Introduction to Machine Learning: How to Create Text Classification
?
2 likes?524 views

The presentation about the relationship between Big Data, AI, and Machine Learning. How is the process? What are the methods used? Where are the implementations? And what's an example of mathematical calculations from the Machine Learning method?
































































































![Text Normalization: Regex
Ī░The development of
snowboarding was
inspired by
skateboarding,
sledding, surfing
and skiing.Ī▒
'The development of
snowboarding was inspired by
skateboarding sledding
surfing and skiing '
Ī░[^
w]Ī▒
+](https://image.slidesharecdn.com/introduction-to-machine-learning-191105082909/85/Introduction-to-Machine-Learning-How-to-Create-Text-Classification-108-320.jpg)













Introduction to Machine Learning: How to Create Text Classification
- 1. Introduction to Machine Learning: How to Create Text Classification Moch. Ari Nasichuddin (ML Engineer & Web/Core Programmer Netray.id) Yogyakarta, 2 November 2019 netray.id
- 2. Work Experiences Feb 2018 ©C Present ML ENGINEER & WEB/CORE PROGRAMMER PT Atmatech Global Informatika Jogjakarta, Indonesia Sept 2017 ©C Feb 2018 FULL STACK ENGINEER Wonderlabs.io Jogjakarta, Indonesia Apr 2015 ©C Aug 2017 FULL STACK WEB DEVELOPER Komuri Geek Garden Jogjakarta, Indonesia Education 2016 ©C 2018 MASTER OF INFORMATION TECHNOLOGY (M.ENG) Universitas Gadjah Mada Jogjakarta, Indonesia 2010 ©C 2015 BACHELOR OF INFORMATICS (S.KOM) Universitas Islam Indonesia Jogjakarta, Indonesia
- 3. Apa yang akan kita pelajari? Bagaimana konsep tentang Artificial Intelligence, Machine Learning, Big Data? 1 Apa saja pendekatan learning di dalam Machine Learning dan metode apa saja yang digunakan? 2 Bagaimana proses dalam membangun model Machine Learning? 3 Bagaimana contoh implementasi Machine Learning pada suatu sistem? 4 Bagaimana cara kerja Text Classification dalam Machine Learning? 5
- 4. Agenda Konsep Big Data, AI, dan Machine Learning Studi Kasus Demo
- 5. Konsep Big Data, AI, dan Machine Learning
- 10. Data Sources Source: Machine Learning for Dummies, IBM Limited Edition Structured Data Unstructured Data
- 11. Structured Data ? Sensor Data: Examples include radio frequency ID (RFID) tags, smart meters, medical devices, and Global Positioning System (GPS) data. ? Weblog data: When servers, applications, networks, and so on operate, they capture all kinds of data about their activity. ? Point-of-sale data: When the cashier swipes the bar code of any product that you purchase, all that data associated with the product is generated. ? Financial Data: Many financial systems are now programmatic; they operate based on predefined rules that automate processes. ? Weather data: Sensors to collect weather data are being deployed across towns, cities, and regions to collect data on things like temperature, wind, barometric pressure, and precipitation. ? Click-stream data: Data is generated every time you click a link on a website. This data can be analyzed to determine customer behavior and buying patterns. Source: Machine Learning for Dummies, IBM Limited Edition
- 12. Unstructured Data ? Document: Think of all of the text within documents, logs, survey results, and emails. Enterprise information actually represents a large percent of the text information in the world today. ? Social Media: This data is generated from the social media platforms, such as YouTube, Facebook, Twitter, LinkedIn, and Flickr. ? Mobile data: This includes text messages, notes, calendar inputs, pictures, videos, and data entered into third-party mobile applications. ? Satellite images: This includes weather data or the data that the government captures in its satellite surveillance imagery. ? Photographs and Video: This includes security, surveillance, and traffic data. ? Radar or sonar data: This includes vehicular, meteorological, and oceanographic data. Source: Machine Learning for Dummies, IBM Limited Edition
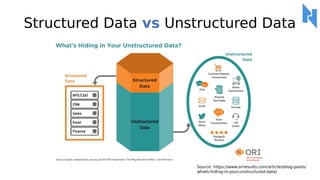
- 13. Structured Data vs Unstructured Data Source: https://www.oriresults.com/articles/blog-posts/ whats-hiding-in-your-unstructured-data/
- 14. Structured Data vs Unstructured Data Source: https://www.predactica.com/blog/2018/08/29/feature- engineering-the-secret-sauce-of-machine-learning-3/
- 21. Data ©C Information ©C Knowledge
- 22. PROBLEM?
- 23. PROBLEM: Mengapa mahasiswa yang aktif di lembaga mahasiswa UII cenderung sedikit?
- 25. Informasi ? Jenis kelamin paling banyak laki- laki ? Rata-rata domisilinya di Jalan Kaliurang ? Paling banyak dari FTI dan FTSP
- 26. Knowledge ? Mahasiswa yang berdomisili di sekitaran Jakal lebih banyak aktif di lembaga mahaswa ? Mahasiwa dari FTI dan FTSP paling banyak yang aktif di lembaga mahasiwa
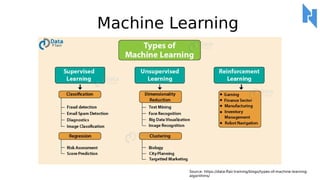
- 31. Machine Learning Source: https://data-flair.training/blogs/types-of-machine-learning- algorithms/
- 35. Application of AI & Machine Learning Source: http://www.mindmapsoft.com/mind-maps-artificial-intelligence-ai/ai-application/
- 36. Application of AI & Machine Learning Source: https://blog.quantinsti.com/machine-learning-basics/
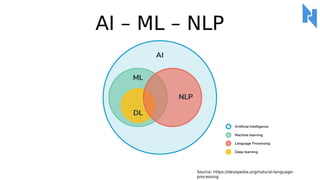
- 37. AI ©C ML ©C NLP Source: https://devopedia.org/natural-language- processing
- 38. STUDI KASUS
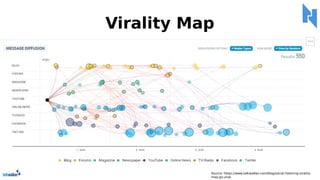
- 39. Media monitoring berbasis big data, deep learning, dan sentiment analysis yang dapat membantu mengetahui suatu hal yang tengah terjadi di media sosial (twitter dan instagram) dan media daring. netray.id
- 40. Monitoring TWITTER Netray memantau akun & kata kunci Twitter Menarik data dari Twitter Menyajikan dalam visualisasi interaktif dan realtime Menyajikan report dalam berbagai bentuk
- 41. Monitoring INSTAGRAM Netray memantau akun & kata kunci Instagram Menarik data dari Instagram Menyajikan dalam visualisasi interaktif dan realtime Menyajikan report dalam berbagai bentuk
- 42. Monitoring ONLINE MEDIA Netray memantau akun & kata kunci Online Media Menarik data dari Online Media Menyajikan dalam visualisasi interaktif dan realtime Menyajikan report dalam berbagai bentuk
- 44. ML Services ? Sentiment Analysis ? Named-entity recognition ? Category Classification ? Topic Modeling ? Sex Classification by Name
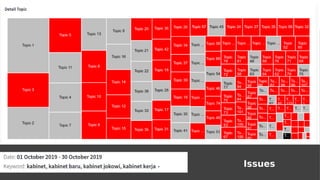
- 48. Topic Modeling
- 49. Sex Classification by Name
- 51. Kabinet Jokowi-Maruf Keyword & Filter Tanggal
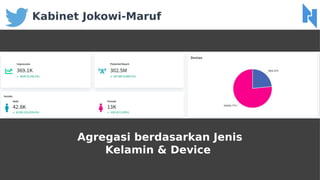
- 52. Kabinet Jokowi-Maruf Agregasi berdasarkan Jenis Kelamin & Device
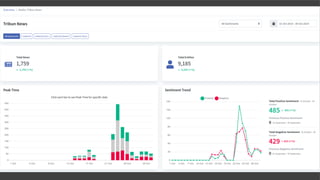
- 53. Kabinet Jokowi-Maruf Peaktime Data dan Sentimen
- 56. Detail Peaktime Data dan Sentimen 23 Okt Kabinet Jokowi-Maruf
- 57. Kabinet Jokowi-Maruf Top Word dan Top Inisiator
- 58. Kabinet Jokowi-Maruf Top Location dan Popular Media
- 68. Kabinet Jokowi-Maruf Keyword & Filter Tanggal
- 69. Kabinet Jokowi-Maruf Total News, Total Media, Total Entities, Top Categories
- 70. Kabinet Jokowi-Maruf Word Cloud dan Latest News
- 73. Kabinet Jokowi-Maruf Detail Entity: Prabowo
- 75. Kabinet Jokowi-Maruf Top Portal dan Top Location
- 84. Quiz Training Data Label aku seneng banget sama olahraga Positive olahraga bikin kita tambah sehat Positive kakiku terkilir ketika olahraga Negative bidang olahraga kita minim prestasi Negative kevin pergi olahraga Neutral Apa sentimen dari kalimat berikut: Ī░Faldo orangnya sehat dan punya prestasi di bidang olahragaĪ▒
- 85. Machine Learning Methods Supervised Learning Unsupervised Learning Classification Support Vector Machines Naive Bayes Neural Networks Regression Linier Regression Logistic Regression Polynomial Regression Classification Support Vector Machines Naive Bayes Neural Networks Clustering K-Means DBSCAN Density-based Clustering
- 86. ML Method: Naive Bayes Source: https://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
- 87. ML Method: SVM Source: https://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
- 88. Machine Learning Process Source: Machine Learning for Dummies, IBM Limited Edition Identify the data Prepare data Select the ML algorithm Split data TrainEvaluatePredictDeploy
- 90. Text Classification Type ? Binary classification: The total number of distinct classes or categories is two in number and any prediction can contain either one of those classes. ? Multi-class classification: The total number of classes is more than two, and each prediction gives one class or category that can belong to any of those classes. ? Multi-label classification: The problem where each prediction can yield more than one outcome/predicted class for any data point. Source: Text Analytics with Python a Practical R
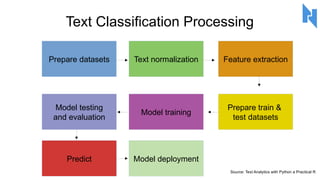
- 91. Text Classification Processing Source: Text Analytics with Python a Practical R Prepare datasets Text normalization Feature extraction Prepare train & test datasets Model training Model testing and evaluation Predict Model deployment
- 92. Machine Learning Evaluation ? Classification Accuracy ? Confusion Matrix ? F-Measure
- 93. ML Evaluation: Classification Accuracy ? Rasio/jumlah data prediksi benar dari total input data prediksi Data Label Data Predict A A B B A A B A A B Result 3/5 = 0.6 (60%) Source: https://towardsdatascience.com/metrics-to-evaluate-your-machine- learning-algorithm-f10ba6e38234
- 94. ML Evaluation: Confusion Matrix (Binary Class) ? Sebuah matrik berisi kumpulan hasil prediksi Source: https://towardsdatascience.com/metrics-to-evaluate-your-machine- learning-algorithm-f10ba6e38234
- 95. ML Evaluation: Confusion Matrix (Multi-class) Source: https://docs.wso2.com/display/ML110/Model+Evaluation+Measures
- 96. ML Evaluation: F-Measure ? Precission: Rasio TP dibandingkan dengan keseluruhan hasil yang diprediksi positif ? Recall: Rasio TP dibandingkan dengan keseluruhan data TP ? Specificity: Rasio TN dibandingan keseluruhan data negatif ? F1 Score: Perbandingan rata-rata Precission dan Recall
- 98. Underfitting ? Data training terlalu sedikit ? Model tidak dapat memperoleh nilai loss yang rendah saat training ? Proses training berhenti terlalu cepat Source: https://machinelearningmastery.com/learning-curves- for-diagnosing-machine-learning-model-performance/
- 99. Overfitting ? Model terlalu komplek untuk menangani suatu kasus ? Model ditraining terlalu lama Source: https://machinelearningmastery.com/learning-curves- for-diagnosing-machine-learning-model-performance/
- 100. Good Fit ? Nilai loss ketika training rendah ? Ketika gap antara train dan validation sesuai atau tidak terlalu besar Source: https://machinelearningmastery.com/learning-curves- for-diagnosing-machine-learning-model-performance/
- 101. How to Prevent Overfitting & Underfitting ? Cross-validation ? Train with more data ? Early stopping
- 102. Cross-validation & Early Stopping Example Cross- validation Early Stopping
- 103. Text Normalization: Sentence Tokenization Ī░Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.Ī▒ Source: https://towardsdatascience.com/introduction-to-natural-language-processing-for-text-df845750fb63
- 104. Text Normalization: Word Tokenization Source: https://towardsdatascience.com/introduction-to-natural-language-processing-for-text-df845750fb63
- 105. Text Normalization: Stopwords Source: https://towardsdatascience.com/introduction-to-natural-language-processing-for-text-df845750fb63
- 106. Text Normalization: Stopwords Ī░Backgammon is one of the oldest known board games.Ī▒ Source: https://towardsdatascience.com/introduction-to-natural-language-processing-for-text-df845750fb63
- 107. Stemming vs Lemmatization Stemming Lemmatization Proses mengubah sebuah kata menjadi kata dasar. Proses mengubah sebuah kata menjadi kata dasar sesuai kamusnya. Waktu pemrosesannya cenderung cepat Waktu pemrosesannya cenderung lambat Dipergunakan ketika kata yang dihasilkan tidak penting untuk analisis Dipergunakan ketika kata yang dihasilkan penting untuk analisis
- 108. Text Normalization: Regex Ī░The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing.Ī▒ 'The development of snowboarding was inspired by skateboarding sledding surfing and skiing ' Ī░[^ w]Ī▒ +
- 109. Naive Bayes for Text Classification Training Data Label Ronaldo menggiring bola Sports Bola keluar dari lapangan Sports Kendaraan itu sering macet Transportation Harga kendaraan mobil mahal Transportation BCL mengadakan konser di Jakarta Entertainment
- 110. Feature Extraction ? 1. One Hot Encoding ? 2. Word Embedding ? 3. Bag of Word
- 111. One Hot Encoding
- 113. Naive Bayes for Text Classification Sports Bow Transportation Bow Entertainment Bow Words Count Words Count Words Count ronaldo 1 kendaraan 2 bcl 1 menggiring 1 itu 1 mengadakan 1 bola 2 sering 1 konser 1 keluar 1 harga 1 di 1 dari 1 mobil 1 jakarta 1 lapangan 1 mahal 1 Vocabulary: 6 Total Count : 7 Vocabulary: 6 Total Count : 7 Vocabulary: 5 Total Count : 5 Total Unique Words 17 Prediksi: Ī░Kendaraan dia bikin macetĪ▒
- 114. Naive Bayes for Text Classification Sentence: kendaraan dia bikin macetSports: P(kendaraan | sports) = 0/7 = 0 P(dia | sports) = 0/7 = 0 P(bikin | sports) = 0/7 = 0 P(macet | sports) = 0/7 = 0 Transportation: P(kendaraan | transportation) = 2/7 = 0.2857 P(dia | transportation) = 0/7 = 0 P(bikin | transportation) = 0/7 = 0 P(macet | transportation) = 0/7 = 0 Entertainment: P(kendaraan | entertainment) = 0/5 = 0 P(dia | entertainment) = 0/5 = 0 P(bikin | entertainment) = 0/5 = 0 P(macet | entertainment) = 0/5 = 0 Jika kita lihat, banyak perhitungan yang hasil akhirnya 0. Hasil tersebut nantinya memberikan informasi sama sekali. Untuk itu kita mesti menerapkan Laplace Smoothing. Kita akan menambah angka 1 pada setiap jumlah kata. Dan untuk mengimbanginya, kita juga menambahkan Total Unique Words pada bagian pembagi.
- 115. Naive Bayes for Text Classification Sentence: kendaraan dia bikin macetSports: P(kendaraan | sports) = (0+1)/(7+17) = 0.0416 P(dia | sports) = (0+1)/(7+17) = 0.0416 P(bikin | sports) = (0+1)/(7+17) = 0.0416 P(macet | sports) = (0+1)/(7+17) = 0.0416 Transportation: P(kendaraan | transportation) = (2+1)/(7+17) = 0.125 P(dia | transportation) = (0+1)/(7+17) = 0.0416 P(bikin | transportation) = (0+1)/(7+17) = 0.0416 P(macet | transportation) = (0+1)/(7+17) = 0.0416 Entertainment: P(kendaraan | entertainment) = (0+1)/(5+17) = 0,0454 P(dia | entertainment) = (0+1)/(5+17) = 0,0454 P(bikin | entertainment) = (0+1)/(5+17) = 0,0454 P(macet | entertainment) = (0+1)/(5+17) = 0,0454
- 116. Naive Bayes for Text Classification Sentence: kendaraan dia bikin macet P(kendaraan dia bikin macet | sports) = 0.0416 x 0.0416 x 0.0416 x 0.0416 = 0.000002995 P(kendaraan dia bikin macet | transportation) = 0.125 x 0.0416 x 0.0416 x 0.0416 = 0.000008999 P(kendaraan dia bikin macet | entertainment) = 0.0416 x 0.0416 x 0.0416 x 0.0416 = 0.000002995 Dari ketiga hasil di atas, maka kalimat Ī░Kendaraan dia bikin macetĪ▒ mempunyai kategori Ī░Transportation"
- 117. Splitting Datasets ? Training Dataset: Sampel data yang digunakan untuk training ? Validation Dataset: Sampel data yang digunakan untuk mengevaluasi model dari hasil training ? Test Dataset: Sampel data yang digunakan untuk menguji model dari hasil training Source: https://towardsdatascience.com/train-validation-and- test-sets-72cb40cba9e7
- 118. Splitting Datasets (Small Dataset) Data Training (80%) Test (20%) Model Accuracy
- 119. Splitting Datasets (Large Dataset) Data Training (80%) Test (20%) Training (60%) Validation (20%) Test (20%) Model Accuracy
- 120. WeĪ»re Hiring (Front-End) ? Menguasai HTML, CSS, Responsive website, LESS, dan SASS ? Menguasai HTML5 dan CSS3 adalah nilai lebih ? Berpengalaman menggunakan JavaScript, CSS, jQuery, Vue.JS, dan Bootstrap ? Bersedia bekerja penuh waktu dan penempatan di Yogyakarta ? Fresh graduate are welcome