Google§őĽýĪP•Į•Ū©`•ů Hadoop§ň§ń§§§∆
?Download as PPT, PDF?
10 likes?2,805 views

@ Kernel Reading Party (20080704)











![MPI §őÜĖÓ}Ķ„ ÜĖÓ}Ķ„ ńÕ’Ōļ¶–‘§ō§őŅľĎ]§¨…Ŕ§ §§ •Ę•◊•Í•Ī©`•∑•Á•ů§¨∂ņ◊‘§ň•Ń•ß•√•Į•›•§•ů•»ôCń‹§ÚĆg◊į 1 ÕÚŐ®“‘…Ō§ő≠hĺ≥§«”čň„§Ļ§Ž§ň§ŌńÕ§®§ť§ž§ §§ 1 Ő®§¨ 1000 »’≥Ő∂»§«Č≤§ž§Ž§»§Ļ§Ž§»°Ę 1 »’§« 10 Ő®≥Ő∂»Č≤§ž§Ž Č≤§ž§Ž∂»§ň•Ń•ß•√•Į•›•§•ů•»§ę§ťĎݧĻ§»§ę§š§√§∆§ť§ů§ §§ RAID ĹM§ů§«§‚§Ĺ§ő§¶§ŃČ≤§ž§Ž§ő§«“Ľĺw Õ®–Ň•—•Ņ©`•ů§ §…§Ú”õ Ų§Ļ§Ž◊ųėI§¨∂ŗ§Į§ §Í°ĘĆgŽH§ő•Ę•Ž•ī•Í•ļ•ŗ§Ú”õ Ų§Ļ§Ž§ő§ň§Ņ§…§Í◊ҧĮ§ř§«ērťg§¨§ę§ę§Ž](https://image.slidesharecdn.com/20080704hadoop-090503155350-phpapp01/85/Google-Hadoop-15-320.jpg)
![§Ĺ§≥§« MapReduce īůŐŚ§ő īů“éń£•«©`•ŅĄIņŪ§Ú––§¶ÜĖÓ}§ňŐōĽĮ§∑§Ņ•◊•Ū•į•ť•Ŗ•ů•į•‚•«•Ž •Ę•Ž•ī•Í•ļ•ŗ§ő”õ Ų§ő§Ŗ§ň•◊•Ū•į•ť•ř§¨ľĮ÷–§«§≠§Ž §Ņ§ņ§∑ ņ§ő÷–§őÜĖÓ}»ę§∆§ňḈ∑§∆◊ÓŖm§ •‚•«•Ž§«§Ō§ §§ •ť•§•÷•ť•Íā»§«√śĶĻ§ ¬§Ú»ę§∆Ķ£ĶĪ ◊‘Ą”Ķń§ňĄIņŪ§Ú∑÷…Ę / ĀKŃ–ĽĮ •Ū©`•…•–•ť•ů•∑•ů•į •Õ•√•»•Ô©`•Į‹ěňÕ?•«•£•Ļ•Į Ļ”√ĄŅ¬ ĽĮ ńÕ’Ōļ¶–‘§őŅľĎ] 1 •ő©`•…§« ßĒ°§∑§Ņ§ťŖ`§¶ąŲňý§«§š§Í§ §™§Ľ§–§§§§§Ť§Õ MapReduce §¨Ŕt§Į§ §ž§–°Ę§Ĺ§ž§Ú Ļ§¶»ę§∆§ő•◊•Ū•į•ť•ŗ§¨Ŕt§Į§ §Ž£°](https://image.slidesharecdn.com/20080704hadoop-090503155350-phpapp01/85/Google-Hadoop-16-320.jpg)



![ņż : •Ô©`•…•ę•¶•ů•» ĒMň∆•≥©`•… map(string key, string value) { foreach word in value: emit(word, 1); } reduce(string key, vector<int> values) { int result = 0; for (int i = 0; I < values.size(); i++) result += values[i]; emit(key, result); }](https://image.slidesharecdn.com/20080704hadoop-090503155350-phpapp01/85/Google-Hadoop-31-320.jpg)


















![Ļ§§∑Ĺ Ćg––∑Ĺ∑® ./bin/hadoop jar contrib/hadoop-0.15.3-streaming.jar -input inputdir [HDFS §ő•—•Ļ ] -output outputdir [HDFS §ő•—•Ļ ] -mapper map [map •◊•Ū•į•ť•ŗ§ő•—•Ļ ] -reduce reduce [reduce •◊•Ū•į•ť•ŗ§ő•—•Ļ ] -inputformat [TextInputFormat | SequenceFileAsTextInputFormat] -outputformat [TextOutputFormat]](https://image.slidesharecdn.com/20080704hadoop-090503155350-phpapp01/85/Google-Hadoop-55-320.jpg)



![ņż : Ruby §ň§Ť§Ž•Ô©`•…•ę•¶•ů•» map.rb #!/usr/bin/env ruby while !STDIN.eof? line = STDIN.readline.strip ws = line.split ws.each { |w| puts "#{w}1°į } end reduce.rb #!/usr/bin/env ruby h = {} while !STDIN.eof? line = STDIN.readline.strip word = line.split("")[0] unless h.has_key? word h[word] = 1 else h[word] += 1 end end h.each { |w, c| puts "#{w}#{c}°į } $ ./bin/hadoop jar contrib/hadoop-0.15.3-streaming.jar -input wcinput -output wcoutput -mapper /home/hadoop/kzk/map.rb -reducer /home/hadoop/kzk/reduce.rb -inputformat TextInputFormat -outputformat TextOutputFormat](https://image.slidesharecdn.com/20080704hadoop-090503155350-phpapp01/85/Google-Hadoop-61-320.jpg)


Google§őĽýĪP•Į•Ū©`•ů Hadoop§ň§ń§§§∆
- 1. Google §őĽýĪP•Į•Ū©`•ů Hadoop §ň§ń§§§∆ ŐęŐÔ “Ľėš <kazuki.ohta@gmail.com>
- 2. ◊‘ľļĹBĹť ŐęŐÔ“Ľėš Ė|ĺ©īů—ß«ťąůņŪĻ§—ßŌĶ—–ĺŅŅ∆•≥•ů•‘•Ś©`•Ņ©`Ņ∆—ßĆüĻ• Įī®—–ĺŅ “ M1 HPC ŌĶ§ő‘í ( ĀKŃ–•’•°•§•Ž•∑•Ļ•∆•ŗ ) āÄ»ň•Ķ•§•» http://kzk9.net/ http://kzk9.net/blog/ Ňdő∂ OS, •Õ•√•»•Ô©`•Į , I/O, ∑÷…Ę•∑•Ļ•∆•ŗ OSS ĶńĽÓĄ” I was a committer of KDE, uim, SigScheme copybench? Kernel Reporter
- 3. §»§Ō£Ņ Google §őĽýĪP•Ĺ•’•»•¶•ß•Ę§ő•Į•Ū©`•ů Google File System, MapReduce Yahoo Research §ő Doug Cutting Ō§¨ť_įk ‘™°©§Ō Lucene §ő•Ķ•÷•◊•Ū•ł•ß•Į•» Doug §ő◊”Ļ©§ő≥÷§√§∆§§§Ž§Ő§§§į§Ž§Ŗ§ő√Ż«į Java §«”õ Ų !
- 4. Google ťvŖB ≤őŅľ’ďőń & •Ļ•ť•§•… The Google File System Sanjay Ghemawat, Howard Gobioff, and Shu-Tak Leong, SOSP 2003 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat, SOSP 2004 Parallel Architectures and Compilation Techniques (PACT) 2006, KeyNote http://www.cs.virginia.edu/~pact2006/program/mapreduce-pact06-keynote.pdf
- 5. Hadoop ≤őŅľőńŌ◊ Hadoop Ļę Ĺ•Ķ•§•» http://hadoop.apache.org/core/ Wiki: http://wiki.apache.org/hadoop/ •§•ů•Ļ•»©`•Ž∑Ĺ∑®?•Ń•Ś©`•»•Í•Ę•Ž?•◊•ž•ľ•ůŔYŃŌ§ §… Running Hadoop on Ubuntu Linux http://www.michael-noll.com/wiki/Running_Hadoop_On_Ubuntu_Linux_(Single-Node_Cluster) http://www.michael-noll.com/wiki/Running_Hadoop_On_Ubuntu_Linux_%28Multi-Node_Cluster%29 Hadoop, hBase §«ėčļB§Ļ§Žīů“éń£•«©`•ŅĄIņŪ•∑•Ļ•∆•ŗ on Codezine http://codezine.jp/a/article/aid/2448.aspx
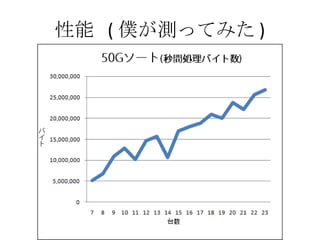
- 7. –‘ń‹ Apache Hadoop wins TeraSort Benchmark! http://developer.yahoo.com/blogs/hadoop/2008/07/apache_hadoop_wins_terabyte_sort_benchmark.html “é∂®•’•©©`•ř•√•»§ő 1T •«©`•Ņ§Ú•Ĺ©`•» 209 seconds (5G/sec, 5M/sec per node) 910 nodes, 4 dual core Xeon 2.0GHz, 1G Ether őÔŃŅ◊ųĎť
- 8. –‘ń‹ ( ÉW§¨úy§√§∆§Ŗ§Ņ )
- 9. ťvŖB•◊•Ū•ł•ß•Į•» hBase BigTable •Į•Ū©`•ů Pig •Į•®•Í—‘’Z§« MapReduce •◊•Ū•į•ť•ŗ§Ú”õ Ų clean = FILTER raw BY org.apache.pig.tutorial.NonURLDetector(query);
- 11. ÜĖÓ} •§•ů•Ņ©`•Õ•√•»§őĪ¨įkĶń∆’ľį§ň§Ť§Í°Ę∑«≥£§ňīů“éń£§ •«©`•Ņ§¨–Ó∑e§Ķ§ž§∆§§§Ž ņż§®§– Web •ŕ©`•ł§ő•Ķ•§•ļ§ÚŅľ§®§∆§Ŗ§Ž 200 É|•ŕ©`•ł * 20KB = 400 TB Disk ’i§Ŗřz§Ŗ–‘ń‹§Ō 50MB/sec (SATA) 1 Ő®§«§Ō’i§Ŗřz§ŗ§ņ§Ī§«§‚ľs 100 »’ Ī£īś§Ļ§Ž§ņ§Ī§«§‚ 500G §ő•«•£•Ļ•Į§¨ 1000 āÄ≥Ő∂»Īō“™ §≥§ő•«©`•Ņ§ÚĄŅ¬ Ķń§ňĄIņŪ§∑§Ņ§§
- 12. Ĺ‚õQ∑Ĺ∑® §™Ĺū §»§ň§ę§ĮīůŃŅ§ő•ř•∑•ů§Ú”√“‚ 1000 Ő®•ř•∑•ů§¨§Ę§ž§– 1 Ő®§« 400G ĄIņŪ§Ļ§ž§– ok ’i§Ŗřz§ŗ§ő§ň 8000 √Ž≥Ő∂»§«úg§ŗ
- 13. §™Ĺū§ņ§Ī§«§ŌĹ‚õQ§∑§ §§ •◊•Ū•į•ť•Ŗ•ů•į§¨∑«≥£§ňņߎy§ň§ §Ž •◊•Ū•Ľ•Ļ∆ūĄ” •◊•Ū•Ľ•ĻĪO“ē •◊•Ū•Ľ•ĻťgÕ®–Ň •«•–•√•į ◊ÓŖmĽĮ Ļ ’Ōēr§ō§őĆĚŹÍ §∑§ę§‚°Ę–¬§∑§§•◊•Ū•į•ť•ŗ§Ú◊ų§Ž∂»§ň§≥§ž§ť§őÜĖÓ}§Ú§§§Ń§§§ŃĆg◊į§Ļ§ŽĪō“™§¨§Ę§Ž §¶§Ō©` §Š§ů§…§Į§Ľ©`£°
- 14. ľ»īś§ő∑÷…Ę / ĀKŃ–•◊•Ū•į•ť•Ŗ•ů•į≠hĺ≥ MPI (Message Passing Interface) ĀKŃ–•◊•Ū•į•ť•Ŗ•ů•į§ő§Ņ§Š§ő•ť•§•÷•ť•Í •Ļ•—•≥•ů§ő ņĹÁ§«§Ō÷ųŃų •◊•Ū•į•ť•ř§Ōłų•◊•Ū•Ľ•Ļ§őí§Ą”§Ú”õ Ų Õ®–Ň•◊•Í•Ŗ•∆•£•÷ (Send, Recv, All-to-All) §¨ŐŠĻ©§Ķ§ž§∆§™§Í°Ę§Ĺ§ž§Ú”√§§§∆•«©`•ŅÕ®–ҧÚĆg¨F ņŻĶ„ Õ®–Ň•—•Ņ©`•ů§ §…§Ú•◊•Ū•į•ť•ř§¨•≥•ů•»•Ū©`•Ž§«§≠°ĘÜĖÓ}§ňḈ∑§∆◊ÓŖm§ •◊•Ū•į•ť•ŗ§Ú”õ Ų§Ļ§Ž ¬§¨§«§≠§Ž
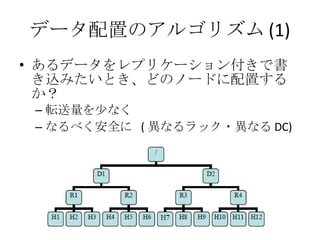
- 15. MPI §őÜĖÓ}Ķ„ ÜĖÓ}Ķ„ ńÕ’Ōļ¶–‘§ō§őŅľĎ]§¨…Ŕ§ §§ •Ę•◊•Í•Ī©`•∑•Á•ů§¨∂ņ◊‘§ň•Ń•ß•√•Į•›•§•ů•»ôCń‹§ÚĆg◊į 1 ÕÚŐ®“‘…Ō§ő≠hĺ≥§«”čň„§Ļ§Ž§ň§ŌńÕ§®§ť§ž§ §§ 1 Ő®§¨ 1000 »’≥Ő∂»§«Č≤§ž§Ž§»§Ļ§Ž§»°Ę 1 »’§« 10 Ő®≥Ő∂»Č≤§ž§Ž Č≤§ž§Ž∂»§ň•Ń•ß•√•Į•›•§•ů•»§ę§ťĎݧĻ§»§ę§š§√§∆§ť§ů§ §§ RAID ĹM§ů§«§‚§Ĺ§ő§¶§ŃČ≤§ž§Ž§ő§«“Ľĺw Õ®–Ň•—•Ņ©`•ů§ §…§Ú”õ Ų§Ļ§Ž◊ųėI§¨∂ŗ§Į§ §Í°ĘĆgŽH§ő•Ę•Ž•ī•Í•ļ•ŗ§Ú”õ Ų§Ļ§Ž§ő§ň§Ņ§…§Í◊ҧĮ§ř§«ērťg§¨§ę§ę§Ž
- 16. §Ĺ§≥§« MapReduce īůŐŚ§ő īů“éń£•«©`•ŅĄIņŪ§Ú––§¶ÜĖÓ}§ňŐōĽĮ§∑§Ņ•◊•Ū•į•ť•Ŗ•ů•į•‚•«•Ž •Ę•Ž•ī•Í•ļ•ŗ§ő”õ Ų§ő§Ŗ§ň•◊•Ū•į•ť•ř§¨ľĮ÷–§«§≠§Ž §Ņ§ņ§∑ ņ§ő÷–§őÜĖÓ}»ę§∆§ňḈ∑§∆◊ÓŖm§ •‚•«•Ž§«§Ō§ §§ •ť•§•÷•ť•Íā»§«√śĶĻ§ ¬§Ú»ę§∆Ķ£ĶĪ ◊‘Ą”Ķń§ňĄIņŪ§Ú∑÷…Ę / ĀKŃ–ĽĮ •Ū©`•…•–•ť•ů•∑•ů•į •Õ•√•»•Ô©`•Į‹ěňÕ?•«•£•Ļ•Į Ļ”√ĄŅ¬ ĽĮ ńÕ’Ōļ¶–‘§őŅľĎ] 1 •ő©`•…§« ßĒ°§∑§Ņ§ťŖ`§¶ąŲňý§«§š§Í§ §™§Ľ§–§§§§§Ť§Õ MapReduce §¨Ŕt§Į§ §ž§–°Ę§Ĺ§ž§Ú Ļ§¶»ę§∆§ő•◊•Ū•į•ť•ŗ§¨Ŕt§Į§ §Ž£°
- 17. MapReduce –Õ§őĄIņŪ WordCount Grep Sort ( Ŗm«–§ Partition ťv ż§ÚŖxík§Ļ§ŽĪō“™ ) Log Analysis Web Graph Generation Inverted Index Construction Machine Learning NaiveBayes, K-means, Expectation Maximization, etc.
- 18. Google §«§ő Ļ”√¬
- 19. MapReduce Model
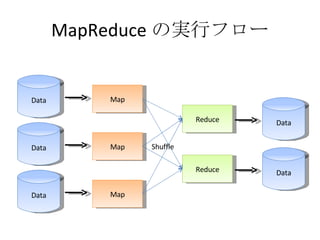
- 20. MapReduce §őĆg––•’•Ū©` Data Map Data Map Data Map Reduce Reduce Data Data Shuffle
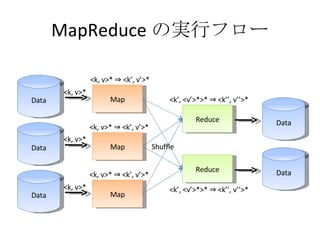
- 21. MapReduce §őĆg––•’•Ū©` »ŽŃ¶’i§Ŗřz§Ŗ <key, value>* Map map: <key, value> ? <key°Į, value°Į>* Shuffle shuffle: <key°Į, reducers> ? destination reducer Reduce reduce: <key°Į, <value°Į> * > ? <key°Į°Į, value°Į°Į>* ≥ŲѶēݧ≠≥Ų§∑ <key°Į°Į, value°Į°Į>*
- 22. MapReduce §őĆg––•’•Ū©` Data Map Data Map Data Map Reduce Reduce Data Data Shuffle <k, v>* <k, v>* <k, v>* <k, v>* ? <k°Į, v°Į>* <k°Į, <v°Į>*>* ? <k°Į°Į, v°Į°Į>* <k, v>* ? <k°Į, v°Į>* <k, v>* ? <k°Į, v°Į>* <k°Į, <v°Į>*>* ? <k°Į°Į, v°Į°Į>*
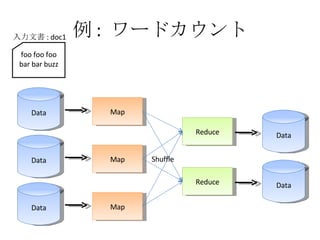
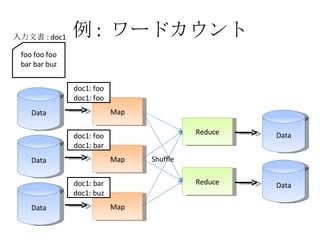
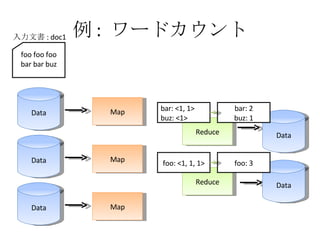
- 23. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data Shuffle foo foo foo bar bar buzz »ŽŃ¶őńēÝ : doc1
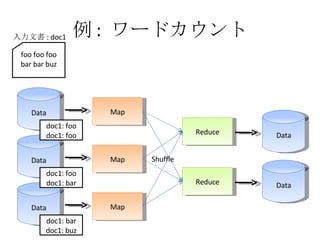
- 24. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data Shuffle foo foo foo bar bar buz »ŽŃ¶őńēÝ : doc1 doc1: foo doc1: foo doc1: foo doc1: bar doc1: bar doc1: buz
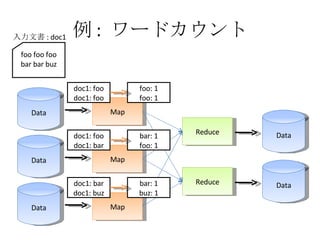
- 25. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data Shuffle foo foo foo bar bar buz »ŽŃ¶őńēÝ : doc1 doc1: foo doc1: bar doc1: bar doc1: buz doc1: foo doc1: foo
- 26. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data foo foo foo bar bar buz »ŽŃ¶őńēÝ : doc1 doc1: foo doc1: bar doc1: bar doc1: buz doc1: foo doc1: foo foo: 1 foo: 1 bar: 1 foo: 1 bar: 1 buz: 1
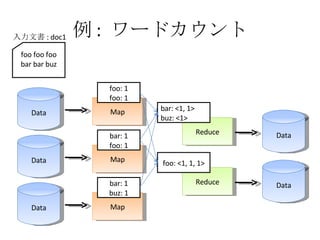
- 27. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data foo foo foo bar bar buz »ŽŃ¶őńēÝ : doc1 foo: 1 foo: 1 bar: 1 foo: 1 bar: 1 buz: 1 bar: <1, 1> buz: <1> foo: <1, 1, 1>
- 28. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data foo foo foo bar bar buz »ŽŃ¶őńēÝ : doc1 bar: <1, 1> buz: <1> foo: <1, 1, 1>
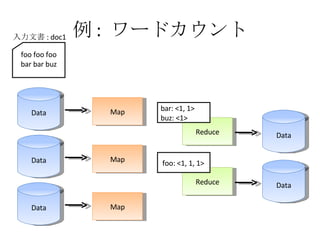
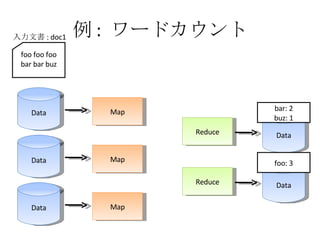
- 29. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data foo foo foo bar bar buz »ŽŃ¶őńēÝ : doc1 foo: <1, 1, 1> bar: <1, 1> buz: <1> foo: 3 bar: 2 buz: 1
- 30. ņż : •Ô©`•…•ę•¶•ů•» Data Map Data Map Data Map Reduce Reduce Data Data foo foo foo bar bar buz »ŽŃ¶őńēÝ : doc1 bar: 2 buz: 1 foo: 3
- 31. ņż : •Ô©`•…•ę•¶•ů•» ĒMň∆•≥©`•… map(string key, string value) { foreach word in value: emit(word, 1); } reduce(string key, vector<int> values) { int result = 0; for (int i = 0; I < values.size(); i++) result += values[i]; emit(key, result); }
- 32. MapReduce §őŐōŹ’ •«©`•ŅÕ®–Ň łų Map ĄIņŪ°Ę Reduce ĄIņŪ§ŌÕÍ»ę§ňĀKŃ–§ňĆg––Ņ…ń‹ •ř•∑•ů§ÚČą§š§Ľ§–§Ĺ§ő∑÷ĄIņŪń‹Ń¶§¨Čą§®§Ž ńÕĻ ’Ō–‘ ßĒ°§∑§Ņ Map, Reduce ĄIņŪ§ŌňŻ§ő•ő©`•…§«‘ŔĆg––§Ķ§ž§Ž ŖW§§ Map, Reduce ĄIņŪ§ň§ń§§§∆§‚Õ¨§ł •Ū©`•ę•Í•∆•£ •«©`•Ņ§ő§Ę§ŽąŲňý§«”čň„§Ú ľ§Š§ž§–°Ę•Õ•√•»•Ô©`•Į§Ú Ļ§¶Īō“™§¨§ §Į§ §Ž Moving Computation is Cheaper Than Moving Data
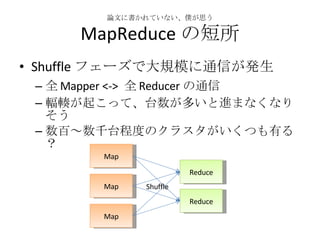
- 33. ’ďőń§ňēݧ꧞§∆§§§ §§°ĘÉW§¨ňľ§¶ MapReduce §ő∂Őňý Shuffle •’•ß©`•ļ§«īů“éń£§ňÕ®–ҧ¨įk…ķ »ę Mapper <-> »ę Reducer §őÕ®–Ň ›ó›Ź§¨∆ū§≥§√§∆°ĘŐ® ż§¨∂ŗ§§§»ŖM§ř§ §Į§ §Í§Ĺ§¶ żįŔ°ę ż«ßŐ®≥Ő∂»§ő•Į•ť•Ļ•Ņ§¨§§§Į§ń§‚”–§Ž£Ņ Map Map Map Reduce Reduce Shuffle
- 35. Hadoop §ő÷–…Ū Hadoop Distributed File System (HDFS) GFS §ő•Į•Ū©`•ů MapReduce •◊•Ū•į•ť•ŗ§ő»ŽŃ¶§š≥ŲѶ§ň Ļ”√ Hadoop MapReduce MapReduce Ćg¨F§Ļ§Ž§Ņ§Š§ő•Ķ©`•–©` , •ť•§•÷•ť•Í
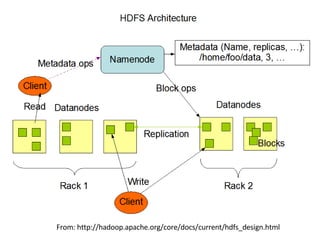
- 36. Hadoop Distributed File System Master/Slave •Ę©`•≠•∆•Į•Ń•„ •’•°•§•Ž§Ō•÷•Ū•√•Į§»§§§¶ÖgőĽ§ň∑÷łÓ§∑§∆Ī£īś NameNode Master •’•°•§•Ž§ő•Š•Ņ•«©`•Ņ ( •—•Ļ?ėōŌř§ §… ) §ÚĻ‹ņŪ DataNode Slave ĆgŽH§ő•«©`•Ņ ( •÷•Ū•√•Į§ÚĻ‹ņŪ )
- 38. •«©`•ŅŇš÷√§ő•Ę•Ž•ī•Í•ļ•ŗ (1) §Ę§Ž•«©`•Ņ§Ú•ž•◊•Í•Ī©`•∑•Á•ůł∂§≠§«ēݧ≠řz§Ŗ§Ņ§§§»§≠°Ę§…§ő•ő©`•…§ňŇš÷√§Ļ§Ž§ę£Ņ ‹ěňÕŃŅ§Ú…Ŕ§ §Į § §Ž§Ŕ§Įį≤»ę§ň ( ģź§ §Ž•ť•√•Į?ģź§ §Ž DC)
- 39. •ž•◊•Í•Ī©`•∑•Á•ů§ő•Ę•Ž•ī•Í•ļ•ŗ (2) Hadoop §ŌĹYėčŖmĶĪ§ň§š§√§∆§§§Ž 1 §ńńŅ§ŌĪō§ļ•Ū©`•ę•Ž§ňēݧĮ 2 §ńńŅ§Ōģź§ §Ž•ť•√•Į§ňēݧĮ 3 §ńńŅ§ŌÕ¨§ł•ť•√•Į§őŖ`§¶•ő©`•…§ňēݧĮ 4 §ńńŅ“∆––§Ō•ť•ů•ņ•ŗ “‚Õ‚§»§≥§¶§§§¶ŖmĶĪ§ §ő§¨ …Ō ÷§Į––§Į§ő §ę§‚§∑§ž§ §§
- 40. GFS §ň”–§√§∆ HDFS §ňüo§§§‚§ő Atomic § Append HADOOP-1700 http://issues.apache.org/jira/browse/HADOOP-1700 •Ū•√•Į GFS §«§Ō Chubby §»ļۧ–§ž§Ž∑÷…Ę•Ū•√•Į•Ķ©`•”•Ļ§Ú Ļ”√§∑§∆§§§Ž Hadoop §ň§Ō Chubby ŌŗĶĪ§ő§‚§ő§¨§ §§§ő§«°Ę•’•°•§•Ž§ő…Ōēݧ≠§Ō≥Ųņī§ļ°Ę–¬“é◊ų≥…§∑§ę≥Ųņī§ §§
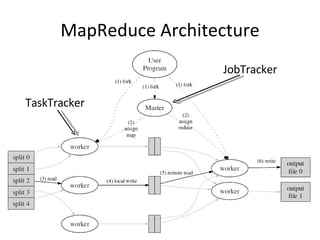
- 41. Hadoop MapReduce Master/Slave •Ę©`•≠•∆•Į•Ń•„ JobTracker Master Job §Ú Task §ň∑÷łÓ§∑°Ę Task §Úłų TaskTracker §ň∑÷Ňš Job: MapReduce •◊•Ū•į•ť•ŗ§őĆg––ÖgőĽ Task: MapTask, ReduceTask »ę§∆§ő Task §őŖM––◊īõr§ÚĪO“ē§∑°Ęňņ§ů§ņ§ÍŖW§ž§Ņ§Í§∑§Ņ Task §ŌĄe§ő TaskTracker §«Ćg––§Ķ§Ľ§Ž TaskTracker Slave JobTracker §ň•Ę•Ķ•§•ů§Ķ§ž§Ņ Task §ÚĆg–– ĆgŽH§ő”čň„ĄIņŪ§Ú––§¶
- 42. MapReduce Architecture JobTracker TaskTracker
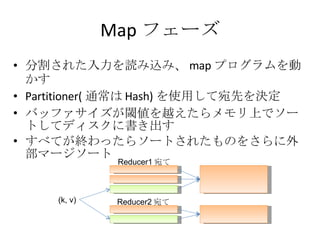
- 43. Map •’•ß©`•ļ ∑÷łÓ§Ķ§ž§Ņ»ŽŃ¶§Ú’i§Ŗřz§Ŗ°Ę map •◊•Ū•į•ť•ŗ§ÚĄ”§ę§Ļ Partitioner( Õ®≥£§Ō Hash) §Ú Ļ”√§∑§∆ÕūŌ»§ÚõQ∂® •–•√•’•°•Ķ•§•ļ§¨ťďāé§Ú‘ŧ®§Ņ§ť•Š•‚•Í…Ō§«•Ĺ©`•»§∑§∆•«•£•Ļ•Į§ňēݧ≠≥Ų§Ļ §Ļ§Ŕ§∆§¨ĹK§Ô§√§Ņ§ť•Ĺ©`•»§Ķ§ž§Ņ§‚§ő§Ú§Ķ§ť§ňÕ‚≤Ņ•ř©`•ł•Ĺ©`•» (k, v) Reducer1 Õū§∆ Reducer2 Õū§∆
- 44. Reduce •’•ß©`•ļ Map •’•ß©`•ļ§ő≥ŲѶ§Ú•’•ß•√•Ń •Š•‚•Í…Ō§«•≠©`öį§ň§ř§»§Š§Ę§≤§Ž Reduce •◊•Ū•į•ť•ŗ§ÚĄ”§ę§Ļ ≥ŲѶ§Ú HDFS §ňēݧ≠≥Ų§∑ Amazon S3 § §…§ň§‚ēݧ≠≥Ų§Ľ§Ž
- 46. HDFS §ő≤Ŕ◊ų∑Ĺ∑® # ls alias dfsls='~/hadoop/bin/hadoop dfs -ls°ģ # ls -r alias dfslsr='~/hadoop/bin/hadoop dfs -lsr°ģ # rm alias dfsrm='~/hadoop/bin/hadoop dfs -rm°ģ # rm -r alias dfsrmr='~/hadoop/bin/hadoop dfs -rmr' # cat alias dfscat='~/hadoop/bin/hadoop dfs -cat°ģ # mkdir alias dfsmkdir='~/hadoop/bin/hadoop dfs -mkdir°ģ
- 47. HDFS §ő≤Ŕ◊ų∑Ĺ∑® hadoop@pficore:~$ dfsls Found 5 items /user/hadoop/access-log <r 3> 3003 2008-04-30 00:21 /user/hadoop/hoge <r 3> 2183 2008-04-30 00:32 /user/hadoop/reported <dir> 2008-04-30 00:28 /user/hadoop/wcinput <r 3> 29 2008-05-08 10:17 /user/hadoop/wcoutput <dir> 2008-05-08 11:48
- 48. HDFS §ő≤Ŕ◊ų∑Ĺ∑® HDFS …Ō§ň•’•°•§•Ž§Ú‹ěňÕ HDFS …Ō§ę§ť•’•°•§•Ž§Ú‹ěňÕ alias dfsput='~/hadoop/bin/hadoop dfs -put°ģ dfsput <local-path> <hdfs-path> alias dfsget='~/hadoop/bin/hadoop dfs -get°ģ dfsget <hdfs-path> <local-path>
- 49. HDFS §ő Ļ”√∑Ĺ∑® hadoop@pficore:~$ dfsls Found 0 items hadoop@pficore:~$ dfsput hoge.txt hoge.txt hadoop@pficore:~$ dfsls Found 1 items /user/hadoop/hoge.txt <r 3> 31 2008-05-08 12:00
- 50. HDFS §őŐōŹ’ Master/Slave •Ę©`•≠•∆•Į•Ń•„§ §ő§«°Ę Master §ňł∂ľ”§¨łŖ§ř§Ž§»»ęŐŚ§ő•Ļ•Ž©`•◊•√•»§¨¬š§Ń§Ž •Š•Ņ•«©`•Ņ≤Ŕ◊ų§Ú…Ŕ§ §Į§Ļ§Ž§ő§¨•›•§•ů•» ≥Ųņī§Ž§ņ§Ī°Ī…Ŕ§ §§ ż°Ī§ő°Īĺřīů§ •’•°•§•Ž°Ī§ÚłŮľ{§Ļ§Ž§Ť§¶§ň§Ļ§Ž ł–“ôĶń§ň§Ō żįŔ M °ę ż G ≥Ő∂»§ő•’•°•§•Ž§Ú◊ų§Ž§ő§¨Ńľ§Ķ§Ĺ§¶
- 51. Hadoop Programming on Hadoop with °įJava°Ī
- 52. Skipped for Kernel Hackers ? who never want to write Java :-P
- 53. Hadoop Programming on Hadoop with °į Hadoop Streaming °Ī (sh, C, C++, Ruby, Python, etc.)
- 54. HadoopStreaming ėňú »Ž≥ŲѶ§ÚĹť§∑§∆ MapReduce ĄIņŪ§ÚēݧĪ§Ž§Ť§¶§ň§Ļ§Ž§Ņ§Š§ő ňĹM§Ŗ sh ? C++ ? Ruby ? Python § §…°Ę»ő“‚§ő—‘’Z§« MapReduce §¨Ņ…ń‹§ň§ §Ž http://hadoop.apache.org/core/docs/r0.15.3/streaming.html Hadoop Streaming §ŌÖgľÉ§ wrapper •ť•§•÷•ť•Í ÷ł∂®§∑§Ņ•◊•Ū•į•ť•ŗ§őėňú »ŽŃ¶§ň <key, value> §Ú∂…§Ļ ėňú ≥ŲѶ§ę§ťĹYĻŻ§Ú’i§Ŗřz§Ŗ°Ę§Ĺ§ž§Ú≥ŲѶ Amazon, Facebook Ķ»§«§‚ Streaming ĹU”…§« Hadoop §¨ Ļ§Ô§ž§∆§§§Ž§ť§∑§§ http://wiki.apache.org/hadoop/PoweredBy
- 55. Ļ§§∑Ĺ Ćg––∑Ĺ∑® ./bin/hadoop jar contrib/hadoop-0.15.3-streaming.jar -input inputdir [HDFS §ő•—•Ļ ] -output outputdir [HDFS §ő•—•Ļ ] -mapper map [map •◊•Ū•į•ť•ŗ§ő•—•Ļ ] -reduce reduce [reduce •◊•Ū•į•ť•ŗ§ő•—•Ļ ] -inputformat [TextInputFormat | SequenceFileAsTextInputFormat] -outputformat [TextOutputFormat]
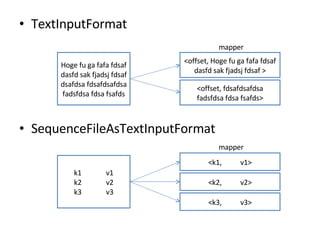
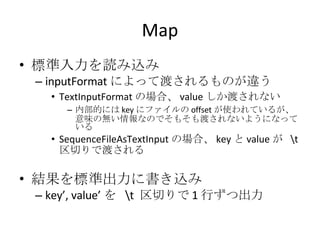
- 56. InputFormat -inputformat •™•◊•∑•Á•ů »ŽŃ¶•’•°•§•Ž§ő•’•©©`•ř•√•»§Ú÷ł∂® TextInputFormat (default) •’•°•§•Ž§ő»ő“‚§őőĽ÷√§«ŖmĶĪ§ň∑÷łÓ§Ķ§ž§Ž <k, v> = < •’•°•§•Ž§ő•™•’•Ľ•√•» , •’•°•§•Ž§ő÷–…Ū > SequenceFileAsTextInputFormat 1 –– 1map ĄIņŪ °į keyvalue°Ī §»§§§¶Ń–§¨ĀK§ů§«§§§Ž•’•°•§•ŽŅ§§Ú”√“‚ <k, v> = <key, value> (1 ––öį )
- 57. TextInputFormat SequenceFileAsTextInputFormat Hoge fu ga fafa fdsaf dasfd sak fjadsj fdsaf dsafdsa fdsafdsafdsa fadsfdsa fdsa fsafds <offset, Hoge fu ga fafa fdsaf dasfd sak fjadsj fdsaf > <offset, fdsafdsafdsa fadsfdsa fdsa fsafds> k1 v1 k2 v2 k3 v3 <k1, v1> <k2, v2> <k3, v3> mapper mapper
- 58. OutputFormat -outputformat •™•◊•∑•Á•ů ≥ŲѶ•’•°•§•Ž§ő•’•©©`•ř•√•»§Ú÷ł∂® TextOutputFormat (default) °į keyvalue°Ī §¨ 1 ––§ļ§ńēݧ≠≥Ų§Ķ§ž§Ž
- 59. Map ėňú »ŽŃ¶§Ú’i§Ŗřz§Ŗ inputFormat §ň§Ť§√§∆∂…§Ķ§ž§Ž§‚§ő§¨Ŗ`§¶ TextInputFormat §őąŲļŌ°Ę value §∑§ę∂…§Ķ§ž§ §§ ńŕ≤ŅĶń§ň§Ō key §ň•’•°•§•Ž§ő offset §¨ Ļ§Ô§ž§∆§§§Ž§¨°Ę“‚ő∂§őüo§§«ťąů§ §ő§«§Ĺ§‚§Ĺ§‚∂…§Ķ§ž§ §§§Ť§¶§ň§ §√§∆§§§Ž SequenceFileAsTextInput §őąŲļŌ°Ę key §» value §¨ «Ý«–§Í§«∂…§Ķ§ž§Ž ĹYĻŻ§Úėňú ≥ŲѶ§ňēݧ≠řz§Ŗ key°Į, value°Į §Ú «Ý«–§Í§« 1 ––§ļ§ń≥ŲѶ
- 60. Reduce ėňú »ŽŃ¶§Ú’i§Ŗřz§Ŗ keyval §ő§Ť§¶§ň 1 ––§« key §» val §¨∂…§Ķ§ž§Ž Õ¨§ł key §ň§ń§§§∆§Ō£Ī§ń§ő reducer ń৫ĄIņŪ§Ķ§ž§Ž ¬§¨Ī£‘^§Ķ§ž§∆§§§Ž ėňú ≥ŲѶ§ňēݧ≠≥Ų§∑ key, value §Ú őń◊÷«Ý«–§Í§« 1 ––§ļ§ńēݧ≠≥Ų§∑
- 61. ņż : Ruby §ň§Ť§Ž•Ô©`•…•ę•¶•ů•» map.rb #!/usr/bin/env ruby while !STDIN.eof? line = STDIN.readline.strip ws = line.split ws.each { |w| puts "#{w}1°į } end reduce.rb #!/usr/bin/env ruby h = {} while !STDIN.eof? line = STDIN.readline.strip word = line.split("")[0] unless h.has_key? word h[word] = 1 else h[word] += 1 end end h.each { |w, c| puts "#{w}#{c}°į } $ ./bin/hadoop jar contrib/hadoop-0.15.3-streaming.jar -input wcinput -output wcoutput -mapper /home/hadoop/kzk/map.rb -reducer /home/hadoop/kzk/reduce.rb -inputformat TextInputFormat -outputformat TextOutputFormat
- 62. ņż : ≥ŲѶ§ÚąRŅs§Ļ§Ž -jobconf mapred.output.compress=true Key, Value §Ĺ§ž§ĺ§ž§ňḈ∑§∆ gzip ąRŅs§¨§ę§ę§Ž ’i§Ŗřz§ŗ읧ň§ŌŐōĄe§ •™•◊•∑•Á•ů§ŌĪō“™§ §∑ $ ./bin/hadoop jar contrib/hadoop-0.15.3-streaming.jar -input wcinput -output wcoutput -mapper /home/hadoop/kzk/map.rb -reducer /home/hadoop/kzk/reduce.rb -inputformat TextInputFormat -outputformat TextOutputFormat -jobconf mapred.output.compress=true
- 63. §Ņ§Š§∑§ňēݧ§§∆§Ŗ§Ņ§‚§ő •Ô©`•…•ę•¶•ů•» Wikipedia »ęŐŚ ÷–ťg•’•°•§•ŽąRŅs ≥ŲѶ•’•°•§•ŽąRŅs ó ňų•§•ů•«•√•Į•Ļ◊ų≥… 20G Lucene §Ú Ļ”√ »ę≤Ņ I/O •Õ•√•Į ż ģŐ®≥Ő∂»§ő≠hĺ≥§«Őō§ňÜĖÓ}§ §ĮĄ”§§§Ņ
- 64. Enjoy Playing Around Hadoop ? Thank you! kzk