搁顿叠でのツリー表现入门2024
?
0 likes?39 views

RDBでツリー構造を表現するための典型的なモデルについて学ぼう! cf. 2020年版(in Opt Technologies): /slideshow/introduction-to-tree-representations-in-rdb/237861471































搁顿叠でのツリー表现入门2024
- 2. のプロダクトエンジニア 主要技術スタック: / + PostgreSQL 関数型言語/関数型プログラミングが好き 仕事や趣味で , , などに長く 触れてきた RDB/SQLが好き プログラミングを始めて最初に好きになった言語 がSQLだった lagénorhynque?カマイルカ 株式会社スマートラウンド Kotlin Ktor Clojure Scala Haskell 2
- 3. 0. 事前準備 1. 隣接リスト(adjacency list) 2. 経路列挙(path enumeration) 3. 入れ子集合(nested sets) 4. 閉包テーブル(closure table) 3
- 4. 0. 事前準備 4
- 5. サンプルコード ローカルDB: MySQL 8.4 lagenorhynque/tree-representations-in-rdb # 実験環境の準備 docker compose up -d make migrate compose.yaml 5
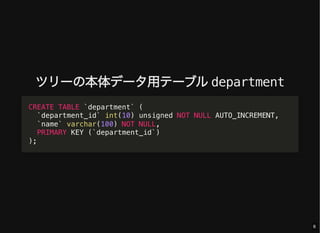
- 6. ツリーの本体データ用テーブル department CREATE TABLE `department` ( `department_id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(100) NOT NULL, PRIMARY KEY (`department_id`) ); 6
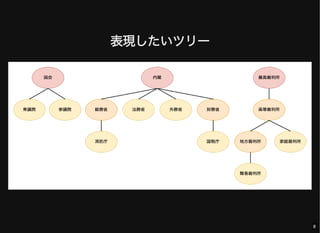
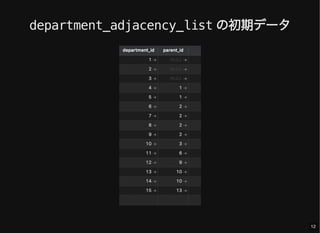
- 8. 表現したいツリー 8
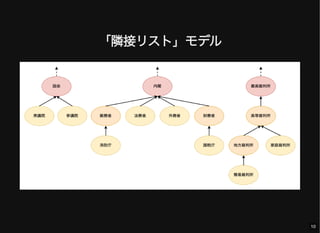
- 10. 「隣接リスト」モデル 10
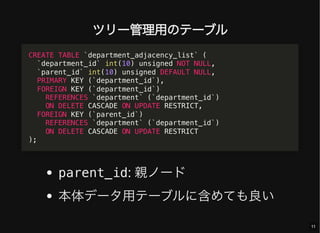
- 11. ツリー管理用のテーブル parent_id: 親ノード 本体データ用テーブルに含めても良い CREATE TABLE `department_adjacency_list` ( `department_id` int(10) unsigned NOT NULL, `parent_id` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`department_id`), FOREIGN KEY (`department_id`) REFERENCES `department` (`department_id`) ON DELETE CASCADE ON UPDATE RESTRICT, FOREIGN KEY (`parent_id`) REFERENCES `department` (`department_id`) ON DELETE CASCADE ON UPDATE RESTRICT ); 11
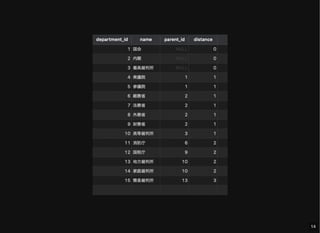
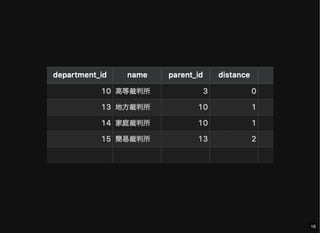
- 13. すべてのノードとその階層情報の取得 distance: ルートノードからの距離 cf. WITH RECURSIVE department_tree AS ( SELECT d.*, dal.parent_id, 0 distance FROM department d JOIN department_adjacency_list dal USING (department_id) WHERE dal.parent_id IS NULL UNION ALL SELECT d.*, dal.parent_id, dt.distance + 1 FROM department d JOIN department_adjacency_list dal USING (department_id) JOIN department_tree dt ON dal.parent_id = dt.department_id ) SELECT * FROM department_tree; MySQL :: MySQL 8.4 Reference Manual :: 15.2.20 WITH (Common Table Expressions) 13
- 14. 14
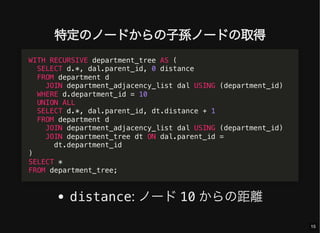
- 15. 特定のノードからの子孫ノードの取得 distance: ノード 10 からの距離 WITH RECURSIVE department_tree AS ( SELECT d.*, dal.parent_id, 0 distance FROM department d JOIN department_adjacency_list dal USING (department_id) WHERE d.department_id = 10 UNION ALL SELECT d.*, dal.parent_id, dt.distance + 1 FROM department d JOIN department_adjacency_list dal USING (department_id) JOIN department_tree dt ON dal.parent_id = dt.department_id ) SELECT * FROM department_tree; 15
- 16. 16
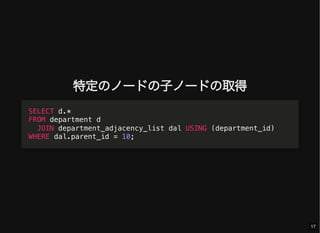
- 17. 特定のノードの子ノードの取得 SELECT d.* FROM department d JOIN department_adjacency_list dal USING (department_id) WHERE dal.parent_id = 10; 17
- 18. 18
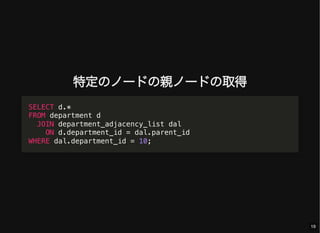
- 19. 特定のノードの親ノードの取得 SELECT d.* FROM department d JOIN department_adjacency_list dal ON d.department_id = dal.parent_id WHERE dal.department_id = 10; 19
- 20. 20
- 22. CONS 再帰CTE (recursive common table expressions)が 使えないと任意階層に対するクエリが困難 削除操作が煩雑 parent_id で NULL が現れてしまう ルートノード管理用のテーブルを用意することで 回避可能 22
- 23. 2. 経路列挙(path enumeration) a.k.a. 経路実体化(materialized path) 23
- 24. 「経路列挙」モデル 24
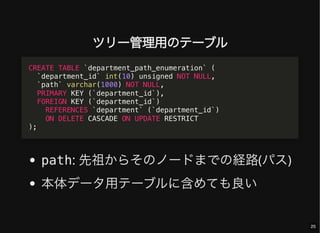
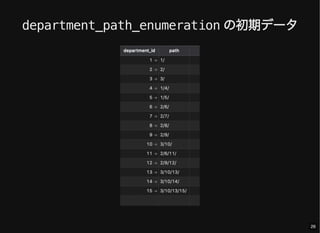
- 25. ツリー管理用のテーブル path: 先祖からそのノードまでの経路(パス) 本体データ用テーブルに含めても良い CREATE TABLE `department_path_enumeration` ( `department_id` int(10) unsigned NOT NULL, `path` varchar(1000) NOT NULL, PRIMARY KEY (`department_id`), FOREIGN KEY (`department_id`) REFERENCES `department` (`department_id`) ON DELETE CASCADE ON UPDATE RESTRICT ); 25
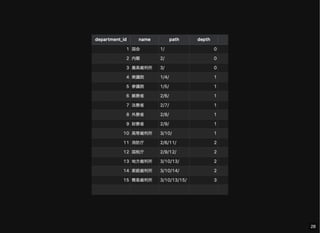
- 27. すべてのノードとその階層情報の取得 depth: ルートノードからの距離 SELECT d.*, dpe.path, CHAR_LENGTH(dpe.path) - CHAR_LENGTH(REPLACE(dpe.path, '/', '')) - 1 depth FROM department d JOIN department_path_enumeration dpe USING (department_id); 27
- 28. 28
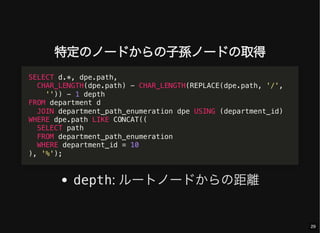
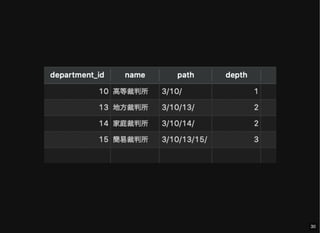
- 29. 特定のノードからの子孫ノードの取得 depth: ルートノードからの距離 SELECT d.*, dpe.path, CHAR_LENGTH(dpe.path) - CHAR_LENGTH(REPLACE(dpe.path, '/', '')) - 1 depth FROM department d JOIN department_path_enumeration dpe USING (department_id) WHERE dpe.path LIKE CONCAT(( SELECT path FROM department_path_enumeration WHERE department_id = 10 ), '%'); 29
- 30. 30
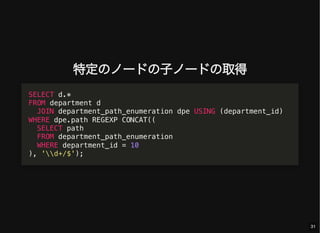
- 31. 特定のノードの子ノードの取得 SELECT d.* FROM department d JOIN department_path_enumeration dpe USING (department_id) WHERE dpe.path REGEXP CONCAT(( SELECT path FROM department_path_enumeration WHERE department_id = 10 ), 'd+/$'); 31
- 32. 32
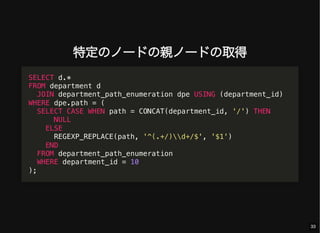
- 33. 特定のノードの親ノードの取得 SELECT d.* FROM department d JOIN department_path_enumeration dpe USING (department_id) WHERE dpe.path = ( SELECT CASE WHEN path = CONCAT(department_id, '/') THEN NULL ELSE REGEXP_REPLACE(path, '^(.+/)d+/$', '$1') END FROM department_path_enumeration WHERE department_id = 10 ); 33
- 34. 34
- 37. 3. 入れ子集合(nested sets) cf. 入れ子区間(nested intervals) 37
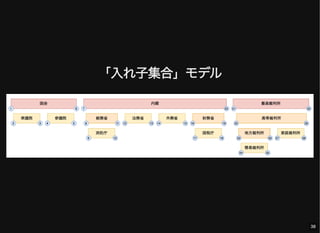
- 38. 「入れ子集合」モデル 38
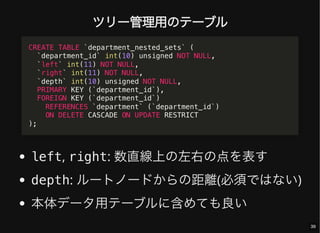
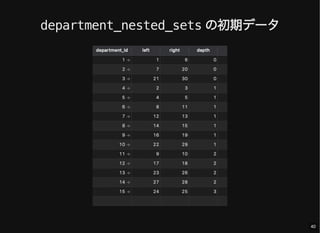
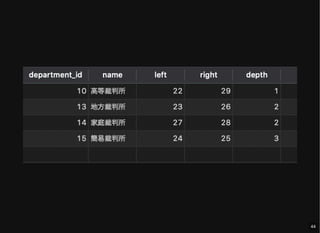
- 39. ツリー管理用のテーブル left, right: 数直線上の左右の点を表す depth: ルートノードからの距離(必須ではない) 本体データ用テーブルに含めても良い CREATE TABLE `department_nested_sets` ( `department_id` int(10) unsigned NOT NULL, `left` int(11) NOT NULL, `right` int(11) NOT NULL, `depth` int(10) unsigned NOT NULL, PRIMARY KEY (`department_id`), FOREIGN KEY (`department_id`) REFERENCES `department` (`department_id`) ON DELETE CASCADE ON UPDATE RESTRICT ); 39
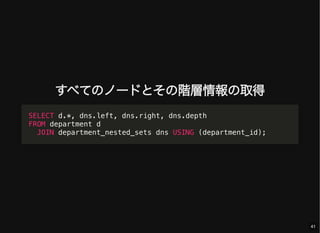
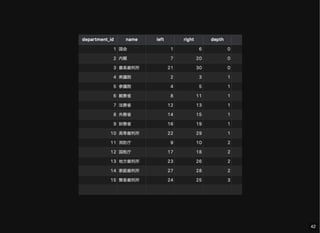
- 41. すべてのノードとその階層情報の取得 SELECT d.*, dns.left, dns.right, dns.depth FROM department d JOIN department_nested_sets dns USING (department_id); 41
- 42. 42
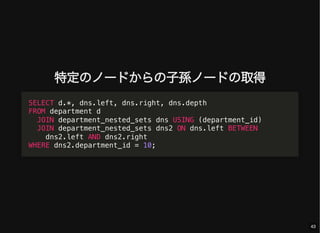
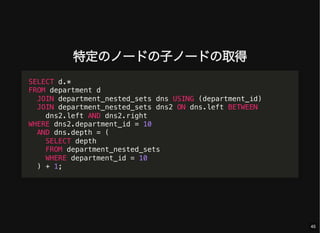
- 43. 特定のノードからの子孫ノードの取得 SELECT d.*, dns.left, dns.right, dns.depth FROM department d JOIN department_nested_sets dns USING (department_id) JOIN department_nested_sets dns2 ON dns.left BETWEEN dns2.left AND dns2.right WHERE dns2.department_id = 10; 43
- 44. 44
- 45. 特定のノードの子ノードの取得 SELECT d.* FROM department d JOIN department_nested_sets dns USING (department_id) JOIN department_nested_sets dns2 ON dns.left BETWEEN dns2.left AND dns2.right WHERE dns2.department_id = 10 AND dns.depth = ( SELECT depth FROM department_nested_sets WHERE department_id = 10 ) + 1; 45
- 46. 46
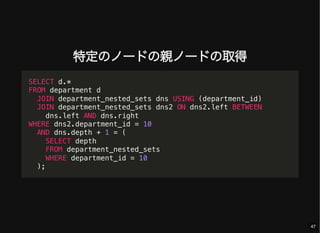
- 47. 特定のノードの親ノードの取得 SELECT d.* FROM department d JOIN department_nested_sets dns USING (department_id) JOIN department_nested_sets dns2 ON dns2.left BETWEEN dns.left AND dns.right WHERE dns2.department_id = 10 AND dns.depth + 1 = ( SELECT depth FROM department_nested_sets WHERE department_id = 10 ); 47
- 48. 48
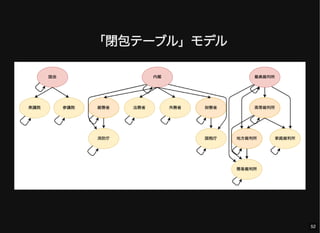
- 52. 「閉包テーブル」モデル 52
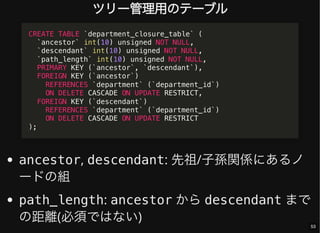
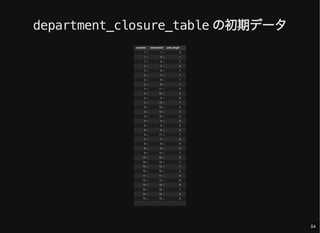
- 53. ツリー管理用のテーブル ancestor, descendant: 先祖/子孫関係にあるノ ードの組 path_length: ancestor から descendant まで の距離(必須ではない) CREATE TABLE `department_closure_table` ( `ancestor` int(10) unsigned NOT NULL, `descendant` int(10) unsigned NOT NULL, `path_length` int(10) unsigned NOT NULL, PRIMARY KEY (`ancestor`, `descendant`), FOREIGN KEY (`ancestor`) REFERENCES `department` (`department_id`) ON DELETE CASCADE ON UPDATE RESTRICT, FOREIGN KEY (`descendant`) REFERENCES `department` (`department_id`) ON DELETE CASCADE ON UPDATE RESTRICT ); 53
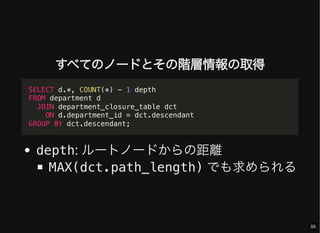
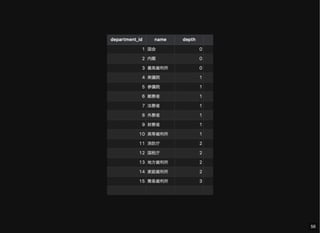
- 55. すべてのノードとその階層情報の取得 depth: ルートノードからの距離 MAX(dct.path_length) でも求められる SELECT d.*, COUNT(*) - 1 depth FROM department d JOIN department_closure_table dct ON d.department_id = dct.descendant GROUP BY dct.descendant; 55
- 56. 56
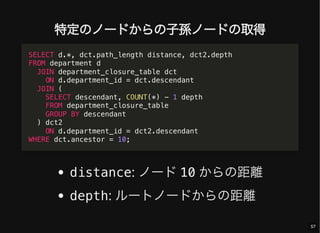
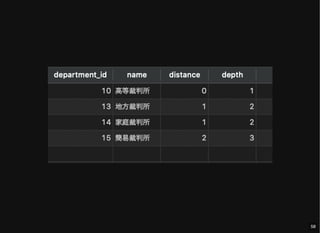
- 57. 特定のノードからの子孫ノードの取得 distance: ノード 10 からの距離 depth: ルートノードからの距離 SELECT d.*, dct.path_length distance, dct2.depth FROM department d JOIN department_closure_table dct ON d.department_id = dct.descendant JOIN ( SELECT descendant, COUNT(*) - 1 depth FROM department_closure_table GROUP BY descendant ) dct2 ON d.department_id = dct2.descendant WHERE dct.ancestor = 10; 57
- 58. 58
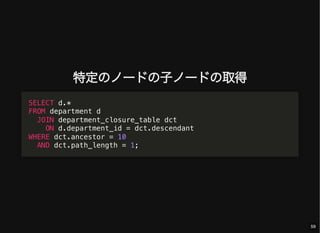
- 59. 特定のノードの子ノードの取得 SELECT d.* FROM department d JOIN department_closure_table dct ON d.department_id = dct.descendant WHERE dct.ancestor = 10 AND dct.path_length = 1; 59
- 60. 60
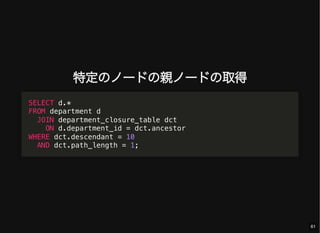
- 61. 特定のノードの親ノードの取得 SELECT d.* FROM department d JOIN department_closure_table dct ON d.department_id = dct.ancestor WHERE dct.descendant = 10 AND dct.path_length = 1; 61
- 62. 62
- 66. Further Reading 2章 ナイーブツリー(素朴な木) 第10章 グラフに立ち向かう 10.4 ツリー(木) 第10章 階層的なデータ構造 『SQLアンチパターン』 『理論から学ぶデータベース実践入門』 『Effective SQL』 66
- 67. 第9章 一歩進んだ論理設計 ~SQLで木構造を扱 う 『達人に学ぶDB設計 徹底指南書』 『プログラマのためのSQLグラフ原論』 What are the options for storing hierarchical data in a relational database? - Stack Overflow 67