 0.61 STD Salary -1.61 -0.95 -0.95 -0.12 0.71 -1.28 -0.62 -0.28 0.21 0.05 0.71 1.54 1.88 0.71 ðŋ ðððð (ðšððððð) = ððððð. ðð ð ð (ðšððððð) = ðððð. ðð
- 6. State Age Salary Purchase California 21 21000 No Texas 25 25000 No Arizona 23 25000 Yes Utah 33 30000 Yes California 45 35000 Yes California 25 23000 No Texas 26 27000 Yes Arizona 27 29000 No Texas 30 32000 No Texas 32 31000 Yes Utah 33 35000 Yes Utah 34 40000 Yes Texas 36 42000 Yes Texas 34 35000 No Copyright ÂĐ Cognitior www.cognitior.com Normalization ðŋ ððð(ðĻðð) = ðð ðŋ ððð(ðĻðð) = ðð STD Age 0 0.17 0.08 0.5 1 0.17 0.21 0.25 0.38 0.46 0.5 0.54 0.63 0.54 STD Salary 0.00 0.19 0.19 0.43 0.67 0.10 0.29 0.38 0.52 0.48 0.67 0.90 1.00 0.67 ðŋ ððð(ðšððððð) = ððððð ðŋ ððð(ðšððððð) = ððððð ðŋ ððð = ðŋð â ðŋ ððð ðŋ ððð â ðŋ ððð
- 7. ThankYou!!! AnyQuestions? support@cognitior.com Copyright ÂĐ Cognitior www.cognitior.com
Editor's Notes
- #3: Missing data in the training data set can reduce the power / fit of a model or can lead to a biased model because we have not analysed the behaviour and relationship with other variables correctly. It can lead to wrong prediction or classification.
- #4: 1. K-Means uses the Euclidean distance measure here feature scaling matters. 2. K-Nearest-Neighbours also require feature scaling. 3. Principal Component Analysis (PCA): Tries to get the feature with maximum variance, here too feature scaling is required.