Geographic Information Retrieval (GIR)
Download as pptx, pdf3 likes847 views

The document discusses the importance of address information in daily life and the challenges of effectively combining address query services with mapping technologies. It outlines geographic information retrieval methods and systems designed for extracting, indexing, and retrieving georeferenced data, detailing components of a proposed address extraction system. Additionally, the document describes techniques for recognizing geographic names and integrating them with databases to enhance location services.



































Geographic Information Retrieval (GIR)
- 1. GIR Behrooz Rasuli Iranian Research Inst. For Information Science & Technol. rasuli9@gmail.com
- 2. ï― Address information is essential for people's daily life. People often need to query addresses of unfamiliar location through Web and then use map services to mark down the location for direction purpose. Although both address information and map services are available online, they are not well combined.
- 3. ï― ï― ï― general search engines are widely used to retrieve Web pages Specialized search engines are dedicated to find either particular types of resources or Web pages based on different criteria e.g. language or geographic location People use search engines to find Web pages of local services and events around them or in a particular area
- 4. ï― ï― is the data pertaining to the location of geographical entities together with their spatial dimensions Location could be defined as âa place on the Internet where an Internet resource, such as a Web page, is storedâ
- 5. ï― Source Geography âĶ physical location of hosts âĶ signal processing and network-based techniques ï― Target Geography âĶ uses elements contained in the page to deduce locations (place names, postal addresses, and phone numbers) âĶ Challenge: involves evidence extraction, semantic analysis, and interpretation, in order to link Web pages to geographic locations
- 6. ï― ï― Geographic Information Retrieval (GIR) is an applied research field that involves indexing, searching, retrieving, and browsing georeferenced information sources, and designing systems to execute these tasks effectively and efficiently Like IR, GIR includes indexing, storage and ranking
- 7. ï― ï― pattern extraction from raw text has already been done. For example, M. Hearst (1990s) developed an approach for discovering lexico-syntactic patterns for hypernyms
- 8. ï― Pattern-Based Methods; âĶ Named Entity Recognition (NER) âĶ Gazetteer approach (Web-a-Where); âĶ Pattern-based method ï― Ontology-Based Methods; âĶ OnLocus ï― Machine Learning Methods;
- 10. ï― ï― Few commercial geographic search engines have been commercially developed among them Google Map and Yahoo Local are notable ambiguous dynamic nature of location names, various addressing styles, lack of geographic information, and multiple locations related to a Web resource
- 11. ï― ï― ï― extract proper names from texts and documents an algorithm that distinguishes five classes for name of locations: CITY, REGION, COUNTRY, ISLAND, RIVER, and MOUNTAIN method is time-consuming and is not useful for real-time search
- 12. tagging individual place names (geotagger); âĶ finds and disambiguates geographic names (assigning a canonical taxonomy node to each phrase in the text) 1. Spotting; 2. Disambiguation; 3. Focus determination; crawling the Web, storing the resulting pages and indexing their contents ï―
- 13. ï― ï― ï― ï― Basically, a geographic search engine must be able to find related addresses and location names and assign them to Web pages Current address extraction techniques basically require large gazetteers which are expensive and unavailable for many countries different markup styles e.g. HTML, XML and DOM natural language processing models are not able to extract all addresses and location names from Web page contents
- 15. divide an address to its semantic components automatic pattern-based model which uses HTML and visual segmentations to improve address extraction on Web pages new location names much human effort large scale gazetteers
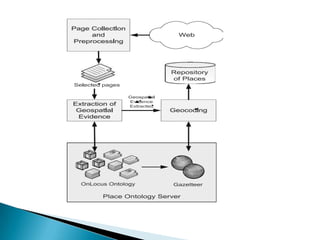
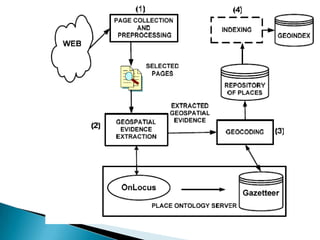
- 16. ï― ï― ï― ï― ï― ï― The proposed address extraction system consists of five components: HTML Pre- Processor, Parser, Knowledge Searcher, Decision Maker, and Knowledge Accumulator
- 17. ï― ï― ï― ï― ï― analyze HTML tags and codes; convert HTML files to XML (by employing the VIPS Demo software); in-depth analyzing and traversing the XML to obtain content information; sorting them in a linear sequence together with their node numbers; a node index is built
- 18. ï― ï― ï― It tries to find all candidate phrases (potential addresses) in a node; divides a potential address into its component; Each segment obtained in this step, will be utilized as default searching unit of Database Searcher;
- 19. ï― ï― itemizes elements of a potential address; It finds all possibilities of a potential address and forms them into a list of possible patterns in three steps: âĶ Standardizing Word Formats (different spells, abbreviations, synonyms) âĶ Knowledge-Base Place Name Matching (separates elements into more delicate level) âĶ Ambiguity Eliminating (tries to match place name)
- 20. ï― ï― whether a candidate phrase is an address or not; by matching it with address patterns already stored in a database; âĶ Delimitating ambiguities and conflicts of place names (syntactic and semantic: geo/non-geo and geo/geo); âĶ Itemizing each potential address to its elements; âĶ Adding the lost parts to address based on a location tree wherever it is possible the address âNo. 10, William Street, Toowong, Queenslandâ will be modified as âNo. 10, William Street, Toowong, Brisbane, Queensland, Australiaâ
- 21. ï― the last component of the system; exhibits in two aspects: âĶ Location Accumulation; âĶ Address Pattern Accumulation
- 22. ï― ï― there are 9 lemmas in KB; 3 lemmas have multiple identities (Victoria, Churchill, Howard Avenue); Following algorithm indicates how place names are detected in Phrases âĶ âĶ âĶ âĶ âĶ PW - A candidate phrase W - the ith word in PW f - any syntactic format of W KB - Knowledge-Base C - Result Collection i i i Inputs
- 23. 1. PW(pre word, Wi) { 2. if ((pre word + f) = a place name found in KB) 3. add (pre word + f) to Ci; 4. if (pre word + f) = part of a name in KB 5. pre word = pre word + f; 6. PW(pre word, Wi+1);//try next word in PW
- 24. 1. 2. 3. 4. SyntacticAE(Potential) { current word = first word in Potential C = NULL; //initialize C While current word != EOF 6. C = SAE (C, current word); //add longest result in C 7. current word = next new word in Potential;
- 25. ï― âĒ âĒ âĒ âĒ inconsistencies between accumulated knowledge in KB and extracted information from the Web: âĶ misspelling and synonymy âĶ incompleteness of KB Keeping the Conflict Removing Meaningless Conflict Element Finding Synonymous Sub-tree Merging Synonymous Sub-Tree
- 27. ï― Direct references âĶ place names, complete postal addresses ï― Indirect references âĶ postal codes and telephone area codes, or from expressions that indicate relationships to other places, which are directly referenced (for instance, âThe hotel is two blocks from Times Squareâ)
- 28. ï― propose a three-phase process for recognizing geographic evidence in Web pages: âĶ Extraction (selecting relevant Web content), âĶ Recognition (corresponds to isolating references to places embedded in text and includes dealing with ambiguity), âĶ Location (obtains locations from the place descriptions previously recognized, using positioning data from gazetteers or from spatial databases)
- 29. ï― ï― an extraction ontology is able to identify objects and relationships; ontology must describe rules for identifying elements within its domain that are present in Web pages
- 30. ï― recognition of terms and expressions as place names; âĶ compared to a gazetteer: Alexandria and GeoNames
- 32. ï― try to determine an actual location from a gazetteer or performing a process known as geocoding ï― Location of direct references ï― âĶ matching and locating ï― Location of indirect references âĶ Formal ï establish a correspondence between a code and the area it serves (supported by spatial databases) âĶ Informal ï natural language interpretation is required
- 35. ï― ï― ï― apply Text Mining procedures to the Internet in order to classify places into different location types (e.g., Maebashi is a CITY, Honshu is an ISLAND) and to determine for a given place name, where the place is (e.g. Maebashi is in Japan, Honshu is in the Pacific ocean); acquire exhaustive fine-grained gazetteers automatically and thus avoid hand-coding; distinguish 6 location types (CITY, REGION, COUNTRY, ISLAND, RIVER, MOUNTAIN)
- 36. ï― ï― dataset consists of 1260 names of locations For each class constructed a set of patterns âĶ patterns have the form âKEYWORD+of+Xâ and âX+KEYWORDâ (Alta Vista counts) ï― ï― Each class has from 3 (ISLAND) up to 10 (MOUNTAIN) different keywords Keywords and patterns were selected manually
- 37. ï― For example, for the class CITY use 4 keywords (âcityâ, âtownâ, âmayorâ, âstreetsâ) and 7 corresponding patterns (âcity+ of+Xâ, âX+cityâ, âtown+of+Xâ, âmayor+of+Xâ, âX+ mayorâ, âstreets+of+Xâ, and âX+streetsâ
- 38. Thank You! Presented in Information Retrieval Course, under supervision of Dr. Saeid Asadi