IDS 570 project presentation
•Download as PPTX, PDF•
0 likes•188 views

This document summarizes an analysis of wine quality data. It describes the steps taken which include data exploration, cleaning, examining relationships between variables, modeling and prediction. The data was explored, cleaned by imputing missing values, removing outliers, and scaling quantitative variables. Correlations between variables and the output quality variable were examined. The data was divided into train and test sets, and regression modeling was performed on the train set to determine important predictors of quality. The model was then used to predict quality on the test set.








IDS 570 project presentation
- 1. Analysis of wine quality Aadhish Chopra Abhilekh Das Gopal Bhutada Parichay Jain Presented By:
- 2. Steps: â—ŹData Exploration â—ŹData Cleaning â—ŹExamining Relationship â—ŹModeling and Prediction
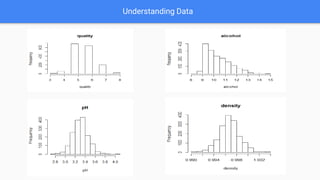
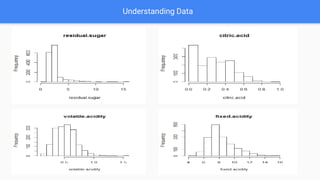
- 3. Data Exploration Dataset Source Link: https://archive.ics.uci.edu/ml/datasets/Wine+Quality Predictors (Variables) in dataset: fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, sulphates, alcohol Output variable:quality
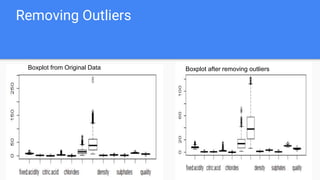
- 8. Data Cleaning The cleaning of the data is done in three steps here Imputation of missing values Removal of outliers Scaling of all the Quantitative variables
- 9. Removing Outliers Boxplot from Original Data Boxplot after removing outliers
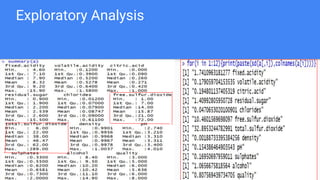
- 11. Examining Relationship Correlation between the variables â—Ź We try to find out the relation between various attributes and with respect to our output variable quality â—Ź Correlation factor lies between -1 to +1 â—Ź Chart along-with indicates the measure of correlation between various attributes.
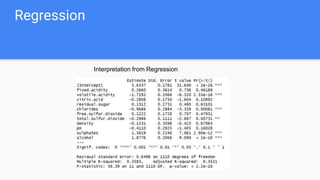
- 12. Regression Divide data into train and test data Train data using regression model Based on the output of regression analysis we find out the parameters which has statistical importance over the quality of wine and are not by random chance Model analysis various combinations and finally concludes the one with minimum RSE, better adjusted R-squared value and F-statistics
- 14. Prediction Based on the train data we try to predict the quality in the test data that is we apply our model on test data