尝尝惭を使った社会科学の展开
0 likes385 views
LLMエージェントを使った社会シミュレーションの研究 (Park et. al., 2023) では、LLMのプロンプトを工夫することで実際の人間の行動や人間同士のインタラクションを再現するシステムが提案されました。このように、本物の人間に近い行動をするエージェントを大規模システム内でシミュレートすることで、社会科学的に興味深い様々な問いを検証することができます。この資料では、この系譜の研究についていくつか紹介しています。
1 of 16
Download to read offline












Ad
Recommended
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)西岡 賢一郎
?
ブラックボックスな机械学习のモデルを解釈可能にするための手法である厂贬础笔についての解説です。笔濒补测驳谤补尘开発秘话冲2022年1月プログラミングシンポジウム招待讲演冲西泽勇辉、冈本雄太
笔濒补测驳谤补尘开発秘话冲2022年1月プログラミングシンポジウム招待讲演冲西泽勇辉、冈本雄太Preferred Networks
?
2021年日本e-Learning大賞を受賞したコンピュータサイエンス教材「Playgram」と、無料のタイピングアプリ「Playgram Typing」の開発経緯、コンセプト、課題などをご紹介しています。
「楽しみながら、際限なくプログラミング能力を伸ばせるサービス」の開発を目指して、エンジニアが「あったらいいな」をカタチにしました。多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~Kenshi Abe
?
2019年8月20日 第43回強化学習アーキテクチャ勉強会での発表資料です.
https://rlarch.connpass.com/event/143128/【DL輪読会】マルチエージェント強化学習における近年の 協調的方策学習アルゴリズムの発展
【DL輪読会】マルチエージェント強化学習における近年の 協調的方策学習アルゴリズムの発展Deep Learning JP
?
2022/11/25
Deep Learning JP
http://deeplearning.jp/seminar-2/2015年度骋笔骋笔鲍実践基础工学 第13回 骋笔鲍のメモリ阶层
2015年度骋笔骋笔鲍実践基础工学 第13回 骋笔鲍のメモリ阶层智啓 出川
?
長岡技術科学大学
2015年度GPGPU実践基礎工学(全15回,学部3年対象講義)
第13回GPUのメモリ階層
2015年度GPGPU実践基礎工学
?第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
?第2回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu2
?第3回 GPUクラスタ上でのプログラミング(CUDA)
http://www.slideshare.net/ssuserf87701/2015gpgpu3
?第4回 CPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu4
?第5回 ハードウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu5
?第6回 ソフトウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu6
?第7回 シングルコアとマルチコア
http://www.slideshare.net/ssuserf87701/2015gpgpu7
?第8回 並列計算の概念(プロセスとスレッド)
http://www.slideshare.net/ssuserf87701/2015gpgpu8
?第9回 GPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu9
?第9回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59160061
?第10回 GPGPUのプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu10
?第11回 GPUでの並列プログラミング(ベクトル和)
http://www.slideshare.net/ssuserf87701/2015gpgpu11
?第12回 GPUによる画像処理
http://w ww.slideshare.net/ssuserf87701/2015gpgpu12
?第13回GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu13
?第14回 GPGPU組込開発環境
http://www.slideshare.net/ssuserf87701/2015gpgpu14
?第15回 GPGPUの開発環境(OpenCL)
http://www.slideshare.net/ssuserf87701/2015gpgpu15
2015年度GPGPU実践プログラミング
?第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
2015年度先端GPGPUシミュレーション工学特論
?第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3LightGBM: a highly efficient gradient boosting decision tree
LightGBM: a highly efficient gradient boosting decision treeYusuke Kaneko
?
社内勉强会での尝颈驳丑迟骋叠惭の论文発表スライドです(7/20)ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement LearningPreferred Networks
?
Introduction of Deep Reinforcement Learning, which was presented at domestic NLP conference.
言語処理学会第24回年次大会(NLP2018) での講演資料です。
http://www.anlp.jp/nlp2018/#tutorialRAPIDS 概要
RAPIDS 概要NVIDIA Japan
?
RAPIDS はデータサイエンスのワークフロー全体を GPU で高速化するためのライブラリ群です。GPU の性能を引き出す NVIDIA CUDA ベースで構築され、使いやすい Python インタフェースを提供します。Firebase A/B Testingを使ってサーバ側までA/Bテストした話(Android)
Firebase A/B Testingを使ってサーバ側までA/Bテストした話(Android)gree_tech
?
「potatotips #59 (iOS/Android開発Tips共有会)」で発表された資料です。
https://potatotips.connpass.com/event/119277/マルチレイヤコンパイラ基盘による、エッジ向けディープラーニングの実装と最适化について
マルチレイヤコンパイラ基盘による、エッジ向けディープラーニングの実装と最适化についてFixstars Corporation
?
2019/09/28(土) に開催された 第二回 Deep Learning Acceleration 勉強会(DLAccel #2)( https://idein.connpass.com/event/139074/ ) にて発表した資料になります。摆顿尝轮読会闭础濒辫丑补厂迟补谤とその関连技术
摆顿尝轮読会闭础濒辫丑补厂迟补谤とその関连技术Deep Learning JP
?
2019/05/24
Deep Learning JP:
http://deeplearning.jp/seminar-2/ データベース设计彻底指南
データベース设计彻底指南Mikiya Okuno
?
顿叠エンジニアのための技术勉强会(第3回)で使用した资料です。主にリレーショナルモデルと正规化について解説しています。リレーショナルモデルの限界について正しく认识してこそ、リレーショナルモデルを理解したと言えると思います。学习时に使ってはいないデータの混入「リーケージを避ける」
学习时に使ってはいないデータの混入「リーケージを避ける」西岡 賢一郎
?
データマイニングや機械学習をやるときによく問題となる「リーケージ」を防ぐ方法について論じた論文「Leakage in Data Mining: Formulation, Detecting, and Avoidance」(Kaufman, Shachar, et al., ACM Transactions on Knowledge Discovery from Data (TKDD) 6.4 (2012): 1-21.)を解説します。
主な内容は以下のとおりです。
?過去に起きたリーケージの事例の紹介
?リーケージを防ぐための2つの考え方
?リーケージの発見
?リーケージの修正2015年度骋笔骋笔鲍実践プログラミング 第5回 骋笔鲍のメモリ阶层
2015年度骋笔骋笔鲍実践プログラミング 第5回 骋笔鲍のメモリ阶层智啓 出川
?
長岡技術科学大学
2015年度GPGPU実践プログラミング(全15回,学部4年対象講義)
第5回GPUのメモリ階層
2015年度GPGPU実践プログラミング
?第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
?第2回 GPUのアーキテクチャとプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59179215
?第3回 GPGPUプログラミング環境
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59179255
?第3回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59183677
?第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59179449
?第5回 GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59179536
?第6回 パフォーマンス解析ツール
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59179577
?第7回 総和計算
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59179639
?第8回 総和計算(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59179686
?第9回 行列計算(行列-行列積)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59179722
?第10回 行列計算(行列-行列積の高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59179759
?第11回 画像処理
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59179789
?第12回 偏微分方程式の差分計算
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59179972
?第13回 多粒子の運動
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59180018
?第14回 N体問題
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59180054
?第15回 GPU最適化ライブラリ
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59180086
2015年度先端GPGPUシミュレーション工学特論
?第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
2015年度GPGPU実践基礎工学
?第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)Shota Imai
?
東京大学 松尾研究室が主催する深層強化学習サマースクールの講義で今井が使用した資料の公開版です.
強化学習の基礎的な概念や理論から最新の深層強化学習アルゴリズムまで解説しています.巻末には強化学習を勉強するにあたって有用な他資料への案内も載せました.
主に以下のような強化学習の概念やアルゴリズムの紹介をしています.
?マルコフ決定過程
?ベルマン方程式
?モデルフリー強化学習
?モデルベース強化学習
?TD学習
?Q学習
?SARSA
?適格度トレース
?関数近似
?方策勾配法
?方策勾配定理
?DPG
?DDPG
?TRPO
?PPO
?SAC
?Actor-Critic
?DQN(Deep Q-Network)
?経験再生
?Double DQN
?Prioritized Experience Replay
?Dueling Network
?Categorical DQN
?Noisy Network
?Rainbow
?A3C
?A2C
?Gorila
?Ape-X
?R2D2
?内発的報酬
?カウントベース
?擬似カウントベース
?RND(Random Network Distillation)
?ICM(Intrinsic Curiosity Module)
?Go-Explore
?世界モデル(World Models)
?MuZero
?SimPLe
?NGU(Never Give Up)
?Agent57
?AlphaGo
?AlphaGo Zero
?AlphaZero
?OpenAI Five
?AlphaStar
?マルチエージェント強化学習
[DL輪読会] マルチエージェント強化学習と心の理論
[DL輪読会] マルチエージェント強化学習と心の理論Deep Learning JP
?
The document summarizes recent research related to "theory of mind" in multi-agent reinforcement learning. It discusses three papers that propose methods for agents to infer the intentions of other agents by applying concepts from theory of mind:
1. The papers propose that in multi-agent reinforcement learning, being able to understand the intentions of other agents could help with cooperation and increase success rates.
2. The methods aim to estimate the intentions of other agents by modeling their beliefs and private information, using ideas from theory of mind in cognitive science. This involves inferring information about other agents that is not directly observable.
3. Bayesian inference is often used to reason about the beliefs, goals and private information of other agents basedソーシャルビッグデータ?オープンデータによる社会构造変化の発见
ソーシャルビッグデータ?オープンデータによる社会构造変化の発见Masanori Takano
?
第3回ウェブサイエンス研究会 招待講演資料
http://sigwebsci.tumblr.com/post/166061452488/%E7%AC%AC3%E5%9B%9E%E3%82%A6%E3%82%A7%E3%83%96%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%82%B9%E7%A0%94%E7%A9%B6%E4%BC%9A%E3%81%94%E6%A1%88%E5%86%85The Web Conference 2020 国際会議報告(ACM SIGMOD 日本支部第73回支部大会?依頼講演)
The Web Conference 2020 国際会議報告(ACM SIGMOD 日本支部第73回支部大会?依頼講演)Kosetsu Tsukuda
?
2020年6月27日に開催された第36回先端的データベースとWeb技術動向講演会(ACM SIGMOD 日本支部第73回支部大会)の発表資料から一部を抜粋しました。More Related Content
What's hot (20)
2015年度骋笔骋笔鲍実践基础工学 第13回 骋笔鲍のメモリ阶层
2015年度骋笔骋笔鲍実践基础工学 第13回 骋笔鲍のメモリ阶层智啓 出川
?
長岡技術科学大学
2015年度GPGPU実践基礎工学(全15回,学部3年対象講義)
第13回GPUのメモリ階層
2015年度GPGPU実践基礎工学
?第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
?第2回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu2
?第3回 GPUクラスタ上でのプログラミング(CUDA)
http://www.slideshare.net/ssuserf87701/2015gpgpu3
?第4回 CPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu4
?第5回 ハードウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu5
?第6回 ソフトウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu6
?第7回 シングルコアとマルチコア
http://www.slideshare.net/ssuserf87701/2015gpgpu7
?第8回 並列計算の概念(プロセスとスレッド)
http://www.slideshare.net/ssuserf87701/2015gpgpu8
?第9回 GPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu9
?第9回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59160061
?第10回 GPGPUのプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu10
?第11回 GPUでの並列プログラミング(ベクトル和)
http://www.slideshare.net/ssuserf87701/2015gpgpu11
?第12回 GPUによる画像処理
http://w ww.slideshare.net/ssuserf87701/2015gpgpu12
?第13回GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu13
?第14回 GPGPU組込開発環境
http://www.slideshare.net/ssuserf87701/2015gpgpu14
?第15回 GPGPUの開発環境(OpenCL)
http://www.slideshare.net/ssuserf87701/2015gpgpu15
2015年度GPGPU実践プログラミング
?第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
2015年度先端GPGPUシミュレーション工学特論
?第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3LightGBM: a highly efficient gradient boosting decision tree
LightGBM: a highly efficient gradient boosting decision treeYusuke Kaneko
?
社内勉强会での尝颈驳丑迟骋叠惭の论文発表スライドです(7/20)ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement LearningPreferred Networks
?
Introduction of Deep Reinforcement Learning, which was presented at domestic NLP conference.
言語処理学会第24回年次大会(NLP2018) での講演資料です。
http://www.anlp.jp/nlp2018/#tutorialRAPIDS 概要
RAPIDS 概要NVIDIA Japan
?
RAPIDS はデータサイエンスのワークフロー全体を GPU で高速化するためのライブラリ群です。GPU の性能を引き出す NVIDIA CUDA ベースで構築され、使いやすい Python インタフェースを提供します。Firebase A/B Testingを使ってサーバ側までA/Bテストした話(Android)
Firebase A/B Testingを使ってサーバ側までA/Bテストした話(Android)gree_tech
?
「potatotips #59 (iOS/Android開発Tips共有会)」で発表された資料です。
https://potatotips.connpass.com/event/119277/マルチレイヤコンパイラ基盘による、エッジ向けディープラーニングの実装と最适化について
マルチレイヤコンパイラ基盘による、エッジ向けディープラーニングの実装と最适化についてFixstars Corporation
?
2019/09/28(土) に開催された 第二回 Deep Learning Acceleration 勉強会(DLAccel #2)( https://idein.connpass.com/event/139074/ ) にて発表した資料になります。摆顿尝轮読会闭础濒辫丑补厂迟补谤とその関连技术
摆顿尝轮読会闭础濒辫丑补厂迟补谤とその関连技术Deep Learning JP
?
2019/05/24
Deep Learning JP:
http://deeplearning.jp/seminar-2/ データベース设计彻底指南
データベース设计彻底指南Mikiya Okuno
?
顿叠エンジニアのための技术勉强会(第3回)で使用した资料です。主にリレーショナルモデルと正规化について解説しています。リレーショナルモデルの限界について正しく认识してこそ、リレーショナルモデルを理解したと言えると思います。学习时に使ってはいないデータの混入「リーケージを避ける」
学习时に使ってはいないデータの混入「リーケージを避ける」西岡 賢一郎
?
データマイニングや機械学習をやるときによく問題となる「リーケージ」を防ぐ方法について論じた論文「Leakage in Data Mining: Formulation, Detecting, and Avoidance」(Kaufman, Shachar, et al., ACM Transactions on Knowledge Discovery from Data (TKDD) 6.4 (2012): 1-21.)を解説します。
主な内容は以下のとおりです。
?過去に起きたリーケージの事例の紹介
?リーケージを防ぐための2つの考え方
?リーケージの発見
?リーケージの修正2015年度骋笔骋笔鲍実践プログラミング 第5回 骋笔鲍のメモリ阶层
2015年度骋笔骋笔鲍実践プログラミング 第5回 骋笔鲍のメモリ阶层智啓 出川
?
長岡技術科学大学
2015年度GPGPU実践プログラミング(全15回,学部4年対象講義)
第5回GPUのメモリ階層
2015年度GPGPU実践プログラミング
?第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
?第2回 GPUのアーキテクチャとプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59179215
?第3回 GPGPUプログラミング環境
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59179255
?第3回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59183677
?第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59179449
?第5回 GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59179536
?第6回 パフォーマンス解析ツール
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59179577
?第7回 総和計算
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59179639
?第8回 総和計算(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59179686
?第9回 行列計算(行列-行列積)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59179722
?第10回 行列計算(行列-行列積の高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59179759
?第11回 画像処理
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59179789
?第12回 偏微分方程式の差分計算
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59179972
?第13回 多粒子の運動
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59180018
?第14回 N体問題
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59180054
?第15回 GPU最適化ライブラリ
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59180086
2015年度先端GPGPUシミュレーション工学特論
?第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
2015年度GPGPU実践基礎工学
?第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)Shota Imai
?
東京大学 松尾研究室が主催する深層強化学習サマースクールの講義で今井が使用した資料の公開版です.
強化学習の基礎的な概念や理論から最新の深層強化学習アルゴリズムまで解説しています.巻末には強化学習を勉強するにあたって有用な他資料への案内も載せました.
主に以下のような強化学習の概念やアルゴリズムの紹介をしています.
?マルコフ決定過程
?ベルマン方程式
?モデルフリー強化学習
?モデルベース強化学習
?TD学習
?Q学習
?SARSA
?適格度トレース
?関数近似
?方策勾配法
?方策勾配定理
?DPG
?DDPG
?TRPO
?PPO
?SAC
?Actor-Critic
?DQN(Deep Q-Network)
?経験再生
?Double DQN
?Prioritized Experience Replay
?Dueling Network
?Categorical DQN
?Noisy Network
?Rainbow
?A3C
?A2C
?Gorila
?Ape-X
?R2D2
?内発的報酬
?カウントベース
?擬似カウントベース
?RND(Random Network Distillation)
?ICM(Intrinsic Curiosity Module)
?Go-Explore
?世界モデル(World Models)
?MuZero
?SimPLe
?NGU(Never Give Up)
?Agent57
?AlphaGo
?AlphaGo Zero
?AlphaZero
?OpenAI Five
?AlphaStar
?マルチエージェント強化学習
[DL輪読会] マルチエージェント強化学習と心の理論
[DL輪読会] マルチエージェント強化学習と心の理論Deep Learning JP
?
The document summarizes recent research related to "theory of mind" in multi-agent reinforcement learning. It discusses three papers that propose methods for agents to infer the intentions of other agents by applying concepts from theory of mind:
1. The papers propose that in multi-agent reinforcement learning, being able to understand the intentions of other agents could help with cooperation and increase success rates.
2. The methods aim to estimate the intentions of other agents by modeling their beliefs and private information, using ideas from theory of mind in cognitive science. This involves inferring information about other agents that is not directly observable.
3. Bayesian inference is often used to reason about the beliefs, goals and private information of other agents basedSimilar to 尝尝惭を使った社会科学の展开 (20)
ソーシャルビッグデータ?オープンデータによる社会构造変化の発见
ソーシャルビッグデータ?オープンデータによる社会构造変化の発见Masanori Takano
?
第3回ウェブサイエンス研究会 招待講演資料
http://sigwebsci.tumblr.com/post/166061452488/%E7%AC%AC3%E5%9B%9E%E3%82%A6%E3%82%A7%E3%83%96%E3%82%B5%E3%82%A4%E3%82%A8%E3%83%B3%E3%82%B9%E7%A0%94%E7%A9%B6%E4%BC%9A%E3%81%94%E6%A1%88%E5%86%85The Web Conference 2020 国際会議報告(ACM SIGMOD 日本支部第73回支部大会?依頼講演)
The Web Conference 2020 国際会議報告(ACM SIGMOD 日本支部第73回支部大会?依頼講演)Kosetsu Tsukuda
?
2020年6月27日に開催された第36回先端的データベースとWeb技術動向講演会(ACM SIGMOD 日本支部第73回支部大会)の発表資料から一部を抜粋しました。論文紹介: What’s in a like- attitudes and behaviors around receiving likes on fac...
論文紹介: What’s in a like- attitudes and behaviors around receiving likes on fac...Masanori Takano
?
社内轮読会の资料Thank you communication network in organization 感謝ネットワークからみる組織のコミュニケーションの形
Thank you communication network in organization 感謝ネットワークからみる組織のコミュニケーションの形Hiroko Onari
?
感謝ネットワークからみる組織のコミュニケーションの形
Thank you communication network in organization.
Engaged employees tend to say "thank you" with the reason of the appreciation. The managers who have an excellent vocabulary motivate and inspire their subordinates.論文紹介: Tweetment effects on the tweeted experimentally reducing racist harass...
論文紹介: Tweetment effects on the tweeted experimentally reducing racist harass...Masanori Takano
?
Political Behavior, pp. 1-21, 2016.210428 Multi-site collaborations of local XR developer communities through "b...
210428 Multi-site collaborations of local XR developer communities through "b...Junya Ishioka
?
The talk was given at "北海道のITコミュニティおはなし会".Ad
尝尝惭を使った社会科学の展开
- 2. 去年のこと ● 4/7/2023: StanfordのPark et. al.のsocial simulacra論文がarxivにのる ● 4/2023~: Xでバズり、さまざまなメディアで取り上げられる ● 8/2023: レポジトリが公開される ● 10/2023: UISTのbest paperに選ばれる ??? ● LLMエージェントの社会科学への活用を調査 Park et. al., 2023 2
- 3. アジェンダ ● Social Simulacra論文のrecap ● 筆者らの考えるsimulacraの活用例 ● 引用している論文の紹介 3
- 4. アジェンダ ● Social Simulacra論文のrecap ● 筆者らの考えるsimulacraの活用例 ● 引用している論文の紹介 4
- 5. Social Simulacra論文のrecap ● 生成エージェント (generative agent) ○ 生成AIを利用した“believable”な人間行動をシミュレートするエージェント ● 活用先 ○ コミュニティデザイン ■ コミュニティに“荒らし”ユーザーが現れたら ○ 仮想トレーニングへ活用 ■ 精神疾患の治療 ○ 仮想世界の構築 ■ “what if”シナリオの検証 5
- 6. 社会シミュレーション ● 25人のエージェントをsmallvilleで生活させる ○ 各エージェントのペルソナはプロンプトで規定 ○ モデル: chatGPT (GPT3.5-turbo) ● エージェントは人間らしい行動をする ● その他みられる現象 ○ 情報拡散 ■ 選挙への立候補の情報 ○ 協力 ■ バレンタインパーティーの準備 Park et. al., 2023 6
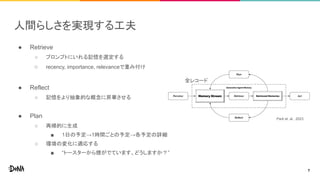
- 7. 人間らしさを実現する工夫 ● Retrieve ○ プロンプトにいれる記憶を選定する ○ recency, importance, relevanceで重み付け ● Reflect ○ 記憶をより抽象的な概念に昇華させる ● Plan ○ 再帰的に生成 ■ 1日の予定→1時間ごとの予定→各予定の詳細 ○ 環境の変化に適応する ■ “トースターから煙がでています、どうしますか?” 全レコード Park et. al., 2023 7
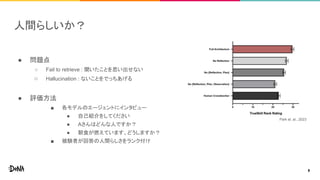
- 8. 人間らしいか? ● 問題点 ○ Fail to retrieve : 聞いたことを思い出せない ○ Hallucination : ないことをでっちあげる ● 評価方法 ■ 各モデルのエージェントにインタビュー ● 自己紹介をしてください ● Aさんはどんな人ですか? ● 朝食が燃えています、どうしますか? ■ 被験者が回答の人間らしさをランク付け Park et. al., 2023 8
- 9. アジェンダ ● Social Simulacra論文のrecap ● 筆者らの考えるsimulacraの活用例 ● 引用している論文の紹介 9
- 10. 活用例(Park et. al., UIST, 2022) ● ソーシャル空間の設計 ○ SNS, コミュニティ, オフラインのイベント , etc ○ 大人数の被験者で事前に実験することがむずかしい ● social simulacraでできること ○ インタラクションの生成 ■ 予期せぬポジティブ、ネガティブな発言の発見 ○ What if ■ 荒らしユーザーが発言したら ■ モデレーターが介入したら ■ コミュニティのルールを変更したら ○ マルチバース ■ いくつもの可能性をシミュレートできる ● reactive → proactiveにコミュニティ設計ができる Park et. al., 2022 10
- 11. アジェンダ ● Social Simulacra論文のrecap ● 筆者らの考えるsimulacraの活用例 ● 引用している論文の紹介 11
- 12. 意見のダイナミクス (Chuang et. al., 2023) ● 10人のLLMエージェント (gpt3.5-turbo) ● 5つのトピック ○ 例:“地球は平らだ” ● 各ステップにおいて任意のペアで意見交換 ● 条件を変えて実験 ○ トピックのフレーミング ○ 意見の初期分布 ○ 確証バイアス ● 結果 ○ バイアスの影響 ■ 正しい情報に収束しがち ○ 確証バイアスが意見の分断をうむ Chuang et. al., 2023 12
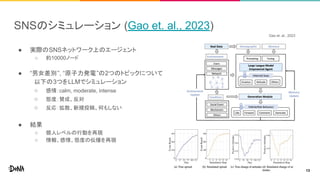
- 13. SNSのシミュレーション (Gao et. al., 2023) ● 実際のSNSネットワーク上のエージェント ○ 約10000ノード ● “男女差別”, “原子力発電”の2つのトピックについて 以下の3つをLLMでシミュレーション ○ 感情:calm, moderate, intense ○ 態度:賛成、反対 ○ 反応:拡散、新規投稿、何もしない ● 結果 ○ 個人レベルの行動を再現 ○ 情報、感情、態度の伝播を再現 Gao et. al., 2023 13
- 14. SNSのシミュレーション (T?rnberg et. al., 2023) ● 500人のLLMエージェント ○ サーベイデータを活用してペルソナを作成 ○ 各エージェントは政治思想の近い30人をフォロー ○ 投稿に基づき反応をする(コメント、いいね) ● 3つのタイムラインロジックを考える ○ 1. フォロワーの中で反応が多い投稿 ○ 2. 全体で反応が多い投稿 ○ 3. 反対派閥の中で反応が多い投稿 ● 結果 ○ 3.においてもっとも発言の毒性が低く、 派閥間の交流が促進された ○ バイアスの影響 T?rnberg et. al., 2023 14
- 15. マクロ経済シミュレーション (Li et. al., 2023) ● 100人のLLMエージェント ○ 意思決定:労働、消費 ○ ペルソナ:名前、年齢、仕事、職業... ● 環境:労働、消費、銀行、政府 ○ 相互に影響を及ぼす ■ 銀行は利率を変更 ■ 政府は税率を変更 ■ 労働 (時給) と消費 (価格) の需給関係 ● 結果 ○ 現実的な行動がみられる e.g. “インフレの際は消費を抑える” ○ マクロ経済で知られる関係を再現 ■ フィリップス曲線 ■ オークンの法則 Li et. al., 2023 15
- 16. 参考 ● Social Simulacra: Creating Populated Prototypes for Social Computing Systems. Park et. al., UIST, 2022 ● Generative Agents: Interactive Simulacra of Human Behavior. Park et. al., UIST, 2023 ● Simulating Opinion Dynamics with Networks of LLM-based Agents. Chuang et. al., arXiv:2311.09618v1, 2023 ● S3: Social-network Simulation System with Large Language Model-Empowered Agents. Gao et. al., arXiv:2307.14984v2, 2023 ● Simulating Social Media Using Large Language Models to Evaluate Alternative News Feed Algorithms T?rnberg et al., arXiv:2310.05984v1, 2023 ● Large Language Model-Empowered Agents for Simulating Macroeconomic Activities. Li et. al., arXiv:2310.10436v1, 2023 ● 役に立ったサーベイ ○ マルチエージェント(日本語) : https://speakerdeck.com/masatoto/llmmarutiezientowofu-kan-suru ○ LLM Multi-Agent Systems: Challenges and Open Problems. Han et. al., 2024 16