Hive-sub-second-sql-on-hadoop-public
3 likes1,105 views

数千億行のデータをApache Hiveで処理する2つの具体的なユースケースをご紹介します。







![Page 9 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved
クエリ実?
クエリ実?は最終的?連の組合せ
?? クライアントの実? [ 正しくやれば 0s ]
?? オプティマイゼーション [HiveServer2] [~ 0.1s]
?? HCatalog問合せ [Hcatalog, Metastore] [ hive 0.14 は?常に早い ]
?? Application Master 作成 [4-5s]
?? コンテナ割当 [3-5s]
?? クエリ実?
YARN and HDFS
HiveServer2
Server #1
Client
Running testing tool
N connections
N connections
Metastore Metastore DB
HiveServer2
Server #2
Tez
AM
Tez
Container
Tez
Container
…](https://image.slidesharecdn.com/sub-second-sql-on-hadoop-public-151030091141-lva1-app6891/85/Hive-sub-second-sql-on-hadoop-public-9-320.jpg)







Hive-sub-second-sql-on-hadoop-public
- 1. Apache Hive Hadoop上のSub-second SQL Yifeng Jiang Solutions Engineer, Hortonworks Japan 2015/10/14 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved
- 2. Page 2 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved アジェンダ ?? Hiveユースケース#1: 超?量データの?並列処理 ?? Hiveユースケース#2: Hive LLAPによるオンラインレポーティング
- 3. ? Hortonworks Inc. 2015. All Rights Reserved Hiveユースケース#1: 超大量データの高並列処理 Page 3 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved
- 4. Page 4 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved ユースケース #1 バッチ レポーティング 超巨?なデータセット ?? 13ヶ?、5千億?以上 ?? 毎?13億?が追加 ?いスループットが求められます ?? ?? 100,000 レポート ?? 15,000クエリを1時間以内で完了しなけ ればならない Input Dataset
- 5. Page 5 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved Hiveチューニング 4つの Hive チューニング ポイント ?? パーティション ?? データロード ?? クエリ実? ?? 並列のためのチューニング
- 6. Page 6 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved パーティション パーティションの数を最?化 ?? パフォーマンスにとって基本的かつ最も重 要なポイント ?? 必要なデータのみ読込み 合計数千パーティション以下になるように ?? Hiveはクエリを早く処理するための適切 な数 CREATE TABLE access_logs ( host string, path string, referrer string, … ) PARTITIONED BY ( site int, ymd date )
- 7. Page 7 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved データロード データをORC形式のHiveテーブルにロード 3つの主なORCパラメータ ?? ファイルシステムのブロックサイズ: 256MB ?? ストライプサイズ: 64MB ?? 圧縮: ZLIB ?? ZLIBは最近のHiveバージョンには?度に最適化さ れている
- 8. Page 8 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved データロード ORCファイルは?分に?きいことを確認 ?? 可能なら1?10HDFSブロックぐらい ?? たくさんの reducers がすべてのパーティションへの書込みを避ける ?? Optimize sort dynamic partitioning を有効に ?? あるいは DISTRIBUTED BY 句を使う ?? 細かいコントロールがきくため DISTRIBUTED BY を選んだ INSERT INTO orc_sales PARTITION ( country ) SELECT FROM daily_sales DISTRIBUTE BY country, gender;
- 9. Page 9 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved クエリ実? クエリ実?は最終的?連の組合せ ?? クライアントの実? [ 正しくやれば 0s ] ?? オプティマイゼーション [HiveServer2] [~ 0.1s] ?? HCatalog問合せ [Hcatalog, Metastore] [ hive 0.14 は?常に早い ] ?? Application Master 作成 [4-5s] ?? コンテナ割当 [3-5s] ?? クエリ実? YARN and HDFS HiveServer2 Server #1 Client Running testing tool N connections N connections Metastore Metastore DB HiveServer2 Server #2 Tez AM Tez Container Tez Container …
- 10. Page 10 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved クエリ実? コレクション作成がオーバヘッドが?い ?? 1つのコレクション接続に?量のクエリを実? ?? 標準なコレクション プールを利? 2つの HiveServer2 でクエリを分散 ?? HiveServer2 が 8-15 queries/s でボトルネックになった ?? 複数の HiveServer2 をAmbariからデプロイ ?? 新しいバージョンではクエリの並列コンパイルを対応予定
- 11. Page 11 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved クエリ実? Tezセッションの再利?と暖機運転 ?? Tezセッションの再?成が5秒以上かかる ?? Tezセッション再利?を有効に ?? 暖機運転による事前?成も可能 ?? 暖機運転を有効にした場合、フルスピードは実質的に?瞬で出せる Tezコンテナの再利? ?? コンテナの作成は3秒かかる ?? コンテナ再利?を有効に。短い間キープする。 ?? キーは100%利?率を実現しながらリソースを無駄にしない
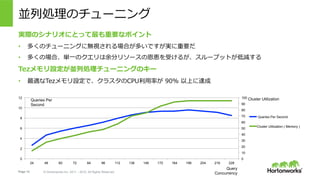
- 12. Page 12 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved 0 10 20 30 40 50 60 70 80 90 100 0 2 4 6 8 10 12 24 48 60 72 84 96 112 136 148 172 184 196 204 216 228 Queries Per Second Cluster Utilization ( Memory ) 並列処理のチューニング 実際のシナリオにとって最も重要なポイント ?? 多くのチューニングに無視される場合が多いですが実に重要だ ?? 多くの場合、単?のクエリは余分リソースの恩恵を受けるが、スループットが低減する Tezメモリ設定が並列処理チューニングのキー ?? 最適なTezメモリ設定で、クラスタのCPU利?率が 90% 以上に達成 Cluster UtilizationQueries Per Second Query Concurrency
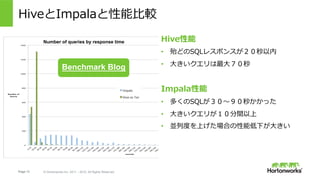
- 13. Page 13 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved HiveとImpalaと性能?較 Hive性能 ?? 殆どのSQLレスポンスが20秒以内 ?? ?きいクエリは最?70秒 Impala性能 ?? 多くのSQLが30?90秒かかった ?? ?きいクエリが10分間以上 ?? 並列度を上げた場合の性能低下が?きい Benchmark Blog Number of queries by response time
- 14. ? Hortonworks Inc. 2015. All Rights Reserved Hiveユースケース#2: Hive LLAPによるオンラインレポーティング Page 14 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved
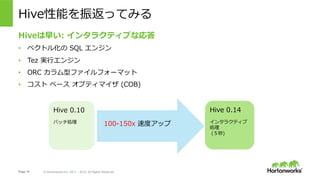
- 15. Page 15 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved Hive性能を振返ってみる Hiveは早い: インタラクティブな応答 ?? ベクトル化の SQL エンジン ?? Tez 実?エンジン ?? ORC カラム型ファイルフォーマット ?? コスト ベース オプティマイザ (COB) Hive 0.10 バッチ処理 100-150x 速度アップ Hive 0.14 インタラクティブ 処理 (5秒)
- 16. Page 16 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved Hiveユースケース#2 オンライン レポーティング ?? インタラクティブなオンライン レポート ?? 巨?なデータセット ?? 低レイテンシ:秒以下(sub-second)?数秒(超巨?なデータの場合) ?? ?い並列度
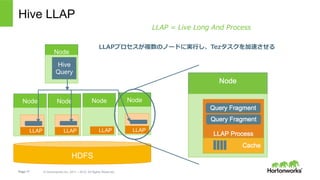
- 17. Page 17 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved Hive LLAP HDFS LLAPプロセスが複数のノードに実?し、Tezタスクを加速させる Node Hive Query Node NodeNode Node LLAP LLAP LLAP LLAP LLAP = Live Long And Process
- 18. Page 18 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved Hive LLAP – 主な利点 パフォーマンスの利点 ?? 起動時間の短縮 ?? データ キャッシュ ?? 常時稼働のため最適化しやすい: JIT、 並列 I/O、 など
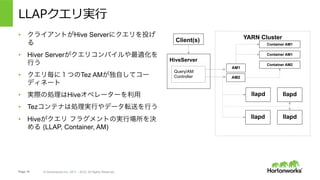
- 19. Page 19 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved LLAPクエリ実? ?? クライアントがHive Serverにクエリを投げ る ?? Hiver Serverがクエリコンパイルや最適化を 行う ?? クエリ毎に1つのTez AMが独自してコー ディネート ?? 実際の処理はHiveオペレーターを利用 ?? Tezコンテナは処理実行やデータ転送を行う ?? Hiveがクエリ フラグメントの実行場所を決 める (LLAP, Container, AM) HiveServer Query/AM Controller Client(s) YARN Cluster AM1 llapd llapd llapd Container AM1 Container AM1 llapd Container AM2 AM2
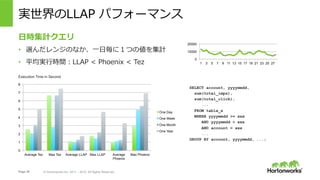
- 20. Page 20 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved 実世界のLLAP パフォーマンス 0 10000 20000 1 3 5 7 9 11 13 15 17 19 21 23 25 27 ?時集計クエリ ?? 選んだレンジのなか、??毎に1つの値を集計 ?? 平均実?時間:LLAP < Phoenix < Tez Execution Time in Second 0 1 2 3 4 5 6 7 8 Average Tez Max Tez Average LLAP Max LLAP Average Phoenix Max Phoenix One Day One Week One Month One Year SELECT account, yyyymmdd, sum(total_imps), sum(total_click), ... FROM table_x WHERE yyyymmdd >= xxx AND yyyymmdd < xxx AND account = xxx ... GROUP BY account, yyyymmdd, ...;
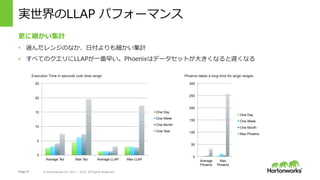
- 21. Page 21 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved 実世界のLLAP パフォーマンス Execution Time in seconds over time range 0 5 10 15 20 25 Average Tez Max Tez Average LLAP Max LLAP One Day One Week One Month One Year 0 50 100 150 200 250 300 Average Phoenix Max Phoenix One Day One Week One Month Max Phoenix Phoenix takes a long time for large ranges 更に細かい集計 ?? 選んだレンジのなか、?付よりも細かい集計 ?? すべてのクエリにLLAPが?番早い。Phoenixはデータセットが?きくなると遅くなる
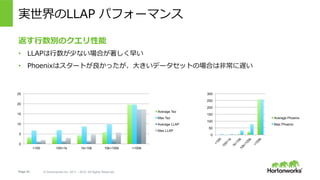
- 22. Page 22 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved 実世界のLLAP パフォーマンス 返す?数別のクエリ性能 ?? LLAPは?数が少ない場合が著しく早い ?? Phoenixはスタートが良かったが、?きいデータセットの場合は?常に遅い 0 5 10 15 20 25 <100 100<1k 1k<10k 10k<100k >100k Average Tez Max Tez Average LLAP Max LLAP 0 50 100 150 200 250 300 Average Phoenix Max Phoenix
- 23. Page 23 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved まとめ Page 23 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved
- 24. Page 24 ? Hortonworks Inc. 2011 – 2015. All Rights Reserved Hiveの今とこれから Hive SQL on Hadoopの事実上の標準 ?? 1つのツールで、バッチやインタラクティブ処理 ?? 1つのツールで、すべてのビッグデータSQLユースケース ?? ETL、レポーティング、BI、ディープ分析など ?? LLAP が実現するSub-second Hive ?? 実世界の超巨?スケールで証明されたパフォーマンス