





![? 2018 NTT DATA Corporation 12
On-going work: Rebalancer
? ¨F◊ī§«§Ō°Ę∆ę§Í§¨įk…ķ§∑§ŅąŲļŌ§ň§Ō•Í•–•ť•ů•Ļ§Ķ§Ľ§ŽĪō“™§¨§Ę§Ž
? •Í•–•ť•ů•Ļ§Ō¨F◊ī ÷Ą”§«§š§Ž§∑§ę§ §§…Ō§ň°Ęü©Žj
? •Í•–•ť•ů•ĻĆĚŌů§ő•«•£•ž•Į•»•Í§Úread-onlyĽĮ§Ļ§Ž
? •«©`•Ņ•≥•‘©`
? Mount table§ő–ř’ż
? Read-only§őĹ‚≥ż
? ĺ…•«©`•Ņ§őŌų≥ż
? ∆ę§Í§Ú◊‘Ą”§«Őō∂®§∑°Ę◊‘Ą”§«•Í•–•ť•ů•Ļ§∑§∆§Į§ž§Ž§»°ĘŖ\”√§¨∑«≥£§ňėS§ň§ §Ž
ť_įk◊īõr
? JIRA§ň§Ōdesign document§¨÷√§§§∆§Ę§Ž§ņ§Ī§ő◊īĎB
? Rebalancer §ÚĆg◊į§∑§∆°Ę§Ĺ§ő‘uĀż§Ú§∑§Ņ’ďőń§¨§Ę§Ž
? Scaling Distributed File Systems in Resource-Harvesting Datacenters [ATC °ģ17]](https://image.slidesharecdn.com/rbf-180813065023/85/HDFS-Router-based-federation-12-320.jpg)













![[db tech showcase Tokyo 2015] B34:•«©`•Ņ§őĀĘŌŽĽĮ§ÚĺŖŐŚĽĮ§Ļ§ŽIBM§ő•Ū•ł•ę•Ž•«©`•Ņ•¶•ß•Ę•Ō•¶•Ļ by »’Īĺ•Ę•§?•”©`?•®...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)




![[db tech showcase Tokyo 2017] D33: Deep Learning§š°ĘAnalytics§ő•Ô©`•Į•Ū©`•…§Úľ”ňŔ§Ļ§Ž§ň§Ō-Ten...](https://cdn.slidesharecdn.com/ss_thumbnails/d33-170912071011-thumbnail.jpg?width=560&fit=bounds)





![[db tech showcase Tokyo 2016] B31: Spark Summit 2016£ņSF§ň≤őľ”§∑§∆§≠§Ņ§ő§«◊Ó–¬ ¬ņż§ §…§ÚĹBĹť§∑§ń§ń•«...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=560&fit=bounds)









More Related Content
What's hot (20)
Similar to HDFS Router-based federation (20)










![[db tech showcase Tokyo 2017] A15: •ž•◊•Í•Ī©`•∑•Á•ů§Ú Ļ”√§∑§Ņ•«©`•Ņ∑÷őŲĽýĪPėčļB§ő•≠•‚£® ¬ņż£©by ÷Í ĹĽŠ…Á•§•ů•Ķ•§•»•∆...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=560&fit=bounds)







More from NTT DATA OSS Professional Services (18)


















Recently uploaded (6)






HDFS Router-based federation
- 1. ? 2018 NTT DATA Corporation 2018/7/20 ľľ–głÔ–¬Ĺyņ®Īĺ≤Ņ •∑•Ļ•∆•ŗľľ–gĪĺ≤Ņ ŲYŘŗ √ų HDFS router based federation
- 2. ? 2018 NTT DATA Corporation 2 Īĺ»’ĹBĹť§Ļ§Ž•Ľ•√•∑•Á•ů ? HDFS router based federation ? Microsoft, Uber§őĻ≤Õ¨įkĪŪ ? ŔYŃŌ: /Hadoop_Summit/hdfs-router-based-federation ? HDFS BoF
- 3. ? 2018 NTT DATA Corporation 3 Źĺņī§őNameNode Federation ? HDFS•Į•ť•Ļ•Ņ§Ú—} ż ݧէ∆°Ę1§ń§őHDFS•Į•ť•Ļ•Ņ§ň“䧼§Ž§Ņ§Š§ő ňĹM§Ŗ ? NameNode§őŌřĹÁ§ÚĺŹļÕ§Ļ§Ž§Ņ§Š§ň°Ęť_įk§Ķ§ž§Ņ ? Uber§«§Ō°Ę¨F‘ŕ§≥§ž§ÚņŻ”√§∑§∆°Ę1§ń§őDC§ī§»§ň3§ń§ő•Į•ť•Ļ•Ņ§ň∑÷łÓ§∑§∆§§§Ž ? Main production HDFS cluster ? HBase cluster ? Tmp cluster (Hive scratch directory, YARN application logs, etc.)
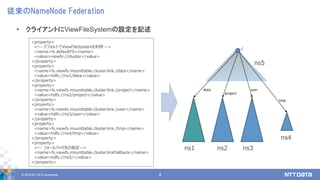
- 4. ? 2018 NTT DATA Corporation 4 Źĺņī§őNameNode Federation ? •Į•ť•§•Ę•ů•»§ňViewFileSystem§ő‘O∂®§Ú”õ Ų <property> <!-- •«•’•©•Ž•»§«ViewFileSystem§ÚņŻ”√ --> <name>fs.defaultFS</name> <value>viewfs://cluster</value> </property> <property> <name>fs.viewfs.mounttable.cluster.link./data</name> <value>hdfs://ns1/data</value> </property> <property> <name>fs.viewfs.mounttable.cluster.link./project</name> <value>hdfs://ns2/project</value> </property> <property> <name>fs.viewfs.mounttable.cluster.link./user</name> <value>hdfs://ns3/user</value> </property> <property> <name>fs.viewfs.mounttable.cluster.link./tmp</name> <value>hdfs://ns4/tmp</value> </property> <property> <!-- •’•©©`•Ž•–•√•ĮŌ»§ő÷ł∂®--> <name>fs.viewfs.mounttable.cluster.linkFallback</name> <value>hdfs://ns5/</value> </property> ns5 ns4 ns1 ns2 ns3
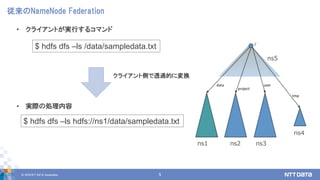
- 5. ? 2018 NTT DATA Corporation 5 Źĺņī§őNameNode Federation ? •Į•ť•§•Ę•ů•»§¨Ćg––§Ļ§Ž•≥•ř•ů•… ? ĆgŽH§őĄIņŪńŕ»› $ hdfs dfs ®Cls /data/sampledata.txt $ hdfs dfs ®Cls hdfs://ns1/data/sampledata.txt ns5 ns4 ns1 ns2 ns3 •Į•ť•§•Ę•ů•»ā»§«ÕłŖ^Ķń§ňČšďQ
- 6. ? 2018 NTT DATA Corporation 6 Źĺņī§őNameNode Federation§őÜĖÓ}Ķ„ ? ViewFileSystem§ő‘O∂®Ļ‹ņŪ ? »ę§∆§ő•Į•ť•§•Ę•ů•»§ň»ę§ĮÕ¨§ł‘O∂®§ÚĆg ©§Ļ§ŽĪō“™§¨§Ę§Ž ? ‘O∂®ČšłŁ§Ō»ę§∆§ő•Į•ť•§•Ę•ů•»§ň”įŪĎ ? Subclusterťg§ő•Í•–•ť•ů•Ļ§¨ ÷Ą” ? Ĺ‚õQ≤Ŗ ? Mount table§Ú÷–—ŽľĮėōĶń§ňĻ‹ņŪ§Ļ§Ž ? Routing layer§Úľ”§®§Ž
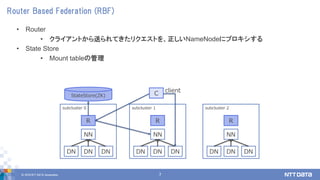
- 7. ? 2018 NTT DATA Corporation 7 Router Based Federation (RBF) ? Router ? •Į•ť•§•Ę•ů•»§ę§ťňÕ§ť§ž§∆§≠§Ņ•Í•Į•®•Ļ•»§Ú°Ę’ż§∑§§NameNode§ň•◊•Ū•≠•∑§Ļ§Ž ? State Store ? Mount table§őĻ‹ņŪ subcluster 0 R NN DN DN DN subcluster 1 R NN DN DN DN subcluster 2 R NN DN DN DN StateStore(ZK) clientC
- 8. ? 2018 NTT DATA Corporation 8 RBF deployments ? Microsoft ? 23K servers ? 8 subclusters ? 28 NameNodes ? 28 Routers ? Uber ? 2 routers ? 1 data center
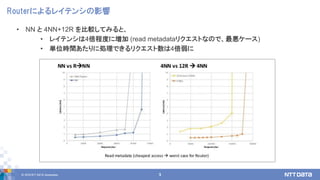
- 9. ? 2018 NTT DATA Corporation 9 Router§ň§Ť§Ž•ž•§•∆•ů•∑§ő”įŪĎ ? NN §» 4NN+12R §ÚĪ»›^§∑§∆§Ŗ§Ž§»°Ę ? •ž•§•∆•ů•∑§Ō4Ī∂≥Ő∂»§ňČąľ” (read metadata•Í•Į•®•Ļ•»§ §ő§«°Ę◊Óźô•Ī©`•Ļ) ? ÖgőĽērťg§Ę§Ņ§Í§ňĄIņŪ§«§≠§Ž•Í•Į•®•Ļ•» ż§Ō4Ī∂»ű§ň
- 10. ? 2018 NTT DATA Corporation 10 ť_įk◊īõr ? •Ę•Į•∆•£•÷§ňť_įk§¨ĺA§§§∆§§§Ž ? Phase 1 (HDFS-10467, 2016/5~2017/10, 22/22 subtasks) ? Phase 2 (HDFS-12165, 2017/10~, 66/86 subtasks) ? New features ? WebHDFS ? Federated quotas ? On-going work ? Mount points across subclusters (HDFS-13224) ? Rebalancer (HDFS-13123)
- 11. ? 2018 NTT DATA Corporation 11 Mount points across subclusters ? •ř•¶•ů•»•›•§•ů•»§»subcluster§Ō1ĆĚ1ĆĚŹÍ ? 1ĆĚNĆ̏ͧĶ§Ľ§Ž§≥§»§«°Ę»›ŃŅ§šNameNode§ō§ő•Í•Į•®•Ļ•»§ő∆ę§Í§¨Ĺ‚ŌŻ§«§≠§Ž ? §…§¶§š§√§∆łÓ§ÍĶĪ§∆§Ž§ę ? Consistent hashing ? HASH (•«•£•ž•Į•»•Í1ŽAĆ”ńŅ§ő•Ō•√•∑•Ś), HASH_ALL (•’•Ž•—•Ļ§ő•Ō•√•∑•Ś) ? LOCAL ? RANDOM ? ÷∆ľs ? •’•°•§•Ž§ÚŐŧĻ§Ņ§Š§ň—} ż§ő•Į•ť•Ļ•Ņ§Úř{§ŽĪō“™§¨§Ę§Ž (consistent hashing“‘Õ‚) ? rename§¨•Į•ť•Ļ•ŅŅÁ§ģ§ň§ §ŽŅ…ń‹–‘§¨§Ę§Í°Ę∑«ĄŅ¬ ? trunk§ň•ř©`•łúg
- 12. ? 2018 NTT DATA Corporation 12 On-going work: Rebalancer ? ¨F◊ī§«§Ō°Ę∆ę§Í§¨įk…ķ§∑§ŅąŲļŌ§ň§Ō•Í•–•ť•ů•Ļ§Ķ§Ľ§ŽĪō“™§¨§Ę§Ž ? •Í•–•ť•ů•Ļ§Ō¨F◊ī ÷Ą”§«§š§Ž§∑§ę§ §§…Ō§ň°Ęü©Žj ? •Í•–•ť•ů•ĻĆĚŌů§ő•«•£•ž•Į•»•Í§Úread-onlyĽĮ§Ļ§Ž ? •«©`•Ņ•≥•‘©` ? Mount table§ő–ř’ż ? Read-only§őĹ‚≥ż ? ĺ…•«©`•Ņ§őŌų≥ż ? ∆ę§Í§Ú◊‘Ą”§«Őō∂®§∑°Ę◊‘Ą”§«•Í•–•ť•ů•Ļ§∑§∆§Į§ž§Ž§»°ĘŖ\”√§¨∑«≥£§ňėS§ň§ §Ž ť_įk◊īõr ? JIRA§ň§Ōdesign document§¨÷√§§§∆§Ę§Ž§ņ§Ī§ő◊īĎB ? Rebalancer §ÚĆg◊į§∑§∆°Ę§Ĺ§ő‘uĀż§Ú§∑§Ņ’ďőń§¨§Ę§Ž ? Scaling Distributed File Systems in Resource-Harvesting Datacenters [ATC °ģ17]
- 13. ? 2018 NTT DATA Corporation 13 Future plan ? Uber ? Observer NameNode (HDFS-12943) ? RBF ? Upgrade to 3.x and use Erasure-Coding ? Auto rebalancing between hot and warm clusters ? Microsoft ? Federating federation!!!
- 14. ? 2018 NTT DATA Corporation 14 HDFS BoF ? ť_įk’Ŗ§¨ľĮ§ř§√§∆°Ęłų◊‘‘í§∑§Ņ§§§≥§»§Ú‘í§Ļ ? •Ę•ł•ß•ů•ņ§Ō§Ĺ§őąŲ§«õQ§ř§Ž
- 15. ? 2018 NTT DATA Corporation 15 HDFS BoF ? §Ĺ§őąŲ§«ēݧ꧞§Ņ•Ę•ł•ß•ů•ņ ? ť_įk’Ŗ§¨∂ŗ§§•∑•Í•≥•ů•–•ž©`ť_īŖ§ņ§ę§ť§≥§Ĺ§őľĮ§ř§ÍĺŖļŌ (HDFS§«20»ň§Į§ť§§§§§∆°ĘīůįŽ§Ō•≥•Ŗ•√•Ņ) ? ňŻ§ő•ę•ů•’•°•ž•ů•Ļ§ň§Ō§ §§°ĘDataworks Summit§őűģű≠ő∂§ņ§»ňľ§¶ ? ņīńͧŌĖ|ļ£į∂ť_īŖ§ §ő§«°ĘľĮ§ř§Í§¨źô§Į§ §ť§ §§§ę≤Ľį≤
- 16. ? 2018 NTT DATA Corporation