Ltc completed slides
?Download as PPTX, PDF?
1 like?454 views

This document discusses the use of latent semantic analysis (LSA) for document clustering. It describes issues with traditional information retrieval systems, defines key concepts like synonymy and polysemy, and explains how LSA addresses these issues by reducing the semantic space. An experiment is described where documents are clustered with and without LSA preprocessing, showing that LSA leads to improved cluster quality metrics like purity, entropy, and average intra-cluster similarity. The study demonstrates LSA can perform comparably to dedicated clustering tools for organizing documents by topic.




























![? Hofmann,T (1999). Probabilistic latent
semantic indexing. In Proceedings of the
22nd annual international ACM SIGIR
conference on Research and development in
information retrieval (SIGIR '99). ACM, New
York, NY, USA, 50-57.
? Hong,J.(2000). Overview of Latent Semantic
Indexing. Available [online] at :
http://www.contentanalyst.com/images/ima
ges/overview_LSI.pdf . Last accessed on 30th
September, 2010.
? Karypis,G.,(2003). CLUTO* A Clustering
toolkit.Release 2.1.1. Technical Report: #02-
017.Department of Computer
Science, University of Minneapolis.](https://image.slidesharecdn.com/ltccompletedslides-130320064749-phpapp01/85/Ltc-completed-slides-30-320.jpg)

![? Zaiane, O. (1999). Principles of Knowledge
Discovery in databases, chapter 8: Data
Clustering, lecturing slides for CmPUT
690, University of Alberta. Available
[online]at:
http://www.cs.ualberta.ca/~zaiane/courses
/cmput690/slides/chapter 8/.
? Zhao, Y and Karypis G. (2001). Criterion
Functions for Document Clustering:
Experiments and Analysis. Technical Report
#01-40, Department of Computer
Science, University of Minneapolis.](https://image.slidesharecdn.com/ltccompletedslides-130320064749-phpapp01/85/Ltc-completed-slides-32-320.jpg)
Ltc completed slides
- 1. Roseline Antai Chris Fox Udo Kruchswitz University of Essex, UK.
- 2. ? Problems in retrieval systems ? Latent Semantic Analysis ? Clustering ? Experiment ? Results ? Evaluation ? Conclusion
- 3. ? Information retrieval systems which use traditional search approaches are plagued by issues like: ? Noise ? Polysemy ? Synonymy ? Leading to reduced accuracy in retrieved documents
- 4. ? What is Synonymy? ? Simply :- the semantic relation that holds between two words that can (in a given context) express the same meaning. ? Arises from the diversity which exist in the words people use to define or express the same object or concept. ? Less than 20% of the instances in which two people use the same major keyword for a certain object (Deerwester et al ,1990). ? Example :- °∞Automobiles°± , °∞cars°±, °∞vehicles°±.
- 5. ?What is polysemy? ? Simply:- the ambiguity of an individual word or phrase that can be used (in different contexts) to express two or more different meanings. ? A condition in which words have more than one unique meaning (Deerwester,1990). ? Example:- the word °∞bank°±.
- 6. ? A statistical information retrieval technique, designed to reduce the problems of polysemy and synonymy in information retrieval (Hong, 2000). ? A technique used for automatic indexing and retrieval, which takes advantage of the semantic structure in correlating terms with documents, to improve the retrieval of documents of relevance to a certain query . ? Designed to solve the problems encountered in keyword matching systems. (Deerwester et al, 1990).
- 7. ? Defined also as a method used for comparing texts, through the use of a vector-based representation, learned from the body of the documents. Used to create vector-based representations of texts claimed to capture the semantic content of such texts (Weimer- Hastings, 1999).
- 8. ? Improves upon the traditional Vector space model. ? Is concerned with dimension reduction ? Identified as the major strength of LSA, defined by Dumais et al (1988) as a technique bearing a close resemblance to eigenvector decomposition and factor analysis, which takes a large matrix say, ?X?, which is the association matrix of terms to documents, and then decomposes this matrix into a set of orthogonal factors, usually in the range of 50-150 factors, which can yield an approximate of the original matrix if linearly combined.
- 9. ? SVD creates a semantic space from the original matrix, decomposes it into the left and right singular vector matrices, and a diagonal matrix of singlular values. ? The semantic space is made up of a term by concept space, which is the left singular vector matrix, the concept by document space, which is the right singular vector matrix, and the third matrix, the concept by concept space, which is the diagonal matrix. Paulsen and Ramampiaro (2009)
- 10. ?X °÷X^ =USVT ? S ®C diagonal matrix of Singular values. ? U- Term by concept space matrix. ? V- Document by concept space matrix.
- 11. ? Probabilistic Latent Semantic Analysis (PLSA) ? An approach to automated document indexing based on the statistical latent class model for factor analysis for count data (Hofman,1999). ? More solid statistical foundation ? Defines proper generative data model ? Latent Dirichlet Allocation (LDA) ? Generative probabilistic model ? Documents represented as random mixtures over latent topics.
- 12. ? Grouping together objects based their similarity to each other. ? A process of splitting a set of objects into a set of structured sub-classes , bearing a strong similarity to each other, such that they can be safely treated as a group. These sub-classes are referred to as clusters (Zaiane, 1999). ? Document clustering :- A procedure used to divide documents based on a certain criterion, like topics, with the expectation that the clustering process should recognize these topics, and subsequently place the documents in the categories to which they belong (Csorba and Vajk, 2006).
- 13. ? System architecture
- 14. ? Document collection ? comprising 118 documents from four topic areas ; deontics, semantics, evolutionary computing and imperatives. ? Converted from all formats to text files ? Split into two equal parts; 59 documents (training set) and 59 documents (test set). ? jLSIlibrary used for latent sematic analysis. ? Stop words removed.
- 15. ? Clustering (Using CLUTO) ? CLUTO ; a clustering toolkit consisting of a suite of clustering algorithms (partitional and agglomerative, hierarchical and non- hierarchical). ? Used for clustering both high and low dimensional datasets and analyszing features of derived clusters(Karypis, 2003). ? Uses two standalone programs ®C vcluster and scluster.
- 16. ? Baseline ? Clustering of the test set and training set using CLUTO only, without carrying out LSA. ? Optimal dimensionality ? The concept of the existence of an optimal dimensionality for a document collection of a certain size investigated. ? Dimensions used ranged from 2 to 50 dimensions
- 17. ? Baseline result (CLUTO only): Cluster Precision Recall F-Measure 0 0.89 0.85 0.87 1 0.86 1.0 0.92 2 0.83 0.63 0.72 3 0.64 0.82 0.72
- 18. ? The results from clustering with LSA at different dimensions (training set) DIM CLUSTER P R F-MEAS 2 0 0.0 0.0 0.00 1 0.38 0.38 0.38 2 0.75 0.75 0.75 3 0.48 0.83 0.61 5 0 0.71 1.0 0.83 1 0.89 0.8 0.84 2 0.69 0.82 0.75 3 0.81 0.56 0.67 10 0 0.92 1.0 0.96 1 0.41 0.82 0.55 2 0.88 0.75 0.81 3 0.57 0.25 0.35 20 0 0.89 0.73 0.80 1 0.77 0.63 0.69 2 0.67 0.4 0.50 3 0.44 0.92 0.59 30 0 1.0 1.0 1.00 1 0.45 0.82 0.58 2 0.77 0.5 0.61 3 0.29 0.25 0.27 40 0 0.47 0.5 0.48 1 0.57 0.67 0.62 2 0.6 0.3 0.40 3 0.28 0.45 0.34 50 0 0.21 0.27 0.24 1 0.4 0.38 0.39 2 0.5 0.3 0.38 3 0.5 0.75 0.60
- 19. Cluster Precision Recall F-Measure 0 0.5 0.4 0.8 1 0.75 0.6 0.67 2 0.31 0.33 0.32 3 0.50 0.25 0.33
- 20. 1 0.9 0.8 0.7 0.6 0.5 Baseline 0.4 LSA 0.3 0.2 0.1 0 Cluster 0 Cluster 1 Cluster 2 Cluster 3
- 21. ? Purity and Entropy ? Entropy is concerned with the distribution of the different classes of documents within each cluster. ? Purity looks at the extent to which a particular cluster contains documents which are mainly from one class (Zhao and Karypis,2003). ? Low entropy and high purity values indicate a good clustering solution. ? Precision, Recall and F-measure ? Isim ? Displays the average similarity between the objects of each cluster.
- 22. Baseline clustering results without LSA Cid Size Isim Sem Imp Deo Evo 0 19 +0.169 1 17 1 0 1 14 +0.159 0 1 1 12 2 12 +0.146 1 1 10 0 3 14 +0.136 9 1 4 0
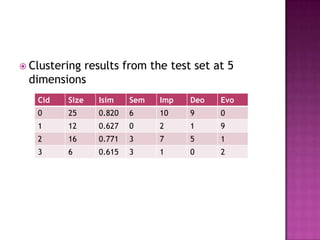
- 23. ? Clustering results from the test set at 5 dimensions Cid Size Isim Sem Imp Deo Evo 0 25 0.820 6 10 9 0 1 12 0.627 0 2 1 9 2 16 0.771 3 7 5 1 3 6 0.615 3 1 0 2
- 24. Cluster 0 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 20.5 9.8 3.2 2.3 2.0 Cluster 1 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 9.2 6.4 4.0 3.8 3.3 Cluster 2 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 8.9 8.1 6.7 6.1 4.5 Cluster 3 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 9.1 3.4 3.2 2.5 2.4
- 25. Cluster 0 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 34.0 32.3 20.7 7.6 5.4 Cluster 1 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 49.2 26.9 15.1 5.7 3.1 Cluster 2 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 47.5 27.9 22.7 1.2 0.7 Cluster 3 Feature Col 1 Col 2 Col 3 Col 4 Col 5 % 45.5 41.9 6.4 4.2 2.0
- 26. ? Repeat the experiment ? On a larger corpus ? On a corpus with more similar topics
- 27. ? The aim of this work was to cluster a document set into their respective topic areas. ? To investigate how LSA will perform in clustering, in comparison to a ready made clustering software. ? LSA gave results which were comparable with the results from CLUTO.
- 28. ? The clusters obtained using LSA had higher Isim values, in comparison to the baseline, indicating that the internal cluster similarity is higher when LSA is used. ? The descriptive features produced when LSA is used give a higher percentage of within cluster similarity that a feature can explain, than when LSA is not used ? It would be very ambitious to conclude that LSA does give better results, given the size of the data set, but LSA did give a commendable performance.
- 29. ? Csorba,K. and Vajk, I. (2006). Double Clustering in Latent Semantic Indexing. In Proceedings of SIAM, 4th Slovakan-Hungarian Joint Symposium on Applied Machine Intelligence, Herlany, Slovakia. ? Deerwester, S., Dumais,S.T., Furnas,G., Landauer,T., Harshman,R. (1990). Indexing by Latent Semantic Analysis.Journal of the American Society for Information Science. Volume 41, issue 6, p.391-407. ? Dumais,S.T., Furnas, G.W., Landauer,T.K., Deerwest er, S., Harshman, R. (1988). Using Latent Semantic Analysis to improve access to textual information.In proceedings of the SIGCHI conference on human factors in computing systems, p.281- 285, Washington D.C, United States.
- 30. ? Hofmann,T (1999). Probabilistic latent semantic indexing. In Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '99). ACM, New York, NY, USA, 50-57. ? Hong,J.(2000). Overview of Latent Semantic Indexing. Available [online] at : http://www.contentanalyst.com/images/ima ges/overview_LSI.pdf . Last accessed on 30th September, 2010. ? Karypis,G.,(2003). CLUTO* A Clustering toolkit.Release 2.1.1. Technical Report: #02- 017.Department of Computer Science, University of Minneapolis.
- 31. ? Paulsen J.R. and Ramampiaro, H. (2009). Combining latent semantic indexing and clustering to retrieve and cluster biomedical information: A 2-step approach, NorskInformatikonferanse (NIK), 2009. ? Wiemer-Hastings, P.(1999). Latent Semantic Analysis.In proceedings of the sixteenth International Joint conference on artificial intelligence. Volume 16, Number 2, p. 932- 941.
- 32. ? Zaiane, O. (1999). Principles of Knowledge Discovery in databases, chapter 8: Data Clustering, lecturing slides for CmPUT 690, University of Alberta. Available [online]at: http://www.cs.ualberta.ca/~zaiane/courses /cmput690/slides/chapter 8/. ? Zhao, Y and Karypis G. (2001). Criterion Functions for Document Clustering: Experiments and Analysis. Technical Report #01-40, Department of Computer Science, University of Minneapolis.