•§•Û•∆•ÎFPGA§ŒDeep Learning Acceleration Suite§»•Þ•§•Ø•Ì•Ω•’•»§ŒBrainwave§ÚHW“﵄§´§È±»ð^§∑§∆§þ§Î Intelæé
?
1 like?876 views

•§•Û•∆•ÎFPGA§ŒDeep Learning Acceleration Suite§»•Þ•§•Ø•Ì•Ω•’•»§ŒBrainwave§ÚHW“﵄§´§È±»ð^§∑§∆§þ§Î •§•Û•∆•ÎFPGA§ŒDeep Learning Acceleration Suite§»•Þ•§•Ø•Ì•Ω•’•»§ŒBrainwave§œ°¢§…§¡§È§‚FPGA§Ú”√§§§∆•§•Û•’•°•Ï•Û•πÑI¿Ì§Ú––§¶§‚§Œ§«§¢§Í§ §¨§È°¢§Ω§Œƒ⁄≤øòã≥…§œ180∂»Æê§ §Í§Þ§π°£§≥§≥§«§œÅI’þ§Ú±»ð^§∑§ƒ§ƒ°¢•§•Û•∆•Î§Œ•§•Û•’•°•Ï•Û•π•Ω•Í•Â©`•∑•Á•Û§À§ƒ§§§∆Ω‚’h§∑§Þ§π°£









•§•Û•∆•ÎFPGA§ŒDeep Learning Acceleration Suite§»•Þ•§•Ø•Ì•Ω•’•»§ŒBrainwave§ÚHW“﵄§´§È±»ð^§∑§∆§þ§Î Intelæé
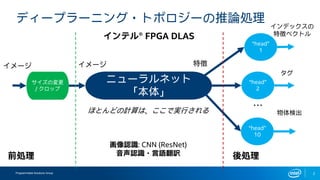
- 2. Programmable Solutions Group 2 •«•£©`•◊•È©`•À•Û•∞?•»•ð•Ì•∏©`§ŒÕ∆’ìÑI¿Ì °∞head°± 1 °∞head°± 2 °∞head°± 10 •À•Â©`•È•Î•Õ•√•» °∏±æÃÂ°π •§•·©`•∏ °≠§€§»§Û§…§Œ”ãÀ„§œ°¢§≥§≥§«åg––§µ§Ï§Î ª≠œÒ’J◊R: CNN (ResNet) “Ù…˘’J◊R?—‘’Z∑≠‘U Ãÿè’ •§•Û•«•√•Ø•π§Œ Ãÿè’•Ÿ•Ø•»•Î •ø•∞ ŒÔÃÂó ≥ˆ ··ÑI¿Ì •§•Û•∆•Î? FPGA DLAS •µ•§•∫§Œâ‰∏¸ / •Ø•Ì•√•◊ •§•·©`•∏ «∞ÑI¿Ì
- 3. Programmable Solutions Group 3 OpenVINO? •ƒ©`•Î•≠•√•» OpenVX §™§Ë§” OpenVX •Ì•¥§œ°¢Khronos Group Inc. §Œ…ÃòÀ§«§π°£ OpenCL §™§Ë§” OpenCL •Ì•¥§œ°¢Apple Inc. §Œ…ÃòÀ§«§¢§Í°¢Khronos’þ§Œ‘Sø…§Úµ√§∆ π”√§∑§∆§§§Þ§π°£ Open VINO? •ƒ©`•Î•≠•√•»§»§œ •≥•Û•ð©`•Õ•Û•»?•ƒ©`•Î toolsèæ¿¥–Õ•≥•Û•‘•Â©`•ø©`?•”•∏•Á•Û ®C »´ SDK •–©`•∏•Á•Û ◊ÓþmªØ§µ§Ï§ø•≥•Û•‘•Â©`•ø©`?•”•∏•Á•Û?•È•§•÷•È•Í©` GPUCPU FPGA VPU ”ñæöúg§þ •‚•«•Î •§•Û•∆•Î? FPGA DLAS •◊•Ì•ª•√•µ©`§Œ•∞•È•’•£•√•Ø•π–‘ƒÐ§ÚœÚ…œ GPU = •§•Û•∆•Î? •§•Û•∆•∞•Ï©`•∆•√•…?•∞•È•’•£•√•Ø•π?•◊•Ì•ª•√•∑•Û•∞?•Ê•À•√•»§Ú≥÷§ƒ CPU VPU = Movidius? •”•∏•Á•Û?•◊•Ì•ª•√•∑•Û•∞?•Ê•À•√•» •§•Û•∆•Î? •«•£©`•◊•È©`•À•Û•∞? •«•◊•Ì•§•·•Û•»?•ƒ©`•Î•≠•√•» •‚•«•Î?•™•◊•∆•£•Þ•§•∂©` â‰ìQ°¢◊ÓþmªØ IR Õ∆’ì•®•Û•∏•Û ◊ÓþmªØ§µ§Ï§øÕ∆’ì OpenCV* OpenVX* OpenCL? •§•Û•∆•Î? •§•Û•∆•∞•Ï©`•∆•√•…?•∞•È •’•£•√•Ø•π§Œ•…•È•§•–©`§»•È•Û•ø•§•ý •§•Û•∆•Î? •·•«•£•¢ SDK (•™©`•◊•Û•Ω©`•π∞Ê) •”•√•»•π•»•Í©`•ý FPGA •È•Û•ø•§•ý≠hæ≥ (RTE) (•§•Û•∆•Î? FPGA SDK for OpenCL? §´§È)
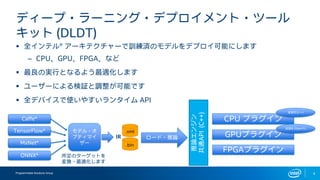
- 4. Programmable Solutions Group 4 ? »´•§•Û•∆•Î? •¢©`•≠•∆•Ø•¡•„©`§«”ñæöúg§Œ•‚•«•Î§Ú•«•◊•Ì•§ø…ƒÐ§À§∑§Þ§π ®C CPU°¢GPU°¢FPGA°¢§ §… ? ◊Ó¡º§Œåg––§»§ §Î§Ë§¶◊ÓþmªØ§∑§Þ§π ? •Ê©`•∂©`§À§Ë§Îó ‘^§»’{’˚§¨ø…ƒÐ§«§π ? »´•«•–•§•π§« 𧧧‰§π§§•È•Û•ø•§•ý API Caffe* TensorFlow* MxNet* .bin IR .xml Õ∆’ì•®•Û•∏•Û π≤Õ®API(C++) •Ì©`•…?Õ∆’ì CPU •◊•È•∞•§•Û GPU•◊•È•∞•§•Û FPGA•◊•È•∞•§•Û •‚•«•Î?•™ •◊•∆•£•Þ•§ •∂©` íàèà–‘ (C++) íàèà–‘ (OpenCL) À˘∂®§Œ•ø©`•≤•√•»§Ú â‰ìQ?◊ÓþmªØ§∑§Þ§π •«•£©`•◊?•È©`•À•Û•∞?•«•◊•Ì•§•·•Û•»?•ƒ©`•Î •≠•√•» (DLDT) ONNX*
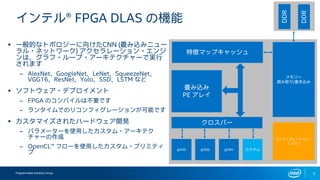
- 5. Programmable Solutions Group 5 •§•Û•∆•Î? FPGA DLAS §ŒôCƒÐ ? “ª∞„µƒ§ •»•ð•Ì•∏©`§ÀœÚ§±§øCNN (Æí§þÞz§þ•À•Â©` •È•Î?•Õ•√•»•Ô©`•Ø) •¢•Ø•ª•È•Ï©`•∑•Á•Û?•®•Û•∏ •Û§œ°¢•∞•È•’?•Î©`•◊?•¢©`•≠•∆•Ø•¡•„©`§«åg–– §µ§Ï§Þ§π ®C AlexNet°¢GoogleNet°¢LeNet°¢SqueezeNet°¢ VGG16°¢ResNet°¢Yolo°¢SSD°¢LSTM § §… ? •Ω•’•»•¶•ß•¢?•«•◊•Ì•§•·•Û•» ®C FPGA §Œ•≥•Û•—•§•Î§œ≤ª“™§«§π ®C •È•Û•ø•§•ý§«§Œ•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§¨ø…ƒÐ§«§π ? •´•π•ø•Þ•§•∫§µ§Ï§ø•œ©`•…•¶•ß•¢È_∞k ®C •—•È•·©`•ø©`§Ú π”√§∑§ø•´•π•ø•ý?•¢©`•≠•∆•Ø •¡•„©`§Œ◊˜≥… ®C OpenCL? •’•Ì©`§Ú π”√§∑§ø•´•π•ø•ý?•◊•Í•þ•∆•£ •÷ Æí§þÞz§þ PE •¢•Ï•§ •Ø•Ì•π•–©` prim prim prim •´•π•ø•ý DDR •·•‚•Í©` ’i§þ»°§Í/ﯧ≠Þz§þ Ãÿè’•Þ•√•◊•≠•„•√•∑•Â DDR •≥•Û•’•£•∞•Ï©`•∑•Á•Û? •®•Û•∏•Û
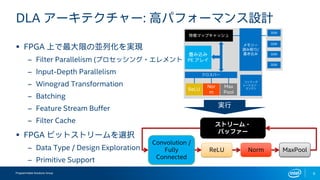
- 6. Programmable Solutions Group 6 DLA •¢©`•≠•∆•Ø•¡•„©`: ∏þ•—•’•©©`•Þ•Û•π‘O”ã ? FPGA …œ§«◊ӥۜާŒÅK¡–ªØ§Úåg¨F ®C Filter Parallelism (•◊•Ì•ª•√•∑•Û•∞?•®•Ï•·•Û•») ®C Input-Depth Parallelism ®C Winograd Transformation ®C Batching ®C Feature Stream Buffer ®C Filter Cache ? FPGA •”•√•»•π•»•Í©`•ý§Úþxík ®C Data Type / Design Exploration ®C Primitive Support ReLU Convolution / Fully Connected Norm MaxPool •π•»•Í©`•ý? •–•√•’•°©` Æí§þÞz§þ PE •¢•Ï•§ •Ø•Ì•π•–©` ReLU Max Pool DDR •·•‚•Í©` ’i§þ»°§Í/ ﯧ≠Þz§þ Ãÿè’•Þ•√•◊•≠•„•√•∑•Â DDR DDR DDR •≥•Û•’•£•∞ •Ï©`•∑•Á•Û? •®•Û•∏•ÛNor m åg––
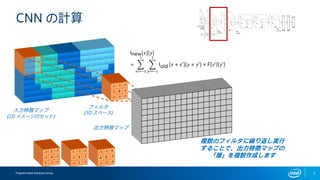
- 7. Programmable Solutions Group CNN §Œ”ãÀ„ Inew ? ? = ? ?°‰=?1 1 ? ?°‰=?1 1 Iold ? + ?°‰ ? + ?°‰ °¡ F ?°‰ ?°‰ »Î¡¶Ãÿè’•Þ•√•◊ (2D •§•·©`•∏§Œ•ª•√•») •’•£•Î•ø (3D •π•⁄©`•π) ≥ˆ¡¶Ãÿè’•Þ•√•◊ —} ˝§Œ•’•£•Î•ø§À¿R§Í∑µ§∑åg–– §π§Î§≥§»§«°¢≥ˆ¡¶Ãÿè’•Þ•√•◊§Œ °∏å”°π§Ú—} ˝◊˜≥…§∑§Þ§π 7
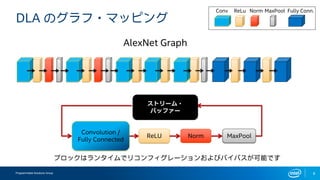
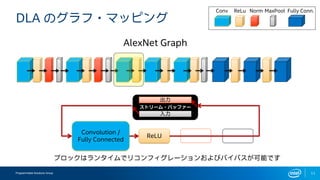
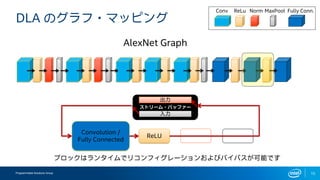
- 8. Programmable Solutions Group 8 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected Norm MaxPool AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý? •–•√•’•°©`
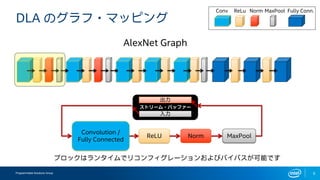
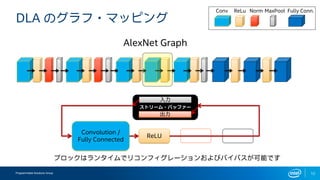
- 9. Programmable Solutions Group 9 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected Norm MaxPool AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶
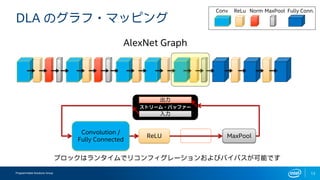
- 10. Programmable Solutions Group 10 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected Norm MaxPool AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶
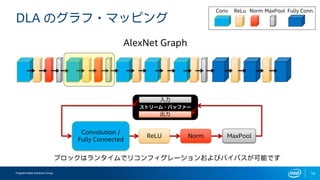
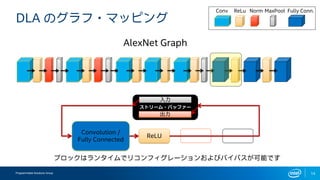
- 11. Programmable Solutions Group 11 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶ •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π
- 12. Programmable Solutions Group 12 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶
- 13. Programmable Solutions Group 13 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶ MaxPool
- 14. Programmable Solutions Group 14 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶
- 15. Programmable Solutions Group 15 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ ReLU Convolution / Fully Connected AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶
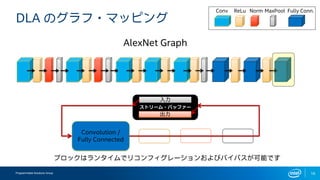
- 16. Programmable Solutions Group 16 DLA §Œ•∞•È•’?•Þ•√•‘•Û•∞ Convolution / Fully Connected AlexNet Graph Conv ReLu Norm MaxPool Fully Conn. •÷•Ì•√•Ø§œ•È•Û•ø•§•ý§«•Í•≥•Û•’•£•∞•Ï©`•∑•Á•Û§™§Ë§”•–•§•—•π§¨ø…ƒÐ§«§π •π•»•Í©`•ý?•–•√•’•°©` ≥ˆ¡¶ »Î¡¶
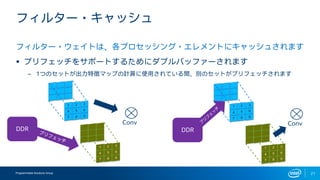
- 17. Programmable Solutions Group 20 •’•£©`•¡•„?•≠•„•√•∑•Â Ãÿè’•«©`•ø§œ•™•Û•¡•√•◊§À•≠•„•√•∑•Â§µ§Ï§Þ§π ? ÅK¡–ÑI¿Ì•®•Ï•·•Û•»§Œ•«•§•∏©`•¡•ß©`•Û§À•π•»•Í©`•ý§µ§Ï §Þ§π ? •¿•÷•Î•–•√•’•°©`§µ§Ï§Þ§π ®C Æí§þÞz§þ§»•≠•„•√•∑•Â§Œ∏¸–¬§¨Õ¨ïrþM––§∑§Þ§π ®C 1§ƒ§Œ•µ•÷•∞•È•’§Œ≥ˆ¡¶§¨À˚§Œ•µ•÷•∞•È•’§Œ»Î¡¶§»§ §Í§Þ§π ®C ≤ª±ÿ“™§ Õ‚≤ø•·•‚•Í©`§ÿ§Œ•¢•Ø•ª•π§ÚΩ‚œ˚§∑§Þ§π •¿•÷•Î•–•√•’•°©` •™•Û•¡•√•◊ RAM •π•»•Í©`•ý? •–•√•’•°©`?•µ•§•∫
- 18. Programmable Solutions Group 21 •’•£•Î•ø©`?•≠•„•√•∑•Â •’•£•Î•ø©`?•¶•ß•§•»§œ°¢∏˜•◊•Ì•ª•√•∑•Û•∞?•®•Ï•·•Û•»§À•≠•„•√•∑•Â§µ§Ï§Þ§π ? •◊•Í•’•ß•√•¡§Ú•µ•ð©`•»§π§Î§ø§·§À•¿•÷•Î•–•√•’•°©`§µ§Ï§Þ§π ®C 1§ƒ§Œ•ª•√•»§¨≥ˆ¡¶Ãÿè’•Þ•√•◊§Œ”ãÀ„§À π”√§µ§Ï§∆§§§ÎÈg°¢Ñe§Œ•ª•√•»§¨•◊•Í•’•ß•√•¡§µ§Ï§Þ§π DDR Conv Conv DDR
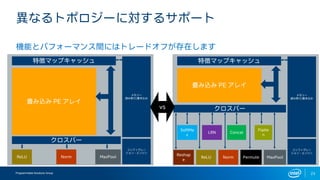
- 19. Programmable Solutions Group 22 DLA •¢©`•≠•∆•Ø•¡•„©`§Œþxík ? ±ÿ“™Ãıº˛§Úú∫§ø§π◊Óþm§ FPGA •§•·©`•∏§Úþxík§∑§Þ§π ? ±ÿ“™§Àèͧ∏§∆•´•π•ø•ý§Œ FPGA •§•·©`•∏§Ú◊˜≥…§∑§Þ§π
- 20. Programmable Solutions Group 23 Æê§ §Î•»•ð•Ì•∏©`§Àåù§π§Î•µ•ð©`•» ôCƒÐ§»•—•’•©©`•Þ•Û•πÈg§À§œ•»•Ï©`•…•™•’§¨¥Ê‘⁄§∑§Þ§π Æí§þÞz§þ PE •¢•Ï•§ •Ø•Ì•π•–©` ReLU Norm MaxPool •·•‚•Í©` ’i§þ»°§Í/ﯧ≠Þz§þ Ãÿè’•Þ•√•◊•≠•„•√•∑•Â •≥•Û•’•£•∞•Ï©` •∑•Á•Û?•®•Û•∏•Û Æí§þÞz§þ PE •¢•Ï•§ •Ø•Ì•π•–©` ReLU Norm MaxPool •·•‚•Í©` ’i§þ»°§Í/ﯧ≠Þz§þ Ãÿè’•Þ•√•◊•≠•„•√•∑•Â •≥•Û•’•£•∞•Ï©` •∑•Á•Û?•®•Û•∏•Û LRN Permute Concat Flatte n SoftMa x Reshap e vs
- 21. Programmable Solutions Group 24 •µ•ð©`•»§µ§Ï§Î•◊•Í•þ•∆•£•÷§»•»•ð•Ì•∏©` •»•ð•Ì•∏©` ? •µ•ð©`•»”– ? •Í•Ø•®•π•»§Àèͧ∏§∆•µ•ð©`•»”– ? Ω´¿¥µƒ§À•µ•ð©`•»§Ú”Ë∂® •◊•Í•þ•∆•£•÷ ?batch norm ?concat ?flatten ?max pool ?relu, leaky relu ? lrn normalization ?average pool ?scale ? softmax ?inner product ?permute ? prelu ?reshape ?detection output ?conv ?prIOrbox ?fully connected ?eltwise ?bias ?group conv ?depthwise conv ?local conv ?sigmoid ?elu ?power ?crop ?proporal ?slice ?depthwise conv ?roi pooling ?dilated conv ?tanh ?deconv ?AlexNet ?GoogleNet v1 ?SSD ?ResNet18 ?SSD ?ResNet50 ?ResNet101 ?SqueezeNet ?SSD ?VGG16 ?Tiny Yolo ?LeNet
- 22. Programmable Solutions Group 25 æ´∂»§Úœ¬§≤§∆•«•∂•§•Û§Úó ”ë§∑§∆§þ§Î •—•’•©©`•Þ•Û•π§»æ´∂»§ŒÈg§À§œ•»•Ï©`•…•™•’§¨¥Ê‘⁄§∑§Þ§π ? æ´∂»§Úœ¬§≤§Î§≥§»§«°¢§Ë§Í∂ý§Ø§ŒÑI¿Ì§¨ÅK¡–µƒ§Àåg––ø…ƒÐ§»§ §Í§Þ§π ? §Ë§Í–°§µ§§∏°Ñ”–° ˝µ„–Œ Ω§Ú π”√§π§Î§ø§·§Œ°¢•Õ•√•»•Ô©`•Ø§Œ‘Ÿ•»•Ï©`•À•Û•∞§œ≤ª“™§«§π ? FP11 §œ INT8/9 §Ë§Í§‚•·•Í•√•»§¨§¢§Í§Þ§π ®C ‘Ÿ•»•Ï©`•À•Û•∞≤ª“™°¢§Ë§Í¡º§§•—•’•©©`•Þ•Û•π°¢æ´∂»§Œìp ߧ¨…Ÿ§ §§ FP11 FP10 FP9 FP8 Sign°¢÷∏ ˝5•”•√•»°¢Å¢ ˝10•”•√•»FP16 Sign°¢÷∏ ˝5•”•√•»°¢Å¢ ˝5•”•√•» Sign°¢÷∏ ˝5•”•√•»°¢Å¢ ˝4•”•√•» Sign°¢÷∏ ˝5•”•√•»°¢Å¢ ˝3•”•√•» Sign°¢÷∏ ˝5•”•√•»°¢Å¢ ˝2•”•√•»
- 23. Programmable Solutions Group •È•§•÷•È •Í©` •§•Û•∆•Î? •«•£©`•◊•È©`•À •Û•∞?•«•◊•Ì•§•·•Û•»? •ƒ©`•Î•≠•√•» •ƒ©`•Î •’•Ï©`•ý •Ô©`•Ø •§•Û•∆•Î? DAAL •œ©`•… •¶•ß•¢ •·•‚•Í©` & •π•»•Ï©`•∏ •Õ•√•»•Ô©`•≠•Û•∞ •§•Û•∆•Î? Distribution for Python Mlib BigDL •§•Û•∆•Î? Nervana? Graph •§•Û•∆•Î? AI (»Àπ§÷™ƒÐ) •ð©`•»•’•©•Í•™ ÃÂÚY •¢•Ω•∑•¢•∆•£•÷? •·•‚•Í©`•Ÿ©`•π OpenVINO? •ƒ©`•Î•≠•√•» •”•∏•Â•¢•Î?•§•Û•∆•Í •∏•ß•Û•π •§•Û•∆•Î? FPGA DLAS •§•Û•∆•Î? Math Kernel Library (MKL°¢MKL-DNN) •≥•Û•‘•Â©`•» More * 26
- 24. Programmable Solutions Group 27 –‘ƒÐ§ÀÈv§π§Î√‚ÿüÃıÌó •§•Û•∆•Î? •∆•Ø•Œ•Ì•∏©`§ŒôCƒÐ§»¿˚µ„§œ•∑•π•∆•ýòã≥…§À§Ë§√§∆Æê§ §Í°¢åùèͧπ§Î•œ©`•…•¶•ß•¢§‰•Ω•’•»•¶•ß•¢°¢§Þ§ø§œ •µ©`•”•π§Œ”–ÑøªØ§¨±ÿ“™§»§ §Îàˆ∫œ§¨§¢§Í§Þ§π°£ågÎH§Œ–‘ƒÐ§œ•∑•π•∆•ýòã≥…§À§Ë§√§∆Æê§ §Í§Þ§π°£Ω~åùµƒ§ •ª•≠•Â•Í •∆•£©`§ÚÃ·π©§«§≠§Î•≥•Û•‘•Â©`•ø©`?•∑•π•∆•ý§œ§¢§Í§Þ§ª§Û°£‘îºö§À§ƒ§§§∆§œ°¢∏˜•∑•π•∆•ý•·©`•´©`§Þ§ø§œÿú┵ͧÀ§™ Üñ§§∫œ§Ô§ª§§§ø§¿§Ø§´°¢http://www.intel.co.jp/ §Ú≤Œ’’§∑§∆§Ø§¿§µ§§°£ •∆•π•»§«§œ°¢Ãÿ∂®§Œ•∑•π•∆•ý§«§ŒÇÄ°©§Œ•∆•π•»§À§™§±§Î•≥•Û•ð©`•Õ•Û•»§Œ–‘ƒÐ§ÚŒƒï¯ªØ§∑§∆§§§Þ§π°£•œ©`•…•¶•ß•¢°¢•Ω •’•»•¶•ß•¢°¢•∑•π•∆•ýòã≥…§ §…§Œþ`§§§À§Ë§Í°¢ågÎH§Œ–‘ƒÐ§œí˜ðd§µ§Ï§ø–‘ƒÐ•∆•π•»§‰‘uÅ˝§»§œÆê§ §Îàˆ∫œ§¨§¢§Í§Þ§π°£ Ÿè»Î§Úó ”맵§Ï§Îàˆ∫œ§œ°¢§€§´§Œ«ÈàÛ§‚≤Œøº§À§∑§∆°¢•—•’•©©`•Þ•Û•π§Úæt∫œµƒ§À‘uÅ˝§π§Î§≥§»§Ú§™Ñ·§·§∑§Þ§π°£–‘ƒÐ§‰ •Ÿ•Û•¡•Þ©`•ØΩYπ˚§À§ƒ§§§∆°¢§µ§È§À‘î§∑§§«ÈàÛ§Ú§™÷™§Í§À§ §Í§ø§§àˆ∫œ§œ°¢http://www.intel.com/benchmarks/ (”¢’Z) §Ú≤Œ’’§∑§∆§Ø§¿§µ§§°£ ±æŸY¡œ§À§œ°¢È_∞k÷–§Œ—u∆∑°¢•µ©`•”•π°¢•◊•Ì•ª•π§ÀÈv§π§Î«ÈàÛ§¨∫¨§Þ§Ï§∆§§§Þ§π°£§≥§≥§À”õðd§µ§Ï§∆§§§Î§π§Ÿ§∆§Œ«ÈàÛ §œ°¢”Ë∏ʧ §Øâ‰∏¸§µ§Ï§Î§≥§»§¨§¢§Í§Þ§π°£◊Ó–¬§Œ”Ëúy°¢•π•±•∏•Â©`•Î°¢ Àòî°¢§™§Ë§”•Ì©`•…•Þ•√•◊§Ú§¥œ£Õ˚§Œ∑Ω§œ°¢•§ •Û•∆•Î§Œµ£µ±’þ§Þ§«§™Üñ§§∫œ§Ô§ª§Ø§¿§µ§§°£ ?2018 Intel Corporation. Intel°¢•§•Û•∆•Î°¢Intel •Ì•¥°¢Arria §œ°¢•¢•·•Í•´∫œ–\π˙§™§Ë§” / §Þ§ø§œ§Ω§ŒÀ˚§Œπ˙§À§™§±§Î Intel Corporation §Þ§ø§œ§Ω§Œ◊”ª·…Á§Œ…ÃòÀ§«§π°£ * §Ω§ŒÀ˚§Œ…Á√˚°¢—u∆∑√˚§ §…§œ°¢“ª∞„§À∏˜…Á§Œ±Ì æ°¢…ÃòÀ§Þ§ø§œµ«Âh…ÃòÀ§«§π°£