
































Machine Learning to moderate ads in real world classified's business
- 1. Machine Learning to moderate ads in real world classified's business by Vaibhav Singh & Jaroslaw Szymczak
- 2. Agenda ŌŚÅ Moderation problem ŌŚÅ Offline model creation ŌŚŗ feature generation ŌŚŗ feature selection ŌŚŗ data leakage ŌŚŗ the algorithm ŌŚÅ Model evaluation ŌŚÅ Going live with the product ŌŚŗ is your data really big? ŌŚŗ automatic model creation pipeline ŌŚŗ consistent development and production environments ŌŚŗ platform architecture ŌŚŗ performance monitoring
- 3. 50+ countries 60+ million new monthly listings 18+ million unique monthly sellers
- 4. What do moderators look for? Avoidance of payment Sell another item in paid listing by changing its content Flood site with duplicate posts to increase visibility Create multiple accounts to bypass free ad per user limit Violation of ToS Add Phone numbers, Company information on image rather than in description or dedicated fields Try to sell forbidden items, very often with title and description that try to evade keyword filters Miscategorized listings Item is placed in wrong category Item is coming from legitimate business, but is marked as coming from individual ŌĆśSeekŌĆÖ problem in job offers
- 6. Feature engineering... ŌĆ” and selection Feature selection: ŌŚÅ necessary for some algorithms, for others - not so much ŌŚÅ most important features ŌŚÅ avoiding leakage
- 7. Feature generation - one-hot-encoding
- 8. Feature generation - feature hashing
- 9. Feature hashing Ō×ö Good when dealing high dimensional, sparse features -- dimensionality reduction Ō×ö Memory efficient Ō×ö Cons - Getting back to feature names is difficult Ō×ö Cons - Hash collisions can have negative effects
- 10. Data Leakage Ō×ö Remove obvious fields e.g.: id, account numbers Ō×ö Check the importance of the features for any unusual observations Ō×ö Have hold-out set that you do not process wrt. target variable Ō×ö Closely monitor live performance
- 11. The algorithm Desired features: ŌŚÅ state-of-the-art structured binary problems ŌŚÅ allowing reducing variance errors (overfitting) ŌŚÅ allowing reducing bias errors (underfitting) ŌŚÅ has efficient implementation
- 12. eXtreme Gradient Boosting (XGBoost) Source: /JaroslawSzymczak1/xgboost-the-algorithm-that-wins-every-competition
- 13. Model evaluation
- 15. Beyond accuracy ŌŚÅ ROC AUC (Receiver-Operator Curve): ŌŚŗ can be interpreted as concordance probability (i.e. random positive example has the probability equal to AUC, that itŌĆÖs score is higher) ŌŚŗ it is too abstract to use as a standalone quality metric ŌŚŗ does not depend on classes ratio ŌŚÅ PRC AUC (Precision-Recall Curve) ŌŚŗ Depends on data balance ŌŚŗ Is not intuitively interpretable ŌŚÅ Precision @ fixed Recall, Recall @ fixed Precision: ŌŚŗ can be found using thresholding ŌŚŗ they heavily depend on data balance ŌŚŗ they are the best to reflect the business requirements ŌŚŗ and to take into account processing capabilities (then actually Precision @k is more accurate) ŌŚÅ choose one, and only one as your KPI and others as constraints
- 16. Example ROC for moderation problem
- 20. Going live with the product
- 21. Is your data really big?
- 22. SVM Light Data Format Ō×ö Memory Efficient. Features can be created on one machine and do not require huge clusters Ō×ö Cons - Number of features is unknown, store it separately 1 191:-0.44 87214:-0.44 200004:0.20 200012:1 206976:1 206983:-1 207015:1 207017:1 226201:1 1 1738:0.57 130440:-0.57 206999:0.32 207000:28 207001:6 207013:1 207015:1 207017:1 226300:1 0 2812:-0.63 34755:-0.31 206995:2.28 206997:1 206998:2 206999:0.00 207000:1 207001:28 226192:1 1 4019:0.35 206999:0.43 207000:40 207001:18 207013:1 207014:1 207016:1 226261:1 0 8903:0.37 207000:4 207001:14 207013:1 207014:1 207016:1 226262:1 1 5878:-0.27 206995:2.28 206998:1 206999:5.80 207000:1 207001:24 226187:1
- 23. Lessons Learnt Ō×ö Do not go for distributed learning if you donŌĆÖt need to Ō×ö Choose your tech dependent on data size. Do not go for hype driven development Ō×ö Your machine does not limit, thereŌĆÖs cloud Ō×ö Ask yourself: WhatŌĆÖs the most difficult problem to scale ? ŌåÆ People
- 25. Automatic model creation pipeline ŌŚÅ Automation makes things deterministic ŌŚÅ Airflow, Luigi and many others are good choice for Job dependency management
- 26. Luigi Dashboard
- 28. Lessons Learnt Ō×ö when you use the output path on your own, create your output at the very end of the task Ō×ö you can dynamically create dependencies by yielding the task Ō×ö adding workers parameter to your command parallelizes task that are ready to be run (e.g. python run.py Task ŌĆ” --workers 15)
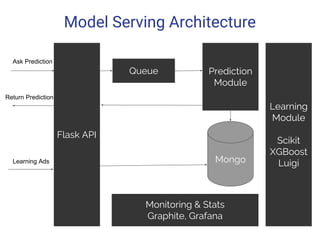
- 30. Model Serving Architecture Flask API Queue Prediction Module Mongo Monitoring & Stats Graphite, Grafana Learning Module Scikit XGBoost Luigi Ask Prediction Return Prediction Learning Ads
- 31. Image Model Serving Architecture AWS Kinensis Stream Incoming Pictures Hash Generation Country Specific Image Moderation General Moderation NSFW Tag and Category Prediction Mongo OLX Site S3 Models GPU Clusters Learning Cluster TF, Keras, MxNet
- 33. Model monitoring and management
- 34. Lessons Learnt Ō×ö Always Batch Batching will reduce CPU Utilization and the same machines would be able to handle much more requests Ō×ö Modularize, Dockerize and Orchestrate Containerize your code so that it is transparent to Machine configurations Ō×ö Monitoring Use a monitoring service Ō×ö Choose simple and easy tech
- 35. Acknowledgements ŌŚÅ Andrzej Pra┼éat ŌŚÅ Wojciech Rybicki Vaibhav Singh vaibhav.singh@olx.com Jaroslaw Szymczak jaroslaw.szymczak@olx.com PYDATA BERLIN 2017 July 2nd , 2017