












![? 2014 Masayuki Takagi-17-
Ż│Ż«ŻČŻ«źčźšź®®`ź▐ź¾ź╣▒╚▌^
GPU ż“└¹ė├żĘżŲüK┴ąėŗ╦Ńż╣żļż│ż╚żŪĪóCPU żŪż╬ų┤╬äI└Ēż╦īØżĘĪó40▒ČĮ³żżąį─▄Ž“╔Žż¼Ą├żķżņż▐żĘ
ż┐ĪŻ
x37.5
Amazon EC2 źżź¾ź╣ź┐ź¾ź╣
źūźĒź╗ź├źĄ
ź│źó╩²
g2.2xlarge g2.2xlarge
Xeon E5-2670 2.6GHz NVIDIA GRID K520
1 ź│źó
Ż©źĘź¾ź░źļź╣źņź├ź╔ĪóSIMD├³┴Ņ╩╣ė├ż╗ż║Īógcc -O3ŽÓĄ▒Ż®
1,536 ź│źó
4.86[sec]
182.2[sec]
SPH(Smoothed Particle Hydrodynamics) ż╦żĶżļ┴„╠ÕźĘź▀źÕźņ®`źĘźńź¾ 11,774┴Żūė](https://image.slidesharecdn.com/2014-07-18-140804070219-phpapp01/85/Lisp-Meet-Up-19-cl-cuda-a-library-to-use-NVIDIA-CUDA-in-Common-Lisp-18-320.jpg)

Lisp Meet Up #19, cl-cuda: a library to use NVIDIA CUDA in Common Lisp
- 1. cl-cuda : a library to use NVIDIA CUDA in Common Lisp 2014.7.29 Masayuki Takagi Lisp Meet Up presented by Shibuya.lisp #19 Ż▒Ż«│ę▒╩│ę▒╩▒½ Ż▒Ż«Ż▒Ż«│ę▒╩│ę▒╩▒½(General Purpose GPU) ż╚żŽŻ┐ Ż▒Ż«Ż▓Ż«GPU ż╬Üs╩Ę Ż▒Ż«Ż│Ż«ź╣źčź│ź¾żžż╬Į■═Ė Ż│Ż«cl-cuda źķźżźųźķźĻ Ż│Ż«Ż▒Ż«cl-cuda ż╬╠žÅš Ż│Ż«Ż▓Ż«╩╣żżĘĮ Ż│Ż«Ż│Ż«─┌▓┐įOėŗ Ż│Ż«Ż┤Ż«ź½®`ź═źļķv╩²ż“Ųäėż╣żļż▐żŪż╬┴„żņ Ż│Ż«ŻĄŻ«źŪźŌ Ż│Ż«ŻČŻ«źčźšź®®`ź▐ź¾ź╣▒╚▌^ Ż│Ż«ŻĘŻ«źņź▌źĖź╚źĻ Ż▓Ż«NVIDIA CUDA Ż▓Ż«Ż▒Ż«CUDA ż╚żŽŻ┐ Ż▓Ż«Ż▓Ż«źūźĒź╗ź├źĄ?źó®`źŁźŲź»ź┴źŃ Ż▓Ż«Ż│Ż«źßźŌźĻ?źó®`źŁźŲź»ź┴źŃ Ż▓Ż«Ż┤Ż«źūźĒź░źķź▀ź¾ź░?źŌźŪźļ ─┐┤╬Ż║
- 3. ? 2014 Masayuki Takagi-2- Ż▒Ż«Ż▒Ż«│ę▒╩│ę▒╩▒½(General Purpose GPU) ż╚żŽŻ┐ ? GPU ż╬ėŗ╦Ń┘Yį┤ż“Īó╗ŁŽ±äI└Ēęį═Ōż╬─┐Ą─ż╦ÅĻė├ż╣żļ╝╝ąg
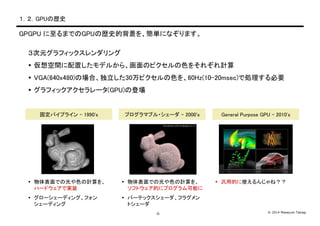
- 4. ? 2014 Masayuki Takagi-3- Ż▒Ż«Ż▓Ż«GPUż╬Üs╩Ę Ż│┤╬į¬ź░źķźšźŻź├ź»ź╣źņź¾ź└źĻź¾ź░ ? üóŽļ┐šķgż╦┼õų├żĘż┐źŌźŪźļż½żķĪó╗Ł├µż╬źįź»ź╗źļż╬╔½ż“żĮżņżŠżņėŗ╦Ń ? VGA(640x480)ż╬ł÷║ŽĪóČ└┴óżĘż┐30═“źįź»ź╗źļż╬╔½ż“Īó60Hz(10-20msec)żŪäI└Ēż╣żļ▒žę¬ ? ź░źķźšźŻź├ź»źóź»ź╗źķźņ®`ź┐(GPU)ż╬ĄŪł÷ GPGPU ż╦ų┴żļż▐żŪż╬GPUż╬Üs╩ĘĄ─▒│Š░ż“Īó║åģgż╦ż╩żŠżĻż▐ż╣ĪŻ ╣╠Č©źčźżźūźķźżź¾ - 1990's ? ╬’╠Õ▒Ē├µżŪż╬╣Ōżõ╔½ż╬ėŗ╦Ńż“Īó źŽ®`ź╔ź”ź¦źóżŪīgū░ ? ź░źĒ®`źĘź¦®`źŪźŻź¾ź░Īóźšź®ź¾ źĘź¦®`źŪźŻź¾ź░ źūźĒź░źķź▐źųźļ?źĘź¦®`ź└ - 2000's ? ╬’╠Õ▒Ē├µżŪż╬╣Ōżõ╔½ż╬ėŗ╦Ńż“Īó źĮźšź╚ź”ź¦źóĄ─ż╦źūźĒź░źķźÓ┐╔─▄ż╦ ? źą®`źŲź├ź»ź╣źĘź¦®`ź└Īóźšźķź░źßź¾ ź╚źĘź¦®`ź└ General Purpose GPU - 2010's ? Ü°ė├Ą─ż╦╩╣ż©żļż¾żĖżŃż═Ż┐Ż┐
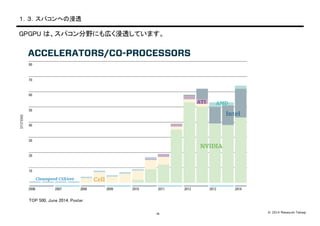
- 5. ? 2014 Masayuki Takagi-4- Ż▒Ż«Ż│Ż«ź╣źčź│ź¾żžż╬Į■═Ė GPGPU żŽĪóź╣źčź│ź¾Ęųę░ż╦żŌÄ┌ż»Į■═ĖżĘżŲżżż▐ż╣ĪŻ TOP 500, June 2014, Poster
- 7. ? 2014 Masayuki Takagi-6- Ż▓Ż«Ż▒Ż«CUDA ż╚żŽŻ┐ ? NVIDIA ż¼╠ß╣®ż╣żļĪóüK┴ąėŗ╦Ńźó®`źŁźŲź»ź┴źŃĪŻNVIDIA ču GPU ż╦żŲäėū„ ? GPUż“└¹ė├żĘż┐ź│źūźĒź╗ź├źĘź¾ź░ż╦żĶż├żŲĪóźŪ®`ź┐üK┴ąż╬ėŗ╦ŃäI└Ē─▄┴”ż“┤¾Ę∙ż╦Ž“╔Ž ? C ź┘®`ź╣ż╬čįšZ(CUDA C)Īóź│ź¾źčźżźķĪóźŪźąź├ź¼ĪóźūźĒźšźĪźżźķż╚żżż├ż┐ĪóźĮźšź╚ź”ź¦źóķ_ ░kŁhŠ│żŌ░³└©Ą─ż╦╠ß╣® Kepler GK110 ż╬ź┴ź├źūą┤šµ
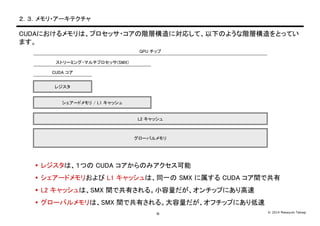
- 8. ? 2014 Masayuki Takagi-7- Ż▓Ż«Ż▓Ż«źūźĒź╗ź├źĄ?źó®`źŁźŲź»ź┴źŃ CUDAżŪżŽĪó┤¾┴┐ż╬źūźĒź╗ź├źĄ?ź│źóż“ĪóęįŽ┬ż╬żĶż”ż╩ļAīėśŗįņż“ż╚żļż│ż╚żŪ╣▄└ĒżĘżŲżżż▐ż╣ĪŻ ? Ż▒ż─ż╬ GPU ź┴ź├źūżŽĪóč}╩²ż╬ź╣ź╚źĻ®`ź▀ź¾ź░?ź▐źļź┴źūźĒź╗ź├źĄ(SMX)ż½żķż╩żļ ? Ż▒ż─ż╬ź╣ź╚źĻ®`ź▀ź¾ź░?ź▐źļź┴źūźĒź╗ź├źĄżŽĪó192 éĆż╬ CUDA ź│źóż╚Ż▒ĮMż╬źšźĒ®`?ź│ź¾ź╚ źĒ®`źķĪó L1 źŁźŃź├źĘźÕż½żķż╩żļ ? č}╩²ż╬ź╣źņź├ź╔ż“ż▐ż╚żßż┐ź╣źņź├ź╔źųźĒź├ź»ż┤ż╚ż╦Īóź╣ź╚źĻ®`ź▀ź¾ź░?ź▐źļź┴źūźĒź╗ź├źĄżŪäI └Ēż╣żļ GTX 680 źųźĒź├ź»ćĒŻ©ę╗▓┐╩Ī┬įŻ®
- 9. ? 2014 Masayuki Takagi-8- Ż▓Ż«Ż│Ż«źßźŌźĻ?źó®`źŁźŲź»ź┴źŃ CUDAż╦ż¬ż▒żļźßźŌźĻżŽĪóźūźĒź╗ź├źĄ?ź│źóż╬ļAīėśŗįņż╦īØÅĻżĘżŲĪóęįŽ┬ż╬żĶż”ż╩ļAīėśŗįņż“ż╚ż├żŲżż ż▐ż╣ĪŻ ? źņźĖź╣ź┐żŽĪóŻ▒ż─ż╬ CUDA ź│źóż½żķż╬ż▀źóź»ź╗ź╣┐╔─▄ ? źĘź¦źó®`ź╔źßźŌźĻż¬żĶżė L1 źŁźŃź├źĘźÕżŽĪó═¼ę╗ż╬ SMX ż╦╩¶ż╣żļ CUDA ź│źóķgżŪ╣▓ėą ? L2 źŁźŃź├źĘźÕżŽĪóSMX ķgżŪ╣▓ėążĄżņżļĪŻąĪ╚▌┴┐ż└ż¼Ī󟬟¾ź┴ź├źūż╦żóżĻĖ▀╦┘ ? ź░źĒ®`źąźļźßźŌźĻżŽĪóSMX ķgżŪ╣▓ėążĄżņżļĪŻ┤¾╚▌┴┐ż└ż¼Ī󟬟šź┴ź├źūż╦żóżĻĄ═╦┘ ź░źĒ®`źąźļźßźŌźĻ L2 źŁźŃź├źĘźÕ źĘź¦źó®`ź╔źßźŌźĻ / L1 źŁźŃź├źĘźÕ źņźĖź╣ź┐ CUDA ź│źó ź╣ź╚źĻ®`ź▀ź¾ź░?ź▐źļź┴źūźĒź╗ź├źĄ(SMX) GPU ź┴ź├źū
- 10. ? 2014 Masayuki Takagi-9- Ż▓Ż«Ż┤Ż«źūźĒź░źķź▀ź¾ź░?źŌźŪźļ CUDA ż╬źūźĒź░źķź▀ź¾ź░?źŌźŪźļżŽĪ󟎮`ź╔ź”ź¦źóż╬źó®`źŁźŲź»ź┴źŃż╦īØÅĻżĘż┐ļAīėśŗįņż╚ż╩ż├żŲżżż▐ ż╣ĪŻ ? C ż“ÆłÅłżĘż┐ CUDA C ż╦żĶż├żŲĪóź½®`ź═źļķv╩²ż“Č©┴xĪŻCUDA ź╣źņź├ź╔ż“śŗ│╔żĘĪóŻ▒ż─ ż╬CUDA ź│źóżŪīgąążĄżņżļĪŻ ? ź╣źņź├ź╔╩²ż╬ųĖČ©ż╚ż╚żŌż╦Īóź½®`ź═źļķv╩²ż“ŲäėĪŻź╣źņź├ź╔źųźĒź├ź»ż“śŗ│╔żĘĪóŻ▒ż─ż╬ź╣ź╚ źĻ®`ź▀ź¾ź░?ź▐źļź┴źūźĒź╗ź├źĄ(SMX)żŪīgąążĄżņżļĪŻ ? üK┴ąČ╚ż¼Ė▀ż»Ż▒ż─ż╬ź╣źņź├ź╔źųźĒź├ź»ż╦ģ¦ż▐żķż╩żżł÷║ŽĪóč}╩²ż╬ź╣źņź├ź╔źųźĒź├ź»ż“ż▐ż╚żß ż┐ź░źĻź├ź╔ż“╩╣żżĪóč}╩²ż╬ SMX żŪīgąąż╣żļĪŻ
- 12. ? 2014 Masayuki Takagi-11- Ż│Ż«Ż▒Ż«cl-cuda ż╬╠žÅšĄ─ż╩ÖC─▄ cl-cuda żŽĪóCommon Lisp ż½żķ NVIDIA CUDA ż“╩╣ė├ż╣żļż┐żßż╬źķźżźųźķźĻżŪż╣ĪŻęįŽ┬ż╬ÖC─▄ż“╠ß ╣®żĘż▐ż╣ĪŻ ? ź½®`ź═źļķv╩²ż╬Č©┴x ? ź½®`ź═źļėø╩÷čįšZ ? ź½®`ź═źļź▐ź»źĒż╬Č©┴x ? ź½®`ź═źļźŌźĖźÕ®`źļż╬▀Wčėź│ź¾źčźżźļ╝░żė▀WčėźĒ®`ź╔ ? CUDA ź│ź¾źŲźŁź╣ź╚ż╬╣▄└Ē ? ź█ź╣ź╚źßźŌźĻ╝░żėźŪźąźżź╣źßźŌźĻż╬╣▄└Ē ? ź█ź╣ź╚=źŪźąźżź╣ķgż╬źßźŌźĻ▄×╦═ ? OpenGL ŽÓ╗ź▀\ė├
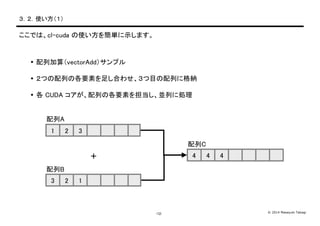
- 13. ? 2014 Masayuki Takagi-12- Ż│Ż«Ż▓Ż«╩╣żżĘĮŻ©Ż▒Ż® ż│ż│żŪżŽĪócl-cuda ż╬╩╣żżĘĮż“║åģgż╦╩ŠżĘż▐ż╣ĪŻ ? ┼õ┴ą╝ė╦ŃŻ©vectorAddŻ®źĄź¾źūźļ ? Ż▓ż─ż╬┼õ┴ąż╬Ė„ę¬╦žż“ūŃżĘ║Žż’ż╗ĪóŻ│ż──┐ż╬┼õ┴ąż╦Ė±╝{ ? Ė„ CUDA ź│źóż¼Īó┼õ┴ąż╬Ė„ę¬╦žż“ĄŻĄ▒żĘĪóüK┴ąż╦äI└Ē ┼õ┴ąA ┼õ┴ąB ┼õ┴ąC 1 2 3 3 2 1 4 4 4+
- 14. ? 2014 Masayuki Takagi-13- Ż│Ż«Ż▓Ż«╩╣żżĘĮŻ©Ż▓Ż® ęįŽ┬ż╬żĶż”ż╩ź│®`ź╔żŪĪóCommon Lisp ż½żķ CUDA ż“╩╣ė├żŪżŁż▐ż╣ĪŻ (defkernel ?vec-?®\add-?®\kernel ?(void ?((a ?float*) ?(b ?float*) ?(c ?float*) ?(n ?int))) ? ?(let ?((i ?(+ ?(* ?block-?®\dim-?®\x ?block-?®\idx-?®\x) ?thread-?®\idx-?®\x))) ? ? ? ?(if ?(< ?i ?n) ? ? ? ? ? ? ? ?(set ?(aref ?c ?i) ? ? ? ? ? ? ? ? ? ? ? ? ?(+ ?(aref ?a ?i) ?(aref ?b ?i)))))) (defun ?main ?() ? ?(let* ?((dev-?®\id ?0) ? ? ? ? ? ? ? ? ?(n ?1024) ? ? ? ? ? ? ? ? ?(threads-?®\per-?®\block ?256) ? ? ? ? ? ? ? ? ?(blocks-?®\per-?®\grid ?(/ ?n ?threads-?®\per-?®\block))) ? ? ? ?(with-?®\cuda ?(dev-?®\id) ? ? ? ? ? ?(with-?®\memory-?®\blocks ?((a ?'float ?n) ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(b ?'float ?n) ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(c ?'float ?n)) ? ? ? ? ? ? ? ?(random-?®\init ?a ?n) ? ? ? ? ? ? ? ?(random-?®\init ?b ?n) ? ? ? ? ? ? ? ?(sync-?®\memory-?®\block ?a ?:host-?®\to-?®\device) ? ? ? ? ? ? ? ?(sync-?®\memory-?®\block ?b ?:host-?®\to-?®\device) ? ? ? ? ? ? ? ?(vec-?®\add-?®\kernel ?a ?b ?c ?n ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?:grid-?®\dim ? ?(list ?blocks-?®\per-?®\grid ?1 ?1) ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?:block-?®\dim ?(list ?threads-?®\per-?®\block ?1 ?1)) ? ? ? ? ? ? ? ?(sync-?®\memory-?®\block ?c ?:device-?®\to-?®\host) ? ? ? ? ? ? ? ?(verify-?®\result ?a ?b ?c ?n))))) ź½®`ź═źļķv╩²ż“Č©┴x CUDA ź│ź¾źŲźŁź╣ź╚ż“╔·│╔ ź█ź╣ź╚ż╚źŪźąźżź╣ż╦ĪóźßźŌźĻŅIė“ż“┤_▒Ż ź█ź╣ź╚źßźŌźĻż½żķźŪźąźżź╣źßźŌźĻżžźŪ®`ź┐ ż“▄×╦═ Č©┴xżĘż┐ź½®`ź═źļķv╩²ż“Ųäė źŪźąźżź╣źßźŌźĻż½żķź█ź╣ź╚źßźŌźĻżžźŪ®`ź┐ ż“▄×╦═
- 15. ? 2014 Masayuki Takagi-14- Ż│Ż«Ż│Ż«─┌▓┐įOėŗ cl-cuda żŽĪóęįŽ┬ż╬Ż│ż─ż╬ź│ź¾ź▌®`ź═ź¾ź╚ż½żķśŗ│╔żĄżņż▐ż╣ĪŻ cl-cuda.api īgļHż╦źµ®`źČż¼└¹ė├ż╣żļźżź¾ź┐®`źšź¦ źżź╣ż“╠ß╣®ĪŻdefkernel ź▐ź»źĒĪóź½®`ź═ źļź▐ź═®`źĖźŃĪóCUDA ź│ź¾źŲźŁź╣ź╚Īóźß źŌźĻźųźĒź├ź»Īóź┐źżź▐ĪŻ cl-cuda.lang ź½®`ź═źļėø╩÷čįšZż╚ĪóżĮż╬ź│ź¾źčźżźķ ż“╠ß╣®ĪŻź│ź¾źčźżźķżŽĪóź½®`ź═źļėø╩÷ čįšZż“ CUDA C żžēõōQż╣żļĪŻCUDA C ż½żķ PTX źšźĪźżźļżžż╬ēõōQżŽĪócl- cuda.api ż╬ź½®`ź═źļź▐ź═®`źĖźŃż¼╣▄ └Ēż╣żļĪŻ cl-cuda.driver-api CUDA ź╔źķźżźą API żžż╬ FFI(Foreign Function Interface)ż“╠ß╣®ĪŻ
- 16. ? 2014 Masayuki Takagi-15- Ż│Ż«Ż┤Ż«ź½®`ź═źļķv╩²ż“Ųäėż╣żļż▐żŪż╬┴„żņ Č©┴xżĘż┐ź½®`ź═źļķv╩²ż“Ųäėż╣żļż▐żŪż╬äI└Ēż╬┴„żņżŽĪóęįŽ┬ż╬żĶż”ż╦ż╩żĻż▐ż╣ĪŻż│żņżķż╬äI└ĒżŽĪó ź½®`ź═źļź▐ź═®`źĖźŃż╦żĶż├żŲ╣▄└ĒżĄżņĪóź│ź¾źčźżźļżõźĒ®`ź╔żŽĪó▒žę¬ż╩ź┐źżź▀ź¾ź░ż▐żŪ▀WčėżĘżŲīgąążĄ żņż▐ż╣ĪŻ 1. ź½®`ź═źļķv╩²ż“Č©┴x defkenrel ź▐ź»źĒż“╩╣ė├żĘżŲĪóź½®`ź═źļķv╩²ż“Č©┴xżĘż▐ ż╣ĪŻ 2. ź½®`ź═źļėø╩÷čįšZż“ź│ź¾źčźżźļ cl-cuda.lang ż╬ź│ź¾źčźżźķż“ė├żżżŲĪóź½®`ź═źļėø╩÷čįšZ ż“ CUDA C żžź│ź¾źčźżźļżĘż▐ż╣ĪŻ 3. CUDA C ż“ź│ź¾źčźżźļ NVIDIA ż╬╠ß╣®ż╣żļ NVCC (NVIDIA CUDA Compiler) ż“║¶żė│÷żĘĪóCUDA C ż╬ź│®`ź╔ż“ź½®`ź═źļźŌźĖźÕ®`źļ (PTX źšźĪźżźļ)żžź│ź¾źčźżźļżĘż▐ż╣ĪŻ 4. ź½®`ź═źļźŌźĖźÕ®`źļż“źĒ®`ź╔ CUDA ź╔źķźżźą API ż“╩╣ė├żĘżŲĪóź½®`ź═źļźŌźĖźÕ®`źļż“ źĒ®`ź╔żĘż▐ż╣ĪŻ 5. ź½®`ź═źļķv╩²ż“źĒ®`ź╔ CUDA ź╔źķźżźą API ż“╩╣ė├żĘżŲĪóŲäėżĘż┐żżź½®`ź═źļ ķv╩²ż“źĒ®`ź╔żĘż▐ż╣ĪŻ 6. ę²╩²ż╚żĘżŲČ╔ż╣éÄż“┼õ┴ąż╦Ė±╝{ ę²╩²ż╚żĘżŲ GPU ż╦Č╔ż╣éÄż“Ė±╝{żĘż┐┼õ┴ąż“ė├ęŌżĘż▐ ż╣ĪŻ 7. ź½®`ź═źļķv╩²ż“Ųäė CUDA ź╔źķźżźą API ż“╩╣ė├żĘżŲĪóź½®`ź═źļķv╩²ż“Ųäė żĘż▐ż╣ĪŻ
- 17. ? 2014 Masayuki Takagi-16- Ż│Ż«ŻĄŻ«źŪźŌ Nbody źĘź▀źÕźņ®`źĘźńź¾ (:ql ?:cl-?®\cuda-?®\interop-?®\examples) (cl-?®\cuda-?®\interop-?®\examples.nbody:main ?:gpu ?t ?:interop ?t)
- 18. ? 2014 Masayuki Takagi-17- Ż│Ż«ŻČŻ«źčźšź®®`ź▐ź¾ź╣▒╚▌^ GPU ż“└¹ė├żĘżŲüK┴ąėŗ╦Ńż╣żļż│ż╚żŪĪóCPU żŪż╬ų┤╬äI└Ēż╦īØżĘĪó40▒ČĮ³żżąį─▄Ž“╔Žż¼Ą├żķżņż▐żĘ ż┐ĪŻ x37.5 Amazon EC2 źżź¾ź╣ź┐ź¾ź╣ źūźĒź╗ź├źĄ ź│źó╩² g2.2xlarge g2.2xlarge Xeon E5-2670 2.6GHz NVIDIA GRID K520 1 ź│źó Ż©źĘź¾ź░źļź╣źņź├ź╔ĪóSIMD├³┴Ņ╩╣ė├ż╗ż║Īógcc -O3ŽÓĄ▒Ż® 1,536 ź│źó 4.86[sec] 182.2[sec] SPH(Smoothed Particle Hydrodynamics) ż╦żĶżļ┴„╠ÕźĘź▀źÕźņ®`źĘźńź¾ 11,774┴Żūė
- 19. ? 2014 Masayuki Takagi-18- Ż│Ż«ŻĘŻ«źņź▌źĖź╚źĻ cl-cuda żŽĪóGitHub ż½żķ╚ļ╩ųżŪżŁż▐ż╣ĪŻQuicklispżŽĪóżĮż╬źŲź╣ź╚ź▌źĻźĘ®`ż╬Č╝║Ž╔ŽĪóĄŪÕh▓╗┐╔żŪżĘż┐ĪŻ https://github.com/takagi/cl-cuda/