





![Main Cluster Components
• Replication Ops Cache: reuse FileJournal(As for
now, we have only considered FileStore)
• Introduce to journal header: op_replication_head,
op_replication_tail; op_replication_tail -
op_replication_head journal_replication_threshold. If
journal_head hits op_replication_tail, move it to
op_replication_head + 1. Only journal entries outside
[journal_head,Journal_tail]U[op_replication_head,
op_replication_tail] can be removed
• Introduce to journal entry: need_replicate, indicating that
this op needs to be replicated.](https://image.slidesharecdn.com/radoslevelreplication-180207084419/85/Feb-7th-CDM-8-320.jpg)









Feb 7th CDM
- 2. ISSUES • The Overall Architecture • Main cluster implementation • Backup Cluster implementation
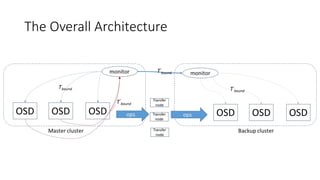
- 4. The Overall Architecture • Implementation Principals: • Modify the current system as less as possible and reuse the current system components as much as possible • Make as little impact on the performance of other system components as possible
- 5. ISSUES • The Whole Architecture • Main cluster implementation • Backup Cluster implementation
- 6. Main Cluster Components • Classification of Ops • Ops issued by clients(librados ops); • Ops issued by other OSDs(repops); Only ops issued by clients needs to be replicated. • Main Difficulties: • Deal with various situations that replication can not go on. • Solutions: later sections • Preserve ops’ order in replication when osdmap changes • Solution: • Make sure replication journal(FileJournal) entries for the ops needing to be replicated are considered removable only when the corresponding replication is finished • During the recovery/backfill phase, make sure an object gets recovered only when all original ops targeting it gets replicated
- 7. Main Cluster Components • REPLICATION SUSPEND • If there are, in the acting set of a pg, enough OSDs whose “replication ops cache” is full, then replication of ops targeting that pg should be suspended, and also, monitors should suspend sendint out “snapshot notifications” • If the backup cluster is “replication full”, suspend the replication. • SNAPSHOT NOTIFICATION SUSPEND • When REPLICATION SUSPEND condition is met, snapshot notification should also be suspended; • When the system clocks of all OSDs in a pg’s acting set are out-of-sync, snapshot notification should be suspended;
- 8. Main Cluster Components • Replication Ops Cache: reuse FileJournal(As for now, we have only considered FileStore) • Introduce to journal header: op_replication_head, op_replication_tail; op_replication_tail - op_replication_head journal_replication_threshold. If journal_head hits op_replication_tail, move it to op_replication_head + 1. Only journal entries outside [journal_head,Journal_tail]U[op_replication_head, op_replication_tail] can be removed • Introduce to journal entry: need_replicate, indicating that this op needs to be replicated.
- 9. Main Cluster Components • New flags in Object Info: • need_replicate: set/unset by clients, indicating whether ops targeting this object need to be replicated; • need_full_replication: set/unset by osd, indicating whether there were ops targeting this object not replicated because of "REPLICATION SUSPEND” condition. • New module “ReplicationWorker” • Conceptually comprised of a cache used to store ops to be replicated and a working thread that continuously replicate those ops targeting pgs of which the current OSD is acting primary. • ReplicationWorker remove ops when they are replicated(a “commit” message is received from OSDs in the backup cluster or a “can remove” message is received from their acting primaries) and move forward journal’s pointer op_replication_tail(op_replication_head is moved forward by OSD’s work thread) • When an op is replicated, ReplicationWorker should also send a “can remove” message to its pg’s other OSDs.
- 10. Main Cluster Components • Replication Robustness • New configuration item “replication_min_size”: the least number of OSDs that should hold the replica of “librados ops” while the replication of it is not complete yet • Replica OSDs should encapsulate a flag indicating whether “op_replication_tail” is moved forward by a repop in the reply to that repop • If less than “replication_min_size” OSDs has moved forward their “op_replication_tail”, then the pg should be marked as “replicaton full” and all subsequent “librados ops” can’t be replicated until that mark is cleared • When an OSD’s “replication ops cache” is left with enough space, a message should be sent to all acting primarys who has a common pg with it, when OSDs capable of caching “librados ops” for replication are enough, the pg’s “replication full” mark is cleared
- 11. Main Cluster Components • Replication Robustness • For the purpose of better performance, acting primary doesn’t need to wait for the repop reply, all target objects are marked as “need_full_replication”, and are all cleared of that mark when the “librados op” is replicated. • When a “librados op”’s replication is done, the replication executing OSD send out “replication succeeded” message for that op to other OSDs in acting set. • Replication is done by the first OSD that has enough “Replication Ops Cache” in the acting set which is actually a list. This decision is made by acting primary. • New field in PG INFO: • need_full_replication_set: a bloom filter that filters out objects that are definitely not marked as “need_full_replication”
- 12. Main Cluster Components • Peering/Recovery/Backfill procedure • The only thing that need to be add to this procedure is that an object’s recovery source should replicate all “librados ops” before pushing that object
- 13. ISSUES • The Whole Architecture • Main cluster implementation • Backup Cluster implementation
- 14. Backup Cluster Implementation • Main Difficulty: • Assuring efficient replication ops caching and efficient recovery when osdmap changes. • Solution: • Add an additional processing step for replication op processing between ops journaling and ops applying: raw ops storing • In the “raw ops storing” phase, a three tuple <timestamp, object_id, op> is stored in Rocksdb • Ops applying happens when the backup cluster’s monitor receives an “snapshot notification” that tells replication ops earlier that certain time point can be merged to the backing store.
- 15. Backup Cluster Implementation • Solution: • Adding a “raw ops storing” phase is for the reason that, when doing “recovery/backfill”, both unmerged ops and the target object need to be recovered and storing the three tuple <timestamp, object_id, op> in Rocksdb can make the query like “what ops need to be recovered for a certain object” more efficient. • NOTE: only “replication ops” need the “raw ops storing” phase.
- 16. Backup Cluster Implementation • In-memory cache(FileStore::op_wq) • To make the “ops applying” more efficient, there should be a new thread that keep feeding the FileStore::op_wq with replication ops stored in Rocksdb in “raw ops storing” phase. • FileStore::op_tp should also distinguish the processing of “replication ops” and other ops, since “replication ops” can only be applied when the corresponding “snapshot notification” is received. • Also, “replication ops” targeting the same object should be merged to the greatest extent before applied to the object, which could make the applying phase more efficient and, further, make the whole replication more efficient since the applying phase could probably be the “FINAL” bottleneck of the whole replication mechanism.
- 17. Other Considerations • Clock Synchronization • Planning to use Chrony, since it’s the default clock synchronization tool in recent CentOS releases which is the mostly used Linux distribution. • Adding extra methods that calculate hard error bounds
Editor's Notes
- #11: Like the current pool “min_size”, there should be a configuration item like “replication_min_size” meaning the least number of OSDs that should hold the replica of “librados ops” while the replication of it is not complete yet.