






































Ãÿè’—°ík§Œ§ø§·§Œ≥¢≤π≤ı≤ı¥«Ω‚¡–í§
- 1. Ãÿè’—°ík§Œ§ø§·§Œ≥¢≤π≤ı≤ı¥«Ω‚¡–í§£®AAAI°Ø17£© ‘≠ ¬á1,2°¢«∞‘≠ ŸFëó3 1 ERATO∏–÷xº¿ Season IV 1) π˙¡¢«ÈàÛ—ß—–æøÀ˘ 2) JST, ERATO, ∫”‘≠¡÷æÞ¥Û•∞•È•’•◊•Ì•∏•ß•Ø•» 3) ¿Ì—–AIP
- 2. —–æø±≥æ∞ 2
- 3. —–æø±≥æ∞£∫Ãÿè’þxík§œÕÍ˵§´£ø n °∫Ãÿè’þxík§Ú 𧶧»°¢•ø•π•Ø§ÀÈvþB§π§ÎÃÿè’¡ø§»°¢•ø•π•Ø§ÀÈvþB§∑ § §§Ãÿè’¡ø§»§Ú◊RÑe§π§Î§≥§»§¨§«§≠§Î°ª§»—‘§Ô§Ï§∆§§§Î°£ ? Lasso§Ú 𧶧»•‚•«•Î§Œ•π•—©`•π§ ±Ì¨F§¨µ√§È§Ï§Î°£ ? Lasso§À§Ë§√§∆þx§–§Ï§øÃÿè’¡ø§¨÷ÿ“™§ Ãÿè’¡ø§¿§»—‘§Ô§Ï§∆§§§Î°£ 3
- 4. —–æø±≥æ∞£∫Ãÿè’þxík§œÕÍ˵§´£ø n °∫Ãÿè’þxík§Ú 𧶧»°¢•ø•π•Ø§ÀÈvþB§π§ÎÃÿè’¡ø§»°¢•ø•π•Ø§ÀÈvþB§∑ § §§Ãÿè’¡ø§»§Ú◊RÑe§π§Î§≥§»§¨§«§≠§Î°ª§»—‘§Ô§Ï§∆§§§Î°£ ? Lasso§Ú 𧶧»•‚•«•Î§Œ•π•—©`•π§ ±Ì¨F§¨µ√§È§Ï§Î°£ ? Lasso§À§Ë§√§∆þx§–§Ï§øÃÿè’¡ø§¨÷ÿ“™§ Ãÿè’¡ø§¿§»—‘§Ô§Ï§∆§§§Î°£ n §∑§´§∑°¢ôC–µ—ß¡ï§ÀÕÍ˵§œ§¢§Í§®§ §§°£ ? ”–œÞ§Œ•«©`•ø§´§È—ß¡ï§π§Î“‘…œ°¢§¢§Î≥Ã∂»§Œ•®•È©`§œ∆§≥§Í§¶§Î°£ ? •«©`•ø”…¿¥?—ß¡ï ÷∑®”…¿¥§Œ•–•§•¢•π§¨§Œ§Î§≥§»§¨§¢§Î°£ 4
- 5. —–æø±≥æ∞£∫Ãÿè’þxík§œÕÍ˵§´£ø n °∫Ãÿè’þxík§Ú 𧶧»°¢•ø•π•Ø§ÀÈvþB§π§ÎÃÿè’¡ø§»°¢•ø•π•Ø§ÀÈvþB§∑ § §§Ãÿè’¡ø§»§Ú◊RÑe§π§Î§≥§»§¨§«§≠§Î°ª§»—‘§Ô§Ï§∆§§§Î°£ ? Lasso§Ú 𧶧»•‚•«•Î§Œ•π•—©`•π§ ±Ì¨F§¨µ√§È§Ï§Î°£ ? Lasso§À§Ë§√§∆þx§–§Ï§øÃÿè’¡ø§¨÷ÿ“™§ Ãÿè’¡ø§¿§»—‘§Ô§Ï§∆§§§Î°£ n §∑§´§∑°¢ôC–µ—ß¡ï§ÀÕÍ˵§œ§¢§Í§®§ §§°£ ? ”–œÞ§Œ•«©`•ø§´§È—ß¡ï§π§Î“‘…œ°¢§¢§Î≥Ã∂»§Œ•®•È©`§œ∆§≥§Í§¶§Î°£ ? •«©`•ø”…¿¥?—ß¡ï ÷∑®”…¿¥§Œ•–•§•¢•π§¨§Œ§Î§≥§»§¨§¢§Î°£ 5 ôC–µ—ߡ隆ïr§»§∑§∆Ègþ`§®§Î°£ ôC–µ—ߡ裡•þ•π§π§Î§»°£°£°£
- 6. —–æø±≥æ∞£∫ôC–µ—ߡ裡•þ•π§π§Î§»°£°£°£ 6 åüÈTº“ X§»§§§¶≤°öð§À§œ°∏à÷ÿ°π§»°∏—™àR°π§¨ÈvþB§π §Î§œ§∫£°
- 11. —–æø±≥æ∞£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ n §∑§´§∑°¢°∞Ègþ`§®§ §§Ãÿè’þxík°±§œÎy§∑§§°£ ? Lasso§œþx§–§Ï§øÃÿè’¡ø§¨°∞’ʧÀ÷ÿ“™§ Ãÿè’¡ø°±§«§¢§Î§≥§»§¨±£‘^§µ§Ï§ §§°£ - Adaptive Lasso§Ú§œ§∏§·°¢òî°©§ ∏ƒ…∆∑®§¨øº∞∏§µ§Ï§∆§§§Î°£ - §∑§´§∑°¢”–œÞ§Œ•«©`•ø§´§È—ß¡ï§∑§∆§§§Î“‘…œ°¢•®•È©`§œ±Ð§±§È§Ï§ §§°£ 11
- 12. —–æø±≥æ∞£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ n §∑§´§∑°¢°∞Ègþ`§®§ §§Ãÿè’þxík°±§œÎy§∑§§°£ ? Lasso§œþx§–§Ï§øÃÿè’¡ø§¨°∞’ʧÀ÷ÿ“™§ Ãÿè’¡ø°±§«§¢§Î§≥§»§¨±£‘^§µ§Ï§ §§°£ - Adaptive Lasso§Ú§œ§∏§·°¢òî°©§ ∏ƒ…∆∑®§¨øº∞∏§µ§Ï§∆§§§Î°£ - §∑§´§∑°¢”–œÞ§Œ•«©`•ø§´§È—ß¡ï§∑§∆§§§Î“‘…œ°¢•®•È©`§œ±Ð§±§È§Ï§ §§°£ n ±æ—–æø§Œ•¢•§•«•£•¢ ? §Ω§‚§Ω§‚°∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú“ª§ƒÃΩ§Ω§¶§»§∑§∆§§§Î§´§ÈÎy§∑§§°£ 12
- 13. —–æø±≥æ∞£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ n §∑§´§∑°¢°∞Ègþ`§®§ §§Ãÿè’þxík°±§œÎy§∑§§°£ ? Lasso§œþx§–§Ï§øÃÿè’¡ø§¨°∞’ʧÀ÷ÿ“™§ Ãÿè’¡ø°±§«§¢§Î§≥§»§¨±£‘^§µ§Ï§ §§°£ - Adaptive Lasso§Ú§œ§∏§·°¢òî°©§ ∏ƒ…∆∑®§¨øº∞∏§µ§Ï§∆§§§Î°£ - §∑§´§∑°¢”–œÞ§Œ•«©`•ø§´§È—ß¡ï§∑§∆§§§Î“‘…œ°¢•®•È©`§œ±Ð§±§È§Ï§ §§°£ n ±æ—–æø§Œ•¢•§•«•£•¢ ? §Ω§‚§Ω§‚°∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú“ª§ƒÃΩ§Ω§¶§»§∑§∆§§§Î§´§ÈÎy§∑§§°£ ? °∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú§ø§Ø§µ§Û“䧃§±§∆°¢§Ω§Ï§Ú•Ê©`•∂§À÷ æ§∑§ø§È§…§¶ §´£ø °˙ °∏LassoΩ‚§Ú—} ˝¡–í§§π§ÎÜñÓ}°π§Úøº§®§Î°£ 13
- 14. —–æø±≥æ∞£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ n §∑§´§∑°¢°∞Ègþ`§®§ §§Ãÿè’þxík°±§œÎy§∑§§°£ ? Lasso§œþx§–§Ï§øÃÿè’¡ø§¨°∞’ʧÀ÷ÿ“™§ Ãÿè’¡ø°±§«§¢§Î§≥§»§¨±£‘^§µ§Ï§ §§°£ - Adaptive Lasso§Ú§œ§∏§·°¢òî°©§ ∏ƒ…∆∑®§¨øº∞∏§µ§Ï§∆§§§Î°£ - §∑§´§∑°¢”–œÞ§Œ•«©`•ø§´§È—ß¡ï§∑§∆§§§Î“‘…œ°¢•®•È©`§œ±Ð§±§È§Ï§ §§°£ n ±æ—–æø§Œ•¢•§•«•£•¢ ? §Ω§‚§Ω§‚°∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú“ª§ƒÃΩ§Ω§¶§»§∑§∆§§§Î§´§ÈÎy§∑§§°£ ? °∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú§ø§Ø§µ§Û“䧃§±§∆°¢§Ω§Ï§Ú•Ê©`•∂§À÷ æ§∑§ø§È§…§¶ §´£ø °˙ °∏LassoΩ‚§Ú—} ˝¡–í§§π§ÎÜñÓ}°π§Úøº§®§Î°£ 14 X§»§§§¶≤°öð§ÀÈvþB§π §ÎÌóƒø§œ°£°£°£
- 15. —–æø±≥æ∞£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ n §∑§´§∑°¢°∞Ègþ`§®§ §§Ãÿè’þxík°±§œÎy§∑§§°£ ? Lasso§œþx§–§Ï§øÃÿè’¡ø§¨°∞’ʧÀ÷ÿ“™§ Ãÿè’¡ø°±§«§¢§Î§≥§»§¨±£‘^§µ§Ï§ §§°£ - Adaptive Lasso§Ú§œ§∏§·°¢òî°©§ ∏ƒ…∆∑®§¨øº∞∏§µ§Ï§∆§§§Î°£ - §∑§´§∑°¢”–œÞ§Œ•«©`•ø§´§È—ß¡ï§∑§∆§§§Î“‘…œ°¢•®•È©`§œ±Ð§±§È§Ï§ §§°£ n ±æ—–æø§Œ•¢•§•«•£•¢ ? §Ω§‚§Ω§‚°∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú“ª§ƒÃΩ§Ω§¶§»§∑§∆§§§Î§´§ÈÎy§∑§§°£ ? °∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú§ø§Ø§µ§Û“䧃§±§∆°¢§Ω§Ï§Ú•Ê©`•∂§À÷ æ§∑§ø§È§…§¶ §´£ø °˙ °∏LassoΩ‚§Ú—} ˝¡–í§§π§ÎÜñÓ}°π§Úøº§®§Î°£ 15 X§»§§§¶≤°öð§ÀÈvþB§π §ÎÌóƒø§œ°£°£°£ °∏…ÌÈL°π§»°∏—™àR°π §¶?§Û£ø
- 16. —–æø±≥æ∞£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ n §∑§´§∑°¢°∞Ègþ`§®§ §§Ãÿè’þxík°±§œÎy§∑§§°£ ? Lasso§œþx§–§Ï§øÃÿè’¡ø§¨°∞’ʧÀ÷ÿ“™§ Ãÿè’¡ø°±§«§¢§Î§≥§»§¨±£‘^§µ§Ï§ §§°£ - Adaptive Lasso§Ú§œ§∏§·°¢òî°©§ ∏ƒ…∆∑®§¨øº∞∏§µ§Ï§∆§§§Î°£ - §∑§´§∑°¢”–œÞ§Œ•«©`•ø§´§È—ß¡ï§∑§∆§§§Î“‘…œ°¢•®•È©`§œ±Ð§±§È§Ï§ §§°£ n ±æ—–æø§Œ•¢•§•«•£•¢ ? §Ω§‚§Ω§‚°∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú“ª§ƒÃΩ§Ω§¶§»§∑§∆§§§Î§´§ÈÎy§∑§§°£ ? °∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú§ø§Ø§µ§Û“䧃§±§∆°¢§Ω§Ï§Ú•Ê©`•∂§À÷ æ§∑§ø§È§…§¶ §´£ø °˙ °∏LassoΩ‚§Ú—} ˝¡–í§§π§ÎÜñÓ}°π§Úøº§®§Î°£ 16 X§»§§§¶≤°öð§ÀÈvþB§π §ÎÌóƒø§œ°£°£°£ °∏…ÌÈL°π§»°∏—™àR°π §¶?§Û£ø °∏ÃÂ÷ÿ°π§»°∏—™Ã«Çé°π §¶?§Û£ø
- 17. —–æø±≥æ∞£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ n §∑§´§∑°¢°∞Ègþ`§®§ §§Ãÿè’þxík°±§œÎy§∑§§°£ ? Lasso§œþx§–§Ï§øÃÿè’¡ø§¨°∞’ʧÀ÷ÿ“™§ Ãÿè’¡ø°±§«§¢§Î§≥§»§¨±£‘^§µ§Ï§ §§°£ - Adaptive Lasso§Ú§œ§∏§·°¢òî°©§ ∏ƒ…∆∑®§¨øº∞∏§µ§Ï§∆§§§Î°£ - §∑§´§∑°¢”–œÞ§Œ•«©`•ø§´§È—ß¡ï§∑§∆§§§Î“‘…œ°¢•®•È©`§œ±Ð§±§È§Ï§ §§°£ n ±æ—–æø§Œ•¢•§•«•£•¢ ? §Ω§‚§Ω§‚°∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú“ª§ƒÃΩ§Ω§¶§»§∑§∆§§§Î§´§ÈÎy§∑§§°£ ? °∞÷ÿ“™§ Ãÿè’¡ø§ŒΩM°±§Ú§ø§Ø§µ§Û“䧃§±§∆°¢§Ω§Ï§Ú•Ê©`•∂§À÷ æ§∑§ø§È§…§¶ §´£ø °˙ °∏LassoΩ‚§Ú—} ˝¡–í§§π§ÎÜñÓ}°π§Úøº§®§Î°£ 17 X§»§§§¶≤°öð§ÀÈvþB§π §ÎÌóƒø§œ°£°£°£ °∏…ÌÈL°π§»°∏—™àR°π §¶?§Û£ø °∏ÃÂ÷ÿ°π§»°∏—™Ã«Çé°π §¶?§Û£ø °∏ÃÂ÷ÿ°π§»°∏—™àR°π §≥§Ï§¿£°£°
- 18. Lasso 18
- 19. Lasso§À§Ë§ÎÃÿè’þxík •π•—©`•πæÄ–Œªÿé¢ÜñÓ} Given: »Î≥ˆ¡¶§Œ•⁄•¢ ?", ?" ° ?'°¡? ? = 1, 2, °≠ , ? Find: ªÿé¢ÇS ˝? ° ?' s.t. ?" 1 ? °÷ ? (? = 1, 2, °≠ , ?) §ø§¿§∑°¢?§œ∑«•º•Ì“™Àÿ§¨…Ÿ§ §§£®•π•—©`•π£© n •π•—©`•π–‘ ? ŒÔ¿Ìµƒ“™’à - ¥Û¡ø§ŒÃÿè’¡ø§Œ§¶§¡°¢Ñø§ØÃÿè’¡ø§œ…Ÿ§ §§§œ§∫§»§§§¶÷±∏–°£ ? Ω‚·ã–‘œÚ…œ - Ω‚§´§È“‚Œ∂§Œ§¢§ÎÃÿè’¡ø§Ú“ä≥ˆ§∑§ø§§°£â‰ ˝§ŒΩgÞz§þ°£ Ω‚∑®£∫Lassoªÿ颣® ?6’˝ÑtªØ£© ?? = argmin > 1 2 ?? ? ? A + ? ? 6 ? LassoΩ‚??§œ•π•—©`•π°£supp(??) = {? °√ ?" ? °Ÿ 0}§¨÷ÿ“™§ Ãÿè’¡ø°£ 19
- 20. Lasso§Œ¿Ì’쵃’˝µ±–‘£∫èÕ‘™∂®¿Ì LassoΩ‚£∫?? = argmin > 6 A ?? ? ? A + ? ? 6 þmµ±§ ‘O∂®§Œ‘™§«°¢LassoΩ‚??§œ’ʧŒ•—•È•·©`•ø?L§Œ•µ•ð©`•»£®∑« ¡„“™Àÿ£©§Ú∏þ§§¥_¬ §«èÕ‘™§π§Î°£ n Å¢∂® ? ’ʧŒ•‚•«•Î§¨? = ??L + ?; ?L§œ•π•—©`•π, ? °´ ?(0, ?A) ? ’˝ÑtªØ•—•È•·©`•ø?§œ Æ∑÷–°§µ§§°£ ? ?§Œ∏˜––§œ Æ∑÷∂¿¡¢£®∏þœýÈv§ Ãÿè’¡ø§œ§ §§£©°£ n …œ”õÅ¢∂®§Œ‘™§«°¢∏þ§§¥_¬ §«’ʧŒ•—•È•·©`•ø?L§Œ•µ•ð©`•»§¨èÕ ‘™§«§≠§Î°£ supp(??) = supp(?L) 20
- 21. Lasso§ŒœÞΩÁ£∫÷ÿ“™§ Ãÿè’¡ø§Ú“䬉§»§π°£ n ∏þ¥Œ‘™•«©`•ø§«§œ°¢ÓêÀ∆§∑§øÃÿè’¡ø§¨¥Ê‘⁄§π§Î§≥§»§¨∂ý§§°£ ? ÓêÀ∆Ãÿè’¡ø§Œ§¶§¡°¢§…§Ï§Ú π§√§∆§‚Õ¨µ»§Œ”Ëúyæ´∂»§Œ•‚•«•Î§¨◊˜§Ï§Î°£ ? °∏?§Œ∏˜––§œ Æ∑÷∂¿¡¢£®∏þœýÈv§ Ãÿè’¡ø§œ§ §§£©°π§»§§§¶Å¢∂®§¨≥…¡¢§∑§ §§ àˆ∫œ§Àœýµ±°£ °˙§≥§Œ§Ë§¶§ àˆ∫œ°¢Lasso§œÓêÀ∆Ãÿè’¡ø§Œ“ª≤ø§¿§±§Ú π§§≤–§Í§Úüo “ï§π§Î°£ n Lasso§ŒœÞΩÁ£∫ÓêÀ∆Ãÿè’¡ø§Œ÷–§Œ÷ÿ“™§ Ãÿè’¡ø§Ú“䬉§»§π°£ ? ¿˝§®§–°¢°∏…ÌÈL°π§»°∏ÃÂ÷ÿ°π§Œ§Ë§¶§ œýÈv§Œ∏þ§§Ãÿè’¡ø§Œ§¶§¡°¢∆¨∑Ω£®¿˝§®§– °∏…ÌÈL°π£©§¿§±§Ú π§√§ø•‚•«•Î§Ú≥ˆ¡¶§π§Î°£ °˙°∏ÃÂ÷ÿ°π§Ú“䬉§»§π°£°∏ÃÂ÷ÿ°π§Ú π§√§ø•‚•«•Î§Ú∆⁄¥˝§π§Î•Ê©`•∂§»§ŒÈg§À˝e ˝r§¨∆§≠§Î°£ n ±æ—–æø£∫°∏…ÌÈL°π°¢°∏ÃÂ÷ÿ°π§Ω§Ï§æ§Ï§Ú π§√§ø•‚•«•Î§ÚÅI∑Ω≥ˆ¡¶§π §Î°£ 21
- 24. ÜñÓ}§Œ∂® ΩªØ£∫LassoΩ‚§Œ¡–í§ n Ω‚§Œ•µ•ð©`•»§Ú? ? {?6, ?A, °≠ , ?'}§À÷∆œÞ§∑§øLasso£∫ Lasso ? = min > 6 A ?? ? ? A + ? ? 6 s.t. supp ? ? ? ÜñÓ}£∫LassoΩ‚§Œ¡–í§ Lasso ? §Œ–°§µ§§Ìò§ÀòO–°§Œ?§Ú?ÇÄ¡–í§§π§Î°£ £®òO–°£∫supp ? = ?§»§ §Î§‚§Œ°£§Ω§Ï“‘Õ‚§œ»þÈL°££© °æ◊¢“‚°ø’˝ÑtªØ•—•π§Àª˘§≈§§§øΩ‚§Œ¡–í§§«§œ§ §§°£ ? ’˝ÑtªØ•—•π§«§œØE§ Ω‚§´§È√Ч Ω‚§ÿ§»?§Ú≪اµ§ª§øïr§ŒΩ‚§Ú¡–í§§π§Î°£ ? ±æÜñÓ}§«§œ?πÃ∂®§Œ‘™§«°¢ƒøµƒÈv ˝Ç駨ïNÌò§À§ §Î§Ë§¶§ÀΩ‚§Œ•µ•ð©`•»§Ú¡– í§§π§Î°£ ? ?6, ?A, ?V , ?6, ?A, ?W , ?6, ?W, ?X , ?6, ?A , °≠ 24 ◊ÓþmΩ‚§«§ŒƒøµƒÈv ˝Çé§ÚLasso ? §»§π§Î°£
- 25. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•»?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ? ° ?§À§ƒ§§§∆ ?§´§È§Ú?§Ú»°§Í≥˝§§§ø? = ? ? {?}§Ú◊˜§Î °£ Lasso(?°‰)§ŒΩ‚?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 25
- 26. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•» ?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ? ° ?§À§ƒ§§§∆ ?§´§È§Ú?§Ú»°§Í≥˝§§§ø? = ? ? {?}§Ú◊˜§Î °£ Lasso(?°‰)§ŒΩ‚?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 26 Ω‚§Œ∫Ú—a Lasso •Ω•Î•– ? = ?6, ?A, ?V ≥ˆ¡¶ ? = ?6, ?A, ?W, ?V, ?X ?6 = ?6, ?A, ?V ?6 = ?6, ?A, ?W, ?V, ?X
- 27. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•»?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ ? ° ?§À§ƒ§§§∆ ?§´§È§Ú ?§Ú»°§Í≥˝§§§ø ? = ? ? {?}§Ú◊˜§Î °£ Lasso(?°‰)§ŒΩ‚?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 27 Ω‚§Œ∫Ú—a ?6 = ?A, ?W, ?V, ?X ?A = ?6, ?W, ?V, ?X ?W = ?6, ?A, ?W, ?X ?6 = ?6, ?A, ?W, ?V, ?X Lasso •Ω•Î•– ?6 = ?6, ?A, ?V ?6 = ?6, ?A, ?W, ?V, ?X
- 28. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•»?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ ? ° ?§À§ƒ§§§∆ ?§´§È§Ú?§Ú»°§Í≥˝§§§ø? = ? ? {?}§Ú◊˜§Î °£ ?????(?°‰)§ŒΩ‚ ?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 28 Ω‚§Œ∫Ú—a (?6 = ?A, ?V, ?X , ?6 )?6 = ?A, ?W, ?V, ?X ?A = ?6, ?W, ?V, ?X ?W = ?6, ?A, ?W, ?X ?6 = ?6, ?A, ?W, ?V, ?X Lasso •Ω•Î•– ?6 = ?6, ?A, ?V ?6 = ?6, ?A, ?W, ?V, ?X
- 29. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•»?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ ? ° ?§À§ƒ§§§∆ ?§´§È§Ú?§Ú»°§Í≥˝§§§ø? = ? ? {?}§Ú◊˜§Î °£ ?????(?°‰)§ŒΩ‚ ?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 29 Ω‚§Œ∫Ú—a (?6 = ?A, ?V, ?X , ?6 )?6 = ?A, ?W, ?V, ?X ?A = ?6, ?W, ?V, ?X ?W = ?6, ?A, ?W, ?X ?6 = ?6, ?A, ?W, ?V, ?X Lasso •Ω•Î•– (?A = ?6, ?W, ?V , ?A ) ?6 = ?6, ?A, ?V ?6 = ?6, ?A, ?W, ?V, ?X
- 30. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•»?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ ? ° ?§À§ƒ§§§∆ ?§´§È§Ú?§Ú»°§Í≥˝§§§ø? = ? ? {?}§Ú◊˜§Î °£ ?????(?°‰)§ŒΩ‚ ?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 30 Ω‚§Œ∫Ú—a (?6 = ?A, ?V, ?X , ?6 )?6 = ?A, ?W, ?V, ?X ?A = ?6, ?W, ?V, ?X ?W = ?6, ?A, ?W, ?X ?6 = ?6, ?A, ?W, ?V, ?X Lasso •Ω•Î•– (?A = ?6, ?W, ?V , ?A ) (?W = ?6, ?A, ?X , ?W )?6 = ?6, ?A, ?V ?6 = ?6, ?A, ?W, ?V, ?X
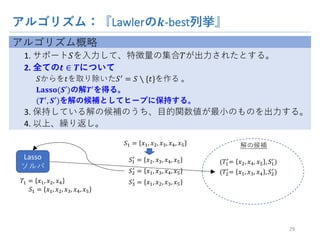
- 31. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•»?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ? ° ?§À§ƒ§§§∆ ?§´§È§Ú?§Ú»°§Í≥˝§§§ø? = ? ? {?}§Ú◊˜§Î °£ ?????(?°‰)§ŒΩ‚?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 31 Ω‚§Œ∫Ú—a (?6 = ?A, ?V, ?X , ?6 ) Lasso •Ω•Î•– (?A = ?6, ?W, ?V , ?A ) (?W = ?6, ?A, ?X , ?W )≥ˆ¡¶ ?A = ?A, ?V, ?X ?A = ?A, ?W, ?V, ?X ?6 = ?6, ?A, ?V ?6 = ?6, ?A, ?W, ?V, ?X
- 32. •¢•Î•¥•Í•∫•ý£∫°∫Lawler§Œ ?-best¡–í§°ª •¢•Î•¥•Í•∫•ý∏≈¬‘ 1. •µ•ð©`•»?§Ú»Î¡¶§∑§∆°¢Ãÿè’¡ø§ŒºØ∫œ?§¨≥ˆ¡¶§µ§Ï§ø§»§π§Î°£ 2. »´§∆§Œ ? ° ?§À§ƒ§§§∆ ?§´§È§Ú ?§Ú»°§Í≥˝§§§ø ? = ? ? {?}§Ú◊˜§Î °£ Lasso(?°‰)§ŒΩ‚?°‰§Úµ√§Î°£ (? , ?°‰)§ÚΩ‚§Œ∫Ú—a§»§∑§∆•“©`•◊§À±£≥÷§π§Î°£ 3. ±£≥÷§∑§∆§§§ÎΩ‚§Œ∫Ú—a§Œ§¶§¡°¢ƒøµƒÈv ˝Ç駨◊Ó–°§Œ§‚§Œ§Ú≥ˆ¡¶§π§Î°£ 4. “‘…œ°¢¿R§Í∑µ§∑°£ 32 Ω‚§Œ∫Ú—a Lasso •Ω•Î•– ?6 = ?6, ?A, ?V ?6 = ?6, ?A, ?W, ?V, ?X (?A = ?6, ?W, ?V , ?A ) (?W = ?6, ?A, ?X , ?W ) ?A = ?A, ?V, ?X ?A = ?A, ?W, ?V, ?X ?V = ?W, ?V, ?X ?X = ?A, ?W, ?X ?j = ?A, ?W, ?V ?A = ?A, ?W, ?V, ?X
- 33. •¢•Î•¥•Í•∫•ý§ŒÕ◊µ±–‘ ∂®¿Ì ÷∞∏∑®§À§Ë§ÍLasso ? §Œ–°§µ§§Ìò§ÀòO–°§Œ?§Ú¡–í§§«§≠§Î°£ n ≤ª“™§ ÃΩÀ˜§Ú•π•≠•√•◊§π§Î§≥§»§«°¢Ã·∞∏∑®§ÚÑø¬ ªØ§«§≠§Î°£ ? º»§ÀÃΩÀ˜§∑§ø?§Ú÷ÿ—}§∑§∆ÃΩÀ˜§∑§ §§§Ë§¶§À§π§Î°£»°§Í≥˝§Ø≠˝§Œ¬ƒös§Ú±£ ≥÷§π§Î°£ ? ÃΩÀ˜§∑§ø§≥§»§Œ§ §§? §À§ƒ§§§∆§‚°¢Lasso§Œ◊Óþm–‘Ãıº˛§´§ÈΩ‚§¨º»§ÀÃΩÀ˜ úg§þ§Œ§‚§Œ§»“ª÷¬§π§Î§≥§»§¨≈–∂®§«§≠§Î§≥§»§¨§¢§Î°£ 33
- 34. ¡–í§∞ʧŒèÕ‘™∂®¿Ì ∂®¿Ì∏≈¬‘ þmµ±§ Å¢∂®§Œ‘™§«°¢ Æ∑÷§ø§Ø§µ§Û¡–í§§π§Ï§–°¢∏þ§§¥_¬ §«¡–í§§∑§øΩ‚§Œ÷–§À supp(?L)§¨∫¨§Þ§Ï§Î°£ n þmµ±§ Å¢∂®??§§¥_¬ £∫ ? ’˝ÑtªØ•—•È•·©`•ø?§œ?∑÷?§µ§§(?L§Œ?•º•Ì≥…∑÷§Úœ¬§´§È•–•¶•Û•…)°£ ? •Œ•§•∫§¨?§µ§§§€§…¥_¬ §œ?§§°£ n ¡–í§ÇÄ ˝§À§ƒ§§§∆?§®§Î§≥§»£∫ ? ’˝ÑtªØ•—•È•·©`•ø?§¨?§µ§§§€§…¡–í§§π§Ÿ§≠“™Àÿ§¨â৮§Î°£ ? ?§Œ∂¿?–‘§¨µÕ§§£®∏þœýÈv§ŒÃÿè’¡ø§¨∂ý§§£©§€§…¡–í§§π§Ÿ§≠“™Àÿ§¨â৮ §Î°£ 34
- 35. ågÚYΩYπ˚ 35
- 36. ågÚY1. •∑•Ì•§•∫• §ŒÈ_ª® n Thaliana gene expression data (Atwell et al. °Ø10): §…§ŒþzŪ?§¨È_ª®§ÀÑø§Ø§´§Ú÷™§Í§ø§§°£ ? ? ° ?A6j6Wk£∫þzŪ?∏˜•—•ø©`•Û§¨?∆§∑§∆§§§Î§´§…§¶§´£®2 Ç飩 ? ? ° ?£∫∞k¨F¡ø ? •«©`•ø ˝£®ÇÄà˝£©£∫134 36 50ÇÄ¡–í§§∑§∆§‚°¢ƒøµƒÈv ˝Ç駜0.05% §∑§´âດ§∑§ §´§√§ø°£ ¥Û”ÚΩ‚§¨6Çħ¢§√§ø°£ Ω‚§Œ•µ•ð©`•»§Œ•µ•§•∫§œ ¥ÛÃÂ40~45§Ø§È§§°£ ¥Û”ÚΩ‚§¨—} ˝§¢§Î = ÖgºÉ§ÀLasso§Úþm”√§π§Î§»°¢6ÇħŒ§¶§¡§Œ1§ƒ§¨“䧃§´§Î§¿§±°£À˚§ŒÃÿè’¡ø§œ“䬉§»§π°£
- 37. ågÚY2. •À•Â©`•π”õ ¬§Œ∑÷Óê n 20 Newsgroups Data (Lang°Ø95); ibm vs mac •À•Â©`•π”õ ¬§Ú∂˛§ƒ§Œ•´•∆•¥•Í§À∑÷Óê§π§Î§Œ§ÀÃÿè’µƒ§ Ög’Z§Ú÷™§Í§ø§§°£ ? ? ° ?66jVl£∫Ög’Z§Œ∞k¨F£®åg ˝Çé°¢tf-idf£© ? ? ° {ibm, mac} £∫”õ ¬§Œ•´•∆•¥•Í£®2Ç飩 ? •«©`•ø ˝£®Õ∂∏ ˝£©£∫1168 °˙ ∑÷ÓêÜñÓ}§ §Œ§«°¢•Ì•∏•π•∆•£•√•Øªÿ颧À÷∞∏∑®§Úþm”√°£ 37 ¥Û”ÚΩ‚§À§¢§√§ø’Z ¡–í§Ω‚§«÷√§≠ìQ§Ô§√§ø’Z drive, os, disk§Œ§Ë§¶§ ibm•Þ•∑•Û£®Windows ôC£©§ÀÃÿ”–§ŒÖg’Z§¨“䬉§»§µ§Ï§∆§§§ø§Œ§¨ “䧃§´§√§ø°£ 040, 610§Œ§Ë§¶§ mac•Þ•∑•Û£®–Õ∑¨£©§ÀÃÿ”– §ŒÖg’Z§¨“䬉§»§µ§Ï§∆§§§ø§Œ§¨“䧃§´§√§ø°£
- 38. §Þ§»§· n ÜñÓ}“‚◊R£∫•Ê©`•∂§À–≈Óm§µ§Ï§ÎÃÿè’þxík§Ú§∑§ø§§°£ ? Ög“ª§ŒÃÿè’þxíkΩYπ˚§Ú≥ˆ¡¶§π§Î§Œ§«§ §Ø°¢—} ˝§ŒΩYπ˚§Ú¡–í§§∑§∆≥ˆ¡¶§π §Î°£ n °∏LassoΩ‚§Œ•µ•ð©`•»¡–í§°π§»§∑§∆ÜñÓ}§Ú∂® ΩªØ§∑§ø°£ n Lawler§Œ?-best •’•Ï©`•ý•Ô©`•Ø§Úþm?§∑§øÑø¬ µƒ§ •¢•Î•¥•Í•∫ •ý§Ú‘O”ã°£ n ¡–í§∞ʧŒ•π•—©`•πèÕ‘™∂®¿Ì§Ú‘^√˜§∑§ø°£ ? §…§Ï§¿§±¡–í§§π§Î§´§œÜñÓ}•—•È•·•ø“¿¥Ê°£ n ågÚY§Ë§Í£¨ågÎH§ŒÃÿè’þxíkÜñÓ}§À§œ°∏Õ¨§∏§Ø§È§§§Œ∆∑Ÿ|§ŒΩ‚§¨ ?¡ø§À¥Ê‘⁄§π§Î°π§≥§»§Ú¥_’J°£ ? Lasso §«µ√§È§Ï§øÃÿè’¡ø§Ú∞≤“◊§À–≈§∏§Î§Œ§œŒ£Íì°£ 38 GitHub: sato9hara/LassoVariants
- 39. —a◊„ŸY¡œ 39
- 40. ¡–í§∞ʧŒèÕ‘™∂®¿Ì£®ÕÍ»´∞Ê£© n Å¢∂®£∫? = ??L + ?; ?L•π•—©`•π, ? °´ ?(0, ?^2) ? ??L ? ? A °Ð ? ??? ? ? A for some ? °ð 0 ? ??? ? ? A °Ð ? for some ? °ð 0 ? ?? °Ÿ 0 with ?? A °Ð 1 + ? ?, ?vw 6 °Ð ? ?vwy 6 for some ? °ð max{1, ?A} ∂®¿Ì1£∫No False Inclusion By enumerating solutions up to ? ? ? °ð ??(??), we can find ? { , ? { , 1 °Ð ? °Ð ? such that supp ? { ? supp ?L ? ? { and ? ? { °Ð ?(?L). ∂®¿Ì2£∫No False Exclusion Let ? { , ? { be an enumerated solution where supp ? { ? supp ?L ? ? { . If ?vw 1 ?vw is invertible, then we have supp ? { ? ? °√ ?" L > 2? ?vw 1 ?vw ~6 ? with probability 1 ? ?L exp ??A/2? ???°≠ ?vw 1 ?vw . 40