Image-to-Image Translation pix2pix
?Download as PPTX, PDF?
0 likes?1,698 views

This document discusses image-to-image translation using conditional adversarial networks. It introduces the problem of mapping pixels to pixels across different image representations. Generative adversarial networks are presented as a solution, using a generator network to synthesize images and a discriminator network to identify fakes. The document describes a U-Net architecture for the generator and a PatchGAN discriminator. It then shows experiments on tasks like semantic labeling, colorization, and discusses evaluation methods and failure cases.

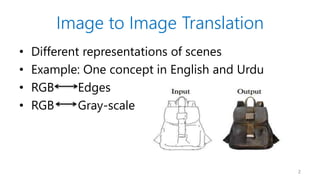















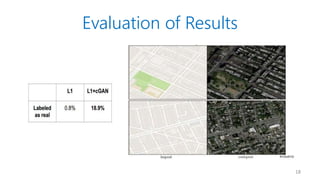
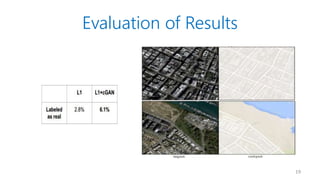
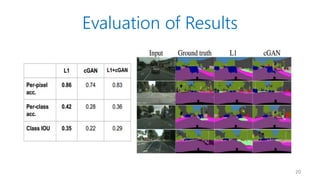


Image-to-Image Translation pix2pix
- 1. Image to Image Translation with Conditional Adversarial Networks Presented by: Shahbaz Ali Khan
- 2. Image to Image Translation ? Different representations of scenes ? Example: One concept in English and Urdu ? RGB Edges ? RGB Gray-scale 2
- 3. Image to Image Translation ? Primary objective remains the same ¨C Map pixels to pixels ? Why use different approaches? ? Why not a general purpose solution? ? Problem: Hand-crafted loss functions ¨C Telling the network what we want to minimize 3
- 4. Discriminative vs. Generative ? Discriminative: identify objects i.e. determine class scores ? Generative: capture the underlying distribution and produce samples from that distribution 4
- 5. Generative Adversarial Networks ? The solution to this problem is provided by GANs ? GANs learn a loss function ? Two neural networks (example Art forgery) ¨C Generator (G): synthesizes images ¨C Discriminator (D): identifies fakes ? A zero sum game is played to reach equilibrium 5
- 6. GANs vs. Conditional GANs 6
- 8. U-Net Architecture ? Underlying structure doesn¡¯t change during translation ? Allow low level info to shuttle across the network ? Motivated by use of L1 loss 8
- 10. Experiments Architecture labels Semantic labels to street to photo scene 10
- 11. Experiments Map to aerial photo BW to color 11
- 12. Experiments 12
- 13. Experiments 13
- 15. Evaluation of Results ? Amazon Mechanical Turk ¨C Is this image real or fake? ? FCN score ¨C Object recognition by off-the-shelf recognition systems 15
- 21. Conclusion ? Investigation of Conditional GANs as a general purpose solution for image to image translation tasks. ? Presentation of effective architecture for Generator and Discriminator. ? Lesser accuracy for tasks like semantic segmentation ? Failure cases: (highly) sparse inputs 21
- 22. Thank You! 22
Editor's Notes
- Give example of the L2 loss function here that leads to blurry result from page 2 para 2
- No need to specify loss functions See what is zero sum game