Flow Solver: HiFUN
0 likes437 views

This document summarizes the performance of HiFUN, a computational fluid dynamics (CFD) solver, on parallel computing platforms using Intel MPI library. It finds that HiFUN demonstrates high scalability, with a cell count of a few thousand achieving over 85% parallel efficiency. Testing on grids with 12.7 million to 63.5 million cells on platforms with up to 10,248 cores shows near ideal speedup and good parallel efficiency. HiFUN also exhibits strong algorithmic scalability, with convergence independent of core count. This makes HiFUN highly suitable for industrial CFD simulations.



Flow Solver: HiFUN
- 1. Aerospace Supercomputing Demonstrates the Parallelism Advantage High Resolution Flow Solver on Unstructured Meshes (HiFUN) Offers Extreme Scalable Performance Overview Simulation and Innovation Engineering Solutions (SandI) Pvt. Ltd. (www.sandi.co.in) is a technology-driven company incubated from the Indian Institute of Science (www.iisc.ernet.in), one of IndiaĪ»s premier research institutes. While the main focus of the company is on promotion of the CFD flow solver HiFUN (High Resolution Flow Solver on Unstructured Meshes), SandI is also involved in providing high-end CFD services to the aerospace industry. One of the primary strengths of SandI is that it is continuously supported by research and development initiatives from the Computational Aerodynamic Laboratory (CAd Lab) in the Department of Aerospace Engineering at IISc. This enables SandI to evolve current CFD tools and processes, while at the same time meeting ever- increasing customer needs and demands. HiFUN Supports Complex Simulations and Delivers Usable Data The primary product of SandI, the state-of-the-art, general-purpose CFD solver HiFUN, is robust, fast, and accurate, providing aerodynamic design data in a time-frame that is most attractive to designers. The usefulness of HiFUN stems from its ability to handle complex geometries and flow physics arising in a typical industrial environment. While the use of unstructured data capable of handling arbitrary polyhedral volumes renders the code HiFUN, the ability to simulate complex geometries with relative ease and the use of a matrix-free implicit procedure resulting in rapid convergence to steady state makes the solver both efficient and robust. The accuracy of HiFUN has been amply demonstrated through participation in various international CFD code evaluation exercises such as the AIAA Drag Prediction Workshop (http://aaac.larc.nasa.gov/tsab/ cfdlarc/aiaa-dpw) and AIAA High Lift Prediction Workshop (http://hiliftpw.larc.nasa.gov). In the High Lift workshop in Chicago, U.S.Ī¬where 18 organizations from eight countries participatedĪ¬HiFUN was judged one of the very good CFD solvers. The other important strength of HiFUN is its ability to scale over several thousand processor cores in a typical massively parallel supercomputing environment. This feature is a boon to the designerĪ¬who can expect to have a turnaround time independent of the problem size. With these features, HiFUN has been successfully used in simulations for a wide range of flow problems, from low subsonic speeds to hypersonic speeds (http://www.sandi.co.in). HiFun and Parallel Performance For a CFD solver like HiFUN, two important indicators of parallel performance are parallel scalability and algorithmic scalability. For an iterative solver, parallel scalability demands that the time taken by the solver per iteration should inversely reduce as Ī░The ability to simulate complex geometries with relative ease and the use of a matrix-free implicit procedure resulting in rapid convergence to steady state makes the solver both efficient and robust.Ī▒ ©C Dr. Nikhil V Shende Director S & I Engineering Solutions Pvt. Ltd. case study Intel? Software Development Tools Intel? Cluster Studio XE, Intel? Fortran Compiler, and Intel? MPI Library
- 2. the number of compute cores increase. Parallel scalability depends on balancing the computational load across the cores, while at the same time ensuring minimum data communication across them. In the present study, the software METIS (http://glaros.dtc.umn.edu/gkhome/views/ metis), is employed to obtain optimal load balance, based on a multilevel, multi- constraint graph partitioning algorithm. The other important indicator of parallel performance, the algorithmic scalability, effectively means that numerical performance of the code is independent of the number of compute cores employed for computations. The algorithmic scalability of the solver depends on the ability of underlying serial algorithms to be amenable to efficient parallelization and their actual implementation in the solver framework. The use of a novel four-layer data structure enables HiFUN to achieve a high level of algorithmic scalability. HiFUN employs standard mode, nonblocking communication MPI directives to transfer data across the compute cores. The parallel performance of HiFUN is studied by simulating subsonic flow past NASA Trapezoidal Wing (NASA Trap Wing: http://hiliftpw.larc.nasa.gov/index- workshop1.html). Trap Wing is a typical high-lift configuration offering adequate geometric complexity. Simulating the resulting complex flow is a challenge to the CFD community. Naturally, the grid for adequately resolving such a complex flow is large and makes this problem an ideal candidate for evaluating the parallel performance of a CFD solver. For this study, the free stream Mach number is 0.2, the angle of attack is 28 degrees, and the free stream Reynolds number based on mean aerodynamic chord of the wing is 4.2 million. The computations are performed on three hybrid unstructured grids consisting of prismatic and tetrahedral elements. Table 1 gives the size of each grid in terms of number of cells. Figure 1 depicts an unstructured surface grid on NASA Trap Wing and figure 2 depicts typical pressure distribution on the wing. Compute Platforms The parallel performance of HiFUN using grid UG1 is studied on Endeavor, an Intel? 360-node HPC cluster. At the time of the study, each node of Endeavor consists of dual hexacore Intel? Xeon? X5670 B1 Step processors using 2.93 GHz with 24 GB RAM. The interconnect used for connecting the nodes is InfiniBand QDR, and message passing across the nodes is achieved using Intel? MPI Library, 4.0.3. The parallel performance of HiFUN using grids UG2 and FG is studied on the compute platform Pleiades, available with NASA (http://www.nas.nasa.gov/hecc/ resources/pleiades.html). This system consists of 4480 nodes of Intel Xeon X5670 processors using 2.93 GHz and 128 nodes of Intel? Xeon? X5675 processors using 3.06 GHz. Each node of Pleiades consists of dual hexacore processors with 24 GB RAM. The interconnect used for connecting the nodes is InfiniBand QDR host channel adapter and message passing across the nodes is achieved using Intel MPI Library, version 4.0.3. The Intel MPI Library is a multifabric message passing library that implements the MPI, v2 (MPI-2) specification (http://www.intel.com/go/mpi). It is the commercially supported, high-performance software product based on MPICH2 from Argonne National Laboratory. Results and Discussion The parameters used to study parallel performance of HiFUN are speedup and parallel efficiency defined as follows: Ideal speedup: The ratio of the number of compute cores used for a given run to the reference number of compute cores. Actual speedup: The ratio of time per iteration using reference number of cores to the time per iteration using number of compute cores for a given run. Parallel efficiency: The ratio of actual speedup to ideal speedup. A typical CFD problem is amenable to coarse grain parallelism, given the large quantum of computation compared to the communication associated with a core. Therefore, for a given grid size with an increase in the number of cores, the problem becomes more and more communication dominant, effectively reducing the parallel efficiency. Hence, based on a problem size, the user should choose the number of processor cores that ensures parallel efficiency around 85 percent in order to achieve optimal utilization of computing resources and fast turnaround time. Often, the minimum number of cells per core for ensuring an acceptable threshold parallel efficiency (say 85 percent)Ī¬what we refer to as the C-countĪ¬can be a good indicator to the level of parallelism a CFD solver offers. In fact, the C-count can be a very useful indicator in determining the optimal number of cores on a given machine for different grid sizes. We use these performance parameters to study the scalability offered by the code HiFUN in conjunction with Intel MPI Library. Grid ID Grid Type Number of Cells UG1 Hybrid unstructured: prisms + tetrahedrons 12.7 million UG2 Hybrid unstructured: prisms + tetrahedrons 38.5 million FG Hybrid unstructured: prisms + tetrahedrons 63.5 million Table 1. Grids used for the computations Figure 1. Surface grid on NASA Trap Wing Figure 2. Surface pressure distribution
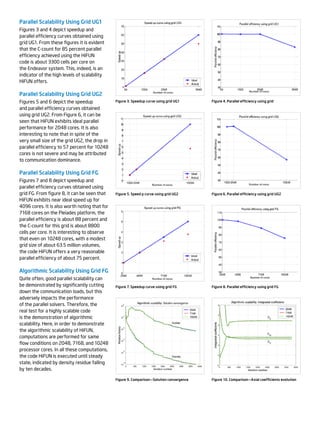
- 3. Parallel Scalability Using Grid UG1 Figures 3 and 4 depict speedup and parallel efficiency curves obtained using grid UG1. From these figures it is evident that the C-count for 85 percent parallel efficiency achieved using the HiFUN code is about 3300 cells per core on the Endeavor system. This, indeed, is an indicator of the high levels of scalability HiFUN offers. Parallel Scalability Using Grid UG2 Figures 5 and 6 depict the speedup and parallel efficiency curves obtained using grid UG2. From Figure 6, it can be seen that HiFUN exhibits ideal parallel performance for 2048 cores. It is also interesting to note that in spite of the very small size of the grid UG2, the drop in parallel efficiency to 57 percent for 10248 cores is not severe and may be attributed to communication dominance. Parallel Scalability Using Grid FG Figures 7 and 8 depict speedup and parallel efficiency curves obtained using grid FG. From figure 8, it can be seen that HiFUN exhibits near ideal speed up for 4096 cores. It is also worth noting that for 7168 cores on the Pleiades platform, the parallel efficiency is about 88 percent and the C-count for this grid is about 8800 cells per core. It is interesting to observe that even on 10248 cores, with a modest grid size of about 63.5 million volumes, the code HiFUN offers a very reasonable parallel efficiency of about 75 percent. Algorithmic Scalability Using Grid FG Quite often, good parallel scalability can be demonstrated by significantly cutting down the communication loads, but this adversely impacts the performance of the parallel solvers. Therefore, the real test for a highly scalable code is the demonstration of algorithmic scalability. Here, in order to demonstrate the algorithmic scalability of HiFUN, computations are performed for same flow conditions on 2048, 7168, and 10248 processor cores. In all these computations, the code HiFUN is executed until steady state, indicated by density residue falling by ten decades. Figure 3. Speedup curve using grid UG1 Figure 5. Speed p curve using grid UG2 Figure 7. Speedup curve using grid FG Figure 9. ComparisonĪ¬Solution convergence Figure 4. Parallel efficiency using grid Figure 6. Parallel efficiency using grid UG2 Figure 8. Parallel efficiency using grid FG Figure 10. ComparisonĪ¬Axial coefficients evolution
- 4. Figure 9 depicts the convergence histories for density and modified turbulence viscosity (Nutilda) using 2048, 7168, and 10248 processor cores. The excellent algorithmic scalability exhibited by HiFUN is brought out in figure 8, wherein the residue curves corresponding to density/ Nutilda are identical for a widely varying number of processor cores. Figure 10 depicts the evolution of axial force and moment coefficients using 2048, 7168, and 10248 processor cores. The overlap of the corresponding coefficient curves obtained using these processor cores further demonstrates the high level of algorithmic scalability exhibited by HiFUN. These curves eloquently bring out the efficacy of the parallel algorithm employed in HiFUN and its accurate implementation. Table 2 presents the comparison of lift, drag, and pitching moment coefficients obtained using the aforementioned sets of processor cores with the experimental results. From this table, it can be seen that the results obtained using the code HiFUN are in excellent agreement with experimental results. Finally, for the designer, Table 3 shows the total time in minutes to achieve steady state convergence on the grid FG for different numbers of processor cores. From this table it is amply clear that using 7168 processor cores, even for grid FGĪ¬which is reasonably fine by industry standardsĪ¬ about 40 solution data points can be generated in a day. Such a fast turnaround time offered by highly scalable code HiFUN was achieved in conjunction with compiling the code with the Intel? Cluster Studio XE suite of HPC tools. Achieving this type of performance and productivity can completely change the design paradigmĪ¬providing the designer with access to high-fidelity aerodynamic data even during early phases of aerodynamic design. Conclusion The present study focuses on performance evaluation of the parallel CFD software HiFUN on massively parallel computing platforms using the Intel MPI library. The indicators parallel scalability and algorithmic scalability are employed for evaluating the parallel performance of the code HiFUN. A high lift NASA Trap Wing configuration offering complexity in both geometry and flow physics is considered. Three grids are utilized: UG1, UG2, and FG, corresponding to coarse, medium, and fine categories. While parallel scalability of the code HiFUN is demonstrated on all three grids, its algorithmic scalability is demonstrated on the grid FG. From this study, it can be concluded that: 1. The code HiFUN is highly scalable. 2. The code HiFUN offers very small C-count, typically of the order of a few thousand volumes with its potential to exploit massive parallelism. 3. Independent of the number of processor cores and parallel performance, the code HiFUN exhibits near-ideal algorithmic scalability. A scalable parallel application stands on the tripod of an efficient parallel implementation of an underlying algorithm, an efficient message passing library that minimizes redundancies during data transfer across the processor cores, and an optimized network topology interconnecting processor cores that ensures scalable performance on large numbers of processor cores. In this regard, it can be concluded that the software HiFUN along with Intel MPI library and Intel Xeon processor-based platforms offers an extremely scalable CFD solution. Learn more about Intel? software development tools at http:// software.intel.com/en-us/intel-sdp- home/. Method Number of Cores Lift Coefficient Drag Coefficient Pitching Moment Coefficient HiFUN 2048 2.8806 0.6747 -0.4387 HiFUN 7168 2.8797 0.6744 -0.4383 HiFUN 10248 2.8797 0.6744 -0.4385 Experiment N/A 2.8952 0.6776 -0.4558 Number of Cores Time to Steady State Convergence in Minutes 2048 93 7168 30 10248 25 Table 2. Comparison of integrated force and moment coefficients using grid FG with experimental results Table 3. Time required for HiFUN to steady state on grid FG using various sets of processor cores For more information regarding performance and optimization choices in Intel? software products, visit http://software.intel.com/en-us/articles/optimization-notice. Optimization Notice: IntelĪ»s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel? microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel? microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 This document and the information given are for the convenience of IntelĪ»s customer base and are provided Ī░AS ISĪ▒ WITH NO WARRANTIES WHATSOEVER, EXPRESS OR IMPLIED, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, AND NONINFRINGEMENT OF INTELLECTUAL PROPERTY RIGHTS. Receipt or possession of this document does not grant any license to any of the intellectual property described, displayed, or contained herein. Intel? products are not intended for use in medical, lifesaving, life-sustaining, critical control, or safety systems, or in nuclear facility applications. Performance tests and ratings are measured using specific computer systems and/or components and reflect the approximate performance of Intel products as measured by those tests. Any difference in system hardware or software design or configuration may affect actual performance. Intel may make changes to specifications, product descriptions, and plans at any time, without notice. ? 2013, Intel Corporation. All rights reserved. All rights reserved. Intel, the Intel logo, and Intel Xeon are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others. Printed in USA 0401/BLA/CMD/PDF Please Recycle 328787-001US