碍顿顿2016论文読み会资料(顿别别辫滨苍迟别苍迟)
?
1 like?2,325 views

KDD2016論文読み会(https://atnd.org/events/80771)の発表資料。 紹介した論文: Zhai et al., “DeepIntent: Learning Attentions for Online Advertising with Recurrent Neural Networks.” KDD2016.
Convert to study materialsBETA
Transform any presentation into ready-made study material—select from outputs like summaries, definitions, and practice questions.












碍顿顿2016论文読み会资料(顿别别辫滨苍迟别苍迟)
- 1. KDD2016論文読み会資 DeepIntent: Learning Attentions for Online Advertising with Recurrent Neural Networks. Zhai et al., 2016 小山田創哲 @sotetsuk
- 2. 概要 ● 検索クエリに対する広告の表出にAttention付きのRNNを使ったという話 ● サブクエリの生成やBM25の改良など、検索クエリに対する広告表出にとって実用的な結果 説明方針 ● RNN, LSTMらへんの事前知識は仮定 ● Attention(の先行研究)は簡単に説明 図や数式は特に断りがないかぎり下記論文からの引用になります。
- 3. Motivation ● (自然言語の)検索クエリに対して広告を表出する際、検索クエリの意図を正しく理 解することはとても重要 ○ 例: “surface pro 3 keyboard”というクエリがあった場合、 ”surface pro 3”や”surface 3”といったサブ クエリを考えるのは正しく意図を汲み取れてない。キーボードが欲しいという意図を汲む必要があ る。 ● そこで... ○ RNNを使って(自然言語の)クエリと(自然言語を含む)広告をそれぞれベクトル化することでクエリ に対して適切な広告を表出できるのではないか? ○ さらに、Attentionを使うことで、一体クエリと広告のどの部分に着目して広告を選んだのかがわかる のではないか?(e.g., ちゃんと”keyboard”に注目した表出になっているか)
- 4. Attentionの復習 Neural Machine Translationの文脈でSeq2Seqからの発展として登場 非常に多くの応用: ● Neural Machine Translation (Sutskever et al., 2014, Bahdanau et al., 2015, Wu et al., 2016) ● Neural Language Correction (Xie et al., 2016) ● Caption Generation (Xu et al., 2015) ● DQNの拡張 (Sorokin et al., 2016) Seq2Seq (Sutskever et al., 2014) 異なる長さの系列の入力と出力を扱えるEncoder Decoderモデル。RNNのEncoderの最後の隠れ層 h を使ってデコードする Sutskever et al., 2014から引用
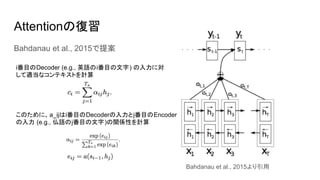
- 5. Attentionの復習 Bahdanau et al., 2015で提案 i番目のDecoder (e.g., 英語のi番目の文字) の入力に対 して適当なコンテキストを計算 このために、a_ijはi番目のDecoderの入力とj番目のEncoder の入力 (e.g., 仏語のj番目の文字)の関係性を計算 Bahdanau et al., 2015より引用
- 6. PoolingとしてのAttention この論文オリジナルの解釈 ● 複数のベクトル(h1, …, hT) から 一つのベクトル h を返すという意味でCNN文脈 のPoolingと同様に理解できる ● Seq2Seqは hT を h にマッピングするので、Last Pooling(と呼ぶ) ● Attentionメカニズムは重み付き平均を使ったPoolingと考えられる ● CNN同様、次も考えられる: ○ Max Pooling ○ Mean Pooling (実験においてこれらを使い分けた結果を示している)
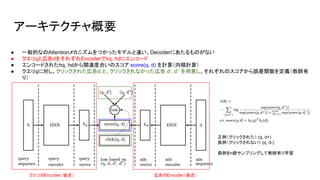
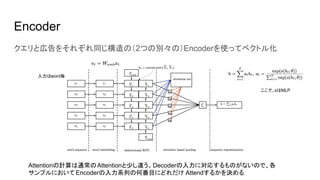
- 7. アーキテクチャ概要 クエリのEncoder(後述) 広告のEncoder(後述) ● 一般的なのAttentionメカニズムをつかったモデルと違い、Decoderにあたるものがない ● クエリqと広告dをそれぞれEncoderでhq, hdにエンコード ● エンコードされたhq, hdから関連度合いのスコア score(q, d) を計算(内積計算) ● クエリqに対し、クリックされた広告d と、クリックされなかった広告 d’, d’’ を用意し、それぞれのスコアから誤差関数を定義(教師有 り) 正例(クリックされた): (q, d+) 負例(クリックされない): (q, d-) 負例をn個サンプリングして教師有り学習
- 9. このモデルの(これから主張する)長所 ● Attentionメカニズムを使ったRNNが、(クエリ、広告)の対応として良いベクトル表現 を獲得できる(Attentionを使わないものと比べて) ● 獲得したAttentnionスコアがサブクエリの生成タスクに有用である ● 获得した础迟迟别苍迟颈辞苍スコアが叠惭25の拡张に使える
- 10. 実験 データセット ● “product ads”のクリックデータ ● 15Mのクリックサンプル ● 1つの正例(p, d+)に対し、 n個の負例(p, d-)を作って教師有り学習
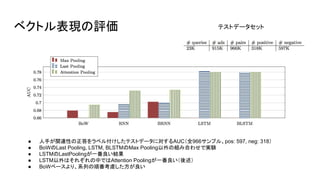
- 11. ベクトル表現の評価 ● 人手が関連性の正答をラベル付けしたテストデータに対するAUC(全966サンプル、pos: 597, neg: 318) ● BoWのLast Pooling, LSTM, BLSTMのMax Pooling以外の組み合わせで実験 ● LSTMのLastPoolingが一番良い結果 ● LSTM以外はそれぞれの中ではAttention Poolingが一番良い(後述) ● BoWベースより、系列の順番考慮した方が良い テストデータセット
- 12. Attentionの評価(1) ● (a): クエリ、(b)?(f): 広告のBLSTMのAttentionスコア ● クエリ、広告ともにbraceletのような重要な単語のAttentionが大きいことが わかる
- 13. Attentionの評価(2) ● LSTMの広告に対するAttentionスコア(上3つ)と、BLSTMの広告に対するAttentionスコア(下3つ) ● LSTMのAttentionスコアは後ろに引きづられてることがわかる(Last Poolingと比べて精度が出ていない理由) ● BLSTMはtoms(ブランド名)のような重要な単語も拾えている
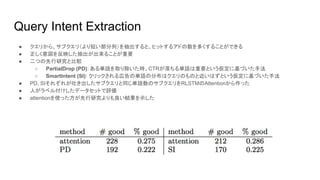
- 14. Query Intent Extraction ● クエリから、サブクエリ(より短い部分列)を抽出すると、ヒットするアドの数を多くすることができる ● 正しく意図を反映した抽出が出来ることが重要 ● 二つの先行研究と比較 ○ PartialDrop (PD): ある単語を取り除いた時、CTRが落ちる単語は重要という仮定に基づいた手法 ○ SmartIntent (SI): クリックされる広告の単語の分布はクエリのものと近いはずという仮定に基づいた手法 ● PD, SIそれぞれが吐き出したサブクエリと同じ単語数のサブクエリをRLSTMのAttentionから作った ● 人がラベル付けしたデータセットで評価 ● attentionを使った方が先行研究よりも良い結果を示した
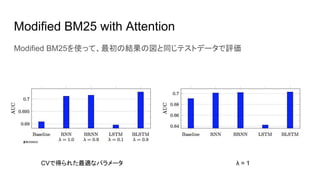
- 15. Modified BM25 with Attention BM25(下式)のTFを Attentionを使って次のように改良(|d|は文書内の単語数)
- 16. Modified BM25 with Attention Modified BM25を使って、最初の結果の図と同じテストデータで評価 CVで得られた最適なパラメータ λ = 1 通常のBM25
- 17. まとめ&感想 まとめ ● Attentionメカニズムを使ったRNNが、(クエリ、広告)の対応として良いベクトル表現を獲得できる ● 獲得したAttentnionスコアがサブクエリの生成タスクに有用である ● 获得した础迟迟别苍迟颈辞苍スコアが叠惭25の拡张に使える 良かった点 ● AttentionメカニズムのEncoder、Decoder以外の応用(二つの Encoder + Supervised)という点で参考に なった ● AttentionメカニズムのPoolingとしての解釈も面白い ?な点 ● 予測にどれくらい時間がかかるのか少し気になる(検索で実際に使えるのか?) ● 結局BidirectionalじゃないLSTMがなんで後ろにAttentionが引っ張られるのか良くわからない ... ● BM25の拡張に使えると言ってるが、スコアの改善幅がそんなに大きいと思えない
- 18. 参考文献 ● Zhai et al., “DeepIntent: Learning Attentions for Online Advertising with Recurrent Neural Networks.” KDD2016. ● Sutskever et al., “Sequence to sequence learning with neural networks.” NIPS, 2014. ● Bahdanau et al., “Neural machine translation by jointly learning to align and translate.” ICLR, 2015. ● Wu et al., “Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.” arXiv, 2016. ● Xie et al., “Neural language correction with character-based attention.” arXiv, 2016. ● Xu et al., “Show, attend and tell: Neural image caption generation with visual attention.” ICML, 2015. ● Sorokin et al., “Deep Attention Recurrent Q-Network.” NIPS(WS), 2015.