ILSVRC2015 ÊÖ·š€Î„á„â
?
2 likes?5,606 views

ILSVRC2015€ÎÊÖ·š€òœBœé€·€żÙYÁÏ€Ç€čĄŁ „á„âű€łÌ¶È€ÎÄÚÈʀǀ耏čČÓĐ€·€Ț€čĄŁ ImageNet and MS COCO Visual Recognition Challenges Joint Workshop http://image-net.org/challenges/ilsvrc+mscoco2015

![Sergey Zagoruyko, Tsung-Yi Lin, Pedro Pinheiro, Adam Lerer, Sam Gross,
Soumith Chintala, Piotr Dollšąr, FAIR (Facebook AI Research), in ILSVRC, 2015.
ĄŸ1Ąż
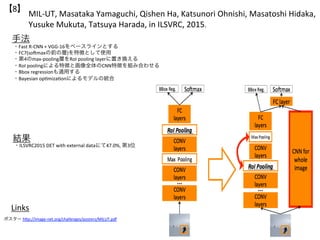
ÊÖ·š
Links
„Ę„č„ż©` hLp://image-net.org/challenges/talks/COCO-ICCV15-clean.pdf
œYčû
?Facebook€ÏCOCO Object DetecSon€Ë„Ő„©©`„«„耷€Æ€€€ż
?DeepMask[Pinheiro+, NIPS2015]€Ë€è€ëșòŃaîIÓò€ÈFast R-CNN€Ë€·€ÆŃ}Êę€ÎžÄÉÆ
?IteraSve LocalizaSon (+1.0AP)€äTop-down re?nement (+0.7AP)€Ê€É€Î„Æ„Ż„Ë„Ă„Ż€âÓĐż
?„Ń„Ă„Á€ò·Öœâ€·€ÆÌŰŐÔuę?BBox»Űą€č€ëFoveal structure[Gidaris+, ICCV2015]€Ë€è€ê+2.0AP
?Ń}Êę€ÎÖŰ€Ê€êÂʀˀè€ëŐ`ČîMulS-threshold loss€Ë€è€ê+1.5AP
?„È„ì©`„Ë„ó„°€Ï4Maxwell GPU€òÓĂ€€€Æ4ÈŐégŁŹ8x4 Kepler/ElasSc Averaging SGD[Zhang+, NIPS2015]€Ë€è€ê2.5ÈŐ
?Base Model€Ë€è€ê30.1APŁŹHorizontal ?ip€Ë€è€ê31.1APŁŹROI Pooling '2 crop'€Ë€è€ê32.1APŁŹ7-model ensemble€Ë€è€ê33.5AP
?SegmentaSon€ÏDeepMask (Proposal BBoxes) - Fast RCNN (Scored BBoxed) - DeepMask (Scored Segments)€Ë€è€êgĐĐ
?œ«ÀŽŐčÍû€È€·€Æ±łŸ°€È€Î»ìÍŹ€äιХîIÓò€ÎžßŸ«¶È»ŻŁŹ„ł„ó„Æ„„č„ȀλîÓĂŁŹfast/proposal-free€ÊÊłö€Ź€€Č€é€ì€ë
?MS COCO dataset€ÎÊłö€Ë€Æ”Ú2λ
?Fast R-CNN€Ź19.7%€ÎÊłöÂʀˀ·€Æ33.5%(Œs66%€ÎÏòÉÏ, MSRA€Ï37.3%)](https://image.slidesharecdn.com/ilsvrc2015-160112145021/85/ILSVRC2015-2-320.jpg)
![CUImage (Chinese Univ. of Hong Kong) "CUImage-poster.pdf", Cascaded
Networks for Object DetecSon with MulS-Context Modeling and Hierarchical
Fine-Tuning, in ILSVRC, 2015.
ĄŸ2Ąż
ÊÖ·š
Links
„Ę„č„ż©` hLp://image-net.org/challenges/posters/CUimage_poster.pdf
[1] X. Zeng, et al. Window-Object RelaSonship Guided RepresentaSon Learning for Generic Object DetecSons , axiv preprint.
[2] W. Ouyang, et al. Factors in Finetuning Deep Model for object detecSon, axiv preprint.
[3] J. Yan, et al. CRAFT Objects from Images, axiv preprint.
[4] W. Ouyang, et al. Deepid-net: Deformable deep convoluSonal neural networks for object detecSon. CVPR, 2015.
[5] J. Yan, et al. Object detecSon by labeling superpixels. CVPR, 2015.
œYčû
?MulS-context[1]: Ń}Êę€Î„Ń„Ă„Á„”„€„ș/Ń}Êę€Î„ł„ó„Æ„„č„È€òșŹ€à»Ïń€òÔu꣏ÌŰŐ€òßBœY€”€»€ÆSVM€Ë€è€ê„č„ł„ą„ê„ó„°
?Cascaded hierarchical feature learning[2]: „Ż„é„耎€È€Ëź€Ê€ëÓĐż€ÊÌŰŐ€òÔuę€č€ë€ż€á€ËëAӔĄ«„脱©`„ÉÌŰŐѧÁ€ògĐĐŁŹ
ëAӔĄŻ„é„č„ż„ê„ó„°€ŹÎïÌć€Î„°„ë©`„Ô„ó„°€ËßmÓĂ€”€ì€œ€ì€Ÿ€ì€Î„â„Ç„ë€ò?ne-tuning
?Cascade Region-Proposal-Network and Fast RCNN (CRAFT)[3]: RPN€ÎșòŃaîIÓò€òÔÙÔuę(IoU>0.7€òposi, IoU<0.3€ònega)€·€ÆșòŃaîIÓò
€ò€”€é€Ëœg€êȚz€ßŁŹCascadeŚReÆś€Ë€è€êŚRe
?ImageNet DetecSon€Ë€Ș€€€Æ52.7%, ImageNet DetecSon€Ë€Æ3λ (MSRA€Ï62.1%)
?CRAFT€Ë€è€êșòŃaîIÓò€ÎŸ«¶È€Ź94+%](https://image.slidesharecdn.com/ilsvrc2015-160112145021/85/ILSVRC2015-3-320.jpg)
![WM (Univ. of Chinese Academy of Sciences, Peking Univ.) Li Shen, Zhouchen
Lin, in ILSVRC, 2015.
ĄŸ3Ąż
ÊÖ·š
Links
„Ę„č„ż©` hLp://image-net.org/challenges/talks/WM_presentaSon.pdf
[1] K. He, X. Zhang, S. Ren and J. Sun. SpaSal pyramid pooling in deep
convoluSonal networks for visual recogniSon. In ECCV 2014.
œYčû
?VGG-like„ą©`„„Æ„Ż„Á„ă
?Model A€Ï22ӳɣŹŚîáá€ÎMax„Ś©`„ê„ó„°Ó€òSPPÓ[1]€ËÖĂ€Q€š
?Model B€ÏmulS-scale€ÎœyșÏŁŹ„”„ó„Ś„ë€Î·ÇÒ»·ÖČŒ€Ë€è€ë„Đ„é„ó„č„”„ó„Ś„ê„ó„°
?Relay Back-PropagaSon(ÓÒí)€Ë€è€ëčŽĆäÏûʧ€Î·ÀÖč
?Place2€Ë€ÆÙ, Classi?caSon error€Ź16.87%](https://image.slidesharecdn.com/ilsvrc2015-160112145021/85/ILSVRC2015-4-320.jpg)

![CUvideo Team, Kai Kang (Chinese Univ. of Hong Kong), Ą°Object DetecSon in
Videos with Tubelets and MulS-context CuesĄ±, in ILSVRC, 2015.
ĄŸ5Ąż
ÊÖ·š
Links
„Ę„č„ż©` hLp://image-net.org/challenges/talks/Object%20DetecSon%20in%20Videos%20with%20Tubelets%20and%20MulS-context%20Cues%20-%20Final.pdf
[1] Wang, Lijun et al. Visual Tracking with Fully ConvoluSonal Networks. ICCV 2015.
[2] J. Yan, et al. CRAFT Objects from Images, axiv preprint.
[3]W. Ouyang, et al. Deepid-net: Deformable deep convoluSonal neural networks for object detecSon. CVPR, 2015.
œYčû
?„Ó„Ç„Ș€Ë€è€ëÎïÌćÊłö
?łőÆڀȀ·€ÆŸČÖ軀ˀè€êÊłö
?(1) rÏ”ÁĐ€ÎșòŃaîIÓò(Temporal Tubelet Re-scoring)€Î„č„ł„ąËăłö
?ŸČÖ軀ˀè€ëÊłö€Ï„Ő„ì©`„àég€ÇČ»°Č¶š€Ê€ż€áŁŹîIÓò€ÎrÏ”ÁĐÔuę€òĐĐ€Š€Î€ŹTubelet
?ĐĆîm¶È€Îžß€€îIÓò€ÎŚ·ÛE[1]ŁŹżŐég”Ä€ÊMax-poolingŁŹrégĘS€Ç€Î„č„ł„ąÔÙÓËă
?żŐég”Ä€ÊMax-pooling€Ë€è€êŁŹŚîŽóîIÓò€Î€ß€òČĐ€č (Kalman ?lter€Ë€è€ëbboxÍƶš)
?(2) MulS-context suppression (MCS) & MoSon Guided PropagaSon (MGP)
?MCS€Ï€č€Ù€Æ€Îbbox€Î„č„ł„ą€ò„œ©`„ÈŁŹrÏ”ÁĐ€Ç„Ï„€„č„ł„ą€Î„Ż„é„耏仯€·€Ê€€€â€Î€ÏÊłöœYčû€È€·€ÆČĐ€č
?MGP€ÏÊłöœYčû€ò€è€êrég”Ä€Ëáá€Î„Ő„ì©`„à€Ë»Č„€”€»ŁŹÇ°€ËÊłö€”€ì€ż€â€Î€òáá€Î„Ő„ì©`„à€Ç€âÌœËśŁŹNMS€·€ä€č€€
?(1), (2)€Î„â„Ç„ëœyșÏ
?șòŃaîIÓò€ÏCRAFT[2]
?ŚRe€ÏDeepID-Net[3]
?ILSVRC2015 VID€Ë€Æ67.8%€ÎÊłöÂÊ](https://image.slidesharecdn.com/ilsvrc2015-160112145021/85/ILSVRC2015-6-320.jpg)


ILSVRC2015 ÊÖ·š€Î„á„â
- 1. 160112 DLĂă»á ÆŹù ÔŁĐÛ, Ph.D. źbIŒŒĐgŸtșÏŃĐŸżËù ÖȘÄÜ„·„č„Æ„àŃĐŸżČżéT „ł„ó„Ô„ć©`„ż„Ó„ž„ç„óŃĐŸż„°„ë©`„Ś http://www.hirokatsukataoka.net/