









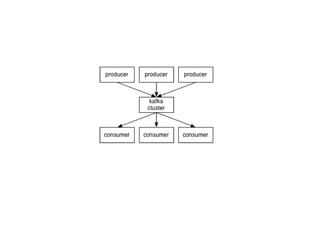



kafka
- 2. Agenda • About Kafka • Kafka vs. others (e.g. RabbitMQ) • Use cases • How it works? • Kafka as Data-Hub
- 3. About Kafka? • Open-source • Distributed, partitioned, replicated commit log service • It provides the functionality of a messaging system
- 6. Why to develop Kafka? • Better Performance with less HD – Huge amount of data – Different use cases (online & offline processing) – Reduce protocol constrains
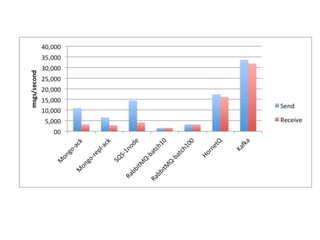
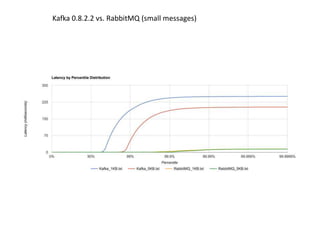
- 9. Kafka 0.8.2.2 vs. RabbitMQ (small messages)
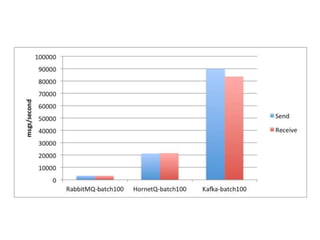
- 10. Now let’s increase the number of messages
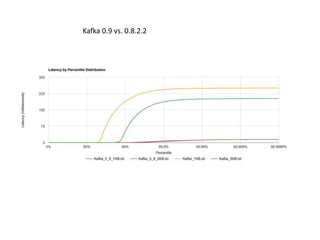
- 11. Kafka 0.9 vs. 0.8.2.2
- 12. Kafka 0.9 vs. RabbitMQ
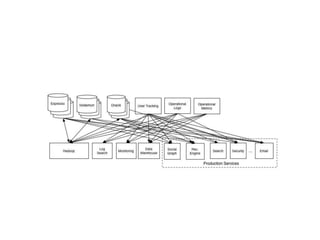
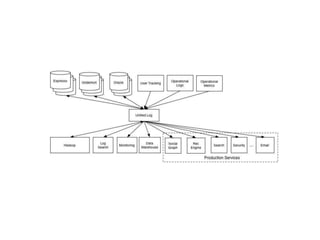
- 13. Use cases • Messaging • Website Activity Tracking • Metrics • Log Aggregation • Stream Processing • Event Sourcing • Commit Log
- 14. How it works?
Editor's Notes
- #4: Apache Kafka is publish-subscribe messaging rethought as a distributed commit log. Fast A single Kafka broker can handle hundreds of megabytes of reads and writes per second from thousands of clients. Scalable Kafka is designed to allow a single cluster to serve as the central data backbone for a large organization. It can be elastically and transparently expanded without downtime. Data streams are partitioned and spread over a cluster of machines to allow data streams larger than the capability of any single machine and to allow clusters of coordinated consumers Durable Messages are persisted on disk and replicated within the cluster to prevent data loss. Each broker can handle terabytes of messages without performance impact. Distributed by Design Kafka has a modern cluster-centric design that offers strong durability and fault-tolerance guarantees.
- #5: The data was taken from: http://www.slideshare.net/ToddPalino/enterprise-kafka-kafka-as-a-service?qid=efef2f94-68c4-45d8-8fa5-be7109e102cf&v=&b=&from_search=14 This slide is not up to date (~2014)
- #6: http://bravenewgeek.com/tag/kafka/ http://www.warski.org/blog/2014/07/evaluating-persistent-replicated-message-queues/
- #7: Issues they have tried to solve: Throughput Batch systems Persistence Stream Processing Ordering guarantees Partitioning They have tried to use other Message-Brokers e.g. RabbitMQ & ActiveMQ Kafka is first and foremost focused on producer performance. LinkedIn uses it to collect everything for example: user activity, logs. It greatly simplifies their infrastructure, since they use it for both online and offline consumption. Better Performance (More data doesn’t affect the performance). Couple of services may want to consume the data with huge delay. The broker doesn’t need to keep track the consumer’s offset. It doesn’t have all the features & complexity of protocols like: AMQP
- #8: It has higher throughput than other QM system.
- #9: It is also interesting to see how sending more messages in a batch improves the throughput. As already mentioned, when increasing the batch size from 10 to 100, Rabbit gets a 2x speedup, HornetQ a 1.2x speedup, and Kafka a 2.5x speedup, achieving about 89 000 msgs/s! Changing the configuration may affect the results.
- #10: In this benchmark, non-durable queues were used for RabbitMQ. As a result, we should see reduced latencies since we aren’t going to disk. Kafka, on the other hand, requires disk persistence, but this doesn’t have a dramatic effect on latency until we look at the 94th percentile and beyond, when compared to RabbitMQ. RabbitMQ is much more concern by design (AMQP protocol) with consumer, while Kafka is not, i.e. provides much more features on the control of messages to consumer and coupled with it. Kafka is first and foremost focused on producer performance, consume as much as possible and let consumers handle it later.
- #11: With RabbitMQ, we see the dramatic increase in tail latencies, while Kafka doesn’t appear to be significantly affected.
- #12: They fix some issues, which improved the performances.
- #13: Kafka latency is almost like RabbitMQ without queue persistence
- #14: Messaging - Kafka works well as a replacement for a more traditional message broker. Website Activity Tracking - The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting. Metrics - Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data. Log Aggregation - Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency. Stream Processing - Many users end up doing stage-wise processing of data where data is consumed from topics of raw data and then aggregated, enriched, or otherwise transformed into new Kafka topics for further consumption. Commit Log - Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data.
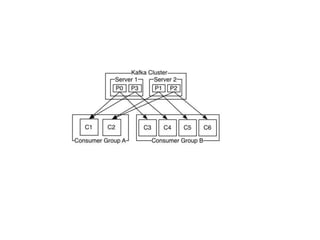
- #17: A topic is a category or feed name to which messages are published. For each topic, the Kafka cluster maintains a partitioned log. Each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition.