














Feudal networks for hierarchical reinforcement learning
- 1. FeUdal Networks for Hierarchical RL Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, etc. DeepMind Youngseok Yoon, MLG POSTECH.
- 2. Contents ŌĆó Architecture ŌĆó Learning ŌĆó Experiments ŌĆó Ablative analysis ŌĆó Discussion
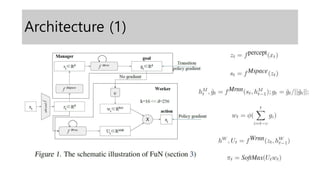
- 4. Architecture (2) ŌĆó Øæō ØæØØæÆØæ¤ØæÉØæÆØæØØæĪ: CNN(16 8x8 4, 32 4x4 2) + FCL(256) ŌĆó Øæō ØæĆØæĀØæØØæÄØæÉØæÆ: FCL ŌĆó To encourage exploration in transition policy, by Ø£¢, emit random goal sampled. ŌĆó Øæō ØæŖØæ¤ØæøØæø : Standard LSTM, 256 ŌĆó Øæō ØæĆØæ¤ØæøØæø : dLSTM, 256 ŌĆó dLSTM: dilated LSTM
- 5. Learning (1) ŌĆó Advantage A-C: Øø╗Ø£ŗ ØæĪ = ØÉ┤ ØæĪ Øø╗Ø£ā log Ø£ŗ(ØæÄ ØæĪ|Øæź ØæĪ; Ø£ā) ØÉ┤ ØæĪ = ØæģØæĪ ŌłÆ ØæēØæĪ Øæź ØæĪ; Ø£ā ŌĆó The direction of state-space (goal): ØæØ(ØæĀØæĪ+ØæÉ|ØæĀØæĪ, Øæ£ØæĪ) ŌłØ ØæÆ Øææ ØæÉØæ£ØæĀ ØæĀ ØæĪ+ØæÉŌłÆØæĀ ØæĪ, Øæö ØæĪ ŌĆó Learning of Goal: Øø╗Ø£ŗ ØæĪ = Øø╗ØæØ ØæÄ ØæĪ ØæĀØæĪ ŌćÆ Øø╗ØæØ ØæĀØæĪ+ØæÉ ØæĀØæĪ, Øæ£t = Øø╗ØæöØæĪ Ōł┤ Øø╗ØæöØæĪ = ØÉ┤ ØæĪ ØæĆ Øø╗Ø£ā Øææ ØæÉØæ£ØæĀ ØæĀØæĪ+ØæÉ ŌłÆ ØæĀØæĪ, ØæöØæĪ Ø£ā ØÉ┤ ØæĪ ØæĆ = ØæģØæĪ ŌłÆ ØæēØæĪ ØæĆ Øæź ØæĪ, Ø£ā
- 6. Learning (2) ŌĆó Intrinsic reward for Worker: Øæ¤ØæĪ ØÉ╝ = 1 ØæÉ Øæ¢=1 ØæÉ Øææ ØæÉØæ£ØæĀ ØæĀØæĪ ŌłÆ ØæĀØæĪŌłÆØæ¢, ØæöØæĪŌłÆØæ¢ ŌĆó WorkerŌĆÖs Policy gradient: Øø╗Ø£ŗ ØæĪ = ØÉ┤ ØæĪ ØÉĘ Øø╗Ø£ā log Ø£ŗ(ØæÄ ØæĪ|Øæź ØæĪ; Ø£ā) ØÉ┤ ØæĪ ØÉĘ = ØæģØæĪ + Øø╝ØæģØæĪ ØÉ╝ ŌłÆ ØæēØæĪ ØÉĘ Øæź ØæĪ; Ø£ā ŌĆó ManagerŌĆÖs Transition Policy Gradients Øø╗Ø£ā Ø£ŗ ØæĪ ØæćØæā = Øö╝ ØæģØæĪ ŌłÆ Øæē ØæĀØæĪ Øø╗Ø£ā log ØæØ(ØæĀØæĪ+ØæÉ|ØæĀØæĪ; Øæ£ØæĪ)
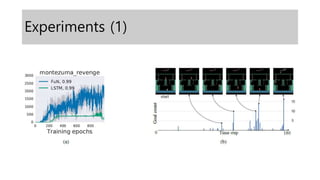
- 10. Experiments (4)
- 11. Experiments (5)
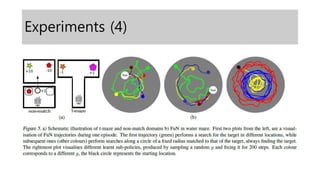
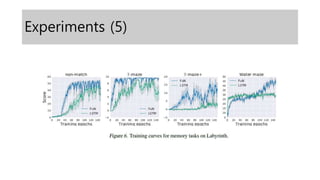
- 12. Experiments (7)
- 18. Discussion ŌĆó Previous action ņØ┤ inputņ£╝ļĪ£ ļōżņ¢┤Ļ░äļŗżļŖö ņ¢ĖĻĖēņØ┤ ņŚåļŗż. ļŗ╣ņŚ░Ē׳ ļōżņ¢┤Ļ░ĆļŖö Ļ▒┤ņ¦Ć, ņŚ¼ĻĖ░ņäĀ ļäŻņ¦Ć ņĢŖļŖöĻ▒┤ņ¦Ć. ŌĆó Ļ▓░ĻĄŁ ØæĀØæĪ+ØæÉņØś stateļź╝ predictĒĢśņŚ¼ sub-goal ņØä ļ¦īļōżĻ▓ĀļŗżļŖö ļ░£ņāü. ŌĆó Step cņØś Ēü¼ĻĖ░Ļ░Ć ņ¢┤ļ¢ż ņŚŁĒĢĀņØä ĒĢśļŖöņ¦Ć. (c=1ņŚÉņä£ļÅä ņל ļÅÖņ×æ.) =>c sizeĻ░Ć ņżæņÜöĒĢ£ ļ¼ĖņĀ£ļÅä ņ׳Ļ│Ā ņĢäļŗī ļ¼ĖņĀ£ļÅä ņ׳ļŗżĻ│Ā ņāØĻ░ü. ŌĆó ManagerļŖö input state sļź╝ c step ņö® Ļ▒┤ļäłļø░ņ¢┤ predict ĒĢśļŖöļŹ░, ņØ┤ cļź╝ hyper-parameterĻ░Ć ņĢäļŗī model parameterļĪ£ ņé¼ņÜ®ĒĢĀ ņłś ņ׳ņØä ņ¦Ć ŌĆó Magerņ£äņŚÉ 2c, c2 ļō▒ņØś Meta-Manager (Hyper-Manager)ļź╝ ļæś ņłś ņ׳ņØäņ¦Ć.
- 19. Thank you!