Introduction to Linked Data - WWW2010
3 likes1,003 views

These are the Introduction to Linked Data slides that we presented at the Consuming Linked Data tutorial at WWW2010 in Raleigh, NC on April 26, 2010











































































More Related Content
Viewers also liked (17)
Similar to Introduction to Linked Data - WWW2010 (6)

Recently uploaded (20)




















Introduction to Linked Data - WWW2010
- 1. Introduc)on ?to ?Linked ?Data ? Consuming ?Linked ?Data ?Tutorial ? World ?Wide ?Web ?Conference ?2010 ?
- 2. Do ?you ?SEARCH ?or ?do ?you ?FIND? ?
- 3. Search ?for ? Football ?Players ?who ?went ?to ?the ? University ?of ?Texas ?at ?Aus)n, ?played ?for ? the ?Dallas ?Cowboys ?as ?Cornerback ?
- 7. Why ?canˇŻt ?we ?just ?FIND ?itˇ ?
- 10. Guess ?how ?I ?FOUND ?out? ?
- 11. IˇŻll ?tell ?you ?how ?I ?did ?NOT ??nd ?it ?
- 12. Current ?Web ?= ?internet ?+ ?links ?+ ?docs ?
- 13. So ?what ?is ?the ?problem? ? ?? The ?Web ?has ?problems ? ¨C? People ?arenˇŻt ?interested ?in ?documents ? ?? They ?are ?interested ?in ?things ? ?(that ?are ?in ?documents) ? ¨C? People ?can ?parse ?documents ?and ?extract ?meaning ? ?? Web ?pages ?are ?wriXen ?in ?HTML ? ?? HTML ?describes ?visualiza)on ?of ?informa)on ? ?? Computers ?canˇŻt! ?
- 14. What ?do ?we ?need ?to ?do? ? ?? We ?need ?to ?help ?machines ?to ?understand ?the ? web ?so ?machines ?can ?help ?us ?understand ? things ? ¨C? They ?can ?learn ?what ?we ?are ?interested ?in ? ¨C? They ?can ?help ?us ?beXer ??nd ?what ?we ?want ?
- 15. How ?can ?we ?do ?that? ? ?? Besides ?publishing ?documents ?on ?the ?web ? ¨C? which ?computers ?canˇŻt ?understand ?easily ? ?? LetˇŻs ?publish ?something ?that ?computers ?can ? understand ?
- 16. RAW ?DATA! ?
- 17. But ?waitˇ ?donˇŻt ?we ?do ?that ? already? ?
- 18. Current ?Data ?on ?the ?Web ? ?? Rela)onal ?Databases ? ?? APIs ? ?? XML ? ?? CSV ? ?? XLS ? ?? ˇ ? ?? CanˇŻt ?computers ?and ?applica)ons ?already ? consume ?that ?data ?on ?the ?web? ?
- 19. True! ?But ?it ?is ?all ?in ?di?erent ? formats ?and ?data ?models! ?
- 20. This ?makes ?it ?hard ?to ?integrate ? data ?
- 21. The ?data ?in ?di?erent ? ? data ?sources ?arenˇŻt ?linked ?
- 22. For ?example, ?how ?do ?I ?know ?that ?the ? Juan ?Sequeda ?in ?Facebook ?is ?the ? same ?as ?Juan ?Sequeda ?in ?TwiXer ?
- 23. Or ?if ?I ?create ?a ?mashup ?from ? di?erent ?services, ?I ?have ?to ?learn ? di?erent ?APIs ?and ?I ?get ?di?erent ? formats ?of ?data ?back ?
- 24. WouldnˇŻt ?it ?be ?great ?if ?we ?had ?a ? standard ?way ?of ?publishing ?data ?on ? the ?Web? ?
- 25. We ?have ?a ?standardized ?way ?of ? publishing ?documents ?on ?the ?web, ? right? ? HTML ?
- 26. Then ?why ?canˇŻt ?we ?have ?a ?standard ? way ?of ?publishing ?data ?on ?the ?Web? ?
- 27. Good ?ques)on! ?And ?the ?answer ? is ?YES. ?There ?is! ?
- 28. Resource ?Descrip)on ?Framework ? (RDF) ? ?? A ?data ?model ? ? ¨C? A ?way ?to ?model ?data ? ¨C? i.e. ?Rela)onal ?databases ?use ?rela)onal ?data ?model ? ?? RDF ?is ?a ?triple ?data ?model ? ?? Labeled ?Graph ? ?? Subject, ?Predicate, ?Object ? ?? <Juan> ?<was ?born ?in> ?<California> ? ?? <California> ?<is ?part ?of> ?<the ?USA> ? ?? <Juan> ?<likes> ?<the ?Seman)c ?Web> ?
- 29. RDF ?can ?be ?serialized ?in ?di?erent ?ways ? ?? RDF/XML ? ?? RDFa ?(RDF ?in ?HTML) ? ?? N3 ? ?? Turtle ? ?? JSON ?
- 30. So ?does ?that ?mean ?that ?I ?have ?to ? publish ?my ?data ?in ?RDF ?now? ?
- 31. You ?donˇŻt ?have ?toˇ ?but ?we ?would ? like ?you ?to ?? ?
- 32. An ?example ?
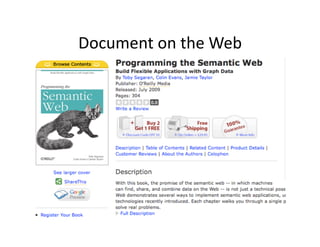
- 33. Document ?on ?the ?Web ?
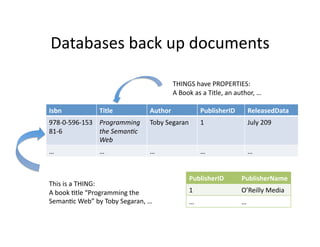
- 34. Databases ?back ?up ?documents ? THINGS ?have ?PROPERTIES: ? A ?Book ?as ?a ?Title, ?an ?author, ?ˇ ? Isbn ? Title ? Author ? PublisherID ? ReleasedData ? 978-?©\0-?©\596-?©\153 Programming ? Toby ?Segaran ? 1 ? July ?209 ? 81-?©\6 ? the ?Seman.c ? Web ? ˇ ? ˇ ? ˇ ? ˇ ? ˇ ? PublisherID ? PublisherName ? This ?is ?a ?THING: ? A ?book ?)tle ?ˇ°Programming ?the ? 1 ? OˇŻReilly ?Media ? Seman)c ?Webˇ± ?by ?Toby ?Segaran, ?ˇ ? ˇ ? ˇ ?
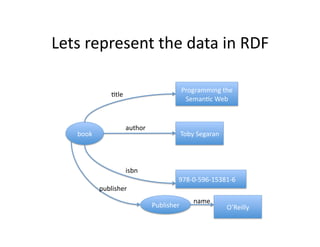
- 35. Lets ?represent ?the ?data ?in ?RDF ? Programming ?the ? )tle ? Seman)c ?Web ? author ? book ? Toby ?Segaran ? ? isbn ? 978-?©\0-?©\596-?©\15381-?©\6 ? publisher ? name ? Publisher ? OˇŻReilly ?
- 36. Remember ?that ?we ?are ?on ?the ? web ? Everything ?on ?the ?web ?is ?iden)?ed ?by ? a ?URI ?
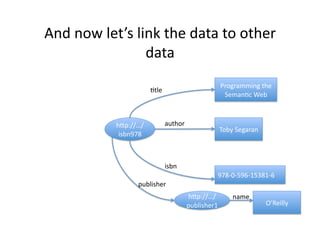
- 37. And ?now ?letˇŻs ?link ?the ?data ?to ?other ? data ? Programming ?the ? )tle ? Seman)c ?Web ? łółÝ±č://ˇ/ author ? Toby ?Segaran ? ? isbn978 ? isbn ? 978-?©\0-?©\596-?©\15381-?©\6 ? publisher ? łółÝ±č://ˇ/ name ? publisher1 ? OˇŻReilly ?
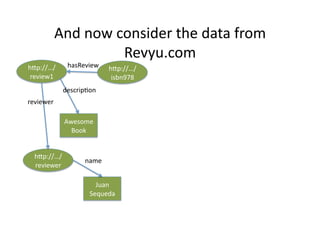
- 38. And ?now ?consider ?the ?data ?from ? Revyu.com ? łółÝ±č://ˇ/ hasReview ? łółÝ±č://ˇ/ review1 ? isbn978 ? descrip)on ? reviewer ? Awesome ? Book ? łółÝ±č://ˇ/ name ? reviewer ? Juan ? Sequeda ?
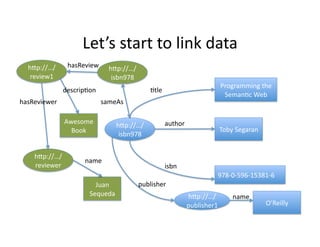
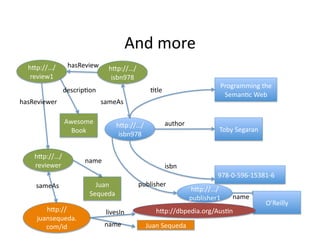
- 39. LetˇŻs ?start ?to ?link ?data ? łółÝ±č://ˇ/ hasReview ? łółÝ±č://ˇ/ review1 ? isbn978 ? Programming ?the ? descrip)on ? )tle ? Seman)c ?Web ? hasReviewer ? sameAs ? Awesome ? author ? łółÝ±č://ˇ/ Book ? Toby ?Segaran ? ? isbn978 ? łółÝ±č://ˇ/ name ? reviewer ? isbn ? 978-?©\0-?©\596-?©\15381-?©\6 ? Juan ? publisher ? Sequeda ? łółÝ±č://ˇ/ name ? publisher1 ? OˇŻReilly ?
- 40. Juan ?Sequeda ?publishes ?data ?too ? hXp:// livesIn ? hXp://dbpedia.org/Aus)n ? juansequeda. com/id ? name ? Juan ?Sequeda ?
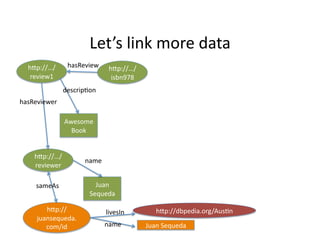
- 41. LetˇŻs ?link ?more ?data ? łółÝ±č://ˇ/ hasReview ? łółÝ±č://ˇ/ review1 ? isbn978 ? descrip)on ? hasReviewer ? Awesome ? Book ? łółÝ±č://ˇ/ name ? reviewer ? sameAs ? Juan ? Sequeda ? hXp:// livesIn ? hXp://dbpedia.org/Aus)n ? juansequeda. com/id ? name ? Juan ?Sequeda ?
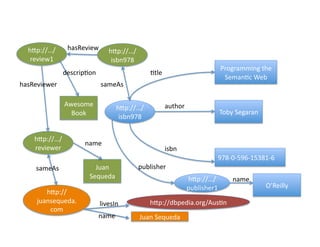
- 42. And ?more ? łółÝ±č://ˇ/ hasReview ? łółÝ±č://ˇ/ review1 ? isbn978 ? Programming ?the ? descrip)on ? )tle ? Seman)c ?Web ? hasReviewer ? sameAs ? Awesome ? author ? łółÝ±č://ˇ/ Book ? Toby ?Segaran ? ? isbn978 ? łółÝ±č://ˇ/ name ? reviewer ? isbn ? 978-?©\0-?©\596-?©\15381-?©\6 ? sameAs ? Juan ? publisher ? łółÝ±č://ˇ/ Sequeda ? name ? publisher1 ? OˇŻReilly ? hXp:// livesIn ? hXp://dbpedia.org/Aus)n ? juansequeda. com/id ? name ? Juan ?Sequeda ?
- 43. Data ?on ?the ?Web ?that ?is ?in ?RDF ?and ? is ?linked ?to ?other ?RDF ?data ?is ?LINKED ? DATA ?
- 44. Linked ?Data ?Principles ? 1.? Use ?URIs ?as ?names ?for ? things ? 2.? Use ?HTTP ?URIs ?so ?that ? people ?can ?look ?up ? (dereference) ?those ? names. ? 3.? When ?someone ?looks ?up ? a ?URI, ?provide ?useful ? informa)on. ? 4.? Include ?links ?to ?other ? URIs ?so ?that ?they ?can ? discover ?more ?things. ?
- 45. Linked ?Data ?makes ?the ?web ?appear ?as ? ? ONE ? ? GIANT ? HUGE ? ? GLOBAL ? ? DATABASE! ?
- 46. I ?can ?query ?a ?database ?with ?SQL. ?Is ? there ?a ?way ?to ?query ?Linked ?Data ? with ?a ?query ?language? ?
- 47. Yes! ?There ?is ?actually ?a ? standardize ?language ?for ?that ? SPARQL ?
- 48. FIND ?all ?the ?reviews ?on ?the ?book ? ˇ°Programming ?the ?Seman)c ?Webˇ± ? by ?people ?who ?live ?in ?Aus)n ?
- 49. łółÝ±č://ˇ/ hasReview ? łółÝ±č://ˇ/ review1 ? isbn978 ? Programming ?the ? descrip)on ? )tle ? Seman)c ?Web ? hasReviewer ? sameAs ? Awesome ? author ? łółÝ±č://ˇ/ Book ? Toby ?Segaran ? ? isbn978 ? łółÝ±č://ˇ/ name ? reviewer ? isbn ? 978-?©\0-?©\596-?©\15381-?©\6 ? sameAs ? Juan ? publisher ? Sequeda ? łółÝ±č://ˇ/ name ? publisher1 ? OˇŻReilly ? hXp:// juansequeda. livesIn ? hXp://dbpedia.org/Aus)n ? com ? name ? Juan ?Sequeda ?
- 50. This ?looks ?cool, ?but ?letˇŻs ?be ?realis)c. ? What ?is ?the ?incen)ve ?to ?publish ? Linked ?Data? ?
- 51. What ?was ?your ?incen)ve ?to ? publish ?an ?HTML ?page ?in ?1990? ?
- 52. 1) ?Share ?data ?in ?documents ? 2) ?Because ?you ?neighbor ?was ?doing ?it ?
- 53. So ?why ?should ?we ?publish ? ? Linked ?Data ?in ?2010? ?
- 54. 1) ?Share ?data ?as ?data ? 2) ?Because ?you ?neighbor ?is ?doing ?it ?
- 55. And ?guess ?who ?is ?star)ng ?to ? publish ?Linked ?Data ?now? ?
- 56. Linked ?Data ?Publishers ? ?? UK ?Government ? ?? US ?Government ? ?? BBC ? ?? Open ?Calais ?¨C ?Thomson ?Reuters ? ?? Freebase ? ?? NY ?Times ? ?? Best ?Buy ? ?? CNET ? ?? Dbpedia ? ?? Are ?you? ?
- 58. How ?can ?I ?publish ?Linked ?Data? ?
- 59. Publishing ?Linked ?Data ? ?? Legacy ?Data ?in ?Rela)onal ?Databases ? ¨C? D2R ?Server ? ¨C? Virtuoso ? ¨C? Triplify ? ¨C? Ultrawrap ? ?? CMS ? ¨C? Drupal ?7 ? ?? Na)ve ?RDF ?Stores ? ¨C? Databases ?for ?RDF ?(Triple ?Stores) ? ?? AllegroGraph, ?Jena, ?Sesame, ?Virtuoso ? ¨C? Talis ?Plauorm ?(Linked ?Data ?in ?the ?Cloud) ? ?? In ?HTML ?with ?RDFa ?
- 60. Ques)ons? ?