Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
ŌĆó
0 likesŌĆó194 views

MADRLņŖ¼ļĪ£ņÜ░ĒÄśņØ┤ĒŹ╝ - Learning to Communicate to Solver Riddles with Deep Distributed Recurrent Q-Networks






















Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
- 1. MADRL Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks 1 Ļ╣Ćņśłņ░¼(Paul Kim)
- 2. Index 1. Abstract 2. Introduction 3. Background 2.1 Deep Q-Networks 2.2 Independent DQN 2.3 Deep Recurrent Q-Networks 2.4 Partially Observable Multi-Agent RL 4. DDRQN 5. Multi-Agent Riddles 4.1 Hats Riddle 4.1.1 Hats Riddle : Formalization 4.1.2 Hats Riddle : Network Architecture 4.1.3 Hats Riddle : Results 4.1.4 Hats Riddle : Emergent Strategy 4.1.5 Hats Riddle : Curriculum Learning 4.2 Switch Riddle 4.2.1 Switch Riddle : Formalization 4.2.2 Switch Riddle : Network Architecture 4.2.3 Switch Riddle : Results n=3 4.2.4 Switch Riddle : Strategy n=3 4.2.5 Switch Riddle : Result n=4 4.2.6 Switch Riddle : No Switch 4.2.7 Switch Riddle : Ablation Experiments 2
- 3. Abstract Abstract ņŚÉņØ┤ņĀäĒŖĖļōżļĪ£ ĻĄ¼ņä▒ļÉ£ ĒīĆņØ┤ CommunicationņØä ĻĖ░ļ░śņ£╝ļĪ£ ĒĢ®ļÅÖ ņ×æņŚģņØä ĒĢ┤Ļ▓░ĒĢĀ ņłś ņ׳ļŖö DDRQN(Deep Distributed Recurrent Q-Network) ņØä ņĀ£ņŗ£ĒĢ©. taskņŚÉņä£ļŖö ņé¼ņĀäņŚÉ ņäżĻ│äļÉ£ communication protocolņØä ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖņØī ņä▒Ļ│ĄņĀüņØĖ communicationņØä ņ£äĒĢ┤ ņŚÉņØ┤ņĀäĒŖĖļōżņØĆ ļ©╝ņĀĆ ņ×ÉĻĖ░ ņ×ÉņŗĀļōżņØś communication protocolņØä ņ×ÉļÅÖņ£╝ļĪ£ Ļ░£ļ░£ĒĢ┤ņĢ╝ ĒĢ© ņØ┤ļ»Ė ņל ņĢīļĀżņ¦ä riddle(ņłśņłśĻ╗śļü╝)ņŚÉ ĻĖ░ļ░śĒĢ£ ļæÉ Ļ░Ćņ¦ĆņØś ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖ ĒĢÖņŖĄ ļ¼ĖņĀ£ņŚÉ ļīĆĒĢ£ Ļ▓░Ļ│╝ļź╝ ņĀ£ņŗ£ĒĢśĻ│Ā DDRQNņ£╝ļĪ£ ņä▒Ļ│ĄņĀüņ£╝ļĪ£ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░Ē¢łņ£╝ļ®░, ĒĢÖņŖĄņ£╝ļĪ£ ļ¦īļōżņ¢┤ņ¦ä communication protocolņØä ļ░£Ļ▓¼Ē¢łļŗżļŖö Ļ▓āņØä Ļ░ĢņĪ░(ļŗ╣ņŗ£ļź╝ ĻĖ░ņżĆņ£╝ļĪ£ DRLņØ┤ communication protocolņØä ĒĢÖņŖĄĒĢ£ ņĄ£ņ┤łņØś ņé¼ļĪĆ) ĻĘĖļ”¼Ļ│Ā ļ¦łņ¦Ćļ¦ēņ£╝ļĪ£ DDRQNņØś ņĢäĒéżĒģŹņ▓śņØś Ļ░ü ņŻ╝ņÜö ĻĄ¼ņä▒ņÜöņåīĻ░Ć ņä▒Ļ│ĄņŚÉ ņżæņÜöĒĢśļŗżļŖö Ļ▓āņØä ņŗżĒŚś Ļ▓░Ļ│╝ļź╝ ņĀ£ņŗ£ĒĢ© 3
- 4. Introduction (ĻĘĖ ļŗ╣ņŗ£ļź╝ ĻĖ░ņżĆņ£╝ļĪ£!!) DRLņØś ļ░£ņĀäņØ┤ Ļ│Āņ░©ņøÉ ļĪ£ļ┤ćņĀ£ņ¢┤ļéś Visual Attention ĻĘĖļ”¼Ļ│Ā ALEļź╝ ĒżĒĢ©ĒĢ£ ņŚ¼ļ¤¼ Ļ░Ćņ¦Ć RLļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśļŖöļŹ░ ļÅäņøĆņØ┤ ļÉśņŚłņØī. ĻĘĖļĀćņ¦Ćļ¦ī ļīĆļČĆļČä single learning agentņŚÉ ĻĄŁĒĢ£ļÉ£ Ļ▓ĮņÜ░Ļ░Ć ļīĆļČĆļČäņ×ä. Competitive & Cooperative CompetitiveņäżņĀĢņŚÉņä£ ļ░öļææ(AlphaGo)ņŚÉ ļīĆĒĢ£ DRLņØĆ ņä▒Ļ│ĄņĀüņØĖ Ļ▓░Ļ│╝ļ¼╝ņØä ļ│┤ņŚ¼ņŻ╝ņŚłĻ│Ā CooperativeņäżņĀĢņŚÉņä£ Tampu(ļ”¼ļĘ░ĒĢ£ ņØ┤ņĀä ļģ╝ļ¼Ė)ļŖö DQNņØä ļ│ĆĒśĢĒĢśņŚ¼ ļæÉ Ļ░£ņØś PlayerĻ░Ć ALEĒÖśĻ▓ĮņŚÉņä£ ļ®ĆĒŗ░ ņŚÉņØ┤ņĀäĒŖĖ settingņØ┤ Ļ░ĆļŖźĒĢ©ņØä ļ│┤ņŚ¼ņżī. TampuņØś ņĀæĻĘ╝ļ░®ņŗØņØĆ Independent Q-LearningņŚÉ ĻĖ░ņ┤łĒĢśļ®░ ņŚÉņØ┤ņĀäĒŖĖļōżņØĆ Ļ░üņ×ÉņØś Q-functionņØä ĻĖ░ļ░śņ£╝ļĪ£ ļÅģļ”ĮņĀüņ£╝ļĪ£ ĒĢÖņŖĄĒĢśļŖö ļ░®ņŗØņ×ä. ĻĘĖļĀćņ¦Ćļ¦ī ņØ┤ļ¤¼ĒĢ£ ņĀæĻĘ╝ļ░®ņŗØņØĆ ļ¬©ļōĀ ņŚÉņØ┤ņĀäĒŖĖĻ░Ć ĒÖśĻ▓ĮņØś ņāüĒā£ļź╝ fully observeĒĢ£ļŗżļŖö Ļ▓āņØä Ļ░ĆņĀĢĒĢ© ļ░śļ®┤ņŚÉ ĒĢ£ ĒÄĖņ£╝ļĪ£ DQNļ░®ņŗØņ£╝ļĪ£ partial observableĒĢ£ Ļ▓ĮņÜ░ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ┤ ņŚ░ĻĄ¼ļōżņØ┤ ņ¦äĒ¢ēļÉśņŚłņ£╝ļéś Single AgentņŚÉ ĻĄŁĒĢ£ļÉ£ ņŚ░ĻĄ¼Ļ░Ć ļ¦ÄņĢśļŗżĻ│Ā ĒĢ© => so ļģ╝ļ¼ĖņØś ņĀĆņ×ÉļōżņØĆ partial observableĒĢśļ®░ ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖņØĖ Ļ▓ĮņÜ░ļź╝ ņāüņĀĢĒĢśĻ│Ā ņØ┤ļź╝ ĒĢ┤Ļ▓░ĒĢśĻ│Āņ×É ĒĢ© 4
- 5. Introduction Ļ│ĀļĀżņé¼ĒĢŁ ĻĘĖļלņä£ ņĢ×ņä£ ņ¢ĖĻĖēĒĢ£ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ┤ 3Ļ░Ćņ¦Ćļź╝ Ļ│ĀļĀżĒĢśņŚ¼ DDRQNņØ┤ļØ╝ļŖö ļ░®ļ▓Ģņ£╝ļĪ£ ņĀ£ņĢł 1. last action input Ļ░üĻ░üņØś ņŚÉņØ┤ņĀäĒŖĖņŚÉĻ▓ī ļŗżņØī stepņØś inputņ£╝ļĪ£ ņØ┤ņĀä ņŗ£ņĀÉņØś actionņØä ņĀ£Ļ│ĄĒĢ© 2. inter-agent weight sharing ļ¬©ļōĀ ņŚÉņØ┤ņĀäĒŖĖļŖö ļŗ©ņØ╝ ļäżĒŖĖņøīĒü¼ņØś Ļ░Ćņżæņ╣śļź╝ ņé¼ņÜ®ĒĢśņ¦Ćļ¦ī ņŚÉņØ┤ņĀäĒŖĖņØś Ļ│Āņ£Ā IDļź╝ ļäżĒŖĖņøīĒü¼ņØś ņĪ░Ļ▒┤ņ£╝ļĪ£ ņé¼ņÜ®ĒĢ©. ņØ┤ļŖö Ļ▓░Ļ│╝ņĀüņ£╝ļĪ£ ļ╣ĀļźĖ ĒĢÖņŖĄņØä Ļ░ĆļŖźĒĢśĻ▓ī ĒĢ£ļŗżĻ│Ā ĒĢ© 3. disabling experience replay ņŚ¼ļ¤¼ ņŚÉņØ┤ņĀäĒŖĖļōżņØ┤ ļÅÖņŗ£ņŚÉ ĒĢÖņŖĄĒĢśļŖö Ļ▓ĮņÜ░ņŚÉļŖö non-stationaryĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ experience replayļź╝ ņé¼ņÜ®ĒĢśļŖö Ļ▓āņØĆ ņĀüĒĢ®ĒĢśņ¦Ć ņĢŖļŗżļŖö Ļ▓āņØä ņØ┤ņĢ╝ĻĖ░ ĒĢ© 5
- 6. Introduction DDRQNņŗżĒŚś DDRQNņØä ņŗżĒŚśĒĢśĻĖ░ ņ£äĒĢ┤ ņל ņĢīļĀżņ¦ä ļæÉ Ļ░Ćņ¦ĆņØś ņłśņłśĻ╗śļü╝ ļ¼ĖņĀ£ļź╝ ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖ Ļ░ĢĒÖöĒĢÖņŖĄņ£╝ļĪ£ ĒĢ┤Ļ▓░ĒĢ© 1. Hats Riddle : ĒĢ£ ņżäņŚÉ ņ׳ļŖö ņŚ¼ļ¤¼ ņŻäņłśļōżņØ┤ ņ×ÉņŗĀņØś ļ¬©ņ×É ņāēņØ┤ ļ¼┤ņŚćņØĖņ¦Ć ļ¦×ņČöļŖö ļ¼ĖņĀ£ 2. Switch Riddle : ņŻäņłśļōżņØ┤ ļ¬©ļæÉ switchĻ░Ć ņ׳ļŖö ļ░®ņØä ņ¢ĖņĀ£ ļ░®ļ¼ĖĒ¢łļŖöņ¦Ćļź╝ Ļ▓░ņĀĢĒĢśļŖö ļ¼ĖņĀ£ ņØ┤ļ¤¼ĒĢ£ ĒÖśĻ▓ĮņØĆ perceptionņ£╝ļĪ£ convolutionņØ┤ ĒĢäņÜöĒĢśņ¦Ć ņĢŖņ¦Ćļ¦ī partial observabilityņØś ņĪ┤ņ×¼ļĪ£ Recurrent Neural Networkņ£╝ļĪ£ ļ│Ąņ×ĪĒĢ£ sequenceļź╝ ņ▓śļ”¼ĒĢ┤ņĢ╝ ĒĢ© Partial observabilityļŖö ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖņÖĆ Ļ▓░ĒĢ®ļÉśĻĖ░ ļĢīļ¼ĖņŚÉ ņĄ£ņĀüņØś ņĀĢņ▒ģņØĆ ņŚÉņØ┤ņĀäĒŖĖ Ļ░äņØś ĒåĄņŗĀņŚÉ ņØśņĪ┤ņØĖ ĒŖ╣ņ¦ĢņØ┤ ņ׳Ļ▓ī ļÉ©. communication protocolņØĆ ņé¼ņĀäņŚÉ ņĀĢņØśĒĢśņ¦Ć ņĢŖĻĖ░ ļĢīļ¼ĖņŚÉ RLļĪ£ ņĪ░ņĀĢļÉśļŖö protocolņØä ņ×ÉļÅÖņ£╝ļĪ£ Ļ░£ļ░£ĒĢ┤ņĢ╝ ĒĢ© Ļ▓░Ļ│╝ļŖö baselineņŚÉ ĒĢ┤ļŗ╣ĒĢśļŖö ļ░®ļ▓ĢņØä ļŖźĻ░Ć!! RLļĪ£ communication protocol ĒĢÖņŖĄņØä ņä▒Ļ│ĄĒĢ£ ņ▓½ļ▓łņ¦Ė ļģ╝ļ¼ĖņØ┤Ļ│Ā DDRQNņØś ĻĄ¼ņä▒ņÜöņåīļōżņØ┤ ņä▒Ļ│ĄņŚÉ ņżæņÜöĒĢśļŗżļŖö Ļ▓āņØä ņŗżĒŚśņ£╝ļĪ£ ņĀ£ņŗ£ 6
- 7. Background : DQN Experience Replay 7
- 8. Background : Independent DQN Independent Q-Learning DQNņØĆ cooperativeĒĢ£ ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖ ņäżņĀĢņ£╝ļĪ£ ĒÖĢņןļÉśņŚłĻ│Ā, Ļ░üĻ░üņØś ņŚÉņØ┤ņĀäĒŖĖ ņØĆ global stateņØĖ ļź╝ Ļ┤Ćņ░░ĒĢśĻ│Ā, Ļ░üĻ░üņØś Ļ░£ļ│äņĀüņØĖ Ē¢ēļÅÖņØĖ ļź╝ ņäĀĒāØĒĢśĻ│Ā, ņŚÉņØ┤ņĀäĒŖĖ Ļ░äņŚÉ Ļ│Ąņ£ĀļÉśļŖö ĒīĆļŗ©ņ£äņØś ļ│┤ņāüņØĖ ļź╝ ļ░øņØī. TammpuļŖö DQNņØä Independent Q-LearningĻ│╝ Ļ▓░ĒĢ®ĒĢ£ ĒöäļĀłņ×äņøīĒü¼ļĪ£ ņ£äņØś ņäżņĀĢņØä Ļ│ĀļĀż. Ļ▓░Ļ│╝ņĀüņ£╝ļĪ£ ņĢäļלņÖĆ Ļ░ÖņØĆ ĒśĢĒā£ņØś Q-functioņØä ņäżņĀĢĒĢśĻ▓ī ļÉ© ļŗ©ņĀÉ Independent Q-LearningņØĆ ņłśļĀ┤ļ¼ĖņĀ£ļź╝ ņĢ╝ĻĖ░ĒĢĀ ņłś ņ׳ņØī(ĒĢ£ ņŚÉņØ┤ņĀäĒŖĖņØś ĒĢÖņŖĄņØ┤ ĒÖśĻ▓ĮņØä ļŗżļźĖ ņŚÉņØ┤ņĀäĒŖĖņŚÉĻ▓ī non-stationaryĒĢśĻ▓ī ļ│┤ņØ┤ĻĖ░ ļĢīļ¼Ė) 8
- 9. Background : DRQN DRQN DQNĻ│╝ IQNņØĆ ļ¬©ļæÉ fully observableĒĢ£ Ļ░ĆļŖźņä▒ņØä Ļ░ĆņĀĢĒĢ©. ņŚÉņØ┤ņĀäĒŖĖņØś ņ×ģļĀźņ£╝ļĪ£ s_tļź╝ ņé¼ņÜ®ĒĢ©. ļīĆņĪ░ņĀüņ£╝ļĪ£, Partial observableĒĢ£ ĒÖśĻ▓ĮņŚÉņä£ļŖö s_tĻ░Ć ņł©Ļ▓©ņ¦ĆĻ│Ā ņŚÉņØ┤ņĀäĒŖĖļŖö s_tņÖĆ Ļ┤ĆĻ│äĻ░Ć ņ׳ļŖö observationļź╝ ņé¼ņÜ®ĒĢśĻ▓ī ļÉśņ¦Ćļ¦ī ĻĘ╝ļ│ĖņĀüņ£╝ļĪ£ ņĢäņŻ╝Ēü░ ņ░©ņØ┤ļź╝ ļ│┤ņØ┤ļŖö Ļ▓āņØĆ ņĢäļŗś ĻĖ░ņĪ┤ņØś ņŚ░ĻĄ¼ņŚÉņä£ Matthew HauknechtļŖö singleņŚÉņØ┤ņĀäĒŖĖļź╝ ņ▓śļ”¼ĒĢśĻĖ░ ņ£äĒĢ┤ Deep Recurrent Q-Networkļź╝ ņĀ£ņĢłĒĢśņŚ¼ partialĒĢ£ Ļ▓ĮņÜ░ļź╝ ļČĆļČäņĀüņ£╝ļĪ£ ĒĢ┤Ļ▓░ Feed forwardļäżĒŖĖņøīĒü¼ļź╝ ĒåĄĒĢ┤ Q;aļź╝ approximateĒĢśļŖö ļīĆņŗĀņŚÉ internal stateļź╝ ņ£Āņ¦ĆĒĢśļ®┤ņä£ ņŗ£Ļ░äņØ┤ ĒØÉļ”äņŚÉ ļö░ļØ╝ņä£ observationņØä ņóģĒĢ®ĒĢĀ ņłś ņ׳ļŖö Recurrent Neural NetworkļĪ£ Q(o;a)ļź╝ approximateĒĢ© DRQNņØĆ Ļ░ü timestepņŚÉņä£ Q_tņÖĆ h_tļź╝ outputņ£╝ļĪ£ ņČ£ļĀźĒĢ© 9
- 10. Background : Partially Observable Multi-Agent RL Partially Observable Multi-Agent RL ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖņÖĆ ļČĆļČä Ļ┤Ćņ░░ Ļ░ĆļŖźņä▒ņØ┤ ļ¬©ļæÉ ņ׳ļŖö ņäżņĀĢņØä Ļ│ĀļĀżĒĢ©. Ļ░ü ņŚÉņØ┤ņĀäĒŖĖļŖö Ļ░ü time stepļ¦łļŗż ņ×Éņ▓┤ņĀüņØĖ o_{t}^{m} ļź╝ ļ░øĻ│Ā ļé┤ļČĆ ņāüĒā£ h_{t}^{m} ļź╝ ņ£Āņ¦ĆĒĢ© ņĀĆņ×ÉļōżņØĆ ĒĢÖņŖĄņØ┤ centralizeļ░®ņŗØņ£╝ļĪ£ ņØ╝ņ¢┤ļéĀ ņłś ņ׳ļŗżĻ│Ā Ļ░ĆņĀĢĒĢ©. ņŚÉņØ┤ņĀäĒŖĖļŖö ņ×ÉĻĖ░ ņ×ÉņŗĀļ¦īņØś historyņŚÉņä£ ņĪ░Ļ▒┤ņØä ĒĢÖņŖĄĒĢĀ ņłś ņ׳ļŗżļ®┤ ĒĢÖņŖĄ Ļ│╝ņĀĢņŚÉņä£ parameterļź╝ Ļ│Ąņ£ĀĒĢĀ ņłś ņ׳ļŗżĻ│Ā Ļ░ĆņĀĢĒĢ©. => Centralized Learning and Decentralized policy ņŚÉņØ┤ņĀäĒŖĖļōżņØ┤ communicationĒĢĀ ļÅÖĻĖ░ļź╝ ņ¢╗ļŖö Ļ▓āņØĆ ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖņÖĆ partial observableĒĢ£ Ļ░ĆļŖźņä▒ņØ┤ Ļ│ĄņĪ┤ĒĢĀ ļĢīļ¦īņØ┤ Ļ░ĆļŖźĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņØ┤ļ¤¼ĒĢ£ Ļ▓ĮņÜ░ņŚÉ ĒĢ┤ļŗ╣ĒĢśļŖö ĒÖśĻ▓Įļ¦īņØä Ļ│ĀļĀżĒĢ© 10
- 11. DDRQN DDRQN Partially observableĒĢ£ MultiagentņäżņĀĢņŚÉņä£ DRLņŚÉ ļīĆĒĢ£ Ļ░Ćņן Ļ░äļŗ©ĒĢ£ ļ░®ļ▓Ģņ£╝ļĪ£ DRQNĻ│╝ Independent Q-LearningņØä Ļ▓░ĒĢ®. ņØ┤ ļ░®ņŗØņØä ļģ╝ļ¼ĖņŚÉņä£ļŖö Na├»ve methodļĪ£ ļČĆļ”ä ņØ┤ļ¤¼ĒĢ£ na├»ve methodņØś 3Ļ░Ćņ¦Ćļź╝ ņłśņĀĢĒĢ┤ņä£ DDRQNņØä ņĀ£ņŗ£ 11
- 12. DDRQN DDRQN 1. last-actionņØä inputņ£╝ļĪ£ ĒÖ£ņÜ®ĒĢśļŖö ļ░®ļ▓Ģ ļŗżņØī time-stepņŚÉ inputņ£╝ļĪ£ ņØ┤ņĀä time-stepņØś last-actionņØä ņĀ£Ļ│ĄĒĢśļŖö ļ░®ņĢł. ņØ┤ņ£ĀļŖö explorationņØä ņ£äĒĢ┤ņä£ stochasticĒĢ£ ņĀĢņ▒ģņØä ņé¼ņÜ®ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ observationļ┐Éļ¦ī ņĢäļŗłļØ╝ actionĻ┤Ćņ░░ņØś historyņŚÉ ļīĆĒĢ£ Ē¢ēļÅÖņØä ņĪ░ņĀłĒĢ┤ņĢ╝ ĒĢśĻĖ░ ļĢīļ¼ĖņØ┤ļØ╝Ļ│Ā ĒĢ©! Ļ▓░Ļ│╝ņĀüņ£╝ļĪ£ RNNņØ┤ Ē¢ēļÅÖ Ļ┤Ćņ░░ņŚÉ ļīĆĒĢ£ historyļź╝ ņĪ░ĻĖł ļŹö ņĀĢĒÖĢĒĢśĻ▓ī ĒīīņĢģĒĢĀ ņłś ņ׳Ļ▓ī ļÉ© 2. inter-agent weight sharing ļ¬©ļōĀ ņŚÉņØ┤ņĀäĒŖĖ ļäżĒŖĖņøīĒü¼ņØś weightļź╝ ņŚ░Ļ▓░ĒĢśļŖö Ļ▓ā. ņśżņ¦ü ĒĢśļéśņØś ļäżĒŖĖņøīĒü¼ļ¦ī ĒĢÖņŖĄļÉśĻ│Ā ņé¼ņÜ®ļÉ©. ĻĘĖļĀćņ¦Ćļ¦ī ņŚÉņØ┤ņĀäĒŖĖļōżņØĆ ļŗżļźĖ observationņØä ļ░øĻ│Ā, Ļ░üĻ░ü ņł©Ļ▓©ņ¦ä ņāüĒā£ļź╝ ĒĢÖņŖĄņ£╝ļĪ£ ņ¦äĒÖöņŗ£ĒéżĻĖ░ ļĢīļ¼ĖņŚÉ ļŗżļź┤Ļ▓ī Ē¢ēļÅÖĒĢĀ ņłś ņ׳ņØī. ļśÉĒĢ£ Ļ░üĻ░üņØś ņŚÉņØ┤ņĀäĒŖĖļōżņØĆ ņ×Éņ▓┤ ņØĖļŹ▒ņŖż mņØä ņ×ģļĀźĻ░Æņ£╝ļĪ£ ļ░øĻĖ░ ļĢīļ¼ĖņŚÉ ņĀäļ¼ĖĒÖöĒĢśĻĖ░Ļ░Ć ņē¼ņøĆ. Weight sharingņØĆ ĒĢÖņŖĄĒĢ┤ņĢ╝ ĒĢĀ ĒīīļØ╝ļ»ĖĒä░ņØś ņł½ņ×Éļź╝ Ļ░Éņåīņŗ£ņ╝£ņä£ ĒĢÖņŖĄ ņåŹļÅä Ē¢źņāüņŚÉ ļÅäņøĆņØä ņżī 3. disabling experience replay ļŗ©ņØ╝ ņŚÉņØ┤ņĀäĒŖĖņŚÉņä£ļŖö experience replayĻ░Ć ņ£ĀņÜ®ĒĢśņ¦Ćļ¦ī ļŗżņżæ ņŚÉņØ┤ņĀäĒŖĖ ņäĖĒīģņŚÉņä£ ņŚÉņØ┤ņĀäĒŖĖļōżņØä ļÅģļ”ĮņĀüņ£╝ļĪ£ ĒĢÖņŖĄĒĢśļŖö Ļ▓ĮņÜ░ ĒÖśĻ▓ĮņØ┤ Ļ░üĻ░üņØś ņŚÉņØ┤ņĀäĒŖĖļōżņŚÉĻ▓ī non-stationaryĒĢśĻ▓ī ļéśĒāĆļéśĻĖ░ ļĢīļ¼ĖņŚÉ ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖļŖö Ļ▓āņØ┤ ņóŗņØī 12
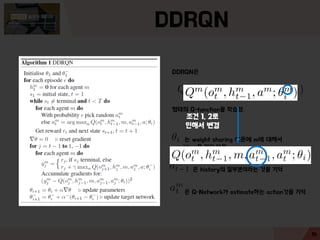
- 13. DDRQN DDRQNņØĆ ĒśĢĒā£ņØś Q-functionņØä ĒĢÖņŖĄĒĢ©. ļŖö weight sharing ļĢīļ¼ĖņŚÉ mņŚÉ ļīĆĒĢ┤ņä£ conditionņØä Ļ▒Ėņ¦Ć ņĢŖņØī ņØĆ historyņØś ņØ╝ļČĆļČäņØ┤ļØ╝ļŖö Ļ▓āņØä ĻĖ░ņ¢Ą ņØĆ Q-NetworkĻ░Ć estimateĒĢśļŖö actionĻ▓āņØä ĻĖ░ņ¢Ą 13
- 14. DDRQN DDRQNņØĆ ĒśĢĒā£ņØś Q-functionņØä ĒĢÖņŖĄĒĢ©. ļŖö weight sharing ļĢīļ¼ĖņŚÉ mņŚÉ ļīĆĒĢ┤ņä£ conditionņØä Ļ▒Ėņ¦Ć ņĢŖņØī ņØĆ historyņØś ņØ╝ļČĆļČäņØ┤ļØ╝ļŖö Ļ▓āņØä ĻĖ░ņ¢Ą ņØĆ Q-NetworkĻ░Ć estimateĒĢśļŖö actionĻ▓āņØä ĻĖ░ņ¢Ą ņĪ░Ļ▒┤ 1, 2ļĪ£ ņØĖĒĢ┤ņä£ ļ│ĆĻ▓Į 14
- 15. Multi-Agent Riddles : Hats Riddle http://news.chosun.com/site/data/html_dir/2016/02/24/2016022402442.html Hats Riddle ļ¼ĖņĀ£ ŌĆ£ĒĢ£ ņé¼ĒśĢ ņ¦æĒ¢ēĻ┤ĆņØ┤ 100ļ¬ģņØś ņŻäņłśļōżņØä ĒĢ£ ņżäļĪ£ ļ¼ČĻ│Ā Ļ░üĻ░üņØś ņŻäņłśļōżņØś ļ©Ėļ”¼ņŚÉ ļČēņØĆņāē ļśÉļŖö Ēīīļ×ĆņāēņØś ļ¬©ņ×Éļź╝ ņō░Ļ▓īĒĢ©. ņŻäņłśļōżņØĆ ņ×ÉņŗĀņØś ņĢ×ņŚÉ ņ׳ļŖö ņé¼ļ×īļōżņØś ļ¬©ņ×Éļź╝ ņżäņŚÉņä£ ļ│╝ ņłś ņ׳ņ¦Ćļ¦ī ņ×ÉņŗĀĻ│╝ ņ×ÉņŗĀņØś ļÆżņŚÉ ņ׳ļŖö ņŻäņłśļōżņØś ļ¬©ņ×Éļź╝ ļ│╝ ņłś ņŚåņØī. ņé¼ĒśĢ ņ¦æĒ¢ēĻ┤ĆņØĆ Ļ░Ćņן ļÆżņŚÉ ņ׳ļŖö ņŻäņłśļź╝ ņŗ£ņ×æņ£╝ļĪ£ Ļ░Ćņן ņĢ×ņŚÉ ņ׳ļŖö ņŻäņłśļōżņŚÉĻ▓ī ņŻäņłś ņ×ÉņŗĀņØś ļ¬©ņ×ÉņāēņØä ļ¼╝ņ¢┤ļ┤ä. ņŻäņłśļŖö ļČēņØĆņāē Ēś╣ņØĆ Ēīīļ×ĆņāēņØ┤ļØ╝Ļ│Ā ļīĆļŗĄĒĢ┤ņĢ╝ ĒĢśļ®░ ņĀĢļŗĄņØä ļ¦×Ē׳ļ®┤ ņé┤ ņłś ņ׳Ļ│Ā ĒŗĆļ”░ ļīĆļŗĄņØä ĒĢśļ®┤ ņé¼ĒśĢņŚÉ ņ▓śĒĢśĻ▓ī ļÉ©. ņ░ĖĻ│ĀļĪ£ ļ¬©ļōĀ ņé¼ļ×īņØ┤ ļŗĄņØä ļōŻļŖö ļÅÖņĢł ņĢäļ¼┤ļÅä ļŗĄņØ┤ ņś│ņØĆņ¦Ć ņĢī ņłś ņŚåņØī) ņĀäļéĀ ļ░żņŚÉ ņŻäņłśļōżņØĆ ņ×ÉņŗĀļōżņØä ņ£äĒĢ£ ņĀäļץņØä ņäĖņøīņĢ╝ ĒĢ©ŌĆØ ņŻäņłśļōżņØĆ Ļ░Ćņן ļÆżņŚÉ ņ׳ļŖö ņŻäņłśĻ░Ć Ēīīļ×Ć ļ¬©ņ×ÉņØś ņł½ņ×ÉĻ░Ć ņ¦ØņłśļØ╝ļ®┤ ŌĆ£ņ▓ŁņāēŌĆØņØ┤ļØ╝Ļ│Ā ļ¦ÉĒĢśĻ│Ā, ĻĘĖļĀćņ¦Ć ņĢŖņ£╝ļ®┤ ŌĆ£ļČēņØĆņāēŌĆ£ņØ┤ļØ╝Ļ│Ā ļ¦ÉĒĢśļŖö communication protocolņŚÉ ļÅÖņØśĒĢśļŖö Ļ▓āņØ┤ ņĄ£ņĀüņØś ņĀäļץ(ņØ┤ļ»Ė Ļ▓Ćņ”ØļÉ£ ļ░®ņŗØņØ┤ļŗł Ļ│Āļ»╝ĒĢśņ¦Ć ļ¦ÉĻ│Ā ļ░øņĢäļō£ļ”¼ņ×É). ļé©ņØĆ ņŻäņłśļōżņØĆ ņĢ×ņŚÉņä£ ļ│Ė ļ¬©ņ×ÉņÖĆ ĻĘĖļōż ļÆżņŚÉņä£ ļōżņØĆ ļīĆļŗĄņØä ļ░öĒāĢņ£╝ļĪ£ ņ×ÉņŗĀļōżņØś ļ¬©ņ×É ņāēņØä ņČöļĪĀĒĢĀ ņłś ņ׳ņØī 15 ļÆż ņĢ×
- 16. Hats Riddle : Formalization Hats Riddle : Formalization 16
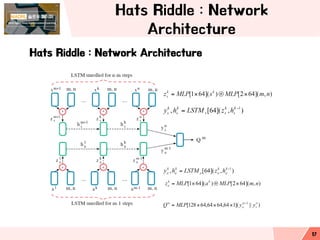
- 17. Hats Riddle : Network Architecture Hats Riddle : Network Architecture 17
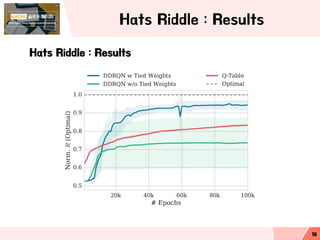
- 18. Hats Riddle : Results Hats Riddle : Results 18
- 19. Hats Riddle : Emergent Strategy Hats Riddle : Emergent Strategy 19
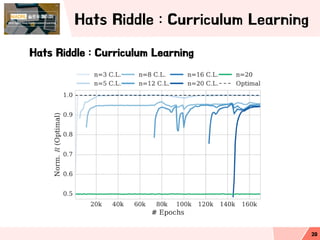
- 20. Hats Riddle : Curriculum Learning Hats Riddle : Curriculum Learning 20
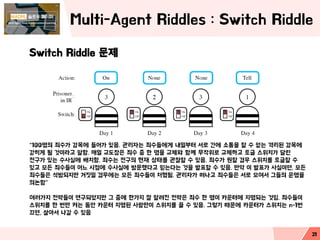
- 21. Multi-Agent Riddles : Switch Riddle Switch Riddle ļ¼ĖņĀ£ ŌĆ£100ļ¬ģņØś ņŻäņłśĻ░Ć Ļ░ÉņśźņŚÉ ļōżņ¢┤Ļ░Ć ņ׳ņØī. Ļ┤Ćļ”¼ņ×ÉļŖö ņŻäņłśļōżņŚÉĻ▓ī ļé┤ņØ╝ļČĆĒä░ ņä£ļĪ£ Ļ░äņŚÉ ņåīĒåĄņØä ĒĢĀ ņłś ņŚåļŖö Ļ▓®ļ”¼ļÉ£ Ļ░ÉņśźņŚÉ Ļ░ćĒ׳Ļ▓ī ļÉĀ Ļ▓āņØ┤ļØ╝Ļ│Ā ļ¦ÉĒĢ©. ļ¦żņØ╝ ĻĄÉļÅäņןņØĆ ņŻäņłś ņżæ ĒĢ£ ļ¬ģņØä ĻĄÉņ▓┤ņÖĆ ĒĢ©Ļ╗ś ļ¼┤ņ×æņ£äļĪ£ ĻĄÉņ▓┤ĒĢśĻ│Ā ĒåĀĻĖĆ ņŖżņ£äņ╣śĻ░Ć ļŗ¼ļ”░ ņĀäĻĄ¼Ļ░Ć ņ׳ļŖö ņłśņé¼ņŗżņŚÉ ļ░░ņ╣śĒĢ©. ņŻäņłśļŖö ņĀäĻĄ¼ņØś Ēśäņ×¼ ņāüĒā£ļź╝ Ļ┤Ćņ░░ĒĢĀ ņłś ņ׳ņØī. ņŻäņłśĻ░Ć ņøÉĒĢĀ Ļ▓ĮņÜ░ ņŖżņ£äņ╣śļź╝ ĒåĀĻĖĆĒĢĀ ņłś ņ׳Ļ│Ā ļ¬©ļōĀ ņŻäņłśļōżņØ┤ ņ¢┤ļŖÉ ņŗ£ņĀÉņŚÉ ņłśņé¼ņŗżņŚÉ ļ░®ļ¼ĖĒ¢łļŗżĻ│Ā ļ»┐ļŖöļŗżļŖö Ļ▓āņØä ļ░£Ēæ£ĒĢĀ ņłś ņ׳ņØī. ļ¦īņĢĮ ņØ┤ ļ░£Ēæ£Ļ░Ć ņé¼ņŗżņØ┤ļ®┤, ļ¬©ļōĀ ņŻäņłśļōżņØĆ ņäØļ░®ļÉśņ¦Ćļ¦ī Ļ▒░ņ¦ōņØ╝ Ļ▓ĮņÜ░ņŚÉļŖö ļ¬©ļōĀ ņŻäņłśļōżņØ┤ ņ▓śĒśĢļÉ©. Ļ┤Ćļ”¼ņ×ÉĻ░Ć ļ¢ĀļéśĻ│Ā ņŻäņłśļōżņØĆ ņä£ļĪ£ ļ¬©ņŚ¼ņä£ ĻĘĖļōżņØś ņÜ┤ļ¬ģņØä ņØśļģ╝ĒĢ©ŌĆØ ņŚ¼ļ¤¼Ļ░Ćņ¦Ć ņĀäļץļōżņØ┤ ņŚ░ĻĄ¼ļÉśņŚłņ¦Ćļ¦ī ĻĘĖ ņżæņŚÉ ĒĢ£Ļ░Ćņ¦Ć ņל ņĢīļĀżņ¦ä ņĀäļץņØĆ ņŻäņłś ĒĢ£ ļ¬ģņØ┤ ņ╣┤ņÜ┤Ēä░ņŚÉ ņ¦Ćļ¬ģļÉśļŖö Ļ▓āņ×ä. ņŻäņłśļōżņØ┤ ņŖżņ£äņ╣śļź╝ ĒĢ£ ļ▓łļ¦ī ņ╝£ļŖö ļÅÖņĢł ņ╣┤ņÜ┤Ēä░ ņ¦Ćļ¬ģļÉ£ ņé¼ļ×īļ¦īņØ┤ ņŖżņ£äņ╣śļź╝ ļüī ņłś ņ׳ņØī. ĻĘĖļĀćĻĖ░ ļĢīļ¼ĖņŚÉ ņ╣┤ņÜ┤Ēä░Ļ░Ć ņŖżņ£äņ╣śļŖö n-1ļ▓ł ļüäļ®┤, ņé┤ņĢäņä£ ļéśĻ░ł ņłś ņ׳ņØī 21
- 22. Switch Riddle : Formalization Switch Riddle : Formalization 22
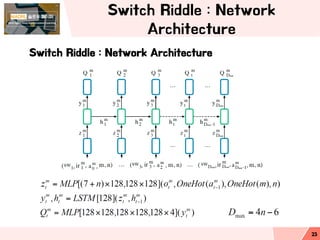
- 23. Switch Riddle : Network Architecture Switch Riddle : Network Architecture 23
- 24. Switch Riddle : Results n=3 Switch Riddle : Results n=3 24 N=3ņŚÉ ļīĆĒĢ£ Ļ▓░Ļ│╝ļź╝ ĒÖĢņØĖĒĢśļ®┤ DDRQNĻ│╝ na├»ve approach, hand- coded ņĀäļץņØś ŌĆ£tell on last dayŌĆØ ņĀäļץņØś ņĄ£ņĀü ņĀĢņ▒ģņØä ļ╣äĻĄÉĒĢ£ ļé┤ņÜ®ņ×ä DDRQNņØ┤ ņä▒ļŖźņØä Ē¢źņāüņŗ£ĒéżļŖö Ļ▓āņØä ņĢī ņłś ņ׳ņØī
- 25. Switch Riddle : Strategy n=3 Switch Riddle : Strategy n=3 25
- 26. Switch Riddle : Results n=4 Switch Riddle : Results n=4 26
- 27. Switch Riddle : No Switch Switch Riddle : No Switch 27
- 28. Switch Riddle : Ablation Experiments Switch Riddle : Ablation Experiments 28