








![Bloom filter - Search [No false negative]
0 1 1 0 0 1 0 0 1 0 0 1 1 0
h1
h...
hk
ŌĆ£aŌĆØ DOES NOT belong to the
set
a
n
b
...](https://image.slidesharecdn.com/hash-aprobabilisticapproachforbigdata-151214145751/85/Hash-A-probabilistic-approach-for-big-data-20-320.jpg)
![Bloom filter - Search [True positive]
0 1 1 0 0 1 0 0 1 0 0 1 1 0
h1
h...
hk
ŌĆ£nŌĆØ MAY belong to the set
n
b
...](https://image.slidesharecdn.com/hash-aprobabilisticapproachforbigdata-151214145751/85/Hash-A-probabilistic-approach-for-big-data-21-320.jpg)
![Bloom filter - Search [Possible false positive]
0 1 1 0 0 1 0 0 1 0 0 1 1 0
h1
h...
hk
b
...
ŌĆ£bŌĆØ MAY belong to the set](https://image.slidesharecdn.com/hash-aprobabilisticapproachforbigdata-151214145751/85/Hash-A-probabilistic-approach-for-big-data-22-320.jpg)

![Bloom filter - Results [MyMemory]
~5% of connections
60+ GB
Hash index (1,5B items)
ŌĆ”
2 GB
bloom filter](https://image.slidesharecdn.com/hash-aprobabilisticapproachforbigdata-151214145751/85/Hash-A-probabilistic-approach-for-big-data-26-320.jpg)













![MinHash - Signature creation
Doc1
ŌĆ”10101
ŌĆ”01100
ŌĆ”10010
ŌĆ”00111
Take a random permutation
of the fingerprints.
Generate the fingerprints
of the documents.
Define minhash(Hn
, Doci
) = First fingerprint of Doci
hashed with
Hn
Sig(Doci
) of length K = [minhashi
, minhash2
, ŌĆ”, minhashn
]
Doc1
ŌĆ”00111
ŌĆ”01100
ŌĆ”10101
ŌĆ”10010
Minhash of this
permutation
Hn](https://image.slidesharecdn.com/hash-aprobabilisticapproachforbigdata-151214145751/85/Hash-A-probabilistic-approach-for-big-data-45-320.jpg)
![MinHash - Implementation
1. Generate the fingerprints of the document
2. Define K hash functions: h1
, h2
, ....
, hk
.
3. Define Sig(Doc) = [h1
(Doc), h2
(Doc), ..., hk
(Doc)]
4. Define O = { i / hi
(Doc1
) = hi
(Doc2
) }
5. Sim(Doc1
, Doc2
) = Ōēā Jaccard(Doc1
, Doc2
)
| O |
K
Storage Ōēģ 4 byte * K * #Docs
Complexity Ōēģ K * #Docs
With K << Doc_length](https://image.slidesharecdn.com/hash-aprobabilisticapproachforbigdata-151214145751/85/Hash-A-probabilistic-approach-for-big-data-48-320.jpg)



![P(|questions| > 0) = 1 - [1 - p(question)]|audience|
Any questions?](https://image.slidesharecdn.com/hash-aprobabilisticapproachforbigdata-151214145751/85/Hash-A-probabilistic-approach-for-big-data-55-320.jpg)
Hash - A probabilistic approach for big data
- 1. Hash A probabilistic approach for big data Luca Mastrostefano
- 2. Who am I? ŌŚÅ Product manager of MyMemory at Translated ŌŚÅ IT background ŌŚÅ Algorithms lover Luca Mastrostefano luca@translated.net
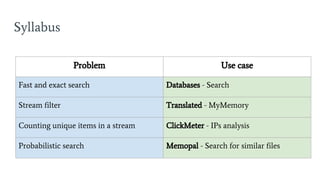
- 3. Syllabus Problem Use case Fast and exact search Databases - Search Stream filter Translated - MyMemory Counting unique items in a stream ClickMeter - IPs analysis Probabilistic search Memopal - Search for similar files
- 4. Search algorithms Databases - Fast and exact search Static, extendible and linear hash indexes
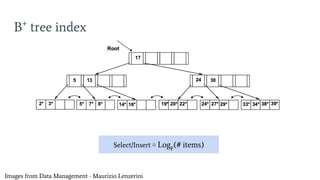
- 5. Use case Sometimes also a logarithmic complexity is too expensive.
- 6. B+ tree index Images from Data Management - Maurizio Lenzerini Select/Insert Ōēģ LogF (# items)
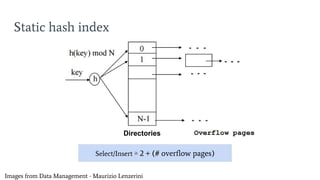
- 7. Search - Hash index
- 8. Static hash index Images from Data Management - Maurizio Lenzerini Select/Insert Ōēģ 2 + (# overflow pages) Directories
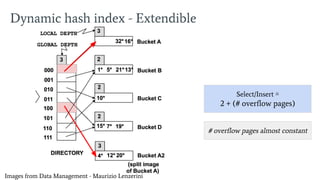
- 9. Images from Data Management - Maurizio Lenzerini Dynamic hash index - Extendible Select/Insert Ōēģ 2 + (# overflow pages) # overflow pages almost constant
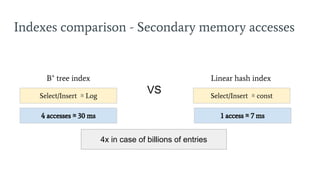
- 10. Intuition: ŌŚÅ Avoid the directories to save one memory access. ŌŚÅ Split one bucket per time: it fits real-time environments! Dynamic hash index - Linear Select/Insert Ōēģ 1 + (# overflow pages) # overflow pages almost constant
- 11. 4x in case of billions of entries Select/Insert ŌēŖ Log VS B+ tree index Indexes comparison - Secondary memory accesses Linear hash index Select/Insert ŌēŖ const 1 access ŌēŖ 7 ms4 accesses ŌēŖ 30 ms
- 12. Stream filter: x Ōłł U ? Translated - MyMemory Bloom filter
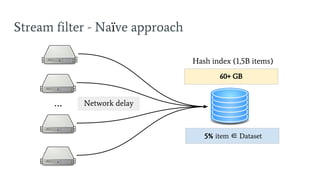
- 13. Use case The delay introduced by the secondary memory does not fit an environment in which milliseconds matter.
- 14. Stream filter - Na├»ve approach 60+ GB Hash index (1,5B items) Network delay 5% item Ōłł Dataset ŌĆ”
- 15. Stream filter - Bloom filter
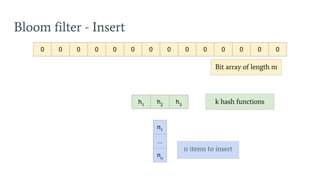
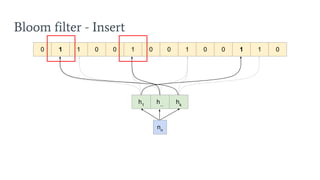
- 16. Bloom filter - Insert 0 0 0 0 0 0 0 0 0 0 0 0 0 0 n1 ... nn n items to insert h1 h2 h3 k hash functions Bit array of length m
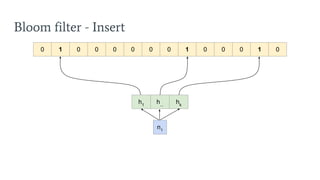
- 17. Bloom filter - Insert 0 1 0 0 0 0 0 0 1 0 0 0 1 0 h1 h... hk n1
- 18. Bloom filter - Insert 0 1 1 0 0 1 0 0 1 0 0 1 1 0 h1 h... hk nn
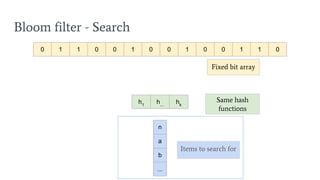
- 19. Bloom filter - Search 0 1 1 0 0 1 0 0 1 0 0 1 1 0 n a b ... h1 h... hk Items to search for Same hash functions Fixed bit array
- 20. Bloom filter - Search [No false negative] 0 1 1 0 0 1 0 0 1 0 0 1 1 0 h1 h... hk ŌĆ£aŌĆØ DOES NOT belong to the set a n b ...
- 21. Bloom filter - Search [True positive] 0 1 1 0 0 1 0 0 1 0 0 1 1 0 h1 h... hk ŌĆ£nŌĆØ MAY belong to the set n b ...
- 22. Bloom filter - Search [Possible false positive] 0 1 1 0 0 1 0 0 1 0 0 1 1 0 h1 h... hk b ... ŌĆ£bŌĆØ MAY belong to the set
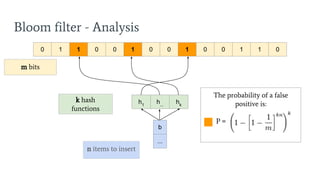
- 23. Bloom filter - Analysis n items to insert k hash functions m bits 0 1 1 0 0 1 0 0 1 0 0 1 1 0 z ... h1 h2 h3 b ... h1 h... hk The probability of a false positive is: P =
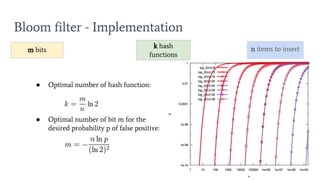
- 24. Bloom filter - Implementation n items to insertk hash functions m bits ŌŚÅ Optimal number of hash function: ŌŚÅ Optimal number of bit m for the desired probability p of false positive:
- 25. Bloom filter - Results 7 hash functions 2 GB (14B bit) 60+ GB VS Naïve approach Bloom filter 1% of false positive
- 26. Bloom filter - Results [MyMemory] ~5% of connections 60+ GB Hash index (1,5B items) ŌĆ” 2 GB bloom filter
- 27. Counting unique items in a stream ClickMeter - Number of unique IPs per link Flajolet - Martin for unique hash counting
- 28. Use case Counting unique elements could be really costly in terms of memory.
- 29. Counting unique items - Naïve approach 500 MB per link (4B bits array) ... 1 1 0 0 1 0 0 1 0 0 1 1 ... 5 PB with 10M links 0.0.0.0 255.255.255.255
- 30. Counting unique items - Flajolet-Martin
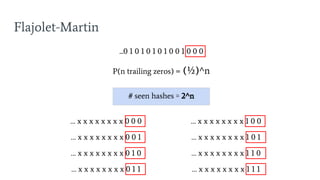
- 31. Flajolet-Martin ...0 1 0 1 0 1 0 1 0 0 1 0 0 0 P(n trailing zeros) = ?
- 32. Flajolet-Martin ...0 1 0 1 0 1 0 1 0 0 1 0 0 0 P(n trailing zeros) = (┬Į)^n # seen hashes Ōēģ ?
- 33. ŌĆ” x x x x x x x x 0 0 0 Flajolet-Martin ...0 1 0 1 0 1 0 1 0 0 1 0 0 0 P(n trailing zeros) = (┬Į)^n # seen hashes Ōēģ 2^n ŌĆ” x x x x x x x x 0 0 1 ŌĆ” x x x x x x x x 0 1 0 ŌĆ” x x x x x x x x 0 1 1 ŌĆ” x x x x x x x x 1 0 0 ŌĆ” x x x x x x x x 1 0 1 ŌĆ” x x x x x x x x 1 1 0 ŌĆ” x x x x x x x x 1 1 1
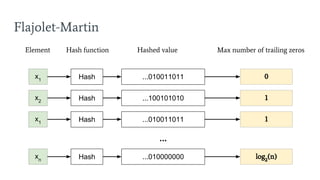
- 34. Flajolet-Martin 0Hash ...010011011 Element Hash function Hashed value Max number of trailing zeros x1 1Hash ...100101010x2 1Hash ...010011011x1 ... Hash ...010000000xn log2 (n)
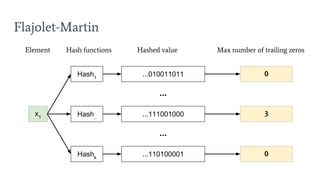
- 35. Flajolet-Martin 0Hash1 ...010011011 Element Hash functions Hashed value Max number of trailing zeros x1 3Hash.. ...111001000 0Hashk ...110100001 ... ...
- 36. Flajolet-Martin - Results VS Naïve approach Flajolet-Martin 500 MB per link 5 PB with 10M links 1,5 KB per link 15 GB with 10M links 2% of error
- 37. Probabilistic search Memopal - Search for similar files Local sensitive hashing & min hashing
- 38. Use case The difference between a petabyte and a gigabyte index is worth an approximation.
- 39. Search - Naïve approach 2 B files 1 PB of index Slow search
- 40. Search - Min hash
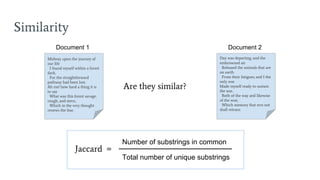
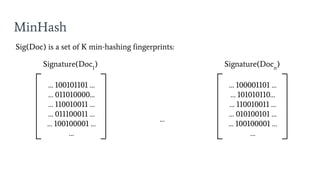
- 41. Day was departing, and the embrowned air Released the animals that are on earth From their fatigues; and I the only one Made myself ready to sustain the war, Both of the way and likewise of the woe, Which memory that errs not shall retrace. Similarity Midway upon the journey of our life I found myself within a forest dark, For the straightforward pathway had been lost. Ah me! how hard a thing it is to say What was this forest savage, rough, and stern, Which in the very thought renews the fear. Are they similar? Jaccard = Number of substrings in common Total number of unique substrings Document 1 Document 2
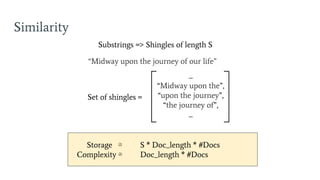
- 42. Similarity Substrings => Shingles of length S Storage Ōēģ S * Doc_length * #Docs Complexity Ōēģ Doc_length * #Docs Set of shingles = ... ŌĆ£Midway upon theŌĆØ, ŌĆ£upon the journeyŌĆØ, ŌĆ£the journey ofŌĆØ, ... ŌĆ£Midway upon the journey of our lifeŌĆØ
- 43. Similarity Fingerprint => 32 bit hash of a shingle Storage Ōēģ 4 byte * Doc_length * #Docs Complexity Ōēģ Doc_length * #Docs Set of shingles = ŌĆ” ŌĆ” 100101101 ŌĆ”, ŌĆ” 011010000ŌĆ”, ŌĆ” 110010011 ŌĆ”, ŌĆ”
- 44. Similarity We need to find a signature Sig(D) of length K so that if Sig(D1 ) ~ Sig(D2 ) then D1 ~ D2 Storage Ōēģ 4 byte * K * #Docs Complexity Ōēģ K * #Docs With K << Doc_length
- 45. MinHash - Signature creation Doc1 ŌĆ”10101 ŌĆ”01100 ŌĆ”10010 ŌĆ”00111 Take a random permutation of the fingerprints. Generate the fingerprints of the documents. Define minhash(Hn , Doci ) = First fingerprint of Doci hashed with Hn Sig(Doci ) of length K = [minhashi , minhash2 , ŌĆ”, minhashn ] Doc1 ŌĆ”00111 ŌĆ”01100 ŌĆ”10101 ŌĆ”10010 Minhash of this permutation Hn
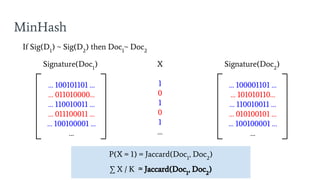
- 46. MinHash Signature(Doc1 ) ŌĆ” 100101101 ŌĆ” ŌĆ” 011010000ŌĆ” ŌĆ” 110010011 ŌĆ” ŌĆ” 011100011 ŌĆ” ŌĆ” 100100001 ŌĆ” ŌĆ” Sig(Doc) is a set of K min-hashing fingerprints: Signature(Docn ) ŌĆ” 100001101 ŌĆ” ŌĆ” 101010110ŌĆ” ŌĆ” 110010011 ŌĆ” ŌĆ” 010100101 ŌĆ” ŌĆ” 100100001 ŌĆ” ŌĆ” ŌĆ”
- 47. MinHash If Sig(D1 ) ~ Sig(D2 ) then Doc1 ~ Doc2 P(X = 1) = Jaccard(Doc1 , Doc2 ) Ōłæ X / K Ōēā Jaccard(Doc1 , Doc2 ) ŌĆ” 100101101 ŌĆ” ŌĆ” 011010000ŌĆ” ŌĆ” 110010011 ŌĆ” ŌĆ” 011100011 ŌĆ” ŌĆ” 100100001 ŌĆ” ŌĆ” ŌĆ” 100001101 ŌĆ” ŌĆ” 101010110ŌĆ” ŌĆ” 110010011 ŌĆ” ŌĆ” 010100101 ŌĆ” ŌĆ” 100100001 ŌĆ” ŌĆ” Signature(Doc1 ) Signature(Doc2 )X 1 0 1 0 1 ŌĆ”
- 48. MinHash - Implementation 1. Generate the fingerprints of the document 2. Define K hash functions: h1 , h2 , .... , hk . 3. Define Sig(Doc) = [h1 (Doc), h2 (Doc), ..., hk (Doc)] 4. Define O = { i / hi (Doc1 ) = hi (Doc2 ) } 5. Sim(Doc1 , Doc2 ) = Ōēā Jaccard(Doc1 , Doc2 ) | O | K Storage Ōēģ 4 byte * K * #Docs Complexity Ōēģ K * #Docs With K << Doc_length
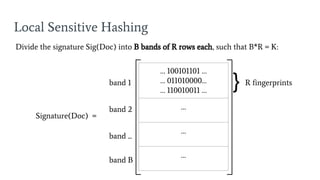
- 49. Local Sensitive Hashing Signature(Doc) = ŌĆ” 100101101 ŌĆ” ŌĆ” 011010000ŌĆ” ŌĆ” 110010011 ŌĆ” ŌĆ” ŌĆ” ŌĆ” Divide the signature Sig(Doc) into B bands of R rows each, such that B*R = K: band 1 band 2 band ... band B } R fingerprints
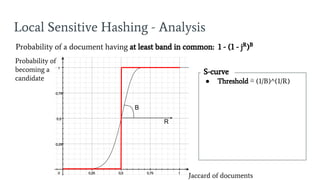
- 50. ŌŚÅ Threshold Ōēģ (1/B)^(1/R) Local Sensitive Hashing - Analysis Probability of a document having at least band in common: 1 - (1 - jR )B Jaccard of documents Probability of becoming a candidate S-curve R B
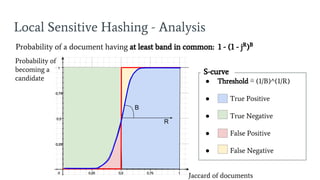
- 51. ŌŚÅ Threshold Ōēģ (1/B)^(1/R) ŌŚÅ True Positive ŌŚÅ True Negative ŌŚÅ False Positive ŌŚÅ False Negative Local Sensitive Hashing - Analysis Probability of a document having at least band in common: 1 - (1 - jR )B Jaccard of documents Probability of becoming a candidate S-curve R B
- 52. Probabilistic search - Results Storage Ōēģ Shingle_length * Doc_length * #Docs Complexity Ōēģ Doc_length * #Docs From: To: Storage Ōēģ 4 byte * K * #Docs Complexity Ōēģ K * #Docs * p(ŌĆ£candidateŌĆØ) With K << Doc_length and p(ŌĆ£candidateŌĆØ) << 1
- 53. Probabilistic search - Results VS Naïve approach Min hash + LSH 2 B files 1 PB of index Slow search 2 B files 1,5 TB of index Fast search & update
- 54. Thank you
- 55. P(|questions| > 0) = 1 - [1 - p(question)]|audience| Any questions?