Glibc malloc internal
?Download as PPT, PDF?
179 likes?64,679 views

glibc mallocż╬ĮŌšh Video: https://youtu.be/0-vWT-t0UHg

















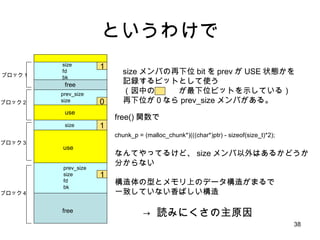


![small bin 16 24 32 40 504 ??? size index 2 63 3 4 5 chunks ż│żņżŪąĪżĄżżźĄźżź║ż╬ malloc ż¼ /* 8 ż╬▒Č╩²ż╦ŪążĻ╔Žż▓ */ size = request2size(req); if( size <= 512 ) { bin_index = size/8; chunk = bins[bin_index].bk; unlink(chunk); /* remove freelist */ return chunk + sizeof(size_t)*2; } ż│ż╬ż░żķżż║åģgż╦ĮKż’żļ śŗįņ╠Õż╚ż½żŽż┐żżżŲżżĪóż│ż╬ż░żķżżż╬źĄźżź║ż╦ż¬żĄż▐żļżĶż═Ż┐ best fit ż╔ż│żĒż½Īó just fit źóźĒź▒®`ź┐żŪż╣żĶĪŻż╚ 8 8 8 8 8 bin width free list head ż╬┼õ┴ą](https://image.slidesharecdn.com/glibcmalloc-110710054847-phpapp01/85/Glibc-malloc-internal-43-320.jpg)










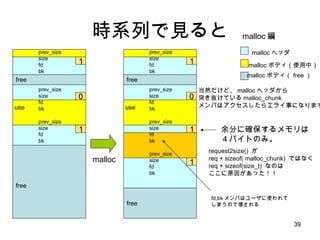
![źąź├źšźĪż╬▀Wčė║Ž╠Õ żĮż╬Ż▓ gligc malloc żŪżŽūŅĄ═┤_▒ŻźĄźżź║ż¼ 32 ż╩ż╬żŪ bins[0] ż╚ bins[1] żŽ╩╣ż├żŲż╩żż bins[1] ż“ż│ż╬▀WčėżĄżņżŲżļ block ż“ż─ż╩ż▓żļźĻź╣ź╚ż╬źĻź╣ź╚źžź├ź╔ż╚żĘżŲ╠žäeż╩ęŌ╬ČżŪė├żżżļ źĮ®`ź╣ź│®`ź╔╔ŽżŽ unsorted_chunk ż╚║¶żążņżŲżżżļż¼ĪóźĮ®`ź╚żĘż╩żżŻĮĢrŽĄ┴ąĒśżŪżóżļĪŻ źĻź╣ź╚ż“ż┐ż░ż├żŲĪóę¬Ū¾źĄźżź║ż╚ę╗ų┬ż╣żļżŌż╬ż“Ś╩╦„ ę¬Ū¾źĄźżź║ż╚ę╗ų┬żĘż╩żżżŌż╬żŽĪóż│ż╬ĢrĄŃżŪĪóļOż╚üŃ║ŽżĘżŲīgļHż╬ free äI└Ē](https://image.slidesharecdn.com/glibcmalloc-110710054847-phpapp01/85/Glibc-malloc-internal-57-320.jpg)
















Glibc malloc internal
- 1. malloc ż╬┬├Ż© glibc ŠÄŻ® kosaki Ż└ż╠ż▐ż┼
- 2. Į±╚šżŽ║╬ż╬įÆŻ┐ libc żŪżŌż├ż╚żŌ┴╝ż»╩╣ż’żņżļķv╩²Īó malloc ż╚ free ż╬īgū░ż╬ĮŌšh żŌż├ż╚ę╗░ŃĄ─ż╦čįż”ż╚ĪóźūźĒź╗ź╣ż╬źóź╔źņź╣┐šķgż╬ż”ż┴Īó heap ŅIė“ż╚żĶżążņżļĪół÷╦∙ż“▓┘ū„ż╣żļķv╩²ż╬šh├„ ĮŌšhż╚żżż”ż╚┬äż│ż©żŽżżżżż¼ĪóżĮż¾ż╩┤¾īėż╩żŌż╬żĖżŃż╩żż
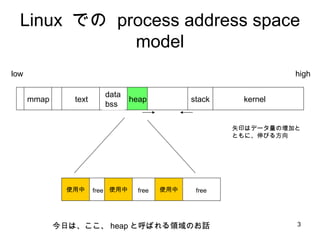
- 3. Linux żŪż╬ process address space model kernel stack text mmap data bss heap ╩ĖėĪżŽźŪ®`ź┐┴┐ż╬ēł╝ėż╚ ż╚żŌż╦Īó╔ņżėżļĘĮŽ“ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą Į±╚šżŽĪóż│ż│Īó heap ż╚║¶żążņżļŅIė“ż╬ż¬įÆ low high free free free
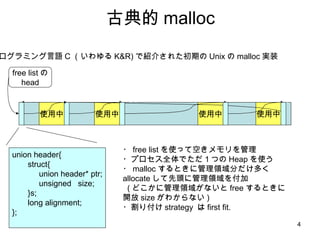
- 4. ╣┼ĄõĄ─ malloc źūźĒź░źķź▀ź¾ź░čįšZ C Ż©żżż’żµżļ K&R) żŪĮBĮķżĄżņż┐│§Ų┌ż╬ Unix ż╬ malloc īgū░ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ? free list ż“╩╣ż├żŲ┐šżŁźßźŌźĻż“╣▄└Ē ?źūźĒź╗ź╣╚½╠ÕżŪż┐ż└Ż▒ż─ż╬ Heap ż“╩╣ż” ? malloc ż╣żļż╚żŁż╦╣▄└ĒŅIė“Ęųż└ż▒ČÓż» allocate żĘżŲŽ╚Ņ^ż╦╣▄└ĒŅIė“ż“ĖČ╝ė ( ż╔ż│ż½ż╦╣▄└ĒŅIė“ż¼ż╩żżż╚ free ż╣żļż╚żŁż╦ķ_Ę┼ size ż¼ż’ż½żķż╩żż ) ?ĖŅżĻĖČż▒ strategy żŽ first fit. union header{ struct{ union header* ptr; unsigned size; }s; long alignment; };
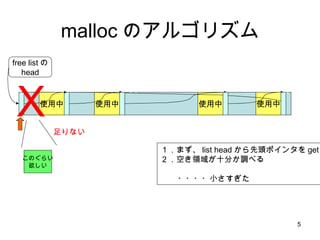
- 5. malloc ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ż│ż╬ż░żķżż ė¹żĘżż Żž ūŃżĻż╩żż Ż▒Ż«ż▐ż║Īó list head ż½żķŽ╚Ņ^ź▌źżź¾ź┐ż“ get Ż▓Ż«┐šżŁŅIė“ż¼╩«Ęųż½š{ż┘żļ ????ąĪżĄż╣ż«ż┐
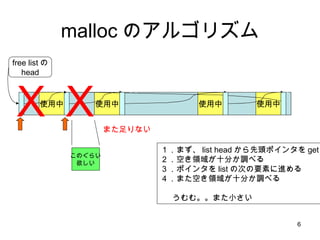
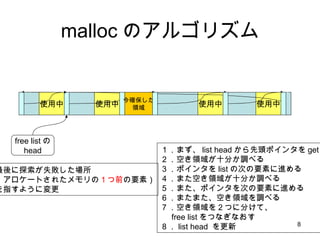
- 6. malloc ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą Żž ż▐ż┐ūŃżĻż╩żż Żž ż│ż╬ż░żķżż ė¹żĘżż Ż▒Ż«ż▐ż║Īó list head ż½żķŽ╚Ņ^ź▌źżź¾ź┐ż“ get Ż▓Ż«┐šżŁŅIė“ż¼╩«Ęųż½š{ż┘żļ Ż│Ż«ź▌źżź¾ź┐ż“ list ż╬┤╬ż╬ę¬╦žż╦▀Mżßżļ Ż┤Ż«ż▐ż┐┐šżŁŅIė“ż¼╩«Ęųż½š{ż┘żļ ż”żÓżÓĪŻĪŻż▐ż┐ąĪżĄżż
- 7. malloc ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą Ż▒Ż«ż▐ż║Īó list head ż½żķŽ╚Ņ^ź▌źżź¾ź┐ż“ get Ż▓Ż«┐šżŁŅIė“ż¼╩«Ęųż½š{ż┘żļ Ż│Ż«ź▌źżź¾ź┐ż“ list ż╬┤╬ż╬ę¬╦žż╦▀Mżßżļ Ż┤Ż«ż▐ż┐┐šżŁŅIė“ż¼╩«Ęųż½š{ż┘żļ ŻĄŻ«ż▐ż┐Īóź▌źżź¾ź┐ż“┤╬ż╬ę¬╦žż╦▀Mżßżļ ŻČŻ«ż▐ż┐ż▐ż┐Īó┐šżŁŅIė“ż“š{ż┘żļ Į±Č╚żŽżóż├ż┐ŻĪŻĪ Żž ŻŽŻ╦ Żž ż│ż╬ż░żķżż ė¹żĘżż
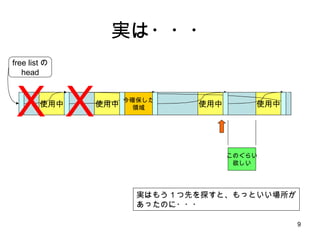
- 8. malloc ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą Ż▒Ż«ż▐ż║Īó list head ż½żķŽ╚Ņ^ź▌źżź¾ź┐ż“ get Ż▓Ż«┐šżŁŅIė“ż¼╩«Ęųż½š{ż┘żļ Ż│Ż«ź▌źżź¾ź┐ż“ list ż╬┤╬ż╬ę¬╦žż╦▀Mżßżļ Ż┤Ż«ż▐ż┐┐šżŁŅIė“ż¼╩«Ęųż½š{ż┘żļ ŻĄŻ«ż▐ż┐Īóź▌źżź¾ź┐ż“┤╬ż╬ę¬╦žż╦▀Mżßżļ ŻČŻ«ż▐ż┐ż▐ż┐Īó┐šżŁŅIė“ż“š{ż┘żļ ŻĘŻ«┐šżŁŅIė“ż“Ż▓ż─ż╦Ęųż▒żŲĪó free list ż“ż─ż╩ż«ż╩ż¬ż╣ ŻĖŻ« list head ż“Ė³ą┬ Į±┤_▒ŻżĘż┐ ŅIė“ ūŅßßż╦╠Į╦„ż¼╩¦öĪżĘż┐ł÷╦∙ Ż©źóźĒź▒®`ź╚żĄżņż┐źßźŌźĻż╬ Ż▒ż─Ū░ ż╬ę¬╦žŻ® ż“ųĖż╣żĶż”ż╦ēõĖ³
- 9. īgżŽ??? ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą īgżŽżŌż”Ż▒ż─Ž╚ż“╠Įż╣ż╚ĪóżŌż├ż╚żżżżł÷╦∙ż¼ żóż├ż┐ż╬ż╦??? Żž Żž ż│ż╬ż░żķżż ė¹żĘżż Į±┤_▒ŻżĘż┐ ŅIė“
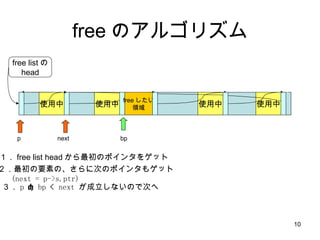
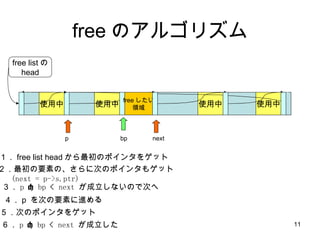
- 10. free ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą free żĘż┐żż ŅIė“ Ż▒Ż« free list head ż½żķūŅ│§ż╬ź▌źżź¾ź┐ż“ź▓ź├ź╚ Ż▓Ż«ūŅ│§ż╬ę¬╦žż╬Ī󿥿ķż╦┤╬ż╬ź▌źżź¾ź┐żŌź▓ź├ź╚ (next = p->s.ptr) Ż│Ż« p < bp < next ż¼│╔┴óżĘż╩żżż╬żŪ┤╬żž bp p next
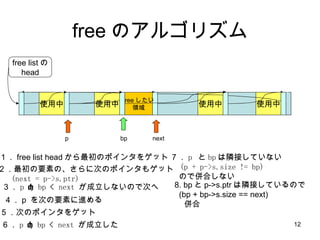
- 11. free ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą free żĘż┐żż ŅIė“ bp p next Ż▒Ż« free list head ż½żķūŅ│§ż╬ź▌źżź¾ź┐ż“ź▓ź├ź╚ Ż▓Ż«ūŅ│§ż╬ę¬╦žż╬Ī󿥿ķż╦┤╬ż╬ź▌źżź¾ź┐żŌź▓ź├ź╚ (next = p->s.ptr) Ż│Ż« p < bp < next ż¼│╔┴óżĘż╩żżż╬żŪ┤╬żž Ż┤Ż« p ż“┤╬ż╬ę¬╦žż╦▀Mżßżļ 5 Ż«┤╬ż╬ź▌źżź¾ź┐ż“ź▓ź├ź╚ 6 Ż« p < bp < next ż¼│╔┴óżĘż┐
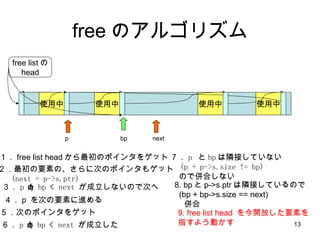
- 12. free ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą bp p 7 Ż« p ż╚ bp żŽļOĮėżĘżŲżżż╩żż (p + p->s.size != bp) ż╬żŪüŃ║ŽżĘż╩żż next Ż▒Ż« free list head ż½żķūŅ│§ż╬ź▌źżź¾ź┐ż“ź▓ź├ź╚ Ż▓Ż«ūŅ│§ż╬ę¬╦žż╬Ī󿥿ķż╦┤╬ż╬ź▌źżź¾ź┐żŌź▓ź├ź╚ (next = p->s.ptr) Ż│Ż« p < bp < next ż¼│╔┴óżĘż╩żżż╬żŪ┤╬żž Ż┤Ż« p ż“┤╬ż╬ę¬╦žż╦▀Mżßżļ 5 Ż«┤╬ż╬ź▌źżź¾ź┐ż“ź▓ź├ź╚ 6 Ż« p < bp < next ż¼│╔┴óżĘż┐ 8. bp ż╚ p->s.ptr żŽļOĮėżĘżŲżżżļż╬żŪ (bp + bp->s.size == next) üŃ║Ž free żĘż┐żż ŅIė“
- 13. free ż╬źóźļź┤źĻź║źÓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą bp p 7 Ż« p ż╚ bp żŽļOĮėżĘżŲżżż╩żż (p + p->s.size != bp) ż╬żŪüŃ║ŽżĘż╩żż next Ż▒Ż« free list head ż½żķūŅ│§ż╬ź▌źżź¾ź┐ż“ź▓ź├ź╚ Ż▓Ż«ūŅ│§ż╬ę¬╦žż╬Ī󿥿ķż╦┤╬ż╬ź▌źżź¾ź┐żŌź▓ź├ź╚ (next = p->s.ptr) Ż│Ż« p < bp < next ż¼│╔┴óżĘż╩żżż╬żŪ┤╬żž Ż┤Ż« p ż“┤╬ż╬ę¬╦žż╦▀Mżßżļ 5 Ż«┤╬ż╬ź▌źżź¾ź┐ż“ź▓ź├ź╚ 6 Ż« p < bp < next ż¼│╔┴óżĘż┐ 8. bp ż╚ p->s.ptr żŽļOĮėżĘżŲżżżļż╬żŪ (bp + bp->s.size == next) üŃ║Ž 9. free list head ż“Į±ķ_Ę┼żĘż┐ę¬╦žż“ ųĖż╣żĶż”äėż½ż╣
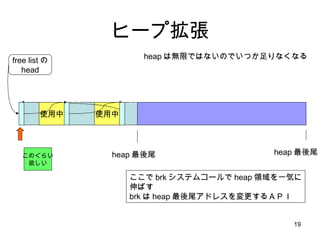
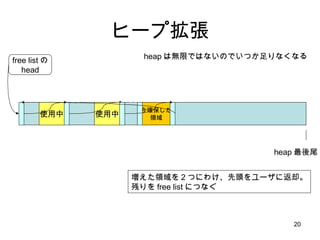
- 14. ┤╬ż╦ malloc ż╬╠ž╩Ōż╩ź▒®`ź╣ heap ż╦ż▐ż├ż┐ż»┐šżŁż¼ż╩ż»żŲ heap ūį╠Õż“ÆłÅłż╣żļź▒®`ź╣ż“ šh├„żĘż▐ż╣
- 15. źę®`źūÆłÅł ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ż│ż╬ż░żķżż ė¹żĘżż heap żŽ¤oŽ▐żŪżŽż╩żżż╬żŪżżż─ż½ūŃżĻż╩ż»ż╩żļ Żž ūŃżĻż╩żż
- 16. źę®`źūÆłÅł ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ż│ż╬ż░żķżż ė¹żĘżż heap żŽ¤oŽ▐żŪżŽż╩żżż╬żŪżżż─ż½ūŃżĻż╩ż»ż╩żļ Żž ūŃżĻż╩żż Żž
- 17. źę®`źūÆłÅł ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ż│ż╬ż░żķżż ė¹żĘżż heap żŽ¤oŽ▐żŪżŽż╩żżż╬żŪżżż─ż½ūŃżĻż╩ż»ż╩żļ Żž ūŃżĻż╩żż Żž Żž
- 18. źę®`źūÆłÅł ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ż│ż╬ż░żķżż ė¹żĘżż heap żŽ¤oŽ▐żŪżŽż╩żżż╬żŪżżż─ż½ūŃżĻż╩ż»ż╩żļ Żž Żž Żž ptr ż╚ free list ż╬ head ż¼į┘żėę╗ų┬ Ż©ę╗ų▄żĘżŲżĘż▐ż├ż┐Ż®
- 19. źę®`źūÆłÅł ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ż│ż╬ż░żķżż ė¹żĘżż heap żŽ¤oŽ▐żŪżŽż╩żżż╬żŪżżż─ż½ūŃżĻż╩ż»ż╩żļ ż│ż│żŪ brk źĘź╣źŲźÓź│®`źļżŪ heap ŅIė“ż“ę╗Ü▌ż╦ ╔ņżąż╣ brk żŽ heap ūŅßß╬▓źóź╔źņź╣ż“ēõĖ³ż╣żļŻ┴ŻąŻ╔ heap ūŅßß╬▓ heap ūŅßß╬▓
- 20. źę®`źūÆłÅł ╩╣ė├ųą ╩╣ė├ųą heap żŽ¤oŽ▐żŪżŽż╩żżż╬żŪżżż─ż½ūŃżĻż╩ż»ż╩żļ heap ūŅßß╬▓ Į±┤_▒ŻżĘż┐ ŅIė“ ēłż©ż┐ŅIė“ż“ 2 ż─ż╦ż’ż▒ĪóŽ╚Ņ^ż“źµ®`źČż╦ĘĄ╚┤ĪŻ ▓ążĻż“ free list ż╦ż─ż╩ż░ free listż╬ head
- 21. żõżõ═čŽ▀
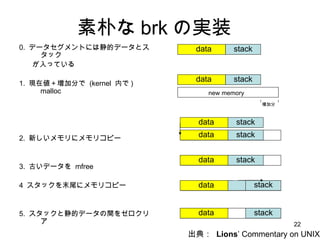
- 22. ╦žŲėż╩ brk ż╬īgū░ 0. źŪ®`ź┐ź╗ź░źßź¾ź╚ż╦żŽŠ▓Ą─źŪ®`ź┐ż╚ź╣ź┐ź├ź» ż¼╚ļż├żŲżżżļ 1. ¼Fį┌éÄŻ½ēł╝ėĘųżŪ (kernel ─┌żŪ ) malloc 2. ą┬żĘżżźßźŌźĻż╦źßźŌźĻź│źį®` 3. ╣┼żżźŪ®`ź┐ż“ mfree 4 ź╣ź┐ź├ź»ż“─®╬▓ż╦źßźŌźĻź│źį®` 5. ź╣ź┐ź├ź»ż╚Š▓Ą─źŪ®`ź┐ż╬ķgż“ź╝źĒź»źĻźó new memory data data stack stack │÷ĄõŻ║ Lions Ī» Commentary on UNIX ēł╝ėĘų data stack data stack data stack data stack data stack
- 23. ż─ż▐żĻ ź½®`ź═źļ brk ż¼ż»żĮ▀Wżż żóż¾ż▐żĻ brk ║¶żąż╩ż»żŲżŌżżżżżĶż”ż╦Īóźµ®`źČ®`┐šķgżŪĪĖż╩żļż┘ż» brk żĘż╩żżĪŻż╣żļż╚żŁżŽź¼źąź├ż╚ę╗Ü▌ż╦╚ĪżļĪ╣ĘĮßśżŪżżż» ż╚ż½żżż”ü²éÄėQżŪīgū░żĄżņżŲż¬żĻż▐ż╣żļ
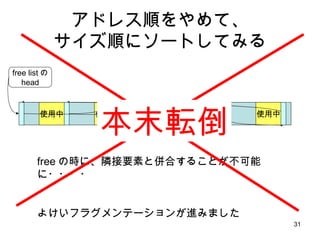
- 24. żĄżŲ īgżŽ brk żŌĪóźżź▐ź╔źŁż╬ Linux żŪżŽ┤¾Ę∙ż╦Ė▀╦┘ż╦ż╩ż├żŲżżżļż╬ż└ż¼ĪóżĮżņżŽĮ±╗žżŽ┐╝ż©ż╩żż╩┬ż╦ż╣żļ Į±żŽŻŌŻ“Żļż¼▀Wżżż├żŲŪ░╠ßżŪ malloc ż╬Ė▀╦┘╗»ż“┐╝ż©żŲżżż»ż╝żż ═čŠĆĮKż’żĻ
- 25. K&R malloc ż╬żżżżż╚ż│żĒ ģg╝ā ź│®`ź╔źĄźżź║ż¼ąĪżĄżżĪŻ Ż©ĮMż▀▐zż▀ż╚ż½żŌ malloc żŽżżż▐ż└ż╦ż│ż¾ż╩ą╬żĘż╚żļżĶŻ® źšźķź░źßź¾źŲ®`źĘźńź¾ż¼▀Mż▐ż╩żżŽ▐żĻ malloc żŽ O(1) źūźĒź░źķźÓ╚½╠ÕżŪ╩²╩«╗žżĘż½ malloc żĘż╩żżżĶż”ż╩ąĪęÄ─ŻźūźĒź░źķźÓżŪżŽż╚żŲżŌż”ż▐ż»äėż»
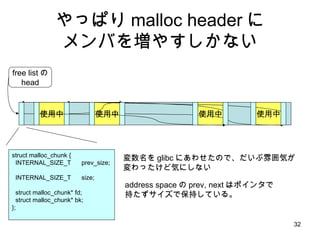
- 26. K&R malloc ż╬ź└źßż╩ż╚ż│żĒ ąĪżĄżż malloc ż¼ČÓ░kż╣żļż╚ źšźķź░źßź¾źŲ®`źĘźńź¾ż¼ż╣ż░▀MżÓ free ż¼ O(n) brk ż¼║¶żążņżļū┤ørżŪżŽę╗╗ž freelist ż“ę╗ų▄ż╣żļ▒žę¬ż¼żóżļ Ż©źĻź╣ź╚ż¼╩²═“éĆżŌżóżņżąĪóż╩ż╦żĮż╬źŁźŃź├źĘźÕ?źšźķź├źĘź¾ź░?ź│®`ź╔ū┤æBŻ® źšźķź░źßź¾źŲ®`źĘźńź¾ż¼▀MżÓż╚źßźŌźĻä┐┬╩żŌ╝▒╝żż╦ÉÖ╗»
- 27. Ģr┤·żŽēõż’ż├ż┐??? źżź▐ź╔źŁż╩źūźĒź░źķź▀ź¾ź░ GUI ź╣ź»źĻźūź╚čįšZżõ Java C++ źūźĒź░źķź▀ź¾ź░ Ą╚Ī® żŽĪóż▐żĄż╦ąĪżĄżż malloc ż¼▀B░kżĄżņżļ
- 28. ūŅ┤¾ż╬å¢Ņ}żŽż╩ż¾ż└żĒż”Ż┐ ż│ż│żŽĪóż╚żĻżóż©ż║źšźķź░źßź¾źŲ®`źĘźńź¾ż¼ūŅ┤¾ż╬å¢Ņ}ż└ż╚üóČ©żĘżĶż” źšźķź░źßź¾źŲ®`źĘźńź¾żĄż©ĮŌøQż╣żņżą źßźŌźĻ╩╣ė├ä┐┬╩ UP! ╩╣ė├źßźŌźĻ┴┐ż¼£pżņżąĪóżĮżņż└ż▒źŁźŃź├źĘźÕż╦▌dżļ┤_┬╩ UP! ż╩ż¾ż½ ?? ( ??? ) ?? !
- 29. ż╚żµ®`ż’ż▒żŪĪóĢr┤·żŽ best fit źóźĒź▒®`ź┐ż╩ż╬żŪżóżļ
- 30. żŪĪó Just Idea ż╦ÅŠż├żŲ īgū░żĘżŲż▀żļ
- 31. źóź╔źņź╣Ēśż“żõżßżŲĪó źĄźżź║Ēśż╦źĮ®`ź╚żĘżŲż▀żļ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą free ż╬Ģrż╦ĪóļOĮėę¬╦žż╚üŃ║Žż╣żļż│ż╚ż¼▓╗┐╔─▄ż╦???? żĶż▒żżźšźķź░źßź¾źŲ®`źĘźńź¾ż¼▀Mż▀ż▐żĘż┐ ▒Š─®▄ץ╣
- 32. żõż├żčżĻ malloc header ż╦ źßź¾źąż“ēłżõż╣żĘż½ż╩żż struct malloc_chunk { INTERNAL_SIZE_T prev_size; INTERNAL_SIZE_T size; struct malloc_chunk* fd; struct malloc_chunk* bk; }; ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą ēõ╩²├¹ż“ glibc ż╦żóż’ż╗ż┐ż╬żŪĪóż└żżżųļāćņÜ▌ż¼ ēõż’ż├ż┐ż▒ż╔Ü▌ż╦żĘż╩żż address space ż╬ prev, next żŽź▌źżź¾ź┐żŪ │ųż┐ż║źĄźżź║żŪ▒Ż│ųżĘżŲżżżļĪŻ
- 33. ║╬ż¼ēõż’ż├ż┐ż╬ż½ ┴╝ż»ż╩ż├ż┐ż╚ż│żĒ free ż¼ typical żŪ O(n) ż½żķ O(1) żž źšźķź░źßź¾źŲ®`źĘźńź¾ż╦żĶżļ┐šķgż╬¤o±jż¼£pżļ ÉÖż»ż╩ż├ż┐ż╚ż│żĒ malloc ż¼ typical żŪ O(1) ż½żķ O(n) żž źžź├ź└źĄźżź║ż¼ēłż©żŲ┐šķgä┐┬╩ź└ź”ź¾
- 35. źžź├ź└ż╬ź└źżź©ź├ź╚ż¼▒žę¬żŪż╣ ż▐ż║Īó free list ż╬ź▌źżź¾ź┐Īó bk, fd żŽĖŅżĻĖČż▒£gż▀źųźĒź├ź»ż╦żŽ▒žę¬ż╩żż ż│żņżŽģg╝āż╦Ž„żņżążżżż źóź»ź╗ź╣ĘĮĘ©ż╦żŽūóęŌ prev_size size fd bk malloc_chunk śŗįņ╠Õż╦źŁźŃź╣ź╚żĘżŲ źóź»ź╗ź╣ż╣żļż╬żŪę╗ęŖĪó fd, bk źßź¾źąż¼ żóżļżĶż”ż╦ęŖż©żļż¼ĪóīgżŽżĮż│żŽ źµ®`źČźóźūźĻż╦╩╣ż’żņżŲżĘż▐ż├żŲżżżļż╬żŪ źóź»ź╗ź╣ż╣żļż╚źßźŌźĻŲŲē▓ źĮ®`ź╣ź│®`ź╔ż½żķżŽšiż▀╚ĪżĻż╦ż»żż??
- 36. ź└źżź©ź├ź╚żŽż─ż┼ż»żĶ??? żĶ®`ż»┐╝ż©żļż╚ prev_size źßź¾źążŽ free Ģrż╬║ŽüŃäI└Ēż╬ż▀ż╦▒žę¬ ż╚żµ®`ż│ż╚żŽĪó prev ż¼ free ū┤æBż╬ż╚żŁż╬ż▀▒žę¬ prev_size żŽ prev ż¼ free ż╬Ģrż╬ż▀ėøÕhżĘż┐żż ż┴żńż├ż╚ż▐ż├żŲ ż╔ż”żõż├żŲĪó prev ż¼ free ū┤æBż½š{ż┘żņżążżżżż¾ż└ż├ż▒Ż┐ Ż©┬čż╚∙Źå¢Ņ}Ż®
- 37. Ž┬╬╗ 2bit żŽĮ~īØŻ░ż╦ż╩żļżĶż═ glibc malloc żŽīgļHż╦żŽ─┌▓┐żŪ 8 ż╬▒Č╩²ż╦ŪążĻ╔Žż▓żļż½żķĪóŽ┬╬╗Ż│ bit żŽ 0 size źßź¾źążŽŻ▓ż─ż╬ź▌źżź¾ź┐ż╬▓Ņż“ėøÕhżĘżŲżżżļż╬ż└ż½żķĪóĄ▒╚╗Īó═¼żĖż»Ž┬╬╗ 3bit ż¼Ż░ 32bit ż╩źĘź╣źŲźÓż╬ź▌źżź¾ź┐ż├żŲ?? Ż░ 31 Ż▒ Ż▓ ź▌źżź¾ź┐ 0 0
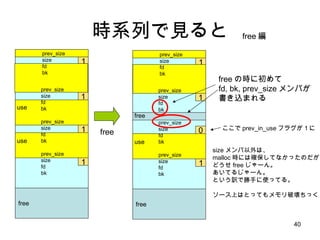
- 38. ż╚żżż”ż’ż▒żŪ prev_size size fd bk size fd bk use free free prev_size size use size 1 0 size źßź¾źąż╬į┘Ž┬╬╗ bit ż“ prev ż¼ USE ū┤æBż½ż“ ėøÕhż╣żļźėź├ź╚ż╚żĘżŲ╩╣ż” Ż©ćĒųąż╬ĪĪĪĪĪĪż¼ūŅŽ┬╬╗źėź├ź╚ż“╩ŠżĘżŲżżżļŻ® į┘Ž┬╬╗ż¼Ż░ż╩żķ prev_size źßź¾źąż¼żóżļĪŻ Ż▒ Ż▒ free() ķv╩²żŪ chunk_p = (malloc_chunk*)(((char*)ptr) - sizeof(size_t)*2); ż╩ż¾żŲżõż├żŲżļż▒ż╔Īó size źßź¾źąęį═ŌżŽżóżļż½ż╔ż”ż½ Ęųż½żķż╩żż śŗįņ╠Õż╬ą═ż╚źßźŌźĻ╔Žż╬źŪ®`ź┐śŗįņż¼ż▐żļżŪ ę╗ų┬żĘżŲżżż╩żżŽŃżążĘżżśŗįņ -> šiż▀ż╦ż»żĄż╬ų„įŁę“ źųźĒź├ź»Ż▒ źųźĒź├ź»Ż▓ źųźĒź├ź»Ż│ źųźĒź├ź»Ż┤
- 39. ĢrŽĄ┴ążŪęŖżļż╚ prev_size size fd bk use free free prev_size size fd bk 0 Ż▒ Ż▒ prev_size size fd bk use free free prev_size size fd bk 0 Ż▒ prev_size size fd bk malloc Ż▒ Ż▒ prev_size size fd bk prev_size size fd bk ėÓĘųż╦┤_▒Żż╣żļźßźŌźĻżŽ Ż┤źąźżź╚ż╬ż▀ĪŻ request2size() ż¼ req + sizeof( malloc_chunk) żŪżŽż╩ż» req + sizeof(size_t) ż╩ż╬żŽ ż│ż│ż╦įŁę“ż¼żóż├ż┐ŻĪŻĪ malloc ŠÄ malloc źžź├ź└ malloc ź▄źŪźŻŻ©╩╣ė├ųąŻ® malloc ź▄źŪźŻŻ© free Ż® Ą▒╚╗ż└ż▒ż╔Īó malloc źžź├ź└ż½żķ ═╗żŁÆiż▒żŲżżżļ malloc_chunk źßź¾źążŽźóź»ź╗ź╣żĘż┐żķź©źķźż╩┬ż╦ż╩żĻż▐ż╣ fd,bk źßź¾źążŽźµ®`źČż╦╩╣ż’żņżŲ żĘż▐ż”ż╬żŪē▓żĄżņżļ
- 40. ĢrŽĄ┴ążŪęŖżļż╚ use free 1 Ż▒ Ż▒ Ż▒ prev_size size fd bk prev_size size fd bk use prev_size size fd bk prev_size size fd bk free free 1 Ż▒ 0 Ż▒ prev_size size fd bk prev_size size fd bk use prev_size size fd bk prev_size size fd bk free ż╬Ģrż╦│§żßżŲ fd, bk, prev_size źßź¾źąż¼ Ģ°żŁ▐zż▐żņżļ size źßź¾źąęį═ŌżŽĪó malloc Ģrż╦żŽ┤_▒ŻżĘżŲż╩ż½ż├ż┐ż╬ż└ż¼ ż╔ż”ż╗ free żĖżŃ®`ż¾ĪŻ żóżżżŲżļżĖżŃ®`ż¾ĪŻ ż╚żżż”įUżŪä┘╩ųż╦╩╣ż├żŲżļĪŻ źĮ®`ź╣╔ŽżŽż╚ż├żŲżŌźßźŌźĻŲŲē▓ż┴ż├ż» free free ŠÄ ż│ż│żŪ prev_in_use źšźķź░ż¼Ż▒ż╦
- 41. ź└źżź©ź├ź╚żŽ│÷└┤ż┐ż╬żŪ żóżļęŌ╬ČĪó▒Š╚šż╬ code reading ż╬ūŅļyķv▓┐ĘųżŽ═╗ŲŲ (^-^; Ż©╦¹ż╬▓┐ĘųżŽĪóż┴żŃż¾ż╚ C čįšZż┴ż├ż»ż╩ C ż╬źĮ®`ź╣ź│®`ź╔ (?) ż╩ż╬żŪŻ® ┤╬żŽūŅ┤¾ż╬šnŅ}ĪŻ malloc() ż¼ typical żŪ O(n) żĖżŃ®`ż¾ĪŻå¢Ņ}ż“Ų¼ĖČż▒żļ
- 42. ż│ż│żŪźóźżźŪźó äeż╦ free list żŪĪóŻ▒ż─ż╬źĻź╣ź╚ż╦╚½▓┐ż─ż╩ż¼ż╩ż»żŲżŌżżżżżĶż═Ż┐ źĄźżź║żŽĮ~īØŻĖż╬▒Č╩²ż╩ż¾ż└ż½żķĪ󟥟żź║Ż▒ŻČė├ż╬źĻź╣ź╚Ī󟥟żź║Ż▓Ż┤ė├ż╬źĻź╣ź╚???? ż├żŲżõż├ż┐żķ best fist ż½ż─ O(1) żĖżŃż═Ż┐
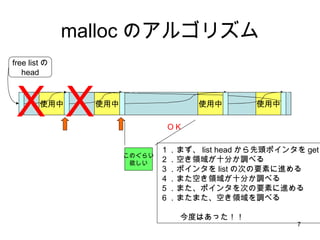
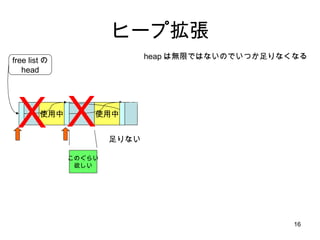
- 43. small bin 16 24 32 40 504 ??? size index 2 63 3 4 5 chunks ż│żņżŪąĪżĄżżźĄźżź║ż╬ malloc ż¼ /* 8 ż╬▒Č╩²ż╦ŪążĻ╔Žż▓ */ size = request2size(req); if( size <= 512 ) { bin_index = size/8; chunk = bins[bin_index].bk; unlink(chunk); /* remove freelist */ return chunk + sizeof(size_t)*2; } ż│ż╬ż░żķżż║åģgż╦ĮKż’żļ śŗįņ╠Õż╚ż½żŽż┐żżżŲżżĪóż│ż╬ż░żķżżż╬źĄźżź║ż╦ż¬żĄż▐żļżĶż═Ż┐ best fit ż╔ż│żĒż½Īó just fit źóźĒź▒®`ź┐żŪż╣żĶĪŻż╚ 8 8 8 8 8 bin width free list head ż╬┼õ┴ą
- 44. żĄżķż╦Ė─┴╝ 512byte over ż╬▓┐Ęųż¼╩ųĖČż½ż║ żŪżŌĪó┤¾żŁżżźĄźżź║ż╦żŌ 8byte ż¬żŁż╦ bin ż“ė├ęŌż╣żļż╬żŽ¼FīgĄ─żĖżŃż╩żż żŪżŌźĻź╣ź╚ż“č}╩²żŌż─ĪŻ ż╚żżż”źóźżźŪźóżŽÉÖż»ż╩żż
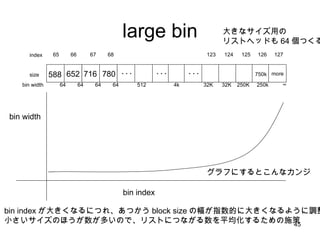
- 45. large bin 588 652 716 780 ??? size index 65 123 66 67 68 64 64 64 64 32K bin width 124 32K 125 250K 126 250k 127 Ī▐ ź░źķźšż╦ż╣żļż╚ż│ż¾ż╩ź½ź¾źĖ bin width bin index bin index ż¼┤¾żŁż»ż╩żļż╦ż─żņĪóżóż─ż½ż” block size ż╬Ę∙ż¼ųĖ╩²Ą─ż╦┤¾żŁż»ż╩żļżĶż”ż╦š{š¹ ąĪżĄżżźĄźżź║ż╬ż█ż”ż¼╩²ż¼ČÓżżż╬żŪĪóźĻź╣ź╚ż╦ż─ż╩ż¼żļ╩²ż“ŲĮŠ∙╗»ż╣żļż┐żßż╬╩®▓▀ ┤¾żŁż╩źĄźżź║ė├ż╬ źĻź╣ź╚źžź├ź╔żŌ 64 éĆż─ż»żļ ??? 512 4k ??? 750k more
- 46. żŪżŌ ż╔ż”ŅBÅłż├żŲżŌĪóę╗Ę¼źķź╣ź╚ż╬ bin żŽę╗▒Łż─ż╩ż¼ż├żŲżĘż▐ż”ż¾ż└żĶż═ ╗ŁŽ±ż╚ż½ÆQż”ż╚ŲĮÜ▌żŪ╩²╩« M ż╚ż½ malloc ż╣żļżĘ???? żó®`żóĪó Heap ż“żŌż”Ż▒ż─ė├ęŌżŪżŁż┐żķ żŪż½żżźßźŌźĻż“═Ļ╚½ż╦ĘųļxżŪżŁżļż╬ż╦??
- 48. anonymous mmap ż╚żŽŻ┐ mmap żŽĪó▒Š└┤źšźĪźżźļż“źßźŌźĻż╦ź▐ź├źūż╣żļźĘź╣źŲźÓź│®`źļ żŪżŌ fd ę²╩²ż╦ Ī░ /dev/zeroĪ▒ ż“Č╔ż╣ż│ż╚ż╦żĶżĻĪóźßźŌźĻ┤_▒Ż API ż╚żĘżŲ╩╣ė├┐╔─▄ ż│ż╬ API ż“╩╣ż├żŲĪó Huge Block( źŪźšź®źļź╚żŪ 128K byte ęį╔Ž ) żŽ heap ż½żķżŪżŽż╩ż»Īó mmap żŪų▒Įė kernel ż½żķ╚ĪĄ├ż╣żļ
- 49. ż▐ż┐żĘżŲżŌ size źßź¾źąż╬Ž┬╬╗ bit ż“ Ż░ 31 Ż▒ Ż▓ size 0 0 0 IS_MMAPED PREV_IN_USE Ž┬ż½żķŻ▓ bit ─┐ż“ mmap ż½żķ╚ĪĄ├żĘż┐żĶ®`ż¾ĪŻ ż╚żżż”ęŌ╬ČżŪ╩╣ż”ż│ż╚ż╦ż╣żļĪŻ ż│ż╬ bit ż¼ ON ż╩żķ free list ż½żķżŪżŽż╩ż» MMAP żŪ╚ĪĄ├ żĘżŲżżżļż╬żŪĪó free Ģrż╦ freelist ż╦ż─ż╩ż¼ż║ż╦Īó żżżŁż╩żĻ munmap() ż╣żļ
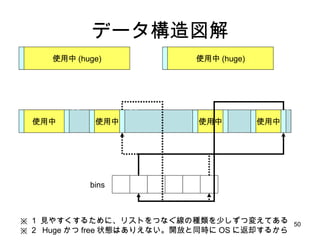
- 50. źŪ®`ź┐śŗįņćĒĮŌ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą (huge) ╩╣ė├ųą (huge) bins Ī∙ Ż▒ ęŖżõż╣ż»ż╣żļż┐żßż╦ĪóźĻź╣ź╚ż“ż─ż╩ż░ŠĆż╬ĘNŅÉż“╔┘żĘż║ż─ēõż©żŲżóżļ Ī∙ Ż▓ Huge ż½ż─ free ū┤æBżŽżóżĻż©ż╩żżĪŻķ_Ę┼ż╚═¼Ģrż╦ OS ż╦ĘĄ╚┤ż╣żļż½żķ
- 51. ż│ż╬ĘĮĘ©ż╬└¹ĄŃ Huge Block żŌ malloc, free ż╚żŌż╦ O(1) źšźķź░źßź¾źŲ®`źĘźńź¾ĪóżÓż├żĄŲżŁż╦ż»żż Ż©źĻź╣ź╚╣▄└ĒżĘżŲż╩żżż¾ż└ż½żķĄ▒ż┐żĻŪ░Ż® źßźŌźĻż╬¤o±jż¼╔┘ż╩żż Ż©żŪż├ż½żżźßźŌźĻżŽ═¼żĖźĄźżź║żŪį┘Č╚ malloc żĄżņżļ┤_┬╩żŽĄ═żżż╬żŪĪóż╣ż░żĄż▐ OS ż╦ĘĄ╚┤ż╣żļż╬żŽ┘tżżæķ┬įŻ®
- 52. ż│ż│ż▐żŪż╬ĮY╣¹ ┴╝ż»ż╩ż├ż┐ż╚ż│żĒ malloc ż¼ typical żŪ O(1) free ż¼ typical żŪ O(1) źšźķź░źßź¾źŲ®`źĘźńź¾ż¼ż╣ż┤ż»ŲżŁż╦ż»ż» źžź├ź└źĄźżź║żŽīg┘|Ż┤źąźżź╚ brk ż¼░k╔·ż╣żļż╚żŁż╦Īó K&R malloc żŪżŽ freelist ż“ę╗ų▄ż╣żļ▒žę¬ż¼żóż├ż┐ż╬ż¼Īóę¬Ū¾źĄźżź║żĶżĻ┤¾żŁżż bin ż“Ś╩╦„ż╣żļż└ż▒żŪżĶż»ż╩ż├ż┐ĪŻ ŲĮŠ∙żŪ╠Į╦„ź│ź╣ź╚ 1/2 ÉÖż»ż╩ż├ż┐ż╚ż│żĒ ż╩ż¾ż½żóż├ż┐ż├ż▒Ż┐
- 53. żŪżŌŻĪ żĮżņżŪżŌŻĪ żĘżążĘżąĪó K&R malloc ż╦ žōż▒żļż¾żŪż╣ĪŻż│żņż¼ īgżŽ large size block ż╬ malloc ©C free ©Cmalloc ©C free ż╚ └RżĻĘĄż╣ĖŅżĻĄ▒żŲż¼▀Wżż
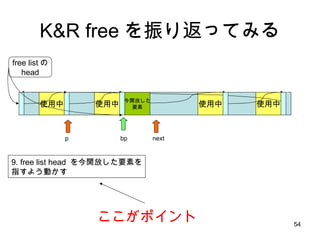
- 54. K&R free ż“š±żĻĘĄż├żŲż▀żļ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą free listż╬ head ╩╣ė├ųą bp p next 9. free list head ż“Į±ķ_Ę┼żĘż┐ę¬╦žż“ ųĖż╣żĶż”äėż½ż╣ Į±ķ_Ę┼żĘż┐ ę¬╦ž ż│ż│ż¼ź▌źżź¾ź╚
- 55. źŁźŃź├źĘźÕż╚Šų╦∙▓╬ššąį heap źßźŌźĻ®`ż╦ę╗Ę¼źóź»ź╗ź╣ż╣żļ┤_┬╩ż¼Ė▀żżż╬żŽ malloc ų▒ßßż╚ free ų▒Ū░żŪżóżļ free żĄżņż┐żąż½żĻż╬źßźŌźĻżŽźŁźŃź├źĘźÕż╦▌dż├żŲżļ┤_┬╩ż¼Ė▀żż żĮż│ż½żķā׎╚żĘżŲźßźŌźĻ┤_▒Żż╣żļż│ż╚żŽ malloc ų▒ßßż╬źóź»ź╗ź╣żŪźŁźŃź├źĘźÕź▀ź╣żĘż╩ż»ż╩żļż╚żżż”ż│ż╚ źŁźŃź├źĘźÕż╬źęź├ź╚┬╩ųžę¬
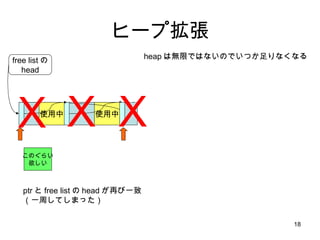
- 56. źąź├źšźĪż╬▀Wčė║Ž╠Õ free ż¼║¶żążņż┐ż╚żŁż╦Īóż╣ż░ż╦ļOż╚üŃ║ŽŻ” free list ż╦ż─ż╩ż░äI└Ēż“żõżßżļ ūŅ│§ż╦ż│ż╬źóźżźŪźóż“īgū░żĘż┐ż╬żŽ SVR4 żķżĘżż ( ūŅŪ░ŠĆ UNIX ż╬ź½®`ź═źļ żĶżĻ ) malloc ©C free ©C malloc ©C free ż╚żżż”ĘŪ│Żż╦żĶż»żóżļźóź»ź╗ź╣źčź┐®`ź¾żŪźßźŌźĻźųźĒź├ź»ż╬Ęųļx?üŃ║Ž?Ęųļx?üŃ║Žż╚żżż”¤o±jż╩äI└Ēż¼▒▄ż▒żķżņżļĪŻ ż½ż─Īó free żĄżņż┐Ēśż╦ĢrŽĄ┴ąż╦źĻź╣ź╚ż╦ż─ż╩ż¼ż├żŲżżżļż╬żŪĪóźĻź╣ź╚Ž╚Ņ^ż╬ block ż“źóźūźĻż╦ĘĄż╗żąźŁźŃź├źĘźÕźęź├ź╚┬╩Ž“╔Ž
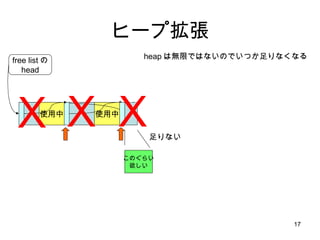
- 57. źąź├źšźĪż╬▀Wčė║Ž╠Õ żĮż╬Ż▓ gligc malloc żŪżŽūŅĄ═┤_▒ŻźĄźżź║ż¼ 32 ż╩ż╬żŪ bins[0] ż╚ bins[1] żŽ╩╣ż├żŲż╩żż bins[1] ż“ż│ż╬▀WčėżĄżņżŲżļ block ż“ż─ż╩ż▓żļźĻź╣ź╚ż╬źĻź╣ź╚źžź├ź╔ż╚żĘżŲ╠žäeż╩ęŌ╬ČżŪė├żżżļ źĮ®`ź╣ź│®`ź╔╔ŽżŽ unsorted_chunk ż╚║¶żążņżŲżżżļż¼ĪóźĮ®`ź╚żĘż╩żżŻĮĢrŽĄ┴ąĒśżŪżóżļĪŻ źĻź╣ź╚ż“ż┐ż░ż├żŲĪóę¬Ū¾źĄźżź║ż╚ę╗ų┬ż╣żļżŌż╬ż“Ś╩╦„ ę¬Ū¾źĄźżź║ż╚ę╗ų┬żĘż╩żżżŌż╬żŽĪóż│ż╬ĢrĄŃżŪĪóļOż╚üŃ║ŽżĘżŲīgļHż╬ free äI└Ē
- 58. ź▐ź»źĒż╩ęĢĄŃżŪįÆż“ż╣żļż╚ malloc ż╬║¶żė│÷żĘźčź┐®`ź¾żŽż┐żżżŲżżęįŽ┬ż╬żĶż”ż╩ĮU▀^ż“żžżļ źóźūźĻŲäėĢrżŽżõż┐żķ malloc ż¼║¶żążņżļĪŻ free żŽż█ż╚ż¾ż╔║¶żążņż╩żż żĮż╬ßßĪó malloc ż╚ free ż¼ż█ż▄Į╗╗źż╦║¶żążņżļČ©│Żū┤æBż╦╚ļżļ GUI ż╬╗Ł├µ▀węŲż╬żĶż”ż╩Īóż╩ż¾ż½żķż╬Ų§ÖCżŪĪó free ż¼żęż┐ż╣żķ║¶żążņĪó┤╬ż╦ malloc ż¼żęż┐ż╣żķ║¶żążņżļźŪ®`ź┐śŗįņż╬┤¾▄×ōQż¼ż¬ż│żļ żĮżĘżŲż▐ż┐Č©│Żū┤æBż╦????
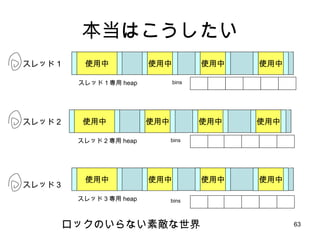
- 59. malloc ż╬ Č©│Żū┤æBż╚źą®`ź╣ź╚ū┤æB źą®`ź╣ź╚ū┤æB źą®`ź╣ź╚ū┤æB ż│ż╬ż╚żŁĪó▀WčėüŃ║Žż¼ čY─┐ż╦│÷żļĪŻ ▀WčėüŃ║ŽźĻź╣ź╚ż╦ę¬╦žż¼ ę╗▒Łż┐ż▐żļż½żķ źßźŌźĻ╩╣ė├┴┐ Č©│Żū┤æB ▀WčėüŃ║ŽżŽčY─┐ż╦żŪżļż│ż╚żŌżóżļż¼Īóżżż┴żąż¾żóżĻż¼ż┴ż╩Īó Č©│Żū┤æBżŪĖ▀╦┘╗»żĄżņżļż╬żŪźŌź╚ż¼ż╚żņżļ
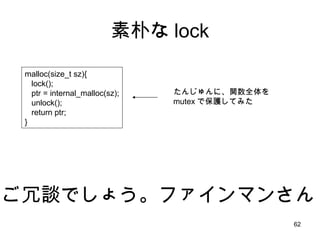
- 62. ╦žŲėż╩ lock malloc(size_t sz){ lock(); ptr = internal_malloc(sz); unlock(); return ptr; } ż┤╚▀šäżŪżĘżńż”ĪŻźšźĪźżź¾ź▐ź¾żĄż¾ ż┐ż¾żĖżÕż¾ż╦Īóķv╩²╚½╠Õż“ mutex żŪ▒ŻūożĘżŲż▀ż┐
- 63. ▒ŠĄ▒żŽż│ż”żĘż┐żż ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą bins ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą bins bins ź╣źņź├ź╔Ż▒ ź╣źņź├ź╔Ż▓ ź╣źņź├ź╔Ż│ ź╣źņź├ź╔Ż▒ī¤ė├ heap ź╣źņź├ź╔ 2 ī¤ė├ heap ź╣źņź├ź╔ 3 ī¤ė├ heap źĒź├ź»ż╬żżżķż╩żż╦žö│ż╩╩└Įń
- 64. żĮżņżŽ┴„╩»ż╦¤o└Ē źóźūźĻż¼żżż»ż─ź╣źņź├ź╔ż“ż─ż»żļż½╩┬Ū░ż╦ų¬żļĘĮĘ©żŽż╩żż Ż▒ż─ż╬ź╣źņź├ź╔ż¼ūŅ┤¾ż╔ż╬ż»żķżżż╬źßźŌźĻż“╩╣ż”ż╬ż½╩┬Ū░ż╦ų¬żļĘĮĘ©żŽż╩żż ITRON ż└ż╚üIĘĮż╚żŌź│ź¾źčźżźļĢrż╦øQż▐żļż╬ż╦??
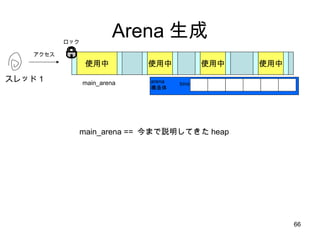
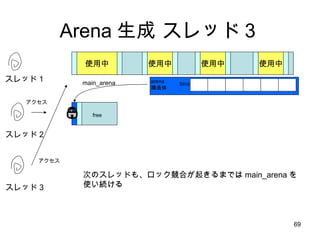
- 66. Arena ╔·│╔ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą bins ź╣źņź├ź╔Ż▒ main_arena main_arena == Į±ż▐żŪšh├„żĘżŲżŁż┐ heap źóź»ź╗ź╣ źĒź├ź» arena śŗįņ╠Õ
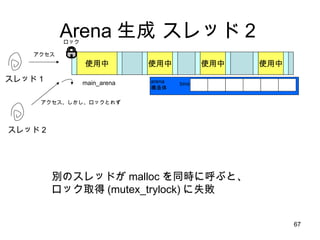
- 67. ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ź╣źņź├ź╔Ż▒ main_arena źóź»ź╗ź╣ źĒź├ź» źóź»ź╗ź╣ĪóżĘż½żĘĪóźĒź├ź»ż╚żņż║ bins arena śŗįņ╠Õ ź╣źņź├ź╔ 2 äeż╬ź╣źņź├ź╔ż¼ malloc ż“═¼Ģrż╦║¶żųż╚Īó źĒź├ź»╚ĪĄ├ (mutex_trylock) ż╦╩¦öĪ Arena ╔·│╔ ź╣źņź├ź╔Ż▓
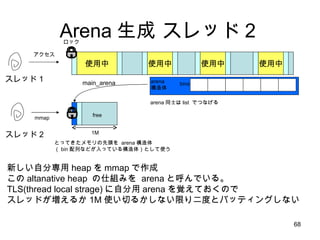
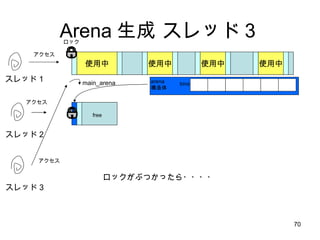
- 68. Arena ╔·│╔ ź╣źņź├ź╔Ż▓ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ź╣źņź├ź╔Ż▒ main_arena źóź»ź╗ź╣ źĒź├ź» ź╣źņź├ź╔ 2 ą┬żĘżżūįĘųī¤ė├ heap ż“ mmap żŪū„│╔ ż│ż╬ altanative heap ż╬╩╦ĮMż▀ż“ arena ż╚║¶ż¾żŪżżżļĪŻ TLS(thread local strage) ż╦ūįĘųė├ arena ż“ęÖż©żŲż¬ż»ż╬żŪ ź╣źņź├ź╔ż¼ēłż©żļż½ 1M ╩╣żżŪążļż½żĘż╩żżŽ▐żĻČ■Č╚ż╚źąź├źŲźŻź¾ź░żĘż╩żż bins arena śŗįņ╠Õ ż╚ż├żŲżŁż┐źßźŌźĻż╬Ž╚Ņ^ż“ arena śŗįņ╠Õ Ż© bin ┼õ┴ąż╩ż╔ż¼╚ļż├żŲżżżļśŗįņ╠ÕŻ®ż╚żĘżŲ╩╣ż” 1M free mmap arena ═¼╩┐żŽ list żŪż─ż╩ż▓żļ
- 69. Arena ╔·│╔ ź╣źņź├ź╔Ż│ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ź╣źņź├ź╔Ż▒ main_arena ź╣źņź├ź╔ 2 bins arena śŗįņ╠Õ free źóź»ź╗ź╣ ź╣źņź├ź╔ 3 źóź»ź╗ź╣ ┤╬ż╬ź╣źņź├ź╔żŌĪóźĒź├ź»Ėé║Žż¼ŲżŁżļż▐żŪżŽ main_arena ż“ ╩╣żżŠAż▒żļ
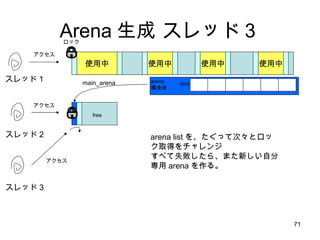
- 70. Arena ╔·│╔ ź╣źņź├ź╔Ż│ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ź╣źņź├ź╔Ż▒ main_arena źóź»ź╗ź╣ źĒź├ź» ź╣źņź├ź╔ 2 bins arena śŗįņ╠Õ free źóź»ź╗ź╣ ź╣źņź├ź╔ 3 źóź»ź╗ź╣ źĒź├ź»ż¼żųż─ż½ż├ż┐żķ????
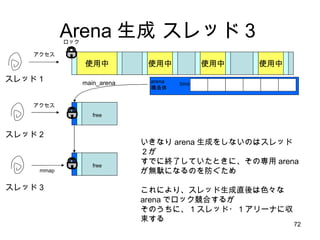
- 71. Arena ╔·│╔ ź╣źņź├ź╔Ż│ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ź╣źņź├ź╔Ż▒ main_arena źóź»ź╗ź╣ źĒź├ź» ź╣źņź├ź╔ 2 bins arena śŗįņ╠Õ free źóź»ź╗ź╣ ź╣źņź├ź╔ 3 źóź»ź╗ź╣ arena list ż“Īóż┐ż░ż├żŲ┤╬Ī®ż╚źĒź├ź»╚ĪĄ├ż“ź┴źŃźņź¾źĖ ż╣ż┘żŲ╩¦öĪżĘż┐żķĪóż▐ż┐ą┬żĘżżūįĘųī¤ė├ arena ż“ū„żļĪŻ
- 72. Arena ╔·│╔ ź╣źņź├ź╔Ż│ ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ╩╣ė├ųą ź╣źņź├ź╔Ż▒ main_arena źóź»ź╗ź╣ źĒź├ź» ź╣źņź├ź╔ 2 bins arena śŗįņ╠Õ free źóź»ź╗ź╣ ź╣źņź├ź╔ 3 mmap żżżŁż╩żĻ arena ╔·│╔ż“żĘż╩żżż╬żŽź╣źņź├ź╔Ż▓ż¼ ż╣żŪż╦ĮK┴╦żĘżŲżżż┐ż╚żŁż╦ĪóżĮż╬ī¤ė├ arena ż¼¤o±jż╦ż╩żļż╬ż“Ę└ż░ż┐żß ż│żņż╦żĶżĻĪóź╣źņź├ź╔╔·│╔ų▒ßßżŽ╔½Ī®ż╩ arena żŪźĒź├ź»Ėé║Žż╣żļż¼ żĮż╬ż”ż┴ż╦Īó 1 ź╣źņź├ź╔? 1 źóźĻ®`ź╩ż╦ģ¦╩°ż╣żļ free
- 73. Ż▒ź╣źņź├ź╔Ż║Ż▒ Arena ż╬ļLżņż┐└¹ĄŃ SMP ź▐źĘź¾żŪżŽĪóäeż╬ CPU ż½żķźóź»ź╗ź╣żĘż┐źßźŌźĻżŽūįĘų CPU ż╬źŁźŃź├źĘźÕż╦żŽü\żķż╩żżż╬żŪźķź╣ź╚źóź»ź╗ź╣ż“ģg╝āż╦╣▄└ĒżĘżŲżŽż”ż▐ż»żżż½ż╩żż żĘż½żĘĪóźµ®`źČ┐šķgż½żķūįĘųż¼ż╔ż╬ CPU żŪäėżżżŲżżżļż╬ż½├„ż╦ęŌūRż╣żļż╬żŽ¤o└Ē Ż©żżż─ż╬ż▐ż╦ż½ä┘╩ųż╦ēõż’żļżĘŻ® żĮż│żŪź½®`ź═źļż¼żŌż─ź╣źņź├ź╔ż╬ CPU affinity ź╣ź▒źĖźÕ®`źĻź¾ź░ż╦ū┼─┐żĘżŲĪóūįĘųź╣źņź├ź╔ż¼źóź»ź╗ź╣żĘż┐źŪ®`ź┐żŽūįĘų CPU żŪźóź»ź╗ź╣żĘż┐┤_┬╩ż¼Ė▀żżż╚┐╝ż©żļ ź╣źņź├ź╔ī¤ė├źßźŌźĻŻĮźŁźŃź├źĘźÕźęź├ź╚┬╩ż¼żŌż╬ż╣ż┤ż» Up!
- 74. ż╚ż│żĒżŪ free ż╣żļż╚żŁż╦ĪóūįĘųż╬╦∙╩¶ż╣żļ arena ż├żŲż╔ż”żõż├żŲęŖż─ż▒żļż¾ż└ż├ż▒Ż┐
- 75. ż└żßźóźżźŪźóŻ▒ TLS ż½żķ arena ż“╚ĪĄ├ -> ūįĘųī¤ė├ arena ż“ū„żļŪ░ż╦ ║╬╗žż½ main_arena ż½żķ╚ĪĄ├ żĘżŲżżżļĘųż¼żóżļĪŻ żĮżņżŽĪó main_arena ż╦æ°żĄż╩żżż╚ĪŻ
- 76. ż└żßźóźżźŪźóŻ▓ żĮżņżŠżņż╬ malloc header ż╦ arena żžż╬ź▌źżź¾ź┐ż“ūĘ╝ėż╣żļ -> ż╩ż¾ż╬ż┐żßż╦╦└ż╠╦╝żżżŪźžź├ź└ż“ Ż┤źąźżź╚ż▐żŪŽ„ż├ż┐ż╚╦╝ż├żŲżļż¾żŪż╣Ż┐
- 77. ż└żßźóźżźŪźóŻ│ main_arena Ż©╬©ę╗ż╬ź░źĒ®`źąźļēõ╩²Ż®ż½żķ arena ż╬źĻź╣ź╚ż“ż┐ż╔ż├żŲ??? -> O(n) ż╬Ś╩╦„żŽź└źßż└ż├ż─ż├żŲż¾ż└żĒŻĪ
- 78. ĮYŠųż╔ż”żĘż┐ż½Ż┐ arena ż“Į~īØ 1M align żĄżņżļżĶż”ż╦źßźŌźĻż“┤_▒Żż╣żļĪŻ ż╣żļż╚Īó ptr & ~0xFFFFF ż╣żļż└ż▒żŪ arena żžż╬ź▌źżź¾ź┐ż¼Ą├żķżņżļżĶż”ż╦ż╣żļ
- 79. šnŅ} 1 main_arena żŽź░źĒ®`źąźļēõ╩²ż╩ż¾ż└ż▒ż╔??? Ż░ 31 Ż▒ Ż▓ size 0 0 0 IS_MMAPED PREV_IN_USE -> Ü░Č╚ż¬ż╩żĖż▀ size źßź¾źąźŽź├ź»ż╬ż¬ĢrķgżŪż┤żČżżż▐Ī½ż╣? IS_NON_MAINARENA
- 80. šnŅ} 2 Linux ż╦ 1M align ż“▒ŻšŽż╣żļźßźŌźĻ┤_▒ŻźĘź╣źŲźÓź│®`źļż├żŲż╩żżż¾ż└ż▒ż╔ -> ęįŽ┬ż╬ż┴żńż├ż╚ź╚źĻź├źŁ®`ż╩ĘĮĘ©żŪ┐╔─▄ ĪĪĪĪĪĪĪĪŻ©┤╬ź┌®`źĖ▓╬ššŻ®
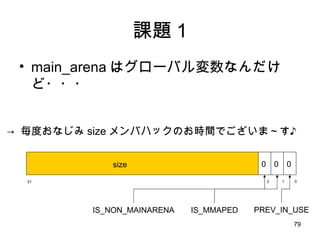
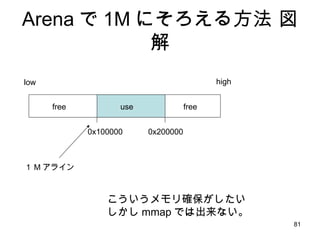
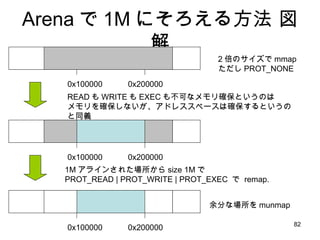
- 81. Arena żŪ 1M ż╦żĮżĒż©żļĘĮĘ© ćĒĮŌ 0x100000 0x200000 ż│ż”żżż”źßźŌźĻ┤_▒Żż¼żĘż┐żż żĘż½żĘ mmap żŪżŽ│÷└┤ż╩żżĪŻ low high use free free Ż▒ M źóźķźżź¾
- 82. Arena żŪ 1M ż╦żĮżĒż©żļĘĮĘ© ćĒĮŌ 0x100000 0x200000 2 ▒Čż╬źĄźżź║żŪ mmap ż┐ż└żĘ PROT_NONE 0x100000 0x200000 ėÓĘųż╩ł÷╦∙ż“ munmap READ żŌ WRITE żŌ EXEC żŌ▓╗┐╔ż╩źßźŌźĻ┤_▒Żż╚żżż”ż╬żŽ źßźŌźĻż“┤_▒ŻżĘż╩żżż¼Īóźóź╔źņź╣ź╣ź┌®`ź╣żŽ┤_▒Żż╣żļż╚żżż”ż╬ż╚═¼┴x 1M źóźķźżź¾żĄżņż┐ł÷╦∙ż½żķ size 1M żŪ PROT_READ | PROT_WRITE | PROT_EXEC żŪ remap. 0x100000 0x200000
- 83. ż▐ż╚żß ąĪżĄżż malloc żŽ╗ž╩²ż¼ż╣ż┤ż»ż┐ż»żĄż¾║¶żążņżļż╬żŪĪó O(n) żŪżŽź└źß źšźķź░źßź¾źŲ®`źĘźńź¾ż“Ę└ż░ż╦żŽ Huge ĪĪ Block żŽ Heap ż“Ęųż▒żļż╬ż¼ä┐╣¹Ą─ źŁźŃź├źĘźÕźęź├ź╚┬╩ż“╔Žż▓żļż╦żŽĪó▓╬ššŠų╦∙ąį │¼ ųžę¬ per Thread ż╩źŪ®`ź┐śŗįņżŽ per CPU ż╩źŪ®`ź┐śŗįņż╬żĶżżĮ³╦ŲéÄ
- 84. glibc malloc ż╬ź└źßż╩ż╚ż│żĒ Huge Block ż¼Į~īØ page align żĄżņżŲżĘż▐ż”ż╬żŪĪ󟣟џ├źĘźÕż¼Ėé║ŽżĘżõż╣żż Ż© HPC Ęųę░żŪżŽż│ż╬ÖC─▄żŽ OFF ż╦ż╣żļż╬ż¼ę╗░ŃĄ─Ż® żŌż”ę╗╣żĘ“ż╣żņżąĪó Arena żžż╬źĒź├ź»ūį╠Õż╩ż»ż╗żļŻ©ż│żņż¼å¢Ņ}ż╦ż╩żļżĶż”ż╩ heavy allocation źóźūźĻżŽūįŪ░ heap ╣▄└Ēż“żĘżŲżļż╬żŪä┐╣¹żŽęŖż©ż╦ż»żżż½żŌŻ® ūŅą┬ż╬ dlmalloc żŽ large-bin ż╬╣▄└Ēż¼źĻź╣ź╚ż½żķźąźżź╩źĻź─źĻ®`ż╦ēõĖ³żĄżņżŲĖ▀╦┘╗»ż¼ćĒżķżņżŲżżżļŻ©żŪżŌ╩╣ė├┬╩ż¼żżż▐żżż┴Ą═żżż╬żŪä┐╣¹żŽ╬ó├Ņż½Ż┐Ż®
- 85. ĮKż’żĻż╦ēõż©żŲ glibc malloc żŽĪóĮ±╚šż╬ź╣źķźżź╔ 90 ├Čż╦ż’ż┐żļ╔½Ī®ż╩źóźżźŪźóż¼ int_malloc() ż╚żżż”Ż▒ż─ż╬ķv╩²ż╦ż┤ż├ż┐ų¾żŪįæżß▐zż¾żŪżóżļż╬żŪĪóż╣ż┤ż»šiż▀ż╦ż»żż ż¬ż▐żżżķĪóźĮ®`ź╣ź│®`ź╔ż╬ź│źßź¾ź╚ż╦ż”żĮż“Ģ°ż»ż╩ż╚ąĪę╗Ģrķg?? ż¬ż▐żżżķĪóķv╩²ĘųĖŅż░żķżżżĘżĒż╚ąĪČ■Ģrķg??? ż¬ż▐żżżķĪóśŗįņ╠Õż╬ą═ż╚źßźŌźĻ╔Žż╬źŪ®`ź┐śŗįņżŽ║Žż’ż╗żŲż¬ż▒ż╚ąĪ╚²Ģrķg??? ż│żņż“ęŖżļż╚ Linux kernel ż├żŲż╩ż¾żŲšiż▀żõż╣żżż╬ż½ż╚????
- 86. ż┤ŪÕ┬ŚżóżĻż¼ż╚ż”ż┤żČżżż▐żĘż┐ŻĪ ż─ż½żņż┐Ī½ (©R”ž©Q) ®g