[KCD GT 2023] Demystifying etcd failure scenarios for Kubernetes.pdf
?
0 likes?97 views

Etcd is a key-value store used by Kubernetes to store cluster data. The document discusses etcd failure scenarios and myths regarding using etcd in Kubernetes clusters. It provides best practices for configuring etcd heartbeat and election timers and hardware specifications to maintain stability. Common etcd failure modes like leader failure, follower failure, and network partitions are also covered.













[KCD GT 2023] Demystifying etcd failure scenarios for Kubernetes.pdf
- 1. Demystifying etcd failure scenarios for Kubernetes By William Caban 1 @williamcaban
- 2. etcd 101 2
- 3. Kubernetes Control-Plane & etcd 3 W W S S S W S W S W S W Multi Node Cluster Compact Cluster S W All-in-One K8s W W W Multi Node Cluster S W S W S W kube-apiserver kube-scheduler kube-controller-manager cloud-controller-manager container runtime kubelet Kubernetes Architectures A B C D K8s Control Plane (Supervisor role)
- 4. 4 Etcd Redundancy vs Performance Failure Tolerance x 2 x 1 x 0 x 0 Write Performance High Low Required Active Quorum Size Low High Redundancy Low High 3 2 2 1
- 5. 5 The life of a write on etcd 1. No leader 2. The election & vote 3. Leader coordinate the writes 4. For ¡°Set Foo=bar¡±. Leader writes into log entry Foo=bar 5. Replicate ¡°Foo=bar¡± to follower nodes Foo=bar Foo=bar Foo=bar 6. Leader waits for majority to write the entry to commit Foo=bar Foo=bar Foo=bar 7. Leader noti?es followers entry is committed Foo=bar Foo=bar Foo=bar 8. Leader send regular role noti?cations to followers Foo=bar Foo=bar Foo=bar
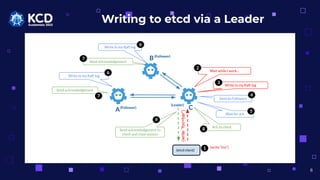
- 6. Writing to etcd via a Leader (etcd client) A C (Follower) (Leader) (write ¡°foo¡±) B(Follower) 1 Wait while I work¡ 2 Write to my Raft log Send to Followers 4 3 Write to my Raft log Send acknowledgement 6 7 Write to my Raft log Send acknowledgement 6 7 Wait for ack Ack to client 8 5 Send acknowledgement to client and close session 6 (write ¡°foo=bar¡±) 9
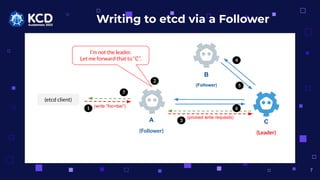
- 7. Writing to etcd via a Follower (etcd client) A C (Follower) (Leader) (write ¡°foo=bar¡±) I¡¯m not the leader. Let me forward that to ¡°C¡±. B (Follower) 1 7 (proxied write requests) 7 2 3 4 5 6
- 9. 9 ¡ñ Critical etcd timers settings: ¡ð HEARTBEAT_INTERVAL (100ms) ¡ö Frequency with which the Leader will notify Followers that it is still the Leader ¡ð ELECTION_TIMEOUT (1000ms) ¡ö How long a Follower node will wait without hearing a heartbeat before attempting to become Leader itself. Why the Critical ETCD Timers? Best Practices Heartbeat Interval ? < max(RTT) between members ? Too low increase CPU and network usage ? Too high leads to high election timeout ? slower to recover and detect failures Election Timeout ? 10 times the HEARTBEAT_INTERVAL
- 10. Why the Hardware Speci?cations? 10 CPU RAM DISK 2 to 4 cores 8 to 16 cores MINIMUM PRODUCTION 8 GB 16GB to 64GB < 30ms latency < 10ms latency Introducing the Magic Latency Formula for ETCD latency pro?les¡ Effective Latency = Disk Latency + Max(Jitter(Disk Latency)) + Network RTT + Max(Network Jitter) Note: To maintain etcd stability at scale, the E?ective Latency must be well below < Election Timeout
- 11. Myth Collection 1 11 Myth: We can use stretched control-plane for Kubernetes: ¡ñ without impact in performance ¡ñ for high availability ¡ñ as a highly available Kubernetes design What happens with failures? ? High Network Latency ? High Disk Latency ? Client to Leader Latency ? Cross-site Disconnection ? Kube-apiserver transaction rate? ? Memory utilization due to etcd fragmentation?
- 12. Myth Collection 2 12 Myth: We can use backups of etcd to: ¡ñ Restore Kubernetes in case of disaster recovery ¡ñ Rollback Kubernetes ¡ñ To recover the applications running in the cluster What happens with failures? ? Cluster identity? ? Certi?cates? ? ETCD peer certi?cates? ? ETCD identity? ? Persistent storage? ? API Schema Version? Manifest and other K8s objects Container image PersistentVolumeClaim PersistentVolume CSI-enabled storage backend Kubernetes Application Stack (Pods, Manifests, Storage mappings, etc) VS.
- 13. 13 ETCD Failure Modes https://etcd.io/docs/v3.5/op-guide/failures/ Leader failure Follower failure Majority failure Majority failure Network Partition Network Partition
- 14. 14 What to Remember about etcd?
- 15. Enjoy the rest of the event! Image by https://www.opsramp.com/guides/why-kubernetes/who-made-kubernetes/ 15