File Organization
•Download as PPTX, PDF•
25 likes•24,955 views

This document discusses different file organization methods including sequential files, indexed sequential files, indexed files, and direct/hashed files. Sequential files store records in the order they are entered with each record having a fixed format. Indexed sequential files add an index to allow random access by key fields while maintaining sequential ordering. Indexed files use multiple indexes on different keys to allow searching by different fields. Direct/hashed files directly access records by key values using hashing techniques for fast random access.











File Organization
- 1. FILES ORGANIZATION PRESENTED BY : KU MAN YI B031210161 MOHAMMAD SAFAR A/L SHARIFF MOHAMED B031210227 ADAM RIDHWAN BIN SUKIMAN B031210083 SOO BOON JIAN B031210199 MUHAMMAD ZULKHAIRI BIN ZAINI B031210140
- 2. FILE ORGANIZATION For understanding  File/Table  Record/Row  Field/Column/Attribute
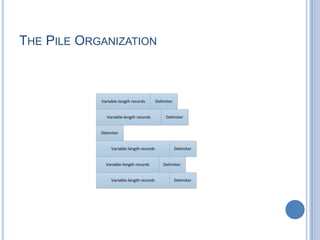
- 3. THE PILE  A form of file organization where data are collected in the same order they arrived  This organization simply accumulate mass of data and save it  Each field is self-describing, includes a field name and a value. Length of each field is determined as shown  Implicitly indicated by delimiters  Explicitly included as subfield or  Done by default for that particular field type  Records may have different fields and there is no visible structure. Hence, record access is through exhaustive search where all record or the entire file is examined  This type of file uses space efficiently and is updated easily. However, retrieval of a single record could be tedious
- 4. THE PILE ORGANIZATION Variable-length records Delimiter Delimiter Delimiter Delimiter Delimiter Delimiter Variable-length records Variable-length records Variable-length records Variable-length records
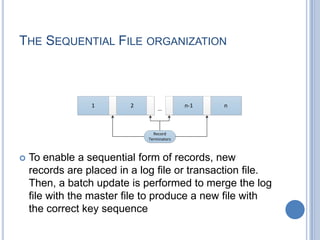
- 5. THE SEQUENTIAL FILE  Most common form of file structure  Fixed format are used for records and records are of the same length  Field names and lengths are attributes of the file  One particular field (usually first field) is referred to as the key field :-  Uniquely identifies the record  Records are stored in key sequence  Alphabetical order or numerical order depending on the key field  It is the simplest structure and easy to implement in any device. However, in the worst case scenario, accessing a single record takes a long time.
- 6. THE SEQUENTIAL FILE ORGANIZATION 1 2 ……. n-1 n Key Field Attributes
- 7. THE SEQUENTIAL FILE ORGANIZATION  To enable a sequential form of records, new records are placed in a log file or transaction file. Then, a batch update is performed to merge the log file with the master file to produce a new file with the correct key sequence 1 2 n-1 n … Record Terminators
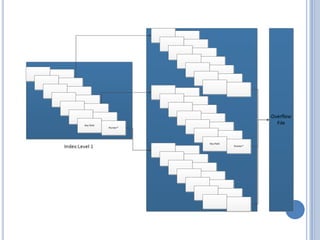
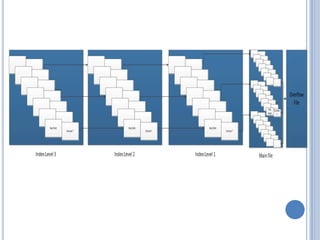
- 8. THE INDEXED SEQUENTIAL FILE  A file management system that allows records to be accessed either sequentially (in the order they were entered) or randomly (with an index)  A secondary set of hash tables known as indexes is created that contains pointers to the main file  In indexed sequential file, records are organized in sequence based on key fields  Each file has an index to support random search  Overflow file is added such as each record in overflow file is located by following a pointer from its predecessor record in main file
- 9. DESCRIPTION  As an example:-  Firstly, a single level of indexing is used. Hence, the index is a simple sequential file.  Each record in the index file consists of:-  Key field(same as key field in the main file)  Pointer to the main file  To find a specific field, the index file is searched for matching key values  Then, the pointer indicates the record having the matching key values as depicted by figure below  This reduces the average search length
- 11.  There is an addition to the organization where each record in the main file contains an additional field which is a pointer to the overflow file  When a new record is added, it is added into the overflow file. The record in main file which is immediately before the new record in a logical sequence to be inserted is updated to contain a pointer to the new record in the overflow file  However, if the record before the new record in logical sequence is itself in the overflow file, then the pointer in that record is updated  The processing of entire file sequentially involves processing of records of main files sequentially until the pointer to the overflow file is found, then accessing is continued in the overflow file until a null pointer is encountered  Secondly, we visualize the organization using multiple levels of indexes  The lowest level of index points to the main file, whereas the index files sitting on the level above points to the index file below it  Hence, the efficiency in access is greatly increased and average length of search is greatly reduced as conveyed in figure below
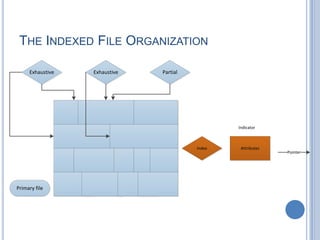
- 13. THE INDEXED FILE  Uses multiple indexes for different key fields which may be the subject of a search  Record accessibility are through their indexes  May contain an exhaustive index that contains one entry for every record in the main file. The index itself is organized in the sequential form for ease of searching  May contain a partial index. It contains entries to records where the desired field exists
- 14. THE INDEXED FILE ORGANIZATION Primary file Exhaustive PartialExhaustive Index Attributes Pointer Indicator
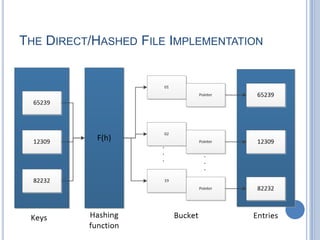
- 15. THE DIRECT/HASHED FILE  This file management system that access directly any block of a known address.  A key field is required for each record.  Uses hashing on the key value.  No concept of sequential ordering implemented.  Such examples are:-  Directories  Pricing table  Schedules  Name lists  It is used where rapid access is required, where fixed- length records are used and where records are accessed one-at-a-time.  The concept of hashing can be shown as below.
- 16. THE DIRECT/HASHED FILE IMPLEMENTATION
- 17. HASHING METHODS  Direct method  The key is the address  a key value might be between 1-100. The address of a certain records will be the same as the key.  Subtraction method  Subtract certain amount of numbers from the key  a key value might start with 1001 and ends with 1100. A simple hashing function could subtract 1000 from the key to determine the address.  Modulo-division method  Key value is divided by the size of records.  the remainder becomes the address of the key.  Digit-extraction method  Selected digits are extracted from the key  As an example:- a field has 10 digits. The hashing function only extracts the first 2 digits and the last digit and use them as address.