

































































More Related Content
Similar to Make your data dance: PIVOT and GROUP BY in Oracle SQL (20)
More from stewashton (6)




Recently uploaded (20)




















Make your data dance: PIVOT and GROUP BY in Oracle SQL
- 1. Make your Data Dance UNPIVOT, PIVOT and GROUP BY Extensions Stew Ashton DOAG 2018 Can you read the following line? If not, please move closer. It's much better when you can read the code ;)
- 2. Who am I? • 1981-2015: – software engineer / application architect – From Mainframe to client / server to Web • 2005-present: focus on Oracle DB development – Contribute to asktom & ODC/OTN SQL forum – Presented at OOW, UKOUG tech, DOAG, ilOUG – Advocate of data-centric application architecture 2
- 3. Data with Subtotals? REGION COUNTRY CUSTOMER SALE_DATE QTY AMOUNT Europe DE Raina Silverberg 2017-01-23 2 110 Europe DE Raina Silverberg 2017-02-19 3 220 3 Europe DE Gloria Saintclair 2017-01-27 2 140 Europe DE Gloria Saintclair 2017-02-26 3 280 Europe DE Gloria Saintclair (Subtotal) 5 420 Europe DE Gloria Saintclair 2017-01-27 2 140 Europe DE Gloria Saintclair 2017-02-26 3 280 Europe DE Raina Silverberg (Subtotal) 5 330
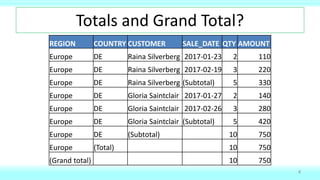
- 4. Totals and Grand Total? REGION COUNTRY CUSTOMER SALE_DATE QTY AMOUNT Europe DE Raina Silverberg 2017-01-23 2 110 Europe DE Raina Silverberg 2017-02-19 3 220 4 Europe DE Gloria Saintclair 2017-01-27 2 140 Europe DE Gloria Saintclair 2017-02-26 3 280 Europe DE Raina Silverberg (Subtotal) 5 330 Europe DE Gloria Saintclair (Subtotal) 5 420 Europe DE (Subtotal) 10 750 Europe (Total) 10 750 (Grand total) 10 750
- 5. Columns to Rows? 5 A C 1A 2A 1 2 3A3 4 5 6 1B 2B 3B 7 8 9 1C 2C 3C B 1B 2B 3B 1C 2C 3C
- 6. Rows to Columns? 6 A C 1A 2A 1 2 3A3 4 5 6 4A 5A 6A 7 8 9 7A 8A 9A B 4A 5A 6A 7A 8A 9A
- 7. Transpose? 7 A C 1A 2A 1 2 3A3 B 1B 2B 3B 1C 2C 3C 1 32 A B C Rows to columns and Columns to rows
- 9. How? • UNPIVOT • PIVOT • GROUP BY extensions – ROLLUP – CUBE – GROUPING SETS • GROUPING_ID() and GROUPING() functions 9
- 10. UNPIVOT: columns to rows 10 KEY COL VAL 1 A 1A KEY A B 1 1A 1B 1 B 1B 1 with data(KEY,A,B) as ( select 1, '1A', '1B' from dual ) select * from data unpivot(VAL for COL in(A,B)); KEY A B 1 1A 1B1 Metadata becomes data
- 11. KEYKEY 'A' 'B' 1A 1B1 PIVOT: rows to columns 11 KEY COL VAL 1 A 1A 1 B 1B select * from data unpivot(VAL for COL in(A,B)); pivot(max(VAL) for COL in('A','B')); Data becomes metadata 1 C 1C Only previously known COLs are output
- 12. KEY A_N A_V 1 VA1 Multiple Columns 12 select * from data unpivot((N, V) for COL in ((A_N, A_V) as 'A',(B_N, B_V) as 'B')) pivot( max(n) as N, max(v) as V for COL in ('A' as A,'B' as B)); B_N B_V 2 VB KEY COL N A 11 V VA B 21 VB 1 Round trip!
- 13. Transpose! 13 A C 1A 2A 1 2 3A3 B 1B 2B 3B 1C 2C 3C 1 32 A B C select * from t unpivot(x for nk in(a,b,c)) pivot(max(x) for k in(1,2,3)) order by 1; KNK
- 14. Matrix: rotate! 14 A C 1A 2A 1 2 3A3 B 1B 2B 3B 1C 2C 3C with normalized as ( select k r, c, v from t unpivot(v for c in( a as 1,b as 2,c as 3 )) ) , rotated as ( select 4-c r, r c, v from normalized ) select * from rotated pivot(max(v) for c in(1,2,3)) order by r; Normalize to cells (row, column, value), rotate, display
- 15. UNPIVOT: Intersecting Ranges 15 C 1 (null) 2 5 3 4 # ranges 1 2 3 2 1 O 1 3 2 4 5 (null) # ranges 1 2 1 1
- 16. 16 OBJ_ID F T C 1(null) C 25 C 34 O 13 O 24 O 5(null) select * from range_input
- 17. 17 select * from range_input unpivot ( F for FT in (F as 1, T as -1) ) OBJ_ID FT F C 11 C 12 C -15 C 13 C -14 O 11 O -13 O 12 O -14 O 15 OBJ_ID F T C 1(null) C 25 C 34 O 13 O 24 O 5(null)
- 18. 18 select * from range_input unpivot include nulls ( F for FT in (F as 1, T as -1) ) OBJ_ID FT F C 11 C -1(null) C 12 C -15 C 13 C -14 O 11 O -13 O 12 O -14 O 15 O -1(null) OBJ_ID FT F C 11 C 12 C -15 C 13 C -14 O 11 O -13 O 12 O -14 O 15
- 19. 19 with unpivoted as ( select * from range_input unpivot include nulls ( F for FT in (F as 1, T as -1) ) ) select OBJ_ID, F, T, NUM_R from ( select a.*, lead(F) over(partition by obj_id order by F) T, sum(FT) over(partition by obj_id order by F) NUM_R from unpivoted a ) where F < nvl(T,F+1) and NUM_R > 0 order by obj_id, T; OBJ_ID F T NUM_R C 1 2 1 C 2 3 2 C 3 4 3 C 4 5 2 C 5 (null) 1 O 1 2 1 O 2 3 2 O 3 4 1 O 5 (null) 1
- 20. Grouping Sales History • 2 years • 2 regions • 2 countries per region • 2 customers per country • 2 sales per year per customer 20
- 21. 21 select sum(amount) amount from sales_yr; AMOUNT 18360
- 22. 22 select sum(amount) amount from sales_yr group by (); AMOUNT 18360
- 23. 23 select region, sum(amount) amount from sales_yr group by region; REGION AMOUNT Americas 9720 Europe 8640 What if I want both?
- 24. 24 select region, sum(amount) amount from sales_yr group by grouping sets ( (), region ); REGION AMOUNT Americas 9720 Europe 8640 18360
- 25. 25 select region, country, sum(amount) amount from sales_yr group by grouping sets ( (), region, (region, country) ); REGION COUNTRY AMOUNT Europe DE 1500 Europe FR 7140 Europe 8640 Americas CA 8820 Americas US 900 Americas 9720 18360 What if I want 3 levels?
- 26. 26 select region, country, sum(amount) amount from sales_yr group by rollup(region, country); REGION COUNTRY AMOUNT Europe DE 1500 Europe FR 7140 Europe 8640 Americas CA 8820 Americas US 900 Americas 9720 18360
- 27. 27 select region, country, sum(amount) amount from sales_yr group by cube(region, country); REGION COUNTRY AMOUNT 18360 CA 8820 DE 1500 FR 7140 US 900 Europe 8640 Europe DE 1500 Europe FR 7140 Americas 9720 Americas CA 8820 Americas US 900 What if I have NULL data?
- 28. 28 select region, country, sum(amount) amount from sales_yr group by cube(region, country); REGION COUNTRY AMOUNT 18360 CA 8820 DE 1500 FR 7140 US 900 Europe 8640 Europe DE 1500 Europe FR 7140 Americas 9720 Americas CA 8820 Americas US 900
- 29. 29 select grouping(country) g_c, region, country, sum(amount) amount from sales_yr group by cube(region, country); G_C REGION COUNTRY AMOUNT 1 18360 0 CA 8820 0 DE 1500 0 FR 7140 0 US 900 1 Europe 8640 0 Europe DE 1500 0 Europe FR 7140 1 Americas 9720 0 Americas CA 8820 0 Americas US 900
- 30. 30 select grouping(region)*2 g_r, grouping(country) g_c, region, country, sum(amount) amount from sales_yr group by cube(region, country); G_R G_C REGION COUNTRY AMOUNT 2 1 18360 2 0 CA 8820 2 0 DE 1500 2 0 FR 7140 2 0 US 900 0 1 Europe 8640 0 0 Europe DE 1500 0 0 Europe FR 7140 0 1 Americas 9720 0 0 Americas CA 8820 0 0 Americas US 900
- 31. 31 select grouping_id(region, country) g_rc, grouping(region)*2 g_r, grouping(country) g_c, region, country, sum(amount) amount from sales_yr group by cube(region, country); G_RC G_R G_C REGION COUNTRY AMOUNT 3 2 1 18360 2 2 0 CA 8820 2 2 0 DE 1500 2 2 0 FR 7140 2 2 0 US 900 1 0 1 Europe 8640 0 0 0 Europe DE 1500 0 0 0 Europe FR 7140 1 0 1 Americas 9720 0 0 0 Americas CA 8820 0 0 0 Americas US 900
- 32. select deptno, job, sum(sal) sal from emp group by cube(deptno, job); 32 select deptno, job, sum(sal) sal from emp group by cube(deptno, job); DEPTNO JOB SAL 29025 CLERK 4150 ANALYST 6000 MANAGER 8275 SALESMAN 5600 PRESIDENT 5000 10 8750 10 CLERK 1300 10 MANAGER 2450 10PRESIDENT 5000 20 10875 20 CLERK 1900 20 ANALYST 6000 20 MANAGER 2975 30 9400 30 CLERK 950 30 MANAGER 2850 30SALESMAN 5600 JOB 10 20 30 TOTAL ANALYST 6000 6000 CLERK 1300 1900 950 4150 MANAGER 2450 2975 2850 8275 PRESIDENT 5000 5000 SALESMAN 5600 5600 (Total) 8750 10875 9400 29025 SpreadSheet-like Data from EMP
- 33. 33 select case grouping(deptno) when 1 then -1 else deptno end deptno, job, sum(sal) sal from emp group by cube(deptno, job); DEPTNO JOB SAL -1 29025 -1 CLERK 4150 -1 ANALYST 6000 -1 MANAGER 8275 -1SALESMAN 5600 -1PRESIDENT 5000 10 8750 10 CLERK 1300 10 MANAGER 2450 10PRESIDENT 5000 20 10875 20 CLERK 1900 20 ANALYST 6000 20 MANAGER 2975 30 9400 30 CLERK 950 30 MANAGER 2850 30SALESMAN 5600
- 34. 34 select case grouping(deptno) when 1 then -1 else deptno end deptno, job, sum(sal) sal, grouping(job) gr_job from emp group by cube(deptno, job); DEPTNO JOB SALGR_JOB -1 29025 1 -1 CLERK 4150 0 -1 ANALYST 6000 0 -1 MANAGER 8275 0 -1SALESMAN 5600 0 -1PRESIDENT 5000 0 10 8750 1 10 CLERK 1300 0 10 MANAGER 2450 0 10PRESIDENT 5000 0 20 10875 1 20 CLERK 1900 0 20 ANALYST 6000 0 20 MANAGER 2975 0 30 9400 1 30 CLERK 950 0 30 MANAGER 2850 0 30SALESMAN 5600 0
- 35. 35 select case gr_job when 1 then '(Total)' else job end job, "10", "20", "30", "(Total)" from ( select case grouping(deptno) when 1 then -1 else deptno end deptno, job, sum(sal) sal, grouping(job) gr_job from emp group by cube(deptno, job) ) pivot(max(sal) for deptno in ( 10, 20, 30, -1 as TOTAL )) order by gr_job, job; JOB 10 20 30 TOTAL ANALYST 6000 6000 CLERK 1300 1900 950 4150 MANAGER 2450 2975 2850 8275 PRESIDENT 5000 5000 SALESMAN 5600 5600 (Total) 8750 10875 9400 29025
- 36. SpreadSheet-like Data from SALES • 4 vertical levels – Grand total, region, country, customer • 2 horizontal levels – Year, total all years • 2 sums – QTY, AMOUNT 36
- 37. 37 select * from ( select decode(grouping_id(REGION,COUNTRY,CUSTOMER),7,'Total',REGION) REGION, decode(grouping_id(REGION,COUNTRY,CUSTOMER),3,'Total',COUNTRY) COUNTRY, decode(grouping_id(REGION,COUNTRY,CUSTOMER),1,'Total',CUSTOMER) CUSTOMER, decode(grouping(YR),1,'Total',YR) YR, sum(QTY) QTY, sum(AMOUNT) AMOUNT from sales_yr group by grouping sets( rollup(REGION,COUNTRY,CUSTOMER,YR), rollup(YR,REGION,COUNTRY) ) ) pivot(max(qty) as q,max(amount) as a for (yr) in ( ('2016') as "2016", ('2017') as "2017", ('Total') as "Total" )) order by nullif(region,'Total'),nullif(country,'Total'),nullif(customer,'Total')
- 38. 38 REGION COUNTRY CUSTOMER 2016_Q 2016_A 2017_Q 2017_A Total_Q Total_A Americas CA Alyce Gray 13 1530 13 1530 26 3060 Americas CA Salena Grace 21 2880 21 2880 42 5760 Americas CA (Total) 34 4410 34 4410 68 8820 Americas US Linette Ingram 3 210 3 210 6 420 Americas US Vida Puleo 3 240 3 240 6 480 Americas US (Total) 6 450 6 450 12 900 Americas (Total) 40 4860 40 4860 80 9720 Europe DE Gloria Saintclair 5 420 5 420 10 840 Europe DE Raina Silverberg 5 330 5 330 10 660 Europe DE (Total) 10 750 10 750 20 1500 Europe FR Koren Macdonald 17 2100 17 2100 34 4200 Europe FR Madelaine Gottlieb 11 1470 11 1470 22 2940 Europe FR (Total) 28 3570 28 3570 56 7140 Europe (Total) 38 4320 38 4320 76 8640 (Total) 78 9180 78 9180 156 18360
- 39. Make your Data Dance UNPIVOT, PIVOT and GROUP BY Extensions Stew Ashton DOAG 2018 Blog: https://stewashton.wordpress.com/2018/05/31/pivot-function-with-totals/ Twitter: @stewashton