Lfac9
0 likes438 views

Documentul detaliază sarcinile și metodele parser-elor, inclusiv gramaticile context-free și generarea de reprezentații intermediare a programelor sursă. Se discută despre tratarea erorilor, proprietăți precum ‚viable-prefix’ și diverse strategii de recuperare a erorilor. De asemenea, sunt prezentate specificațiile yacc/bison pentru crearea de parser-e și exemple de utilizare a lex/flex în contextul compiloarelor.





















![Specifica»õii Lex pentru Exemplul 2
%option noyywrap
%{
#include “y.tab.h”
Generated by Yacc, contains
#define NUMBER xxx
extern double yylval;
%}
number [0-9]+.?|[0-9]*.[0-9]+
Defined in y.tab.c
%%
[ ] { /* skip blanks */ }
{number} { sscanf(yytext, “%lf”, &yylval);
return NUMBER;
}
n|. { return yytext[0]; }
yacc -d example2.y bison -d -y example2.y
lex example2.l flex example2.l
gcc y.tab.c lex.yy.c gcc y.tab.c lex.yy.c
./a.out ./a.out
26](https://image.slidesharecdn.com/lfac9-130318042543-phpapp02/85/Lfac9-26-320.jpg)















![Parsare predictivă ne-recursivă
(bazată pe tabela de parsare)
• Dată o gramatică LL(1) G = (N, T, P, S) se
construiește o tabelă M[A,a] pentru fiecare
A  N, a  T și un ”driver program” cu o
stivă:
input a + b $
stack
Predictive parsing
X output
program (driver)
Y
Z Parsing table
$ M 42](https://image.slidesharecdn.com/lfac9-130318042543-phpapp02/85/Lfac9-42-320.jpg)
![Construirea Tabelei de parsare LL(1)
for each production A ÔÇÆ ÔÅ° do
for each a ÔÉé FIRST(ÔÅ°) do // a ÔÇπ ÔÅ•
add A ÔÇÆ ÔÅ° to M[A, a]
enddo
if ÔÅ• ÔÉé FIRST(ÔÅ°) then
for each b ÔÉé FOLLOW(A) do
add A ÔÇÆ ÔÅ° to M[A, b]
enddo
endif
enddo
Mark each undefined entry in M error
43](https://image.slidesharecdn.com/lfac9-130318042543-phpapp02/85/Lfac9-43-320.jpg)


![Parsare predictivă: Programul (Driver)
push($)
push(S)
a := lookahead
repeat
X := pop()
if X is a terminal or X = $ then
match(X) // moves to next token and a := lookahead
else if M[X, a] = X  Y1Y2…Yk then
push(Yk, Yk-1, …, Y2, Y1) // such that Y1 is on top
… invoke actions and/or produce output …
else error()
endif
until X = $
46](https://image.slidesharecdn.com/lfac9-130318042543-phpapp02/85/Lfac9-46-320.jpg)



Lfac9
- 1. Curs 9 - plan • Sarcinile unui parser • Gramatici CF – remember • Metode de parsare • Generatoare de parsere • Parsare cu Yacc / Bison – Specificații Yacc – Utilizare Lex / Flex cu Yacc / Bison • Parsare top - down
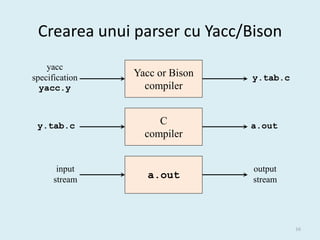
- 2. Parserul Token, Source tokenval Parser Lexical Intermediate Program and rest of Analyzer representation Get next front-end token Lexical error Syntax error Semantic error Symbol Table 2
- 3. Parserul • Un parser implementează o gramatică CF • Rolul unui parser: – Verifică sintaxa(= string recognizer) • raportare cu precizie a erorilor – Invocă acțiunile semantice: • semantica statică: verificarea tipului expresiilor, funcțiilor etc. • traducere orientată sintactic: cod sursă pentru reprezentarea intermediară 3
- 4. Traducere ”Syntax-Directed” • Un rol important al parserului: producerea unei reprezentări intermediare a programului sursă folosind metode de traducere ”dirijate sintactic” • Reprezentări intermediare posibile: – Arbore abstract(ASTs) – Cod cu trei adrese (quadruple) – Forma poloneză 4
- 5. Tratarea erorilor • Identificarea și localizarea erorilor – Erori lexicale : importante, compilatorul le poate recupera ușor și poate continua – Erori sintactice: cele mai importante pentru compilator, pot fi aproape totdeauna recuperate 5
- 6. Tratarea erorilor • Identificarea și localizarea erorilor – Erori de semantică statică : importante, uneori pot fi recuperate – Erori de semantică dinamică: greu sau imposibile de detectat la momentul compilării, e nevoie de verificat la execuție – Erori logice: greu sau imposibil de detectat 6
- 7. Proprietatea ”Viable-Prefix” • Proprietatea viable - prefix a parserelor LL/LR permite detectarea timpurie a erorilor de sintaxă – Scop: detectarea unei erori cât mai devreme posibil fără a se consuma intrări nenecesare – Cum: detectarea unei erori atunci când prefixul cuvântului de la intrare nu se potrivește cu nici un cuvânt din limbaj Error is Error is detected here … detected here … Prefix Prefix DO 10 I = 1;0 for (;) … … 7
- 8. Strategii de recuperare a erorilor • Modul ”panică” – Renunțarea la simboluri de intrare până când se găsește un token dintr-o mulțime specificată • Recuperare la nivel de frază – Efectuarea de corecții locale pentru a repara eroarea • Producții ”error” – Se mărește gramatica cu producții pentru construcții eronate – Se alege o secvență minimă de modificări pentru a obține o corecție de cost minim 8
- 9. Gramatici (Recap) G = (N, T, S, P) – T simboluri terminale – N simboluri neterminale – P o mulțime finită de producții de forma    (NT)* N (NT)* ,   (NT)* – S  N simbol de start 9
- 10. Convenții • Terminali: a, b, c, …  T 0, 1, id, + • Neterminali: A, B, C ,…  N • Simboluri generice: expr, term, stmt X, Y, Z  (NT) • Șiruri de terminali: u, v, w, x, y, z  T* • Șiruri oarecare: , ,   (NT)* 10
- 11. Derivări (Recap) • Derivare one-step : A unde A    P • Derivări extrem stângi (drepte): – lm dacă  nu conține nici un neterminal – rm dacă  nu conține nici un neterminal • Închidere reflexivă și tranzitivă * (zero sau mai mulți pași) • Închidere tranzitivă + (unul sau mai mulți pași) • Limbajul generat de G: L(G) = {w  T* | S + w} 11
- 12. Derivări G = ({E}, {+,*,(,),-,id}, P, E) P= EE+E EE*E E(E) E-E E  id Derivări: E  - E  - id E rm E + E rm E + id rm id + id E * E E * id + id E + id * id + id 12
- 13. Metode de parsare • Universal (orice gramatică CF) – Cocke-Younger-Kasami (CYK) – Earley • Top-down (gramatici CF cu restricții) – Recursiv descendent (predictive parsing) – Metode LL (Left-to-right, Leftmost derivation) • Bottom-up (gramatici CF cu restricții) – Parsare bazată pe relații de precedență – Metode LR (Left-to-right, Rightmost derivation) • SLR, LR, LALR 13
- 14. Generatoare de parsere • ANTLR (http://www.antlr.org/) – Generează parsere LL(k) • YACC (Yet Another Compiler Compiler) – 1975 S. C. Johnson la Bell Laboratory – Generează parsere LALR(1) • Bison – Versiunea îmbunătățită a lui Yacc – Robert Corbett şi Richard Stallmann (2006 – versiunea 2.3) 14
- 15. Generatoare de parsere • http://dinosaur.compilertools.net/ • http://epaperpress.com/lexandyacc/index.html • http://www.gnu.org/software/bison/ • http://catalog.compilertools.net/lexparse.html • http://members.cox.net/slkpg/ • http://wiki.python.org/moin/LanguageParsing • http://scottmcpeak.com/elkhound/ 15
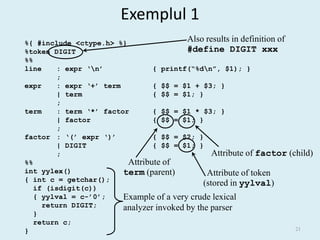
- 16. Crearea unui parser cu Yacc/Bison yacc specification Yacc or Bison y.tab.c yacc.y compiler y.tab.c C a.out compiler input output stream a.out stream 16
- 17. Specificații Yacc • O specificație yacc constă din 3 părți: declarații yacc, eventual declarații C în %{ %} %% reguli de traducere %% proceduri auxiliare definite de utilizator 17
- 18. Specificații Yacc • regulile de traducere sunt de forma: production1 { semantic action1 } production2 { semantic action2 } … productionn { semantic actionn } 18
- 19. Scrierea unei gramatici în Yacc • Producțiile sunt de forma: Nonterminal : tokens/nonterminals | tokens/nonterminals … ; • Token-urile definite ca un singur caracter pot fi incluse direct, de exemplu ‘+’ • Token-urile ce au un nume trebuiesc declarate în partea de declarații sub forma: %token NumeToken 19
- 20. Atribute sintetizate • Acțiunile semantice pot referi valori ale atributelor sintetizate ale terminalilor și neterminalilor din producția respectivă : X : Y1 Y2 Y3 … Yn { acțiune } • acțiune: expresie ce conține $$ și $i – $$ referă valoarea atributului lui X – $i referă valoarea atributului lui Yi • De exemplu factor : ‘(’ expr ‘)’ { $$=$2; } 20
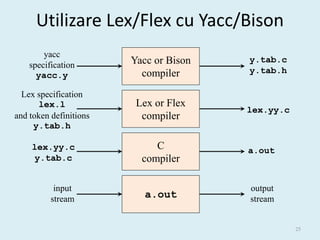
- 21. Exemplul 1 %{ #include <ctype.h> %} Also results in definition of %token DIGIT #define DIGIT xxx %% line : expr ‘n’ { printf(“%dn”, $1); } ; expr : expr ‘+’ term { $$ = $1 + $3; } | term { $$ = $1; } ; term : term ‘*’ factor { $$ = $1 * $3; } | factor { $$ = $1; } ; factor : ‘(’ expr ‘)’ { $$ = $2; } | DIGIT { $$ = $1; } ; Attribute of factor (child) %% Attribute of int yylex() term (parent) Attribute of token { int c = getchar(); (stored in yylval) if (isdigit(c)) { yylval = c-’0’; Example of a very crude lexical return DIGIT; analyzer invoked by the parser } return c; } 21
- 22. Procesare ambiguități • Se pot specifica gramatici ambigui dacă se precizează precedența operatorilor și asociativitatea stângă sau dreaptă : E  E+E | E-E | E*E | E/E | (E) | -E | num • În partea de declarații se specifică: %left ‘+’ ‘-’ %left ‘*’ ‘/’ %right UMINUS 22
- 23. Exemplul 2 %{ #include <ctype.h> Double type for attributes #include <stdio.h> and yylval #define YYSTYPE double %} %token NUMBER %left ‘+’ ‘-’ %left ‘*’ ‘/’ %right UMINUS %% lines : lines expr ‘n’ { printf(“%gn”, $2); } | lines ‘n’ | /* empty */ ; expr : expr ‘+’ expr { $$ = $1 + $3; } | expr ‘-’ expr { $$ = $1 - $3; } | expr ‘*’ expr { $$ = $1 * $3; } | expr ‘/’ expr { $$ = $1 / $3; } | ‘(’ expr ‘)’ { $$ = $2; } | ‘-’ expr %prec UMINUS { $$ = -$2; } | NUMBER ; %% 23
- 24. Exemplul 2 (cont) %% int yylex() { int c; while ((c = getchar()) == ‘ ‘) ; if ((c == ‘.’) || isdigit(c)) Crude lexical analyzer for { ungetc(c, stdin); fp doubles and arithmetic scanf(“%lf”, &yylval); operators return NUMBER; } return c; } int main() { if (yyparse() != 0) fprintf(stderr, “Abnormal exitn”); Run the parser return 0; } int yyerror(char *s) { fprintf(stderr, “Error: %sn”, s); Invoked by parser } to report parse errors 24
- 25. Utilizare Lex/Flex cu Yacc/Bison yacc specification Yacc or Bison y.tab.c compiler y.tab.h yacc.y Lex specification lex.l Lex or Flex lex.yy.c and token definitions compiler y.tab.h lex.yy.c C a.out y.tab.c compiler input output stream a.out stream 25
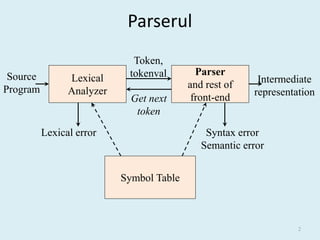
- 26. Specificații Lex pentru Exemplul 2 %option noyywrap %{ #include “y.tab.h” Generated by Yacc, contains #define NUMBER xxx extern double yylval; %} number [0-9]+.?|[0-9]*.[0-9]+ Defined in y.tab.c %% [ ] { /* skip blanks */ } {number} { sscanf(yytext, “%lf”, &yylval); return NUMBER; } n|. { return yytext[0]; } yacc -d example2.y bison -d -y example2.y lex example2.l flex example2.l gcc y.tab.c lex.yy.c gcc y.tab.c lex.yy.c ./a.out ./a.out 26
- 27. Recuperare erori în Yacc %{ … %} … %% lines : lines expr ‘n’ { printf(“%gn”, $2; } | lines ‘n’ | /* empty */ | error ‘n’ { yyerror(“reenter last line: ”); yyerrok; } ; … Error production: Reset parser to normal mode set error mode and skip input until newline 27
- 28. Parsare Top-Down • Metode LL (Left-to-right, Leftmost derivation) și parsare recursiv-descendentă Gramatica: Derivare extrem stângă: ET+T E lm T + T T(E) lm id + T T-E lm id + id T  id E E E E T T T T T T + id + id + id 28
- 29. Left Recursion (Recap) • Producțiile de forma AA | | sunt stâng recursive • În cazul existenței recursiei stângi un parser predictiv ciclează la nesfârșit pentru anumite intrări 29
- 30. Eliminarea recursiei stângi Se stabilește o ordine a neterminalilor: A1, A2, …, An for i = 1, …, n do for j = 1, …, i-1 do replace each Ai  Aj  with Ai  1  | 2  | … | k  where Aj  1 | 2 | … | k enddo eliminate the immediate left recursion in Ai enddo 30
- 31. Eliminarea recursiei stângi imediate Producțiile (recursie stânga): AA | | |A se înlocuiesc cu (recursie dreapta): A   AR |  AR AR   AR |  AR | 31
- 32. Exemplu AÔÇÆBC|a BÔÇÆCA|Ab Ordinea: A, B, C CÔÇÆAB|CC|a i = 1: - i = 2, j = 1: BÔÇÆCA|Ab ÔÉû BÔÇÆCA|BCb|ab ÔÉû(imm) B ÔÇÆ C A BR | a b BR BR ÔÇÆ C b BR | ÔÅ• i = 3, j = 1: CÔÇÆAB|CC|a ÔÉû CÔÇÆBCB|aB|CC|a i = 3, j = 2: CÔÇÆBCB|aB|CC|a ÔÉû C ÔÇÆ C A BR C B | a b BR C B | a B | C C | a ÔÉû(imm) C ÔÇÆ a b BR C B CR | a B CR | a CR CR ÔÇÆ A BR C B CR | C CR | ÔÅ• 32
- 33. Factorizare stângă • Dacă un neterminal are două sau mai multe producții care în partea dreaptă încep cu aceleași simboluri, gramatica nu este LL(1) și nu poate fi parsată predictiv • Se înlocuiesc producțiile A    1 |  2 | … |  n |  cu: A   AR |  AR  1 | 2 | … | n 33
- 34. Parsare predictivă • Se elimină recursia stângă (dacă este cazul) • Se factorizează stânga (dacă este cazul) • Se determină FIRST și FOLLOW • Se alege una din variante: – Recursivă (recursive calls) – Non-recursivă (table - driven) 34
- 35. FIRST • FIRST() = { mulțimea terminalilor ce încep cuvintele derivate din  (incluzând )} FIRST(a) = {a} if a  T FIRST() = {} FIRST(A) = A FIRST() for A  P FIRST(X1X2…Xk) = if for all j = 1, …, i-1 :   FIRST(Xj) then add non- in FIRST(Xi) to FIRST(X1X2…Xk) if for all j = 1, …, k :   FIRST(Xj) then add  to FIRST(X1X2…Xk) 35
- 36. FOLLOW • FOLLOW(A) = { mulțimea terminalilor ce pot urma imediat după neterminalul A în formele propoziționale } FOLLOW(A) = for all (B   A )  P do add FIRST(){} to FOLLOW(A) if A is the start symbol S then add $ to FOLLOW(A) for all (B   A )  P and   FIRST() do add FOLLOW(B) to FOLLOW(A) for all (B   A)  P do add FOLLOW(B) to FOLLOW(A) 36
- 37. Gramatici LL(1) • O gramatică G este LL(1) dacă nu este stâng recursivă și pentru orice colecție de producții: A  1 | 2 | … | n pentru neterminalul A au loc: 1. FIRST(i)  FIRST(j) =  for all i  j 2. if i *  then 2.a. j *  for all i  j 2.b. FIRST(j)  FOLLOW(A) =  for all i  j echivalent cu: FIRST(i FOLLOW(A))  FIRST(j FOLLOW(A)) =  for all i  j 37
- 38. Exemple SÔÇÆE|B EÔÇÆÔÅ• B ÔÇÆ a | begin SC end C ÔÇÆ ÔÅ• | ; SC S ÔÇÆ ABC A ÔÇÆ aA |ÔÅ• B ÔÇÆ bB |ÔÅ• C ÔÇÆ cC |ÔÅ• SÔÇÆaRa RÔÇÆS|ÔÅ• 38
- 39. Exemple Non-LL(1) Gramatica Nu este LL(1) deoarece: SÔÇÆSa|a Este st√¢ng recursiva SÔÇÆaS|a FIRST(a S) ÔÉá FIRST(a) ÔÇπ ÔÉÜ SÔÇÆaR|ÔÅ• RÔÇÆS|ÔÅ• R: S ÔÉû* ÔÅ• and ÔÅ• ÔÉû* ÔÅ• SÔÇÆaRa R: RÔÇÆS|ÔÅ• FIRST(S) ÔÉá FOLLOW(R) ÔÇπ ÔÉÜ 39
- 40. Parsare recursiv descendentă • Gramatica trebuie să fie LL(1) • Pentru fiecare neterminal se construiește o procedură (eventual recursivă) care realizează parsarea categoriei sintactice corespunzătoare acelui neterminal • Când un neterminal are producții multiple, fiecare producție este implementată într-o ramură a instrucțiunii de selectare, corespunzătoare informațiilor din intrare (look-ahead information) 40
- 41. Utilizare FIRST și FOLLOW procedure rest(); expr  term rest begin if lookahead in FIRST(+ term rest) then rest  + term rest match(‘+’); term(); rest() | - term rest else if lookahead in FIRST(- term rest) then | match(‘-’); term(); rest() else if lookahead in FOLLOW(rest) then term  id return else error() end; FIRST(+ term rest) = { + } FIRST(- term rest) = { - } FOLLOW(rest) = { $ } 41
- 42. Parsare predictivă ne-recursivă (bazată pe tabela de parsare) • Dată o gramatică LL(1) G = (N, T, P, S) se construiește o tabelă M[A,a] pentru fiecare A  N, a  T și un ”driver program” cu o stivă: input a + b $ stack Predictive parsing X output program (driver) Y Z Parsing table $ M 42
- 43. Construirea Tabelei de parsare LL(1) for each production A ÔÇÆ ÔÅ° do for each a ÔÉé FIRST(ÔÅ°) do // a ÔÇπ ÔÅ• add A ÔÇÆ ÔÅ° to M[A, a] enddo if ÔÅ• ÔÉé FIRST(ÔÅ°) then for each b ÔÉé FOLLOW(A) do add A ÔÇÆ ÔÅ° to M[A, b] enddo endif enddo Mark each undefined entry in M error 43
- 44. Exemplu AÔÇÆÔÅ° FIRST(ÔÅ°) FOLLOW(A) E ÔÇÆ T ER ( id $) ER ÔÇÆ + T ER + $) E ÔÇÆ T ER ER ÔÇÆ + T ER | ÔÅ• ER ÔÇÆ ÔÅ• ÔÅ• $) T ÔÇÆ F TR T ÔÇÆ F TR ( id +$) TR ÔÇÆ * F TR | ÔÅ• TR ÔÇÆ * F TR * +$) F ÔÇÆ ( E ) | id TR ÔÇÆ ÔÅ• ÔÅ• +$) FÔÇÆ(E) ( *+$) F ÔÇÆ id id *+$) id + * ( ) $ E E ÔÇÆ T ER E ÔÇÆ T ER ER ER ÔÇÆ + T ER ER ÔÇÆ ÔÅ• ER ÔÇÆ ÔÅ• T T ÔÇÆ F TR T ÔÇÆ F TR TR TR ÔÇÆ ÔÅ• TR ÔÇÆ * F TR T R ÔÇÆ ÔÅ• TR ÔÇÆ ÔÅ• F F ÔÇÆ id FÔÇÆ(E) 44
- 45. LL(1) vs. ambiguitate Gramatică ambiguă A FIRST() FOLLOW(A) S  i E t S SR | a S  i E t S SR i e$ SR  e S |  Sa a e$ Eb SR  e S e e$ SR    e$ Eb b t Error: duplicate table entry a b e i t $ S Sa S  i E t S SR SR   SR SR   SR  e S E Eb 45
- 46. Parsare predictivă: Programul (Driver) push($) push(S) a := lookahead repeat X := pop() if X is a terminal or X = $ then match(X) // moves to next token and a := lookahead else if M[X, a] = X  Y1Y2…Yk then push(Yk, Yk-1, …, Y2, Y1) // such that Y1 is on top … invoke actions and/or produce output … else error() endif until X = $ 46
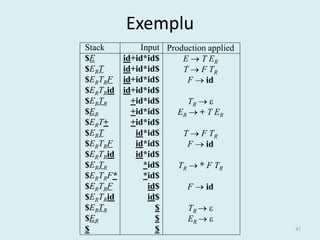
- 47. Exemplu Stack Input Production applied $E id+id*id$ E ÔÇÆ T ER $ERT id+id*id$ T ÔÇÆ F TR $ERTRF id+id*id$ F ÔÇÆ id $ERTRid id+id*id$ $ERTR +id*id$ TR ÔÇÆ ÔÅ• $ER +id*id$ ER ÔÇÆ + T ER $ERT+ +id*id$ $ERT id*id$ T ÔÇÆ F TR $ERTRF id*id$ F ÔÇÆ id $ERTRid id*id$ $ERTR *id$ TR ÔÇÆ * F T R $ERTRF* *id$ $ERTRF id$ F ÔÇÆ id $ERTRid id$ $ERTR $ TR ÔÇÆ ÔÅ• $ER $ ER ÔÇÆ ÔÅ• $ $ 47
- 48. Panic Mode Recovery Add synchronizing actions to FOLLOW(E) = { ) $ } undefined entries based on FOLLOW FOLLOW(ER) = { ) $ } FOLLOW(T) = { + ) $ } Pro: Can be automated FOLLOW(TR) = { + ) $ } Cons: Error messages are needed FOLLOW(F) = { + * ) $ } id + * ( ) $ E E ÔÇÆ T ER E ÔÇÆ T ER synch synch ER ER ÔÇÆ + T ER ER ÔÇÆ ÔÅ• ER ÔÇÆ ÔÅ• T T ÔÇÆ F TR synch T ÔÇÆ F TR synch synch TR TR ÔÇÆ ÔÅ• TR ÔÇÆ * F TR T R ÔÇÆ ÔÅ• TR ÔÇÆ ÔÅ• F F ÔÇÆ id synch synch FÔÇÆ(E) synch synch synch: the driver pops current nonterminal A and skips input till synch token or skips input until one of FIRST(A) is found 48
- 49. Phrase-Level Recovery Change input stream by inserting missing tokens For example: id id is changed into id * id Pro: Can be automated Cons: Recovery not always intuitive Can then continue here id + * ( ) $ E E ÔÇÆ T ER E ÔÇÆ T ER synch synch ER ER ÔÇÆ + T ER ER ÔÇÆ ÔÅ• ER ÔÇÆ ÔÅ• T T ÔÇÆ F TR synch T ÔÇÆ F TR synch synch TR insert * TR ÔÇÆ ÔÅ• TR ÔÇÆ * F TR T R ÔÇÆ ÔÅ• TR ÔÇÆ ÔÅ• F F ÔÇÆ id synch synch FÔÇÆ(E) synch synch insert *: driver inserts missing * and retries the production 49
- 50. Error Productions E  T ER Add “error production”: ER  + T ER |  TR  F TR T  F TR to ignore missing *, e.g.: id id TR  * F TR |  Pro: Powerful recovery method F  ( E ) | id Cons: Cannot be automated id + * ( ) $ E E  T ER E  T ER synch synch ER ER  + T ER ER   ER   T T  F TR synch T  F TR synch synch TR TR  F T R TR   TR  * F TR T R   TR   F F  id synch synch F(E) synch synch 50