










IV_WORKSHOP_NVIDIA-Audio_Processing
- 1. IV WORKSHOP NVIDIA DE GPU E CUDA Audio Processing using Convolutional Neural Network Diego Augusto September 6, 2016
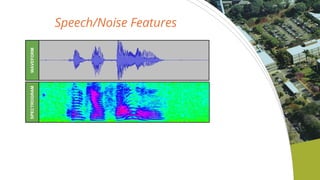
- 2. Speech Activity Detection (SAD) ? Distinguish speech and noise segments. ? Estimate start and end times of speech events. WAVEFORM
- 3. Speech Activity Detection (SAD) ? Distinguish speech and noise segments. ? Estimate start and end times of speech events. #1, START: 1.2 sec, END: 2.5 sec #2, START: 3.3 sec END: 4.9 sec WAVEFORM speech speech
- 4. Applications ? Segmentation of spontaneous speech: ? Live language translation. ? Speech transmission over audio codecˇŻs. ? Retrieval of speech in video and social networks.
- 5. Applications ? Segmentation of spontaneous speech: ? Live language translation. ? Speech transmission over audio codecˇŻs. ? Retrieval of speech in video and social networks. ? Pre processing of speech engines: ? Speech Recognition - ˇ°what is being said?ˇ± ? Speaker Authentication - ˇ°who is speaking?ˇ± ? Speaker Diarization - ˇ°who spoke when?ˇ±
- 6. Challenges ? Large variety of different types of noises: ? Clicking, Motor sound, Background voice. ? Voice distortion, overlapping sounds.
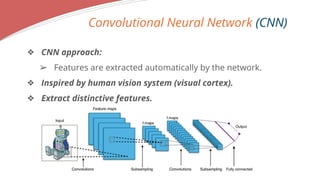
- 7. Convolutional Neural Network (CNN) ? CNN approach: ? Features are extracted automatically by the network. ? Inspired by human vision system (visual cortex). ? Extract distinctive features.
- 8. CPqD Dataset ? > 300 hours of speech and noise. ? with ground truth. ? Environments: ? Phone conversation. ? PCs and IoT devices (mobile apps). ? Split into two parts: ? Development = 75%. ? Evaluation = 25%.
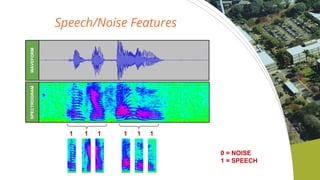
- 10. Speech/Noise Features SPECTROGRAMWAVEFORM 1 1 1 1 1 1 0 = NOISE 1 = SPEECH
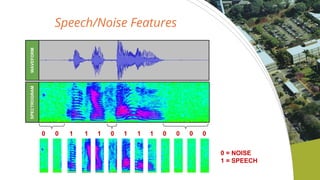
- 11. Speech/Noise Features SPECTROGRAMWAVEFORM 0 = NOISE 1 = SPEECH 0 0 1 0 0 0 0 01 1 1 1 1
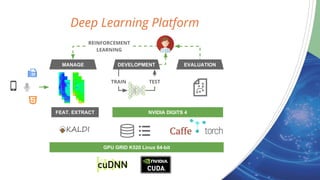
- 12. Deep Learning Platform MANAGE DEVELOPMENT EVALUATION NVIDIA DIGITS 4 GPU GRID K520 Linux 64-bit FEAT. EXTRACT TRAIN TEST REINFORCEMENT LEARNING
- 13. NVIDIA DIGITS Monitor Train Test Model 99,93 0,07 1 0
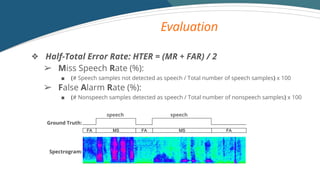
- 14. Evaluation FA MSMS FAFA Ground Truth: Spectrogram: ? Half-Total Error Rate: HTER = (MR + FAR) / 2 ? Miss Speech Rate (%): ˇö (# Speech samples not detected as speech / Total number of speech samples) x 100 ? False Alarm Rate (%): ˇö (# Nonspeech samples detected as speech / Total number of nonspeech samples) x 100 speech speech
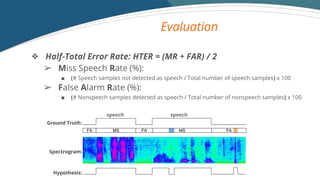
- 15. Evaluation FA MS FA MS FA Ground Truth: Spectrogram: Hypothesis: ? Half-Total Error Rate: HTER = (MR + FAR) / 2 ? Miss Speech Rate (%): ˇö (# Speech samples not detected as speech / Total number of speech samples) x 100 ? False Alarm Rate (%): ˇö (# Nonspeech samples detected as speech / Total number of nonspeech samples) x 100 speech speech
- 16. Evaluation ? QUT-NOISE-TIMIT: ? Large-scale dataset to evaluation SAD algorithms. ? Technical challenges and Future: ? Automatic adaptation to environment. ? Overlapping sound events. ? CNN approach to perform others problems. Features Classifier HTER Energy Threshold 26,3% MFCC GMM-HMM 4,7 % Spectrogram CNN 3,2%
- 17. References ˇń J. Sohn, N. S. Kim, and W. Sung, ˇ°A statistical model based voice activity detection,ˇ± Signal Processing Letters, IEEE, vol. 6, no. 1, pp. 1¨C3, 1999. ˇń W. H. Abdulla, Z. Guan, and H. C. Sou, ˇ°Noise robust speech activity detection,ˇ± in Signal Processing and Information Technology (ISSPIT), 2009 IEEE International Symposium on. IEEE, 2009, pp. 473¨C477. ˇń D. B. Dean, S. Sridharan, R. J. Vogt, and M. W. Mason, ˇ°The qut-noise-timit corpus for the evaluation of voice activity detection algorithms,ˇ± Proceedings of Interspeech 2010, 2010. ˇń D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, and K. Vesely. The Kaldi Speech Recognition Toolkit. In IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. IEEE Signal Processing Society, 2011. ˇń S. Thomas, S. Ganapathy, G. Saon, and H. Soltau, ˇ°Analyzing convolutional neural networks for speech activity detection in mismatched acoustic conditions,ˇ± in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014, pp. 2519¨C 2523. ˇń Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell, ˇ°Caffe: Convolutional architecture for fast feature embedding,ˇ± arXiv preprint arXiv:1408.5093, 2014. ˇń H. Ghaemmaghami, D. Dean, S. Kalantari, S. Sridharan, and C. Fookes, ˇ°Complete-linkage clustering for voice activity detection in audio and visual speech,ˇ± 2015. ˇń NVIDIA Deep Learning GPU Training System (DIGITS) 4. Retrieved July 18, 2016, from https://developer.nvidia.com/digits.