

![ŁhŠ│ż╬ū┤æB s ż╬?ōpżĄżņż┐ėQ£y o (╦└?Ż¼ėøæø?╚ńŻ¼ź▐źļź┴ź©®`źĖź¦ź¾ź╚
ąįĄ╚ż¼įŁę“)ŻĮ ▓╗═Ļ╚½ų¬ęÖå¢Ņ} (Partially Observabl MDP, POMDP)
└² : Montezuma?s Revenge
▓╗═Ļ╚½ų¬ęÖ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
3
µIż“½@Ą├żĘż┐Ą╚ Ī░╦¹ż╬▓┐╬▌żŪ║╬ż“żõż├ż┐ż½Ī▒ ż“ęÖż©żŲżżż╩żżż╚▓╗═Ļ╚½ų¬ęÖ
Ī· ¼FīgŁhŠ│żŪżŽź©®`źĖź¦ź¾ź╚ż¼Ą├żķżņżļŪķł¾ż╩ż╔ż┐ż½ż¼ų¬żņżŲżżżļ
Ī∙ [Bellmare et al., 2012]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-3-320.jpg)


![▓╗═Ļ╚½ų¬ęÖżžż╬īØäI
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
6
ļAīėą═ÅŖ╗»č¦┴Ģ
ÖC─▄ :
? ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż╣żļ (ßß╩÷)
? ėQ£yż╦īØż╣żļ MDP żŪ╩┬?żĻżļ▓┐Ęų (źĄźųź┐ź╣ź») ż“Ž┬╬╗īėż¼ĄŻĄ▒
? źĄźųź┐ź╣ź»ż╬▀xÆkŻ¼▀węŲĒśż“øQżßżļ╔Ž╬╗īėż¼ĄŻĄ▒
? ?ĒśŻ¼ėøæøż“╔Ž╬╗īėż¼?Ą─ęŌūR (ż╬▀węŲ) ż╚żĘżŲÆQżżū┤æBż“Ęųļx
? Ž┬╬╗īėż╬?äė (źĄźųź┐ź╣ź»▀mÅĻ) ż¼╩╣żż╗žż╗żļż╬żŪÜ°╗»ąį─▄ż¼?żż
å¢Ņ}ĄŃ :
? ?┬╔Ą─ż╩źĄźųź┐ź╣ź»ĘųĖŅż¼?│Żż╦└¦ļy
Ī· FeUdal Networks [Vezhnevets et al., 2017]ż╚żżż”źĄźųź┐ź╣ź»ĘųĮŌż“
End-to-End żŪ?ż”źó®`źŁźŲź»ź┴źŃż“ DeepMind ż¼┐╝░Ė](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-6-320.jpg)



![▓╗═Ļ╚½ų¬ęÖżžż╬īØäI (į┘Æ„)
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
10
ļAīėą═ÅŖ╗»č¦┴Ģ
ÖC─▄ :
? ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż╣żļ (ßß╩÷)
? ėQ£yż╦īØż╣żļ MDP żŪ╩┬?żĻżļ▓┐Ęų (źĄźųź┐ź╣ź») ż“Ž┬╬╗īėż¼ĄŻĄ▒
? źĄźųź┐ź╣ź»ż╬▀xÆkŻ¼▀węŲĒśż“øQżßżļ╔Ž╬╗īėż¼ĄŻĄ▒
? ?ĒśŻ¼ėøæøż“╔Ž╬╗īėż¼?Ą─ęŌūR (ż╬▀węŲ) ż╚żĘżŲÆQżżū┤æBż“Ęųļx
? Ž┬╬╗īėż╬?äė (źĄźųź┐ź╣ź»▀mÅĻ) ż¼╩╣żż╗žż╗żļż╬żŪÜ°╗»ąį─▄ż¼?żż
å¢Ņ}ĄŃ :
? ?┬╔Ą─ż╩źĄźųź┐ź╣ź»ĘųĖŅż¼?│Żż╦└¦ļy
Ī· FeUdal Networks [Vezhnevets et al., 2017] ż╚żżż”źĄźųź┐ź╣ź»ĘųĮŌż“
End-to-End żŪ?ż”źó®`źŁźŲź»ź┴źŃż“ DeepMind ż¼┐╝░Ė](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-10-320.jpg)
![Feudal reinforcement learning, FRL [Dayan and Hinton, 1993]
? ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż╣żļ
? Ž┬╬╗ęŌ╦╝øQČ©š▀ Sub-Maneer, ╔Ž╬╗ęŌ╦╝øQČ©š▀ Manager ż╚żżż”
Ė┼─Ņż“╠ß╣®
? FuNs (▒ŠŅ}) ż╬źóźżźŪźŻźóį¬
? Sutton ż╬ÅŖ╗»č¦┴Ģ▒ŠżĶżĻżŌŪ░ż╩ż╬żŪĖ┼─ŅĄ─ż╩żŌż╬ż╦Į³żżŻ┐
FeUdal Networks - ▒│Š░Ė┼─Ņ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
11](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-11-320.jpg)
![Option [Sutton et al., 1999]
? ?Ų┌Ą─ż╩?äė?▓▀ Option (═©│Żż╬?▓▀Ė┼─Ņż╦ goal ū┤æB =
termination condition ż“╝ėż©ż┐żŌż╬) ż╚żĮż╬ Option żĮż╬żŌż╬ż“▀x
Ækż╣żļ policy-over-option ż“ī¦?
? Semi-MDP żžż╬īØäIż¼ų„č█ (ęŌ╦╝øQČ©ż¼»E)
? éĆäeż╬ Option ż╬?┬╔Ą─ż╩č¦┴ĢżŽ▓╗?Ęųż╩é╚?ż¼żóżļ
? ?▌^Ą─╣┼ĄõĄ─ż╩įÆ
Option-Critic [Bacon et al., 2017]
? Option ż“ Deep RL ╗»żĘż┐żŌż╬ (Goal Ė┼─Ņż¼▒ĪżżŻ┐)
? End-to-End żŪč¦┴Ģ┐╔─▄
? ╔Ž╬╗?▓▀ż╚Ž┬╬╗?▓▀ż╬ę█ĖŅż¼╬┤Ęų╗»ż╣żļå¢Ņ}ĄŃż¼┤µį┌
FeUdal Networks - ▒│Š░Ė┼─Ņ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
12](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-12-320.jpg)
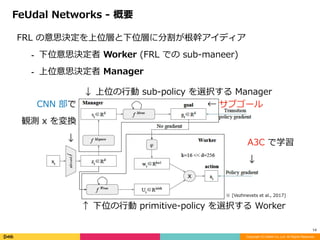
![FRL ż╬ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż¼Ė∙ÄųźóźżźŪźŻźó
? Ž┬╬╗ęŌ╦╝øQČ©š▀ Worker (FRL żŪż╬ sub-maneer)
? ╔Ž╬╗ęŌ╦╝øQČ©š▀ Manager
FeUdal Networks - Ė┼ę¬
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
13
Ī³ Ž┬╬╗ż╬?äė primitive-policy ż“▀xÆkż╣żļ Worker
CNN ▓┐żŪ
ėQ£y x ż“ēõōQ????
Ī²
A3C żŪč¦┴Ģ
Ī²
Ī¹ źĄźųź┤®`źļ
Ī² ╔Ž╬╗ż╬?äė sub-policy ż“▀xÆkż╣żļ Manager
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-13-320.jpg)

![Manager (╔Ž╬╗īė)ė¢ŠÜż╬ż┐żßż╬▀węŲ?▓▀╣┤┼õ :
Worker (Ž┬╬╗īė)ż╚żŽ«Éż╩żļ╣┤┼õż“Č©┴x
Transition policy gradient for the Manager
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
16
Ī∙
Ī∙
Ī³
Manager ż½żķėļż©żķżņżļüóŽļĄ─ż╩ģ¦ęµ
Ī∙ Option-Critic żŽŽ┬╬╗īėż╬ęŌ╦╝øQČ©š▀ż½żķż╬╣┤┼õż“╩╣ż├żŲč¦┴Ģ
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-16-320.jpg)



![ĮY╣¹ - Montezuma?s Revenge
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
20
Ī² ęįŪ░ż╬ĢrŽĄ┴ą│÷?ż╦ż╚ż├żŲ goal ż╦ż╩ż├żŲżļ╩²
Ī¹ ╦žż╬ LSTM żĶżĻ┴╝żż
200 epoch ╬┤£║żŪūŅ│§ż╬▓┐╬▌ż“═╗ŲŲ
(1 epoch = 100═“ step )
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-20-320.jpg)
![ĮY╣¹ - źĄźų?▓▀ż╬┤_šJ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
21
ź┤®`źļ╣╠Č©Ģrż╬äėżŁ :
Manager ż¼ź▓®`źÓųąĮU“YżĘż┐źĄźųź┤®`źļ g ż“ėøæøżĘżŲż¬żŁŻ¼żóż©żŲ╣╠Č©
żĘżŲ?äėżĄż╗żļ╩┬żŪźĄźų?▓▀ż╬äėżŁż“┤_šJżŪżŁżļ
╔Žėøź░źķźŪ®`źĘźńź¾ź▐ź├źūżŽ Agent ż╬┐šķgų═į┌?┬╩ż“ŲĮŠ∙╗»żĘż┐żŌż╬
Ī· «Éż╩żļäėżŁż¼┤_šJżŪżŁżļ
└² : sub-policy 3 żŽ┐šÜ▌ż“ča│õżĘżŲżżżļ
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-21-320.jpg)
![ĮY╣¹ - Option-Critic ż╚ż╬?▌^
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
22
FuNs : Option-Critic :
═¼żĖ End-to-End ż╩ļAīėą═ÅŖ╗»č¦┴Ģ Option-Critic ż╚?▌^żĘżŲ┴╝żż│╔┐ā
═Żų═Ü▌╬Čż╬ Option-Critic ż╦?ż┘żŲŻ¼FuN żŽĖ³ż╦╔Žż¼żĻŠAż▒żŲżżżļ
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-22-320.jpg)
![ĮY╣¹ - źóźżźŪźŻźóż╬š²żĘżĄ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
23
4ĘNż╬?ōpą═ FuN ż╚ż╬?▌^:
Non feudal FuN : ?▓▀╣┤┼õżŪė¢ŠÜŻ¼─┌▓┐ł¾│ĻżŌ╩╣ż’ż╩żż (Option-Criticż╦Į³żż)
Pure feudal FuN : Worker ż╦─┌▓┐ł¾│Ļż“╩╣ż’ż╩żż
Manager via PG FuN : Manager ż“?▓▀╣┤┼õżŪė¢ŠÜ
Absolute goals Fun : Į~īØź┤®`źļż“╩╣? (Š▀╠ÕĄ─ż╩Č©┴xżŽšiż▀żŁżņż╩ż½ż├ż┐)
Ī· ╚½żŲż╦ż¬żżżŲ FuN ż¼ä┘└¹ = 3ż─ż╬źóźżźŪźŻźóż╬ėąä┐ąį
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-23-320.jpg)
![ĮY╣¹ - źóźżźŪźŻźóż╬š²żĘżĄ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
24
Dilated LSTM ż╦ķvż╣żļ?▌^:
No dilation : Manager ż╦═©│Ż LSTM ż“╩╣?
Manager horizon = 1 : c = 1 żŪ Manager ż╚ Dilated LSTM ż“▀\?
Ī· ╚½żŲż╦ż¬żżżŲ FuN ż¼ä┘└¹ = Dilated LSTM ż╬ėąä┐ąį
c = 1 żŪżŌ╔Žż¼ż├żŲżŽżżżļ
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-24-320.jpg)
![ĮY╣¹ - źóźżźŪźŻźóż╬š²żĘżĄ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
25
Dilated LSTM ż╦ķvż╣żļ?▌^:
dLSTM : FuN żŪżŽż╩ż»═©│Żż╬ A3C ż╦Dilated LSTMż╬ż▀ż“╩╣?
Ī· ╗∙▒ŠĄ─ż╦żŽ FuN ż╚ ═©│ŻLSTM ż¼ä┘└¹
= Dilated LSTM żŽ Manager źņź┘źļż└ż½żķėąä┐
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-25-320.jpg)
![ĮY╣¹ - ▄×ęŲżžż╬įćż▀
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
26
Action repeat of 4 ż½żķ Action repeat ¤ożĘżžż╬ųžż▀▄×
?Č©źšźņ®`źÓ╩² (šō?ųążŪżŽ 4 frame) ż╬ķg═¼żĖ?äėż“ż╣żļ═©│Żż╬żõżĻ?
żŪč¦┴ĢżĘż┐ųžż▀ż“Ż¼1 frame ż┤ż╚ż╦?äėż“ęŌ╦╝øQČ©ż╣żļź┐ź╣ź»ż╦▄×?
żĮż╬č¦┴ĢżĘż╩żżżŪż╬│╔┐ā (┴„?ż╦Ė„ĢrķgķvéSźčźķźß®`ź┐żŽ 4 ▒Čż╦ż╣żļ)
Ī· FuN ż╬?żż│╔┐āżŽ Manager żŪč¦┴ĢżĘż┐╔Ž╬╗?▓▀ż╬ėą?ąįż“ęŌ╬Čż╣żļ
Ī· ═¼?ź┐ź╣ź»ż└ż╚ Maneger ż╬Ü°?ąįż╬?żĄż╬į^├„ż╦żŽż╩żķż╩żżÜ▌żŌŻ┐
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-26-320.jpg)
![ĖąŽļ
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
27
End-to-End ż╩źĄźųź┤®`źļą╬│╔
? Į~īØĄ─żŪżŽż╩ż»ŽÓīØĄ─ż╩ź┤®`źļČ©┴x (żóżļĘNż╬╬┤└┤?Ž“ėĶ£y) ż╚żżż”
źóźżźŪźŻźóżŪ│╔żĘż┐ż╬żŽ┼d╬Č╔Ņżż
? ╣╠Č©?Ģrķg c step ż“┐╔ēõ?ż╦żŪżŁżļż╚ż╩ż¬┴╝żż
? ?żżĢrķg?żŪź┤®`źļż“Č©┴xżĘż┐żżł÷║Žżžż╬īØäIż“┐╝ż©żŲ
? ?Ą─šōĄ─ż╦żŽ Option ż╬?ż¼źĄźųź┤®`źļż╚?ż©żļ
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-27-320.jpg)

![ę²??Žū (ź╣źķźżź╔ųą)
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
29
[Vezhnevets et al., 2017] Vezhnevets, A. S., Osindero, S., Schaul, T., Heess, N., Jaderberg, M., Silver, D., and
Kavukcuoglu, K. FeUdal Networks for Hierarchical Reinforcement Learning. ArXiv. Retrieved from http://
arxiv.org/abs/1703.01161 (2017).
[Bellmare et al., 2012] Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M. The arcade learning
environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research. (2012).
[Dayan and Hinton, 1993] Dayan, P., and Hinton, G. E. Feudal reinforcement learning. In NIPS . Morgan
Kaufmann Publishers. (1993).
[Sutton et al., 1999] Sutton, R. S., Precup, D., and Singh, S. Between mdps and semi-mdps: A framework for
temporal abstraction in reinforcement learning. Artificial intelligence. (1999).
[Bacon et al., 2017] Bacon, P. L., Precup, D., and Harb, J. The option-critic architecture. In AAAI. (2017).
[Von Mises©CFisher distribution] https://en.wikipedia.org/wiki/Von_Mises-Fisher_distribution](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-29-320.jpg)
![ĮY╣¹ - ź¬ź▐ź▒
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
30
Water maze żŪīgļHż╦½@Ą├żĄżņż┐?äė :
Staet (Šv)╬╗ų├ż½żķż╬?äėęį═ŌŻ¼═¼żĖ░ļŠČżŪ╗ž▄׿ʿŲ╠Į╦„ż╣żļźĄźų?▓▀ż¼
č¦┴ĢżĄżņżļ
ėęČ╦żŽ goal ż“źķź¾ź└źÓż╦įOČ©Ż¼200step ╣╠Č©żĘżŲč¦┴ĢżĘżŲĄ├żķżņż┐źĄ
źų?▓▀ź▒®`ź╣
Ī∙ [Vezhnevets et al., 2017]](https://image.slidesharecdn.com/abstfuncopy-170724030609/85/FeUdal-Networks-for-Hierarchical-Reinforcement-Learning-30-320.jpg)
FeUdal Networks for Hierarchical Reinforcement Learning
- 1. Copyright (C) DeNA Co.,Ltd. All Rights Reserved. DeNA Co., Ltd. AIźĘź╣źŲźÓ▓┐ AI 蹊┐ķ_░kź░źļ®`źū ╝ūę░ ėė FeUdal Networks for Hierarchical Reinforcement Learning
- 2. ╝ūę░ ėė ╦∙╩¶ : ųĻ╩Į╗ß╔ńźŪźŻ®`?ź©ź╠?ź©®` AI źĘź╣źŲźÓ▓┐ AI 蹊┐ķ_░kź░źļ®` źū │÷? : ¢|Š®ļŖÖC?č¦ (č¦▓┐?▓®?) = ż¬ż┐ż»?č¦ čąŠ┐ : ÅŖ╗»č¦┴Ģ Ż½ ├Ś╔±ĮU?šJų¬ Ī· ź▓®`źÓ AI ķ_░k (DeNA) ? šJų¬żõ├Ś╔±ĮUż╚ÖCąĄč¦┴Ģż“ĮMż▀║Žż’ż╗żŲ╝ā╗éż╩└Ēč¦čąŠ┐żĶżĻīg?Ą─ż╩ ÅŖ╗»č¦┴Ģźóźļź┤źĻź║źÓż“śŗ║BżĘż┐żż ? ?ķgż╬╚ß▄øąįĪ·▓╗═Ļ╚½ų¬ęÖ(żžż╬īØäI)Ī·Ž▐Č©║Ž└ĒąįĪ·Ü°?ąįŻĮļAīėąįŻ┐ ??ĮBĮķ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 2
- 3. ŁhŠ│ż╬ū┤æB s ż╬?ōpżĄżņż┐ėQ£y o (╦└?Ż¼ėøæø?╚ńŻ¼ź▐źļź┴ź©®`źĖź¦ź¾ź╚ ąįĄ╚ż¼įŁę“)ŻĮ ▓╗═Ļ╚½ų¬ęÖå¢Ņ} (Partially Observabl MDP, POMDP) └² : Montezuma?s Revenge ▓╗═Ļ╚½ų¬ęÖ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 3 µIż“½@Ą├żĘż┐Ą╚ Ī░╦¹ż╬▓┐╬▌żŪ║╬ż“żõż├ż┐ż½Ī▒ ż“ęÖż©żŲżżż╩żżż╚▓╗═Ļ╚½ų¬ęÖ Ī· ¼FīgŁhŠ│żŪżŽź©®`źĖź¦ź¾ź╚ż¼Ą├żķżņżļŪķł¾ż╩ż╔ż┐ż½ż¼ų¬żņżŲżżżļ Ī∙ [Bellmare et al., 2012]
- 4. ū┤æB b ?äė2ū┤æB a?äė 1 ėQ£yū┤æB? ▓╗═Ļ╚½ų¬ęÖżžż╬å¢Ņ} Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 4 POMDP ż¼└¦ļyż╩└Ēė╔ż╬?ż─żŽėQ£yż╦īØż╣żļšµż╬ū┤æBż╬╗ņ═¼ Ī· ?äėż╬▀xÆk┤_┬╩ ”ą żŽėQ£yū┤æBż╦īØżĘ?ęŌżĘż½│ųżŲż╩żż╩┬ ū┤æB b ?äė2ū┤æB a?äė 1 ėQ£yū┤æB? ▒Š└┤ū¾ż╦?ż»ż┘żŁū┤æB a ▒Š└┤ėęż╦?ż»ż┘żŁū┤æB b Ī· ║╬żķż½ż╬?Ę©żŪĘųļxżĘżŲżõżņżą┴╝żż
- 5. ═Ļ╚½ėøæø ÖC─▄ : ? │§Ų┌ū┤æBż½żķ╚½żŲż╬ū┤æB▀węŲż“ėøæøż╣żļ╩┬żŪ Ī░▒Š└┤«Éż╩żļū┤æBĪ▒ ż“Ęųļx å¢Ņ}ĄŃ : ? ╚½żŲż╬┬─Üsż“ęÖż©żŲżżżļż╬żŽ¼FīgĄ─ż╦▓╗┐╔─▄ ? ╦└?żõ╦¹ź©®`źĖź¦ź¾ź╚ż╬─┌▓┐ū┤æBżŽż╔ż┴żķż╦ż╗żĶå¢Ņ} ? LSTM Ą╚ż“╩╣ż├żŲżŌå¢Ņ}ż¼ĮŌøQż╣żļż’ż▒żĖżŃż╩żż ? šµ??ż╦żõżļż╚ū┤æB╩²ż¼╚▌ęūż╦▒¼░kż╣żļ (ż½ż─Ü°╗»żĄżņż╩żż) ? ū┤æBĖ┼─Ņż¼č}ļjż╦ż╩żĻł¾│Ļż╩ż╔ż╬½@Ą├Ūķł¾ż¼ŁhŠ│╚½╠Õż╦īØżĘżŲź╣źč®` ź╣ż╦ż╩żĻżõż╣żż (ÅŖ╗»č¦┴Ģ╚½░Ńż╬å¢Ņ}ż“╝ė╦┘żĄż╗żļ) ▓╗═Ļ╚½ų¬ęÖżžż╬īØäI Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 5
- 6. ▓╗═Ļ╚½ų¬ęÖżžż╬īØäI Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 6 ļAīėą═ÅŖ╗»č¦┴Ģ ÖC─▄ : ? ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż╣żļ (ßß╩÷) ? ėQ£yż╦īØż╣żļ MDP żŪ╩┬?żĻżļ▓┐Ęų (źĄźųź┐ź╣ź») ż“Ž┬╬╗īėż¼ĄŻĄ▒ ? źĄźųź┐ź╣ź»ż╬▀xÆkŻ¼▀węŲĒśż“øQżßżļ╔Ž╬╗īėż¼ĄŻĄ▒ ? ?ĒśŻ¼ėøæøż“╔Ž╬╗īėż¼?Ą─ęŌūR (ż╬▀węŲ) ż╚żĘżŲÆQżżū┤æBż“Ęųļx ? Ž┬╬╗īėż╬?äė (źĄźųź┐ź╣ź»▀mÅĻ) ż¼╩╣żż╗žż╗żļż╬żŪÜ°╗»ąį─▄ż¼?żż å¢Ņ}ĄŃ : ? ?┬╔Ą─ż╩źĄźųź┐ź╣ź»ĘųĖŅż¼?│Żż╦└¦ļy Ī· FeUdal Networks [Vezhnevets et al., 2017]ż╚żżż”źĄźųź┐ź╣ź»ĘųĮŌż“ End-to-End żŪ?ż”źó®`źŁźŲź»ź┴źŃż“ DeepMind ż¼┐╝░Ė
- 7. ▒ŠŅ} : FeUdal Networks (FuN) ż╬Ū░ż╦ ļAīėą═ÅŖ╗»č¦┴Ģż╬źżźß®`źĖż“╔┘żĘ ļAīėą═ÅŖ╗»č¦┴Ģ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 7
- 8. ═©│Ż(?ļAīėą═)ż╬ÅŖ╗»č¦┴Ģźżźß®`źĖ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 8 ╝Üż½ż╩ęŌ╦╝øQČ© źūźĻź▀źŲźŻźųż╩?äė : a ?▓▀ : ”ą(a;s)
- 9. ļAīėą═ÅŖ╗»č¦┴Ģźżźß®`źĖ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 9 ╝Üż½ż╩ęŌ╦╝øQČ© źūźĻź▀źŲźŻźųż╩?äė : a ?ż▐ż½ż╩ęŌ╦╝øQČ© ?Ą─ųĖŽ“ : g Ž┬╬╗īė?▓▀ : ”ą(a;s,g) ╔Ž╬╗īė?▓▀ : ”ągoal(g;s) Ž┬╬╗īė?▓▀ ż“▀xÆk (g ż╚żĘżŲ) Ī┴ č}╩² įć?Õeš`ż½ żķ╔Ž╬╗īė? ▓▀ż“?│╔Ż┐
- 10. ▓╗═Ļ╚½ų¬ęÖżžż╬īØäI (į┘Æ„) Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 10 ļAīėą═ÅŖ╗»č¦┴Ģ ÖC─▄ : ? ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż╣żļ (ßß╩÷) ? ėQ£yż╦īØż╣żļ MDP żŪ╩┬?żĻżļ▓┐Ęų (źĄźųź┐ź╣ź») ż“Ž┬╬╗īėż¼ĄŻĄ▒ ? źĄźųź┐ź╣ź»ż╬▀xÆkŻ¼▀węŲĒśż“øQżßżļ╔Ž╬╗īėż¼ĄŻĄ▒ ? ?ĒśŻ¼ėøæøż“╔Ž╬╗īėż¼?Ą─ęŌūR (ż╬▀węŲ) ż╚żĘżŲÆQżżū┤æBż“Ęųļx ? Ž┬╬╗īėż╬?äė (źĄźųź┐ź╣ź»▀mÅĻ) ż¼╩╣żż╗žż╗żļż╬żŪÜ°╗»ąį─▄ż¼?żż å¢Ņ}ĄŃ : ? ?┬╔Ą─ż╩źĄźųź┐ź╣ź»ĘųĖŅż¼?│Żż╦└¦ļy Ī· FeUdal Networks [Vezhnevets et al., 2017] ż╚żżż”źĄźųź┐ź╣ź»ĘųĮŌż“ End-to-End żŪ?ż”źó®`źŁźŲź»ź┴źŃż“ DeepMind ż¼┐╝░Ė
- 11. Feudal reinforcement learning, FRL [Dayan and Hinton, 1993] ? ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż╣żļ ? Ž┬╬╗ęŌ╦╝øQČ©š▀ Sub-Maneer, ╔Ž╬╗ęŌ╦╝øQČ©š▀ Manager ż╚żżż” Ė┼─Ņż“╠ß╣® ? FuNs (▒ŠŅ}) ż╬źóźżźŪźŻźóį¬ ? Sutton ż╬ÅŖ╗»č¦┴Ģ▒ŠżĶżĻżŌŪ░ż╩ż╬żŪĖ┼─ŅĄ─ż╩żŌż╬ż╦Į³żżŻ┐ FeUdal Networks - ▒│Š░Ė┼─Ņ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 11
- 12. Option [Sutton et al., 1999] ? ?Ų┌Ą─ż╩?äė?▓▀ Option (═©│Żż╬?▓▀Ė┼─Ņż╦ goal ū┤æB = termination condition ż“╝ėż©ż┐żŌż╬) ż╚żĮż╬ Option żĮż╬żŌż╬ż“▀x Ækż╣żļ policy-over-option ż“ī¦? ? Semi-MDP żžż╬īØäIż¼ų„č█ (ęŌ╦╝øQČ©ż¼»E) ? éĆäeż╬ Option ż╬?┬╔Ą─ż╩č¦┴ĢżŽ▓╗?Ęųż╩é╚?ż¼żóżļ ? ?▌^Ą─╣┼ĄõĄ─ż╩įÆ Option-Critic [Bacon et al., 2017] ? Option ż“ Deep RL ╗»żĘż┐żŌż╬ (Goal Ė┼─Ņż¼▒ĪżżŻ┐) ? End-to-End żŪč¦┴Ģ┐╔─▄ ? ╔Ž╬╗?▓▀ż╚Ž┬╬╗?▓▀ż╬ę█ĖŅż¼╬┤Ęų╗»ż╣żļå¢Ņ}ĄŃż¼┤µį┌ FeUdal Networks - ▒│Š░Ė┼─Ņ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 12
- 13. FRL ż╬ęŌ╦╝øQČ©ż“╔Ž╬╗īėż╚Ž┬╬╗īėż╦ĘųĖŅż¼Ė∙ÄųźóźżźŪźŻźó ? Ž┬╬╗ęŌ╦╝øQČ©š▀ Worker (FRL żŪż╬ sub-maneer) ? ╔Ž╬╗ęŌ╦╝øQČ©š▀ Manager FeUdal Networks - Ė┼ę¬ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 13 Ī³ Ž┬╬╗ż╬?äė primitive-policy ż“▀xÆkż╣żļ Worker CNN ▓┐żŪ ėQ£y x ż“ēõōQ???? Ī² A3C żŪč¦┴Ģ Ī² Ī¹ źĄźųź┤®`źļ Ī² ╔Ž╬╗ż╬?äė sub-policy ż“▀xÆkż╣żļ Manager Ī∙ [Vezhnevets et al., 2017]
- 14. FuN żŽźó®`źŁźŲź»ź┴źŃ╚½ė“żŪ╬óĘų┐╔─▄ ŻĮ Manager ż╦żĶżļźĄźųź┐ź╣ź»Ęų ĖŅż“ End-to-End żŪč¦┴Ģ┐╔─▄ ŅÉ╦ŲĖ┼─Ņ Option ż╚ FuN ż╬?żŁż╩▀`żżżŽ Goal Ė┼─Ņż¼żóżļż½Ę±ż½ - Option żŽ Goal ż╦ĄĮ▀_żĘż┐żķ╔Ž╬╗?▓▀ż╦żĶż├żŲ┤╬ż╬ Goal ż“øQČ© - FuN żŽČ©╩²Ģrķg c step ż╦żĶż├żŲęŌ╦╝øQČ©ź┐źżź▀ź¾ź░ż“Ū°Ūążļ - ż│ż╬Č©╩²Ģrķg c step ż╬ĖŅżĻŪążĻż¼├žįEż╬?ż─Ż┐ - šō?ųąż╬ĮY╣¹żŽ c = 10 FeUdal Networks - Ė┼ę¬ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 14
- 15. FuNs ż╬╠žÅš 1. Transition policy gradient for training the Manager ? Manager ė¢ŠÜż╬ż┐żßż╬▀węŲ?▓▀╣┤┼õ (▀węŲ?▓▀ŻĮ╔Ž╬╗īė?▓▀) 2. Relative rather than absolute goals ? Į~īØĄ─żŪżŽż╩ż»ŽÓīØĄ─ż╩Č©┴xż╦żĶżļźĄźųź┤®`źļą╬│╔ ? ½@Ą├żĄżņż┐Ū▒į┌ū┤æBź┘ź»ź╚źļ s ż╦īØż╣żļ▓ŅĘųż“ g ż╚żĘżŲč¦┴Ģ 3. Lower temporal resolution for Manager ? Manager ż╬ÆQż”ĢrķgķgĖ¶ż╬Ą═ĮŌŽ±Č╚╗» ? ęŌ╦╝øQČ©ź┐źżź▀ź¾ź░ż╚ Dilated LSTM 4. Intrinsic motivation for the Worker ? ─┌▓┐ł¾│Ļ(ż╚żżż├żŲżŌ?▌^Ą─╚§żß) FeUdal Networks - ╠žÅš Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 15
- 16. Manager (╔Ž╬╗īė)ė¢ŠÜż╬ż┐żßż╬▀węŲ?▓▀╣┤┼õ : Worker (Ž┬╬╗īė)ż╚żŽ«Éż╩żļ╣┤┼õż“Č©┴x Transition policy gradient for the Manager Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 16 Ī∙ Ī∙ Ī³ Manager ż½żķėļż©żķżņżļüóŽļĄ─ż╩ģ¦ęµ Ī∙ Option-Critic żŽŽ┬╬╗īėż╬ęŌ╦╝øQČ©š▀ż½żķż╬╣┤┼õż“╩╣ż├żŲč¦┴Ģ Ī∙ [Vezhnevets et al., 2017]
- 17. Į~īØżŪżŽż╩ż»ŽÓīØĄ─ż╩źĄźųź┤®`źļ : = Von Mises©CFisher Ęų▓╝ (d ┤╬į¬ż╬?Ž“ż╬š²ęÄĘų▓╝) ż“Į³╦Ų Relative rather than absolute goals Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 17 īgļHż╬ŽÓīØĄ─ź┤®`źļż╬Ė³ą┬╩ĮŻ║ Ī² ęŌ╬ČĄ─ż╦żŽŻ║ Ī³ Von Mises©CFisher Ęų▓╝ Ī∙ https://en.wikipedia.org/wiki/Von_Mises-Fisher_distribution Cos ŅÉ╦ŲČ╚ż╚ż╬▒╚└²ķvéSŻ║
- 18. Manager ż¼ÆQż”ĢrķgķgĖ¶ż╬Ą═ĮŌŽ±Č╚╗» Dilated LSTM : Lower temporal resolution for Manager Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 18 r (= c ; šō?ųą) ŽĄ┴ą╩²ż╬ LSTM ż“?ęŌżĘŻ¼r źĄźżź»źļÜ░ż╦ą┬ż┐ż╩ ū┤æBż“▒Ż┤µżĘżŲżżż» Ī· Manager źņź┘źļżŪżŽ?Ų┌ż╬ėøæøż“▒Ż│ų (r step ķgĖ¶)
- 19. ─┌▓┐ł¾│Ļ : Intrinsic motivation for the Worker Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 19 ┴„?żĻż╬║├Ųµ? (intrinsic reword) ż╚żŽż▐ż┐«Éż╩żļ ŁhŠ│╠Į╦„ä┐╣¹żŽ╔┘ż╩żżż╬żŪ║├Ųµ?ż╚ż╬ĮMż▀║Žż’ż╗żŽ┐╔─▄ Ī³ ėĶ£yżĄżņż┐ź┤®`źļż╚ż╬ŅÉ╦ŲČ╚ Ī∙ 0 ~ c step ż╬ķgż╦ goal ż╦Į³ż┼ż▒żą OK !
- 20. ĮY╣¹ - Montezuma?s Revenge Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 20 Ī² ęįŪ░ż╬ĢrŽĄ┴ą│÷?ż╦ż╚ż├żŲ goal ż╦ż╩ż├żŲżļ╩² Ī¹ ╦žż╬ LSTM żĶżĻ┴╝żż 200 epoch ╬┤£║żŪūŅ│§ż╬▓┐╬▌ż“═╗ŲŲ (1 epoch = 100═“ step ) Ī∙ [Vezhnevets et al., 2017]
- 21. ĮY╣¹ - źĄźų?▓▀ż╬┤_šJ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 21 ź┤®`źļ╣╠Č©Ģrż╬äėżŁ : Manager ż¼ź▓®`źÓųąĮU“YżĘż┐źĄźųź┤®`źļ g ż“ėøæøżĘżŲż¬żŁŻ¼żóż©żŲ╣╠Č© żĘżŲ?äėżĄż╗żļ╩┬żŪźĄźų?▓▀ż╬äėżŁż“┤_šJżŪżŁżļ ╔Žėøź░źķźŪ®`źĘźńź¾ź▐ź├źūżŽ Agent ż╬┐šķgų═į┌?┬╩ż“ŲĮŠ∙╗»żĘż┐żŌż╬ Ī· «Éż╩żļäėżŁż¼┤_šJżŪżŁżļ └² : sub-policy 3 żŽ┐šÜ▌ż“ča│õżĘżŲżżżļ Ī∙ [Vezhnevets et al., 2017]
- 22. ĮY╣¹ - Option-Critic ż╚ż╬?▌^ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 22 FuNs : Option-Critic : ═¼żĖ End-to-End ż╩ļAīėą═ÅŖ╗»č¦┴Ģ Option-Critic ż╚?▌^żĘżŲ┴╝żż│╔┐ā ═Żų═Ü▌╬Čż╬ Option-Critic ż╦?ż┘żŲŻ¼FuN żŽĖ³ż╦╔Žż¼żĻŠAż▒żŲżżżļ Ī∙ [Vezhnevets et al., 2017]
- 23. ĮY╣¹ - źóźżźŪźŻźóż╬š²żĘżĄ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 23 4ĘNż╬?ōpą═ FuN ż╚ż╬?▌^: Non feudal FuN : ?▓▀╣┤┼õżŪė¢ŠÜŻ¼─┌▓┐ł¾│ĻżŌ╩╣ż’ż╩żż (Option-Criticż╦Į³żż) Pure feudal FuN : Worker ż╦─┌▓┐ł¾│Ļż“╩╣ż’ż╩żż Manager via PG FuN : Manager ż“?▓▀╣┤┼õżŪė¢ŠÜ Absolute goals Fun : Į~īØź┤®`źļż“╩╣? (Š▀╠ÕĄ─ż╩Č©┴xżŽšiż▀żŁżņż╩ż½ż├ż┐) Ī· ╚½żŲż╦ż¬żżżŲ FuN ż¼ä┘└¹ = 3ż─ż╬źóźżźŪźŻźóż╬ėąä┐ąį Ī∙ [Vezhnevets et al., 2017]
- 24. ĮY╣¹ - źóźżźŪźŻźóż╬š²żĘżĄ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 24 Dilated LSTM ż╦ķvż╣żļ?▌^: No dilation : Manager ż╦═©│Ż LSTM ż“╩╣? Manager horizon = 1 : c = 1 żŪ Manager ż╚ Dilated LSTM ż“▀\? Ī· ╚½żŲż╦ż¬żżżŲ FuN ż¼ä┘└¹ = Dilated LSTM ż╬ėąä┐ąį c = 1 żŪżŌ╔Žż¼ż├żŲżŽżżżļ Ī∙ [Vezhnevets et al., 2017]
- 25. ĮY╣¹ - źóźżźŪźŻźóż╬š²żĘżĄ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 25 Dilated LSTM ż╦ķvż╣żļ?▌^: dLSTM : FuN żŪżŽż╩ż»═©│Żż╬ A3C ż╦Dilated LSTMż╬ż▀ż“╩╣? Ī· ╗∙▒ŠĄ─ż╦żŽ FuN ż╚ ═©│ŻLSTM ż¼ä┘└¹ = Dilated LSTM żŽ Manager źņź┘źļż└ż½żķėąä┐ Ī∙ [Vezhnevets et al., 2017]
- 26. ĮY╣¹ - ▄×ęŲżžż╬įćż▀ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 26 Action repeat of 4 ż½żķ Action repeat ¤ożĘżžż╬ųžż▀▄× ?Č©źšźņ®`źÓ╩² (šō?ųążŪżŽ 4 frame) ż╬ķg═¼żĖ?äėż“ż╣żļ═©│Żż╬żõżĻ? żŪč¦┴ĢżĘż┐ųžż▀ż“Ż¼1 frame ż┤ż╚ż╦?äėż“ęŌ╦╝øQČ©ż╣żļź┐ź╣ź»ż╦▄×? żĮż╬č¦┴ĢżĘż╩żżżŪż╬│╔┐ā (┴„?ż╦Ė„ĢrķgķvéSźčźķźß®`ź┐żŽ 4 ▒Čż╦ż╣żļ) Ī· FuN ż╬?żż│╔┐āżŽ Manager żŪč¦┴ĢżĘż┐╔Ž╬╗?▓▀ż╬ėą?ąįż“ęŌ╬Čż╣żļ Ī· ═¼?ź┐ź╣ź»ż└ż╚ Maneger ż╬Ü°?ąįż╬?żĄż╬į^├„ż╦żŽż╩żķż╩żżÜ▌żŌŻ┐ Ī∙ [Vezhnevets et al., 2017]
- 27. ĖąŽļ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 27 End-to-End ż╩źĄźųź┤®`źļą╬│╔ ? Į~īØĄ─żŪżŽż╩ż»ŽÓīØĄ─ż╩ź┤®`źļČ©┴x (żóżļĘNż╬╬┤└┤?Ž“ėĶ£y) ż╚żżż” źóźżźŪźŻźóżŪ│╔żĘż┐ż╬żŽ┼d╬Č╔Ņżż ? ╣╠Č©?Ģrķg c step ż“┐╔ēõ?ż╦żŪżŁżļż╚ż╩ż¬┴╝żż ? ?żżĢrķg?żŪź┤®`źļż“Č©┴xżĘż┐żżł÷║Žżžż╬īØäIż“┐╝ż©żŲ ? ?Ą─šōĄ─ż╦żŽ Option ż╬?ż¼źĄźųź┤®`źļż╚?ż©żļ Ī∙ [Vezhnevets et al., 2017]
- 28. ĖąŽļ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 28 LSTM żžż╬ę└┤µąį ? ▓╗═Ļ╚½Ūķł¾żžż╬īØäIżŽ╦∙įÅ LSTM ż▐ż½ż╗ ? │╔┐āżŪ Option-Critic ż╦ā׿├żŲżżżļż╬żŽ A3C żõ LSTM ż╬ż¬ż½ż▓ ? ╣╠Č©? c step źĄźżź»źļż╬ Dilated LSTM ż¼ėąä┐ż└ż├ż┐Ż┐ ? FuNs ?╠Õż¼ Dilated LSTM ż“╩╣ż”ż┐żßż╬śŗįņż╚żŌūĮż©żķżņżļ ? ?Ų┌Ą─ż╩ Dilated LSTM ż╚żżż├żŲżŌŽ▐Įńż¼┤µį┌ż╣żļżŽż║ Ī· żĶżĻłR┐s(ėø║┼╗»)żĄżņż┐ėøæø▒Ē¼Fż“ End-to-End żŪč¦┴Ģż╣ż┘żŁŻ┐
- 29. ę²??Žū (ź╣źķźżź╔ųą) Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 29 [Vezhnevets et al., 2017] Vezhnevets, A. S., Osindero, S., Schaul, T., Heess, N., Jaderberg, M., Silver, D., and Kavukcuoglu, K. FeUdal Networks for Hierarchical Reinforcement Learning. ArXiv. Retrieved from http:// arxiv.org/abs/1703.01161 (2017). [Bellmare et al., 2012] Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research. (2012). [Dayan and Hinton, 1993] Dayan, P., and Hinton, G. E. Feudal reinforcement learning. In NIPS . Morgan Kaufmann Publishers. (1993). [Sutton et al., 1999] Sutton, R. S., Precup, D., and Singh, S. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence. (1999). [Bacon et al., 2017] Bacon, P. L., Precup, D., and Harb, J. The option-critic architecture. In AAAI. (2017). [Von Mises©CFisher distribution] https://en.wikipedia.org/wiki/Von_Mises-Fisher_distribution
- 30. ĮY╣¹ - ź¬ź▐ź▒ Copyright (C) DeNA Co.,Ltd. All Rights Reserved. 30 Water maze żŪīgļHż╦½@Ą├żĄżņż┐?äė : Staet (Šv)╬╗ų├ż½żķż╬?äėęį═ŌŻ¼═¼żĖ░ļŠČżŪ╗ž▄׿ʿŲ╠Į╦„ż╣żļźĄźų?▓▀ż¼ č¦┴ĢżĄżņżļ ėęČ╦żŽ goal ż“źķź¾ź└źÓż╦įOČ©Ż¼200step ╣╠Č©żĘżŲč¦┴ĢżĘżŲĄ├żķżņż┐źĄ źų?▓▀ź▒®`ź╣ Ī∙ [Vezhnevets et al., 2017]